Un article scientifique a été publié dans Communications of the ACM , octobre 2018, volume 61, numéro 10, pp. 68−77, doi: 10.1145 / 3230627
En février 2017, un hélicoptère a décollé de la piste d'atterrissage du Boeing en Arizona avec la mission habituelle: voler autour des collines les plus proches. Il a volé de manière complètement autonome. Conformément aux exigences de sécurité de la Federal Aviation Administration des États-Unis, le pilote n'a pas touché aux commandes. Ce n'était pas le premier vol autonome AH-6, que la compagnie appelle le petit oiseau sans pilote (ULB). Il vole comme ça depuis de nombreuses années. Cependant, cette fois au milieu du vol, l'hélicoptère a subi une cyberattaque. L'ordinateur de bord a attaqué le logiciel malveillant du caméscope, ainsi que le virus transmis par le lecteur flash infecté, qui a été inséré lors de la maintenance. L'attaque a menacé certains sous-systèmes, mais n'a pas pu compromettre la sécurité de fonctionnement de l'avion.
Idées clés
- Les preuves formelles de l'architecture logicielle d'un micro-noyau vérifié peuvent être mises à l'échelle, à peu de frais, vers des systèmes réels.
- Différents niveaux de sécurité et de fiabilité au sein d'un même système sont possibles et souhaitables. Il n'est pas nécessaire d'assurer une fiabilité maximale de l'ensemble du code.
- Une refonte et une refactorisation modérées suffisent pour élever les systèmes existants au niveau du code hautement fiable.
Vous pourriez penser que l'aviation militaire peut facilement repousser une telle cyberattaque. En réalité, une équipe de pentesters professionnels mandatée par la DARPA dans le cadre d'un programme de développement de systèmes informatiques militaires hautement fiables High-Assurance Cyber Military Systems (HACMS) en 2013 a réussi à pirater la première version du logiciel ULB, qui a été initialement développée pour assurer la sécurité des vols, et non la protection. des cyberattaques. Les pirates ont eu la possibilité de planter un hélicoptère ou de l'atterrir à n'importe quel endroit comme ils le souhaitent. Par conséquent, le risque de telles attaques avec un passager à bord ne peut guère être surestimé, et une tentative de piratage infructueuse en février 2017 indique certains changements fondamentaux dans le logiciel.
Cet article explique ces changements et la technologie qui les a rendus possibles. Il s'agit d'une technologie développée dans le cadre du programme HACMS visant à assurer le fonctionnement sûr des systèmes critiques dans un environnement cyber hostile - dans ce cas, plusieurs véhicules autonomes. La technologie est basée sur une vérification formelle du logiciel - ce sont des programmes avec des preuves mathématiques vérifiées automatiquement qui fonctionnent conformément à leurs spécifications. Bien que l'article ne soit pas consacré aux méthodes formelles elles-mêmes, il explique comment utiliser la vérification d'artefact pour protéger des systèmes réels dans la pratique.
Le résultat le plus impressionnant de HACMS est peut-être que la technologie peut être étendue aux systèmes réels existants, améliorant considérablement leur protection contre les cyberattaques. Ce processus est appelé «modernisation de la sécurité sismique», similaire aux améliorations sismiques des bâtiments. De plus, la majeure partie de la réingénierie a été effectuée par des ingénieurs de Boeing plutôt que par des spécialistes de la vérification formelle.
 "Bird" lors d'un vol d'essai sans pilote
"Bird" lors d'un vol d'essai sans piloteTous les logiciels d'hélicoptères ne sont pas construits sur des modèles mathématiques et des preuves. Le domaine de la vérification formelle n'est pas encore prêt pour une telle échelle. Cependant, le programme HACMS a démontré que l'application stratégique de méthodes formelles aux parties les plus importantes du système global améliore considérablement la protection. L'approche HACMS fonctionne pour les systèmes dans lesquels la fonctionnalité de sécurité souhaitée peut être obtenue par une application pure et simple au niveau de l'architecture. Il est basé sur notre micro-noyau vérifié sel4, dont nous parlerons ci-dessous. Il garantit l'isolement entre les sous-systèmes, à l'exception des canaux de communication clairement définis qui sont soumis aux politiques de sécurité du système. Cette isolation est garantie au niveau de l'architecture avec le framework vérifié CAmkES pour les composants système. Utilisation de langages spécifiques à un domaine de Galois Inc. CAmkES s'intègre aux outils d'analyse d'architecture de Rockwell Collins et de l'Université du Minnesota, ainsi qu'à des composants logiciels hautement fiables.
Les réalisations HACMS sont basées sur le vieil ami fidèle d'un ingénieur logiciel - modularisation. L'innovation est que les méthodes formelles prouvent l'observabilité des interfaces et l'encapsulation des modules internes. Cette adhésion garantie à la modularité permet aux ingénieurs qui ne sont pas experts en méthodes formelles (comme chez Boeing) de créer de nouveaux systèmes ou même de moderniser des systèmes existants et d'atteindre une stabilité élevée. Bien que les outils ne fournissent pas encore de preuves complètes de la sécurité du système.
Vérification formelle
Les preuves de l'exactitude mathématique des programmes remontent au moins
aux années 1960 , mais pendant longtemps, leurs avantages réels pour le développement de logiciels ont été limités en termes de portée et de profondeur. Cependant, au cours des dernières années, il y a eu un certain nombre de percées impressionnantes dans la vérification formelle au niveau du code des systèmes réels, du compilateur C
CompCert vérifié au micro-noyau
seL4 vérifié (voir les
articles scientifiques à ce sujet), le système de conférence vérifié
CoCon , le compilateur
CakeML ML vérifié, les programmes vérifiés pour prouver les théorèmes de
Milawa et
Candle , le système de fichiers à
sécurité intégrée
FSCQ vérifié, le système distribué IronFleet vérifié et le
cadre de noyau parallèle CertiKOS vérifié, ainsi que d'importants théorèmes mathématiques, y compris les
problèmes des quatre couleurs , la
preuve automatique
de l 'hypothèse de Kepler et
le théorème de Faith - Thompson sur ordre impair . Ce sont tous de vrais systèmes. Par exemple, CompCert est un produit commercial, le micro-noyau seL4 est utilisé dans l'aérospatiale et les avions sans pilote, comme plate-forme de l'Internet des objets, et le système CoCon a été utilisé lors de nombreuses grandes conférences scientifiques.
