Bonjour Mon nom est Ivan Davydov, je suis engagé dans la recherche de performances dans Yandex.Money.
Imaginez que vous disposez de serveurs puissants, chacun hébergeant un certain nombre d'applications. S'il n'y en a pas beaucoup, ils n'interfèrent pas les uns avec les autres - ils sont confortables et douillets. Une fois que vous arrivez aux microservices et retirez une partie de la fonctionnalité "lourde" dans des applications distinctes.
Ici, vous pouvez vous laisser emporter, et il y aura trop de microservices, ce qui rendra difficile leur gestion et leur tolérance aux pannes. En conséquence, une douzaine d'applications qui se battent pour des ressources partagées seront «regroupées» sur chaque serveur. Ce sera une «grande famille», mais dans une grande famille, ne cliquez pas avec votre bec!
Une fois, nous avons également fait face à cela. Mon histoire portera sur des nuits lourdes et sans sommeil, lorsque je me suis assis sous une lampe dans la nuit et j'ai tiré sur la prod. Tout a commencé avec le fait que nous avons commencé à remarquer des problèmes de réseau sur les serveurs de combat.
Ils ont grandement influencé les performances et effectué des baisses importantes. Dans le même temps, il s'est avéré que les mêmes erreurs se produisent avec un flux d'utilisateurs régulier, mais dans une bien moindre mesure.
Le problème résidait dans l'utilisation des sockets TCP de plus de 100%. Cela se produit lorsque toutes les sockets sur les serveurs s'ouvrent et se ferment constamment. Pour cette raison, il y a des problèmes de réseau d'interaction entre les applications et divers types d'erreurs apparaissent - l'hôte distant n'est pas disponible, la connexion HTTP / HTTPS (délai de connexion / lecture, arrêt incorrect du pair SSL) est interrompue et d'autres.
Même si vous n'avez pas votre propre service de paiement électronique, il n'est pas très difficile d'évaluer l'ampleur de la douleur lors d'une vente régulière - le trafic augmente plusieurs fois et la dégradation des performances peut entraîner des pertes importantes. Nous sommes donc arrivés à deux conclusions - nous devons évaluer comment les capacités actuelles sont utilisées et isoler les applications les unes des autres.
Pour isoler les applications, nous avons décidé de recourir à la conteneurisation. Pour ce faire, nous avons utilisé un hyperviseur qui contient de nombreux conteneurs séparés avec des applications. Cela vous permet d'isoler les ressources du processeur, de la mémoire, des périphériques d'entrée / sortie, des réseaux, ainsi que des arborescences de processus, des utilisateurs, des systèmes de fichiers, etc.
Avec cette approche, chaque application possède son propre environnement, qui offre flexibilité, isolation, fiabilité et améliore les performances globales du système. C'est une solution belle et élégante, mais avant cela, vous devez répondre à un certain nombre de questions:
- Quelle marge de performance possède actuellement une instance d'application?
- Comment l'application est-elle mise à l'échelle et existe-t-il une redondance des ressources dans la configuration actuelle?
- Est-il possible d'améliorer les performances d'une instance et quel est le goulot d'étranglement?
Avec de telles questions, des collègues sont venus à nous - une équipe de chercheurs en performance.
On fait quoi?
Nous mettons tout en œuvre pour assurer la performance de notre service et, tout d'abord, nous le recherchons et l'améliorons pour les processus métiers de notre production. Chaque processus métier, qu'il s'agisse de payer des marchandises dans un magasin avec un portefeuille ou de transférer de l'argent entre utilisateurs, représente essentiellement pour nous une chaîne de demandes dans le système.
Nous menons des expériences et préparons des rapports pour évaluer les performances du système à haute intensité de demandes entrantes. Les rapports contiennent des mesures de performances et une description détaillée des problèmes et goulots d'étranglement identifiés. À l'aide de ces informations, nous améliorons et optimisons notre système.
L'évaluation du potentiel de chaque application est compliquée par le fait que plusieurs microservices qui utilisent la puissance de toutes les instances impliquées participent à l'organisation de la séquence des demandes de processus métier.