Ces projets de vérification nécessitent des efforts considérables. Pour rendre les méthodes formelles accessibles au public, ces efforts doivent être réduits. Nous montrons ici comment une combinaison stratégique de méthodes formelles et informelles, une automatisation partielle des méthodes formelles et un développement logiciel minutieux pour maximiser les avantages des composants isolés nous ont permis d'augmenter considérablement la fiabilité des systèmes dont la taille et la complexité globales sont des ordres de grandeur supérieurs à ceux mentionnés ci-dessus.
Veuillez noter que nous appliquons une vérification formelle principalement pour le code dont dépend la sécurité du système. Mais il y a d'autres avantages. Par exemple, la preuve que le code est correct émet des hypothèses sur le contexte dans lequel il est exécuté (par exemple, le comportement matériel et la configuration logicielle). La vérification formelle rend ces hypothèses explicites, ce qui aide les développeurs à se concentrer sur d'autres outils de vérification, tels que les tests. De plus, dans de nombreux cas, le système comprend à la fois du code vérifié et non vérifié. Lors des révisions de code, des tests et du débogage, la vérification formelle agit comme une lentille, se concentrant sur le code système critique et non vérifié.
seL4
Commençons par les fondements de la construction de systèmes fiables: le noyau du système d'exploitation (OS). C'est la partie la plus importante qui garantit la fiabilité de l'ensemble du système de manière rentable.
Le micro-noyau seL4 fournit un ensemble minimum de mécanismes formellement vérifiés pour la mise en œuvre de systèmes sécurisés. Contrairement
aux noyaux standard , il est délibérément universel et convient donc à la mise en œuvre d'un certain nombre de politiques de sécurité et d'exigences système.
L'un des principaux objectifs du développement de seL4 est de fournir une forte isolation entre les composants se méfiant mutuellement qui s'exécutent au-dessus du noyau. Il prend en charge son travail en tant qu'hyperviseur, par exemple, pour des systèmes d'exploitation Linux entiers, tout en les isolant des composants critiques pour la sécurité qui peuvent fonctionner ensemble, comme le montre la figure 1. En particulier, cette fonction permet aux développeurs de systèmes d'utiliser des composants hérités avec des composants masqués vulnérabilités à côté de composants hautement fiables.
 Fig. 1. Isolement et communications contrôlées en seL4
Fig. 1. Isolement et communications contrôlées en seL4Le noyau seL4 occupe une position spéciale parmi les micronoyaux à usage général. Non seulement il offre de
meilleures performances dans sa catégorie , ses 10000 lignes de code C ont subi une vérification formelle plus rigoureuse que tout autre logiciel accessible au public dans l'histoire humaine en termes non seulement de lignes de preuve, mais aussi de force de propriétés éprouvées. Il est basé sur la
preuve de la «justesse fonctionnelle» de l'implémentation principale en C. Il garantit que tout comportement du noyau est prédit par sa spécification abstraite formelle: consultez l'
application en ligne pour avoir une idée de l'apparence de ces preuves. Suite à cette garantie, nous avons ajouté des preuves supplémentaires que nous expliquerons après introduction aux mécanismes de base du noyau.
API seL4
Le noyau seL4 fournit un ensemble minimal de mécanismes pour implémenter des systèmes sécurisés: flux, gestion des capacités, espaces d'adressage virtuels, communication interprocessus (IPC), signalisation et livraison d'interruption.
Le noyau conserve son état dans les "objets du noyau". Par exemple, pour chaque thread du système, il existe un «objet de flux» qui stocke des informations sur la suppression, l'exécution et le contrôle d'accès. Les programmes de l'espace utilisateur ne peuvent faire référence aux objets du noyau qu'indirectement
par le
biais de ce que l'on appelle des «capacités» ou «capacités», qui combinent un lien vers un objet avec un ensemble de droits d'accès à celui-ci. Par exemple, un thread ne peut pas démarrer ou arrêter un autre thread s'il n'a pas la «capacité» pour l'objet de thread correspondant.
Les threads interagissent et se synchronisent en envoyant des messages via des «points de terminaison» de communication interprocessus. Un thread avec la capacité d'envoyer au point de terminaison correspondant peut envoyer un message à un autre thread qui a la capacité de recevoir vers ce point de terminaison. Les objets de notification assurent la synchronisation entre des ensembles de sémaphores binaires. La traduction d'adresses virtuelles est contrôlée par des objets du noyau qui représentent des répertoires de pages, des tables de pages et des objets de cadre ou des abstractions subtiles sur les objets d'architecture de processeur correspondants. Chaque flux a une certaine capacité "VSpace", qui pointe vers la racine de l'arborescence des objets de traduction d'adresse de flux. Les capacités elles-mêmes sont gérées par le noyau et stockées dans les objets du noyau «CNodes» situés dans la structure du graphe, qui mappent les liens vers les objets avec des droits d'accès, de manière similaire à la comparaison de tables de pages virtuelles avec des adresses physiques en mémoire. Chaque thread a sa propre capacité à identifier le CNode racine. L'ensemble des capacités disponibles à partir de cette racine, nous appelons «CSpace Stream». Les capacités peuvent être transférées via des points de terminaison avec transfert de travail, et elles peuvent également être déclarées partagées à l'aide de CSpace commun. La figure 2 montre ces objets du noyau.
 Fig. 2. Objets du noyau dans un système seL4 avec deux threads interagissant via un point de terminaison
Fig. 2. Objets du noyau dans un système seL4 avec deux threads interagissant via un point de terminaisonPreuve de sécurité
En raison de leur polyvalence, les API du noyau seL4 sont de bas niveau et prennent en charge des architectures système hautement dynamiques. Par conséquent, les preuves directes de ces API sont difficiles à obtenir.
Le concept de haut niveau des politiques de contrôle d'accès résume les objets individuels et les capacités du noyau, capturant à la place la configuration de contrôle d'accès du système en utilisant un ensemble de «sujets» (composants) abstraits et les pouvoirs que chacun d'eux a sur les autres (par exemple, pour lire des données et envoyer des messages) . Dans l'exemple de la fig. 2, les composants A et B ont gagné l'autorité sur le point final.
Sewell et ses collègues ont prouvé que les politiques de contrôle d'accès seL4 garantissent le respect de deux fonctions de sécurité de base: la restriction des privilèges et l'intégrité.
La restriction de l'autorité signifie que la politique de contrôle d'accès est une approximation statique (inchangée) sûre des capacités spécifiques et des objets du noyau dans le système pour tout état futur. Cette propriété implique que, quelle que soit l'évolution du système, aucun composant ne recevra plus d'autorité que ne le prévoit la stratégie de contrôle d'accès. Dans la figure 2, la stratégie pour le composant B n'a pas d'accès en écriture au composant A. Par conséquent, le composant B ne pourra jamais obtenir cet accès à l'avenir. Cette propriété implique que le raisonnement au niveau de la stratégie est une approximation sûre du raisonnement sur l'état spécifique du contrôle d'accès dans le système.
L'intégrité signifie que quel que soit le composant, il ne pourra jamais modifier les données du système (y compris les appels système qu'il peut effectuer) qu'il n'est clairement pas autorisé à modifier la stratégie de contrôle d'accès. Par exemple, sur la fig. 2, le seul composant de l'autorité de A sur un autre composant est le droit d'envoyer des données au point de terminaison à partir duquel le composant B reçoit des informations. Cela signifie que le composant A ne peut modifier que son état, l'état du thread B et l'état du tampon de messages. Il ne peut pas modifier d'autres parties du système.
Un effet secondaire de l'intégrité est la confidentialité, lorsqu'un composant est
incapable de lire les informations d'un autre composant sans autorisation : il s'agit d'une propriété éprouvée de la non-interférence non transitive seL4. Autrement dit, dans un système correctement configuré (avec des restrictions plus strictes que simplement pour l'intégrité), aucun des composants ne peut, sans autorisation, trouver des informations sur un autre composant ou son exécution. La preuve exprime cette propriété en termes de politique de flux d'informations, qui peut être extraite de la politique de contrôle d'accès utilisée dans la preuve d'intégrité. Les informations ne seront transmises que lorsqu'elles sont expressément autorisées par la politique. La preuve couvre les flux d'informations explicites ainsi que les canaux de stockage potentiels cachés dans le noyau. Mais les canaux de synchronisation sont en dehors de sa zone et
doivent être traités par d'autres moyens .
D'autres preuves dans seL4 incluent une extension de l'exactitude fonctionnelle et, par conséquent, des théorèmes de sécurité à un niveau binaire
pour l'architecture ARMv7 et un profil d'exécution dans le pire des cas pour le noyau (
1 ,
2 ), qui est nécessaire pour les systèmes en temps réel. Le noyau seL4 est disponible pour différentes architectures: ARMv6, ARMv7 ARMv7a, ARMv8, RISC-V, Intel x86 et Intel x64. À l'heure actuelle, il a passé les tests de machine sur l'architecture ARMv7 pour l'ensemble de la pile de vérification, ainsi que sur ARMv7a avec des extensions d'hyperviseur pour la correction fonctionnelle.
Sécurité de l'architecture
La section précédente a décrit les méthodes de programmation par lesquelles le noyau seL4 crée une base solide pour des systèmes fiables. Le noyau forme une base informatique fiable (TCB) - un composant essentiel du logiciel qui doit fonctionner correctement pour garantir la sécurité du système. Dans les systèmes réels, cette base est beaucoup plus large qu'un simple micro-noyau. Il est nécessaire de vérifier une pile logicielle supplémentaire afin d'obtenir le même niveau de confiance que pour le noyau. Cependant, il existe des classes de systèmes pour lesquelles une telle vérification n'est pas nécessaire: ils ont besoin de théorèmes d'isolement au niveau du noyau pour dériver certaines propriétés de sécurité au niveau du système. Cette section fournit un exemple d'un tel système.
Ce sont des systèmes dans lesquels les architectures de composants ont déjà implémenté une propriété critique, peut-être avec plusieurs petits composants de confiance. Notre exemple est le logiciel de contrôle de vol quadcopter, un appareil de démonstration du programme HACMS mentionné précédemment.
La figure 3 montre les principaux composants matériels du quadricoptère. L'architecture est intentionnellement plus complexe que celle requise par le quadcopter, car elle était censée représenter l'ULB et à ce niveau d'abstraction est similaire à l'architecture de l'ULB.
 Fig. 3. Architecture d'un avion autonome
Fig. 3. Architecture d'un avion autonomeLa figure montre deux ordinateurs principaux: un ordinateur de bord qui communique avec la station au sol et contrôle le logiciel à bord (par exemple, la caméra), et un ordinateur de navigation pour contrôler le vol du véhicule, lire les données des capteurs et contrôler les moteurs. Les ordinateurs sont connectés via un réseau interne ou un bus CAN sur un quadricoptère, Ethernet sur ULB. Le quadricoptère dispose également d'un point WiFi non protégé, ce qui permet de démontrer des méthodes de protection supplémentaires.