Métaphoriquement parlant, nous connaissons la puissance de notre armée, mais nous ne connaissons pas le potentiel de chacun des combattants. Par conséquent, en plus des recherches en cours, il est nécessaire d'évaluer les ressources utilisées dans le cadre du processus de gestion des capacités. Ce processus est appelé gestion de la capacité.
Nos recherches aident à identifier et à prévenir un manque de ressources, à prévoir les achats de fer et à disposer de données précises sur les capacités actuelles et potentielles du système. Dans le cadre de ce processus, les performances réelles des applications (médianes et maximales) sont contrôlées et des données sur le stock actuel sont fournies.
L'essence de la gestion des capacités est de trouver un équilibre entre les ressources consommées et la productivité.
Avantages:
- À tout moment, on sait ce qui arrive aux performances de chaque application.
- Moins de risques lors de l'ajout de nouveaux microservices.
- Réduction des coûts d'achat de nouveaux équipements.
- Ces capacités qui existent déjà sont utilisées plus intelligemment.
Fonctionnement de la gestion des capacités
Revenons à notre situation avec de nombreuses applications. Nous avons mené une étude dont le but était d'évaluer comment les capacités sont utilisées sur les serveurs de production.
En bref, le plan d'action est le suivant:
- Définissez l'intensité utilisateur sur des applications spécifiques.
- Faites un profil de prise de vue.
- Évaluez les performances de chaque instance d'application.
- Taux d'évolutivité.
- Compiler des rapports et des conclusions sur le nombre minimal requis d'instances pour chaque application dans un environnement de combat.
Et maintenant plus en détail.
Les outils
Nous utilisons Heka et Zabbix pour collecter des mesures d'intensité personnalisées. Grafana est utilisé pour visualiser les métriques collectées.
Zabbix est nécessaire pour surveiller les ressources du serveur, telles que: CPU, mémoire, connexions réseau, DB et autres. Heka fournit des données sur le nombre et l'heure d'exécution des demandes entrantes / sortantes, la collecte de métriques sur les files d'attente d'applications internes et une quantité infinie d'autres données. Grafana est un outil de visualisation flexible utilisé par différentes équipes Yandex.Money. Nous ne faisons pas exception.
Grafana peut montrer, par exemple, de telles choses
Apache JMeter est utilisé comme générateur de trafic. Avec son aide, un scénario de prise de vue est compilé, qui comprend la mise en œuvre des demandes, la surveillance de la validité de la réponse, un contrôle flexible du flux de flux, et bien plus encore. Cet outil a ses avantages et ses inconvénients, mais pour aller plus loin "pourquoi ce produit particulier?" Je ne le ferai pas.
En plus de JMeter, le framework yandex-tank est utilisé - un outil pour les tests de stress et l'analyse des performances des services et applications Web. Il vous permet de connecter vos modules pour obtenir toutes les fonctions souhaitées et d'afficher les résultats dans la console ou sous forme de graphiques. Les résultats de nos tirs sont affichés dans Lunapark (analogue à https://overload.yandex.net ), où nous pouvons les observer en détail en temps réel, jusqu'aux seconds crêtes, en fournissant la discrétion nécessaire et suffisante, et ainsi répondre plus rapidement aux explosions, résultant de la prise de vue. Dans graphane, on peut aussi ajuster la discrétion, mais cette solution est plus chère en termes de ressources physiques et logiques. Et parfois, nous téléchargeons même des données brutes et les visualisons via l'interface graphique Jmeter. Mais seulement - chut!
En parlant de dégradation. Presque tous les plantages qui se produisent dans l'application sous un flux de trafic important sont rapidement analysés à l'aide de Kibana . Mais ce n'est pas non plus une panacée - certains problèmes de réseau ne peuvent être analysés qu'en supprimant et en analysant le trafic.