Dans cet exemple, considérons un ordinateur de bord. Pour cela, quatre propriétés de base doivent être remplies:
- authentification appropriée des commandes de la station au sol;
- confidentialité des clés cryptographiques;
- aucun message supplémentaire pour l'ordinateur de navigation;
- les logiciels non fiables d'autres systèmes embarqués ne peuvent pas affecter le vol de l'appareil.
L'hypothèse de travail est que la caméra n'est pas fiable, potentiellement compromise ou malveillante, que ses pilotes et logiciels obsolètes sont potentiellement compromis, ainsi que tous les canaux de communication externes. Dans cet exemple, nous supposons une cryptographie correcte et solide, c'est-à-dire que la clé ne peut pas être récupérée, et nous allons au-delà de la portée de la tâche pour supprimer les communications radio de l'ennemi avec une station au sol.La figure 4 montre comment l'architecture quadricoptère est conçue pour fournir ces propriétés. La machine virtuelle (VM) Linux sert de conteneur pour les logiciels de périphériques intégrés, les pilotes de caméra et les points d'accès Wi-Fi hérités. Nous isolons le module de contrôle de cryptographie dans son propre composant, avec des connexions au bus CAN, au canal de la station au sol et à la machine virtuelle Linux pour envoyer des données à la station au sol. La tâche du composant cryptographique est de transmettre (uniquement) des messages autorisés à l'ordinateur de bord via l'interface CAN de la pile et de renvoyer des données de diagnostic à la station au sol. Le composant radio envoie et reçoit des messages bruts qui sont cryptés et décryptés (avec authentification) par le composant cryptographique. Fig.4. Architecture d'ordinateur embarquée quadcopter simplifiéeLa définition des propriétés souhaitées du système se réduit exclusivement aux propriétés d'isolement et au comportement de l'architecture en termes de flux d'informations, ainsi qu'au comportement d'un seul composant cryptographique de confiance. En supposant le comportement correct de ce composant, les clés ne peuvent pas être compromises, car aucun autre composant n'y a accès. Le canal entre Linux et le composant cryptographique de la Fig. 4 est uniquement destiné à la messagerie et ne donne pas accès à la mémoire. Seuls les messages autorisés peuvent entrer dans le bus CAN, car le composant cryptographique est la seule communication avec le bus. Les logiciels non fiables et le WiFi, en tant que partie de la machine virtuelle Linux, sont encapsulés par l'isolement des composants et ne peuvent interagir avec le reste du système que via un composant cryptographique de confiance.Il est facile d'imaginer qu'une telle analyse de l'architecture puisse être largement automatisée en vérifiant des modèles et des outils de raisonnement mécanique d'un niveau supérieur. Comme indiqué pour les systèmes MILS , les limites des composants dans une telle architecture ne sont pas seulement un outil pratique pour le partitionnement et la gestion de code, mais avec une isolation forcée fournissent des limites efficaces pour un raisonnement formel sur le comportement du système. Cependant, tout dépend de la bonne application des limites des composants au moment de l'exécution dans l'implémentation finale du système binaire.Les mécanismes du noyau seL4 discutés précédemment sont capables de fournir une telle implémentation, mais le niveau d'abstraction des mécanismes contraste fortement avec les blocs et les flèches du schéma architectural: une politique de contrôle d'accès encore plus abstraite contient encore beaucoup plus de détails que le schéma d'architecture. Dans un système réel de cette taille, des dizaines de milliers d'objets et de «capacités» du noyau sont créés par le logiciel et les erreurs de configuration peuvent entraîner des failles de sécurité. Ensuite, nous discutons comment non seulement nous automatisons la configuration et la création d'un tel code, mais aussi comment prouver automatiquement la conformité aux limites de l'architecture.
Fig.4. Architecture d'ordinateur embarquée quadcopter simplifiéeLa définition des propriétés souhaitées du système se réduit exclusivement aux propriétés d'isolement et au comportement de l'architecture en termes de flux d'informations, ainsi qu'au comportement d'un seul composant cryptographique de confiance. En supposant le comportement correct de ce composant, les clés ne peuvent pas être compromises, car aucun autre composant n'y a accès. Le canal entre Linux et le composant cryptographique de la Fig. 4 est uniquement destiné à la messagerie et ne donne pas accès à la mémoire. Seuls les messages autorisés peuvent entrer dans le bus CAN, car le composant cryptographique est la seule communication avec le bus. Les logiciels non fiables et le WiFi, en tant que partie de la machine virtuelle Linux, sont encapsulés par l'isolement des composants et ne peuvent interagir avec le reste du système que via un composant cryptographique de confiance.Il est facile d'imaginer qu'une telle analyse de l'architecture puisse être largement automatisée en vérifiant des modèles et des outils de raisonnement mécanique d'un niveau supérieur. Comme indiqué pour les systèmes MILS , les limites des composants dans une telle architecture ne sont pas seulement un outil pratique pour le partitionnement et la gestion de code, mais avec une isolation forcée fournissent des limites efficaces pour