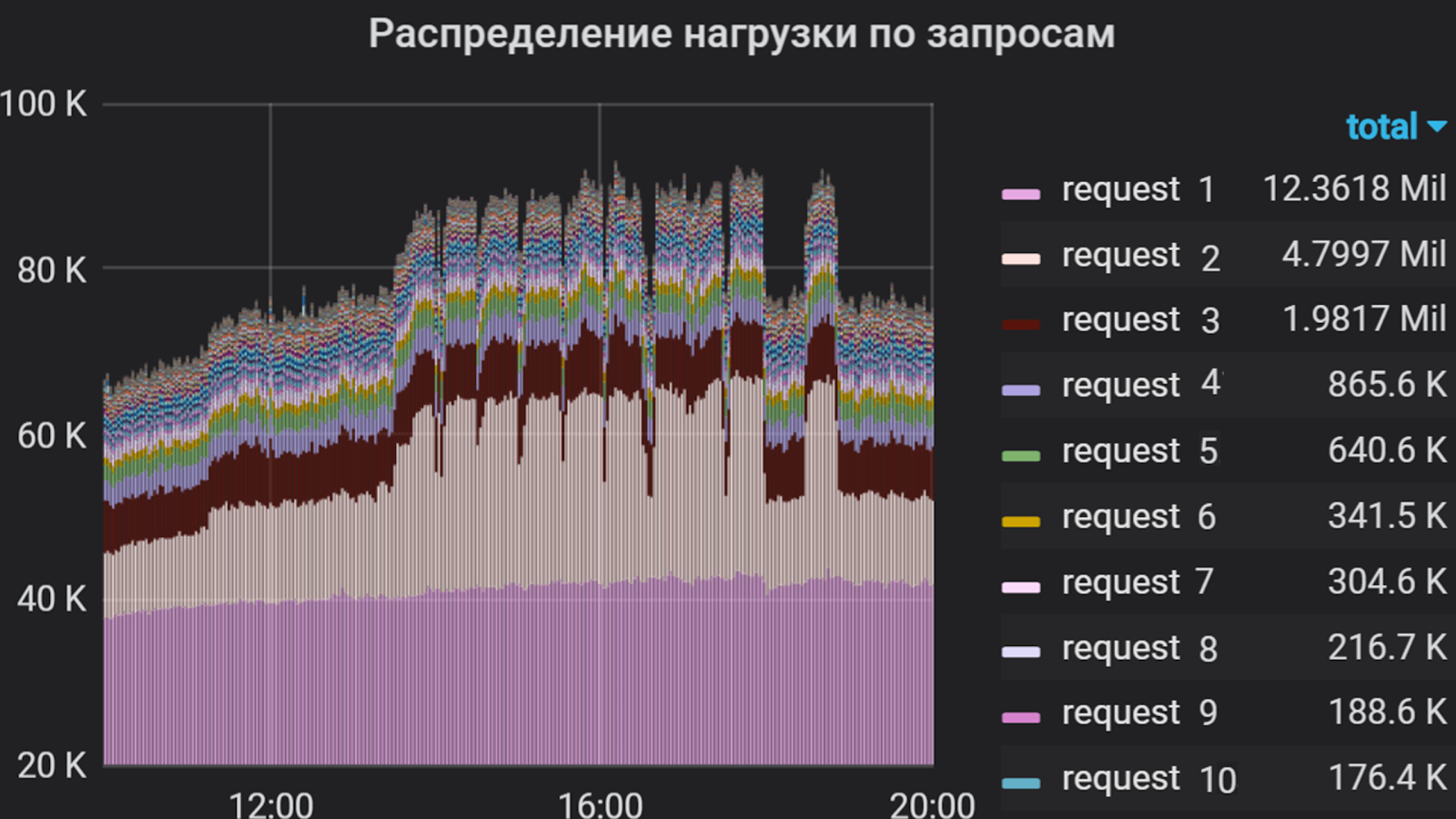
À l'aide de Grafana, nous avons analysé l'intensité de l'utilisateur dans l'application pendant plusieurs mois. Nous avons décidé de prendre le temps total du processeur pour exécuter les requêtes comme unité de mesure, c'est-à-dire que le nombre de requêtes et le temps de leur exécution ont été pris en compte. Nous avons donc compilé une liste des demandes les plus «lourdes», qui constituent l'essentiel du flux vers l'application. C'est cette liste qui a constitué la base du profil de tir.

Intensité utilisateur par application pendant plusieurs mois
Profil de tir et de visée
Nous appelons le lancement d'un script dans le cadre d'une expérience. Le profil est composé de deux parties.
La première partie consiste à écrire un script de requête. Au cours de la mise en œuvre, il est nécessaire d'analyser l'intensité de l'utilisateur pour chaque demande d'application entrante et de faire un pourcentage entre eux pour identifier les plus appelés et les plus longs. La deuxième partie est la sélection des paramètres de croissance du débit: avec quelle intensité et pendant combien de temps à charger.