un raisonnement formel sur le comportement du système. Cependant, tout dépend de la bonne application des limites des composants au moment de l'exécution dans l'implémentation finale du système binaire.Les mécanismes du noyau seL4 discutés précédemment sont capables de fournir une telle implémentation, mais le niveau d'abstraction des mécanismes contraste fortement avec les blocs et les flèches du schéma architectural: une politique de contrôle d'accès encore plus abstraite contient encore beaucoup plus de détails que le schéma d'architecture. Dans un système réel de cette taille, des dizaines de milliers d'objets et de «capacités» du noyau sont créés par le logiciel et les erreurs de configuration peuvent entraîner des failles de sécurité. Ensuite, nous discutons comment non seulement nous automatisons la configuration et la création d'un tel code, mais aussi comment prouver automatiquement la conformité aux limites de l'architecture.Vérification de la vue des composants
Comme les preuves de sécurité sont simplifiées avec des abstractions formelles des politiques de sécurité, l'abstraction aide également à la conception du système. La plate - forme Camkes composante s'exécute sur des abstractions seL4 au-dessus des mécanismes du noyau de bas niveau, fournissant des primitives de communication et décomposant le système en unités fonctionnelles, comme le montre la Fig. 5. En utilisant cette plate-forme, les architectes système peuvent concevoir et construire des systèmes basés sur seL4 en termes de composants de haut niveau qui interagissent entre eux et avec les périphériques matériels via des connecteurs, tels que les appels de procédure à distance (RPC), les ports de données et les événements. Fig. 5. Flux de travail CAmkES
Fig. 5. Flux de travail CAmkESGénération de code
En interne, CAmkES implémente ces abstractions à l'aide d'objets de noyau de bas niveau dans seL4. Chaque composant contient (au moins) un flux, CSpace et VSpace. Les connecteurs RPC utilisent des objets de point de terminaison et CAmkES génère du code intermédiaire pour traiter les messages et les envoyer aux points de terminaison IPC. De même, le connecteur de port de données est implémenté via une mémoire partagée - des trames communes présentes dans les espaces d'adressage de deux composants - et peut éventuellement limiter la direction du transfert de données. Enfin, le connecteur d'événement est implémenté à l'aide du mécanisme de notification seL4.CAmkES génère également dans capDL une spécification de bas niveau de la configuration initiale des objets et des capacités du noyau du système. Cette spécification devient entrée dans l'initialiseur seL4, quiil démarre d'abord après le chargement et effectue les opérations seL4 nécessaires pour créer une instance et initialiser le système .Ainsi, la plateforme de composants génère du code sans effort supplémentaire de la part du développeur. L'architecture des composants décrit un ensemble de blocs et de flèches, et la tâche d'implémentation se résume à simplement remplir les champs. La plateforme génère le reste, fournissant la mise en œuvre de l'architecture décrite.Sur une plate-forme avec des composants traditionnels, le code généré étendra la base informatique de confiance du système, car il peut affecter la fonctionnalité des composants. Cependant, CAmkES génère également des preuves.Preuve automatique
Lors de la génération de code "intermédiaire", CAmkES produit des preuves formelles dans Isabelle / HOL, effectuant la validation pendant la traduction et démontrant que le code "intermédiaire" généré obéit à une spécification de haut niveau et que la spécification capDL générée est un raffinement correct de la description CAmkES . Nous avons également prouvé que l'initialiseur seL4 configure correctement le système dans la configuration initiale requise. Dans le même temps, nous automatisons la majeure partie de la construction du système sans étendre la base informatique de confiance.Les développeurs envisagent rarement l'émission de générateurs de code; ils ne s'intéressent qu'à la fonctionnalité et à la logique métier. Nous supposons également que les preuves de code intermédiaire n'ont pas besoin d'être vérifiées, c'est-à-dire que les développeurs peuvent se concentrer sur la preuve de l'exactitude de leur propre code. Tout comme l'en-tête CAmkES généré donne au développeur une API pour le code généré, les opérateurs de lemme de niveau supérieur produisent une API pour preuve. Les lemmes décrivent le comportement attendu des connecteurs. Dans l'exemple de middleware RPC de la figure 6 fonction généréef permet d'appeler une fonction à distanceg dans un autre composant. Pour enregistrer l'abstraction, appelezf devrait être équivalent à appelerg .
Le lemme généré par le système garantit que f à partir du code RPC généré se comporte comme un appel directg .
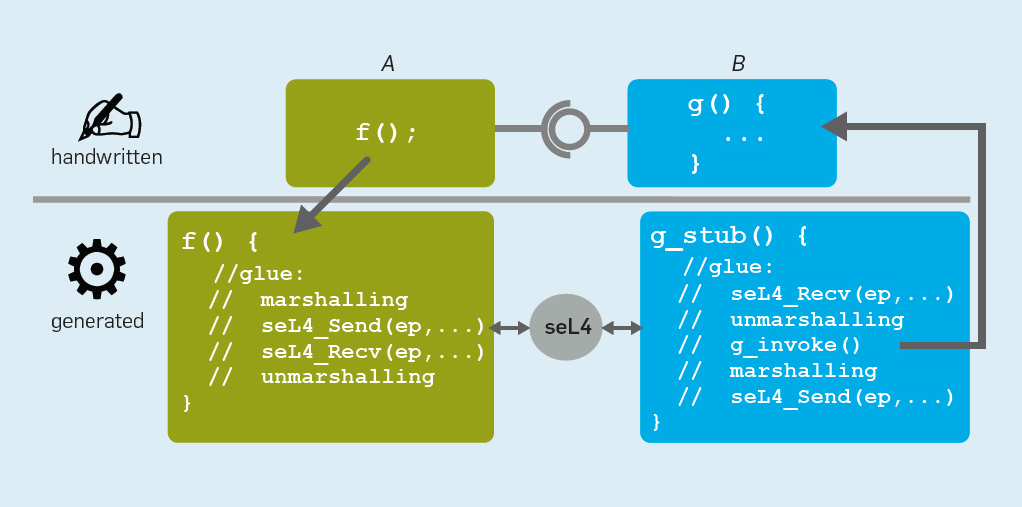 Fig. 6. Code RPC généréPour l'utilisation réelle des preuves générées par le système, elles doivent être composables avec des preuves (presque) arbitraires fournies par l'utilisateur, comme pour une fonctiong , et pour les contextes dans lesquelsg
Fig. 6. Code RPC généréPour l'utilisation réelle des preuves générées par le système, elles doivent être composables avec des preuves (presque) arbitraires fournies par l'utilisateur, comme pour une fonctiong , et pour les contextes dans lesquelsg et
f .
Pour atteindre cette composabilité, la spécification du connecteur est paramétrée via des spécifications fournies par l'utilisateur pour les fonctions à distance. De cette façon, les ingénieurs peuvent raisonner sur leur architecture en fournissant des spécifications et des preuves pour leurs composants, et s'appuyer sur les spécifications du code généré.À ce jour, nous avons démontré ce processus du début à la fin en utilisant le connecteur spécial CAmkES RPC ( 1 , 2 ). Étant donné que les modèles pour d'autres connecteurs (ports de données et événements) sont beaucoup plus simples que les RPC, il ne sera pas difficile d'étendre le générateur de preuves pour prendre en charge ces connecteurs, ce qui vous permettra de créer des systèmes vérifiés plus diversifiés.Après le code de communication, CAmkES crée la configuration de contrôle d'accès initiale pour appliquer les limites de l'architecture. Pour prouver que ces deux descriptions de système - capDL et CAmkES - correspondent, considérez la description CAmkES comme une abstraction pour la description capDL. Nous utilisons le cadre précédemment testé pour dériver l'autorité d'un objet sur un autre objet de la description capDL. Nous allons donc augmenter les preuves au niveau de la politique. De plus, nous avons défini des règles de retrait de l'autorité entre les composants dans la description CAmkES. Cette preuve garantit que les objets capDL représentés comme un graphe de privilèges avec des objets regroupés par composants ont les mêmes limites entre les groupes que dans le graphe de composants CAmkES équivalent. Intuitivement, cette correspondance des limites signifie que l'analyse de l'architecture de la politique à partir de la description CAmkES sauvera la politique de la description générée par capDL, qui, à son tour, est garantie de satisfaire aux exigences de restriction d'autorité, d'intégrité et de confidentialité, comme mentionné précédemment.Enfin, pour prouver l'initialisation correcte, CAmkES utilise un initialiseur universel qui démarre en tant que première tâche utilisateur après le chargement. En seL4, cette première tâche utilisateur (et unique) a accès à toute la mémoire disponible, l'utilisant pour créer des objets et des «capacités» conformément à la description détaillée de capDL, qu'elle accepte en entrée. Il est prouvé quel'état après l'exécution de l'initialiseur satisfait l'état décrit dans la spécification spécifiée . Cette preuve est vraie pour le modèle d'initialisation exact, mais pas encore au niveau de l'implémentation. Comparée à la profondeur du reste de la chaîne de preuves, cette limitation peut sembler faible, mais il s'agit déjà de preuves plus formelles que celles requises au plus haut niveau (EAL7) des critères généraux d'évaluation de la sécurité.Mise à niveau de sécurité sismique
Dans la pratique, il est difficile d'assurer le développement d'un système à partir de zéro pour des raisons de sécurité; par conséquent, la possibilité de mettre à niveau d'anciens logiciels est cruciale pour développer des systèmes sûrs. Notre cadre basé sur seL4 prend en charge un processus itératif, que nous appelons «mises à niveau de sécurité sismique», car un architecte régulier mettra à niveau les bâtiments existants pour une plus grande stabilité sismique. Nous illustrons le processus par l'exemple de l'adaptation progressive de l'architecture logicielle existante d'un hélicoptère sans pilote, passant du schéma de test traditionnel à un système hautement fiable avec des théorèmes soutenus par des méthodes formelles. Bien que cet exemple soit basé sur un véritable projet ULB, il est ici simplifié et n'inclut pas tous les détails.L'architecture originale de l'hélicoptère coïncide avec l'architecture décrite à la Fig. 3. Sa fonctionnalité est fournie par deux ordinateurs distincts: l'ordinateur de navigation contrôle le vol réel et l'ordinateur de bord effectue des tâches de haut niveau (telles que communiquer avec une station au sol et naviguer dans l'image à partir de la caméra). La version initiale de l'ordinateur de bord était une application monolithique pour Linux. Au cours du processus de modernisation, les ingénieurs de Boeing ont appliqué les méthodes, les outils et les composants fournis par les partenaires HACMS.Étape 1. Virtualisation
La première étape consistait à prendre le système tel quel et à l'exécuter dans une machine virtuelle au-dessus d'un hyperviseur sécurisé (voir la figure 7). Dans la métaphore de la modernisation sismique, cela correspond à placer le système sur une base plus mobile. Une machine virtuelle au-dessus de seL4 dans ce système se compose d'un composant CAmkES, qui comprend un moniteur de machine virtuelle (VMM) et un système d'exploitation invité, dans ce cas Linux. Le noyau fournit des abstractions matérielles de virtualisation et VMM gère ces abstractions pour la machine virtuelle. Le noyau seL4 limite non seulement le système d'exploitation invité, mais aussi VMM, vous n'avez donc pas besoin de faire confiance à l'implémentation VMM pour fournir une isolation forcée. Une défaillance VMM entraînera une défaillance du système d'exploitation invité, mais pas une défaillance de l'ensemble du système. Fig. 7. Toutes les fonctionnalités dans une seule machine virtuelleSelon la configuration du système, la machine virtuelle peut avoir accès aux périphériques via des pilotes paravirtualisés, des pilotes directs ou les deux. Dans le cas des pilotes pass-through, les développeurs peuvent utiliser le système MMU ou IOMMU pour empêcher la violation des limites d'isolement par les périphériques matériels et les pilotes du système invité. Veuillez noter que le simple démarrage du système sur une machine virtuelle n'ajoute aucun avantage supplémentaire en termes de sécurité ou de fiabilité. L'étape 1 n'est nécessaire que pour préparer l'étape 2.