Pour plus de clarté, la méthodologie de compilation d'un profil est mieux illustrée par l'exemple.
Grafana construit un graphique qui reflète l'intensité de l'utilisateur et la part de chaque demande dans le flux total. En fonction de ce temps de distribution et de réponse pour chaque demande, des groupes sont créés dans JMeter, chacun étant un générateur de trafic indépendant. Le scénario est basé uniquement sur les demandes les plus «difficiles», car il est difficile de tout mettre en œuvre (dans certaines applications, il y en a plus d'une centaine), ce qui n'est pas toujours nécessaire en raison de leur intensité relativement faible.

Pourcentage de requêtes
Cette étude examine l'intensité des utilisateurs dans un flux constant, et les «salves» périodiques se produisent le plus souvent en privé.
Dans notre exemple, deux groupes sont considérés. Le premier groupe comprenait «demande 1» et «demande 2» dans le rapport de 1 à 2. De même, le deuxième groupe comprenait les demandes 3 et 4. Les demandes restantes pour le composant sont beaucoup moins intenses, nous ne les incluons donc pas dans le script.

Regroupement des requêtes dans Jmeter
Sur la base du temps de réponse médian pour chaque groupe, la performance est estimée par la formule:
x = 1000 / t, où t est le temps médian, ms
Nous obtenons le résultat du calcul et estimons l'intensité approximative avec un nombre croissant de threads:
TPS = x * p, où p est le nombre de threads, TPS est la transaction par seconde et x est le résultat du calcul précédent.
Si la demande est traitée en 500 ms, alors avec un flux, nous avons 2 Tps, et avec 100 threads devrait idéalement avoir 200 Tps. Sur la base des résultats obtenus, les paramètres de croissance initiaux peuvent être sélectionnés. Après la première itération de recherche, ces paramètres sont généralement ajustés.
Lorsque le scénario de prise de vue est prêt, nous commençons la prise de vue - prise de vue pendant une minute dans un flux. Ceci est fait afin de vérifier l'opérabilité du script avec un flux constant, d'évaluer le temps de réponse aux requêtes dans chaque groupe et d'obtenir un pourcentage de requêtes.
Lors de l'exécution de ce profil, nous avons constaté qu'à la même intensité, le pourcentage de demandes est conservé, car le temps de réponse moyen dans le second groupe est plus long que dans le premier. Par conséquent, nous avons défini le même débit pour les deux groupes. Dans d'autres cas, il serait nécessaire de sélectionner expérimentalement les paramètres pour chaque groupe séparément.
Dans cet exemple, l'intensité a été appliquée par étapes, c'est-à-dire qu'un certain nombre de flux ont été ajoutés sur un certain intervalle.

Options de croissance d'intensité
Les paramètres de croissance de l'intensité étaient les suivants:
- Le nombre cible de fils est de 100 (déterminé lors de la visée).
- Croissance pendant 1000 secondes (~ 16 min.).
- 100 étapes.
Ainsi, toutes les 10 secondes, nous ajoutons un flux. L'intervalle entre l'ajout de threads et le nombre de threads ajoutés varie en fonction du comportement du système à une étape particulière. Souvent, l'intensité est fournie avec une croissance régulière, de sorte que vous pouvez suivre l'état du système à chaque étape.
Tir
En règle générale, le tir commence la nuit à partir de serveurs distants. À l'heure actuelle, le trafic des utilisateurs est minime - cela signifie que la prise de vue n'affectera guère les utilisateurs et que l'erreur dans les résultats sera moindre.
Selon les résultats du premier tir dans un cas, nous ajustons le nombre de fils et le temps de croissance, analysons le comportement du système dans son ensemble et trouvons des écarts dans le travail. Après tous les ajustements, le tir répété dans une instance commence. À ce stade, nous déterminons les performances maximales et contrôlons l'utilisation des ressources matérielles du serveur avec l'application et de tout ce qui se trouve derrière.
Selon les résultats du tournage, les performances d'une instance de notre application étaient d'environ 1000 Tps. Dans le même temps, une augmentation du temps de réponse pour toutes les demandes a été enregistrée sans augmenter la productivité, c'est-à-dire que nous avons atteint la saturation, mais pas la dégradation.