Fig. 7. Toutes les fonctionnalités dans une seule machine virtuelleSelon la configuration du système, la machine virtuelle peut avoir accès aux périphériques via des pilotes paravirtualisés, des pilotes directs ou les deux. Dans le cas des pilotes pass-through, les développeurs peuvent utiliser le système MMU ou IOMMU pour empêcher la violation des limites d'isolement par les périphériques matériels et les pilotes du système invité. Veuillez noter que le simple démarrage du système sur une machine virtuelle n'ajoute aucun avantage supplémentaire en termes de sécurité ou de fiabilité. L'étape 1 n'est nécessaire que pour préparer l'étape 2.Étape 2. Plusieurs machines virtuelles
La deuxième étape de la modernisation sismique renforce les murs existants. Dans le logiciel, un développeur peut augmenter la sécurité et la fiabilité en divisant le système source en plusieurs sous-systèmes, chacun étant constitué d'une machine virtuelle qui exécute uniquement une partie du code système source. Chaque combinaison VM / VMM est effectuée dans un composant CAmkES distinct, qui introduit l'isolement entre différents sous-systèmes, ne leur permettant pas de s'influencer mutuellement, puis permet la coexistence de différents niveaux de sécurité.
En général, les sections suivent l'architecture logicielle existante, bien que si l'architecture n'est pas suffisante pour une isolation efficace, une refonte peut être nécessaire.
En règle générale, les sections doivent interagir les unes avec les autres, donc à ce stade, nous ajouterons également des canaux de communication. Pour assurer la sécurité, il est impératif que ces interfaces soient étroites, limitant la connexion entre les partitions à ce qui est absolument nécessaire. De plus, les protocoles d'interface doivent être efficaces, avec un nombre minimum de messages ou de volume de données. Il est essentiel que seL4 vous permette de contrôler et de limiter l'échange de mémoire entre les partitions afin de minimiser la quantité de données.
En plus des machines virtuelles qui représentent les sous-systèmes du système source, nous extrayons et implémentons également des composants pour toutes les ressources partagées (telles qu'une interface réseau).
Vous pouvez répéter l'étape 2 jusqu'à ce que nous atteignions le détail souhaité des sections. Des détails corrects sont un compromis entre la résistance de l'isolation, d'une part, et les frais généraux de communication et les coûts de reconstruction, d'autre part.
Dans notre exemple, nous avons trois sections: une machine virtuelle qui implémente les fonctions de communication d'une station au sol exécutant Linux; une autre machine virtuelle qui implémente des fonctions de navigation par caméra (exécutant également Linux); et un composant de partage de réseau natif, comme le montre la fig. 8.
 Fig.8. Fonctionnalité divisée en plusieurs machines virtuelles
Fig.8. Fonctionnalité divisée en plusieurs machines virtuellesÉtape 3. Composants natifs
Lorsqu'un système est décomposé en sections distinctes d'une machine virtuelle, certaines ou toutes les sections individuelles peuvent être réimplémentées en tant que composants natifs, plutôt qu'en tant que machines virtuelles. Cela réduira considérablement la surface d'attaque pour la même fonctionnalité. Un avantage supplémentaire de la conversion d'un composant en code machine est la réduction de la charge et l'augmentation de la productivité, la suppression du système d'exploitation invité et la surcharge de l'exécution du code et de la communication VMM.
Les composants natifs augmentent également le potentiel d'application de la vérification formelle et d'autres méthodes pour augmenter la fiabilité d'un composant. Les options sont différentes: de la vérification fonctionnelle complète du code natif à la génération conjointe de code et de preuves, à la vérification des modèles, à l'utilisation de langages de programmation sécurisés, à l'analyse statique ou aux tests rigoureux traditionnels d'une base de code plus petite.
Grâce à l'isolement fourni par seL4 et l'architecture des composants, il est possible de travailler ensemble dans un système de composants avec différents niveaux de fiabilité. Dans ce cas, les composants à faible fiabilité ne réduisent pas la fiabilité globale du système et les développeurs bénéficient du fait que vous n'avez pas besoin de consacrer d'efforts à vérifier ce code.
Dans notre exemple, nous analyserons la machine virtuelle pour le canal de communication entre l'ordinateur de bord et la station au sol en modules natifs. Dans les composants natifs, les fonctions de communication, de cryptographie et de contrôle (mission-manager) sont implémentées. Nous laisserons la caméra et le WiFi dans la machine virtuelle comme un composant obsolète non fiable (voir Fig. 9). Cette séparation est devenue un compromis entre les efforts de refonte des sous-systèmes et les avantages de l'utilisation de composants natifs en termes de performances et de fiabilité.
 Fig. 9. Fonctionnalité implémentée dans les composants natifs
Fig. 9. Fonctionnalité implémentée dans les composants natifsÉtape 4. Fiabilité du système dans son ensemble
Après avoir reçu tous les modules nécessaires, nous passerons à l'étape finale: l'analyse de l'ensemble du système dans son ensemble en fonction de la fiabilité de l'architecture et des composants individuels.
Dans le cadre de HACMS, la communication, la cryptographie et un module de contrôle sont implémentés dans le
langage orienté objet de type sécurisé Ivory , avec allocation d'une quantité fixe de mémoire sur le tas. Sans vérification supplémentaire, Ivory ne nous donne pas de garanties d'exactitude fonctionnelle, mais donne confiance dans la tolérance aux pannes et la fiabilité des urgences. Étant donné l'isolement des composants, nous pensons que ces garanties restent en présence de composants non fiables (tels que la machine virtuelle de la caméra).
Le composant réseau est implémenté sur du code C standard, qui se compose du code utilisateur pour la plate-forme et du code bibliothèque existant. Son niveau de fiabilité correspond au niveau obtenu grâce à une mise en œuvre soignée d'un code bien connu. La fiabilité peut être améliorée sans trop de frais en utilisant des méthodes telles que la
synthèse des pilotes , ainsi qu'en utilisant des langages de type sûr comme Ivory. Dans une analyse générale de la sécurité du système, tout compromis d'un composant réseau n'affectera que les paquets réseau. Le trafic étant crypté, une telle attaque ne mettra pas en péril la condition des spécifications que seules les commandes autorisées entrent dans l'ordinateur de bord.
La machine virtuelle du caméscope est la partie la plus faible du système, car elle fonctionne sur le système Linux et est censée contenir des vulnérabilités. Mais la machine virtuelle est isolée, donc si les attaquants la cassent, ils ne pourront pas passer à d'autres composants. La pire chose qu'un attaquant puisse faire est d'envoyer les mauvaises données au composant de contrôle. Comme dans le quadricoptère, ce composant vérifie les données reçues de la caméra. Et il a résisté avec succès à la cyberattaque mentionnée au début de l'article. Il s'agissait d'une attaque de type «boîte blanche», au cours de laquelle l'équipe de Pentesters a eu accès à tout le code et à la documentation, ainsi qu'à tous les canaux de communication externes. Elle a intentionnellement obtenu un accès root à la machine virtuelle de la caméra, simulant une attaque réussie contre un logiciel obsolète. Le confinement des attaques et la capacité de se défendre contre ce scénario très puissant sont devenus un test digne de nos exigences de sécurité et l'identification de toutes les hypothèses manquées, problèmes d'interface ou autres problèmes de sécurité que l'équipe de recherche pourrait ne pas reconnaître.
Limitations et travaux futurs
Cet article fournit une vue d'ensemble de la méthode permettant d'atteindre des niveaux de sécurité très élevés pour les systèmes dans lesquels la fonctionnalité de sécurité est applicable via l'architecture des composants. Nous avons prouvé des théorèmes pour le niveau du noyau et sa configuration correcte, ainsi que des théorèmes qui garantissent que la plate-forme de composants définit correctement les limites de sécurité conformément à la description de son architecture et qu'elle génère le code correct pour les appels de procédure à distance. La connexion avec l'analyse de sécurité de haut niveau du système reste informelle et les théorèmes de code de communication ne couvrent pas toutes les primitives de communication fournies par la plateforme. Pour obtenir automatiquement un théorème qui couvre l'ensemble du système du début à la fin, un travail supplémentaire est nécessaire. Cependant, à ce stade, il est clair que cette tâche est réalisable.
L'objectif principal du travail présenté est de réduire considérablement les efforts de vérification pour des classes spécifiques de systèmes. L'approche purement architecturale décrite ici peut être étendue à des systèmes autres que l'ULB, mais elle est clairement limitée par le fait qu'elle ne peut exprimer que des propriétés qui sont déterminées par l'architecture des composants du système. Les retours diminueront si cette architecture change pendant l'exécution du programme et si les propriétés dépendent de manière critique du comportement d'un trop grand nombre de composants approuvés ou de composants de trop grande taille.
La première étape pour atténuer ces limitations consiste à créer une bibliothèque de composants pré-testés d'un haut niveau de fiabilité pour une utilisation en tant que blocs de construction fiables dans de telles architectures. Cette bibliothèque peut inclure des modèles de sécurité (tels que la désinfection des données d'entrée, des filtres de sortie, des moniteurs de confidentialité et d'exécution) potentiellement générés à partir de spécifications de niveau supérieur, ainsi que des composants d'infrastructure tels que des modules de chiffrement réutilisables, un stockage de clés, des systèmes de fichiers, Pilotes et piles réseau hautement fiables. Si la sécurité dépend de plusieurs de ces composants, il est nécessaire de justifier la fiabilité de leur interaction et de leur partage. Les principaux problèmes techniques ici sont les discussions sur la concurrence et les protocoles, ainsi que le flux d'informations en présence de composants de confiance. Malgré ces limites, les travaux démontrent le développement rapide de véritables systèmes hautement fiables basés sur seL4. Actuellement, la création de tels systèmes est possible à moindre coût que les tests traditionnels.
Application: frais de main-d'œuvre
Le développement de la conception et du code pour seL4 a pris deux années-hommes. Si nous ajoutons toutes les preuves spécifiques au sérotype, un total de 18 années-personnes sera obtenu pour 8700 lignes de code pour C.À titre de comparaison, le développement d'un micro-noyau de taille comparable L4Ka :: Pistachio de la famille seL4 a pris six années-homme et n'a pas fourni un niveau de fiabilité significatif. Cela signifie une différence de vitesse de développement de seulement 3,3 fois entre les logiciels vérifiés et traditionnels. Selon
la méthode d'évaluation de Colbert et Bohm , la certification selon les critères EAL7 traditionnels pour 8700 lignes de code C prendra plus de 45,9 années-personnes. Cela signifie que la vérification formelle de la mise en œuvre au niveau binaire est déjà 2,3 fois moins chère que le plus haut niveau de certification selon des critères généraux, tout en offrant une fiabilité considérablement plus élevée.
À titre de comparaison, l'approche HACMS décrite ici utilise uniquement les preuves existantes pour chaque nouveau système, y compris les preuves générées par les outils. Ainsi, l'effort de preuve général pour un système qui correspond à cette approche se résume à des semaines-hommes, et non à des années, et les tests ne se résument qu'à valider les hypothèses.