À l'étape suivante, nous comparons les résultats obtenus d'autres instances. Ceci est important, car le matériel peut différer, ce qui signifie que différentes instances peuvent donner des indicateurs très différents. C'était donc avec nous - certains des serveurs se sont avérés être un ordre de grandeur plus productifs en raison de la génération et des caractéristiques. Par conséquent, nous avons identifié un groupe de serveurs avec les meilleurs résultats et étudié leur évolutivité.
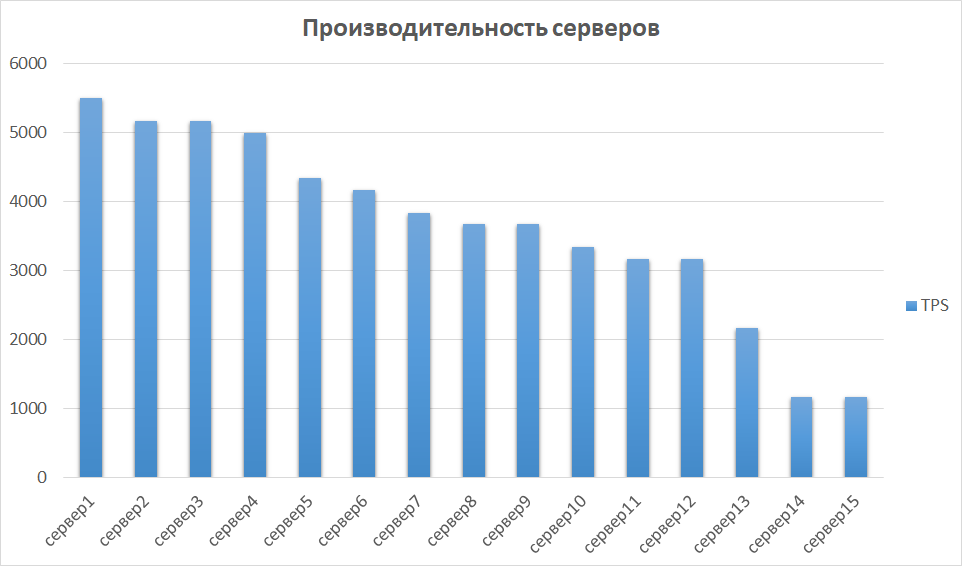
Comparaison des performances du serveur
Évolutivité et goulot d'étranglement
L'étape suivante consiste à étudier les performances des instances 2, 3 et 4. En théorie, les performances devraient croître de façon linéaire avec un nombre croissant d'instances. En pratique, ce n'est généralement pas le cas.
Dans notre exemple, cela s'est avéré être une option presque parfaite.

La raison de la saturation de la croissance de la productivité était l'épuisement des pools de connecteurs avant le backend ultérieur. Ce problème est résolu en contrôlant la taille des pools sur le côté sortant et entrant et conduit à une augmentation des performances des applications.
Dans d'autres études, nous sommes tombés sur des choses plus intéressantes. Des expériences ont montré qu'avec les performances, l'utilisation des connexions CPU et base de données augmente rapidement. Dans notre cas, cela s'est produit parce que dans la configuration avec une instance, nous avons rencontré nos propres paramètres pour les pools d'applications, et avec deux instances, nous avons doublé ce nombre, doublant ainsi le flux sortant. La base de données n'était pas prête pour un tel volume. Pour cette raison, les pools de la base de données ont commencé à se boucher, le pourcentage de CPU consommé a atteint un niveau critique de 99%, et le temps de traitement des demandes a augmenté, et une partie du trafic a complètement chuté. Et nous avons déjà obtenu de tels résultats à deux reprises!
Pour enfin nous convaincre de nos peurs, nous avons tiré sur 3 instances. Les résultats étaient approximativement les mêmes que dans les deux premiers, sauf qu'ils sont rapidement arrivés à un trouble.
Il y a un autre exemple de «plugs», qui, à mon avis, est le plus douloureux - c'est un code mal écrit. Il peut y avoir tout ce que vous voulez, à commencer par des requêtes de base de données qui s'exécutent en quelques minutes, se terminant par du code qui alloue mal la mémoire d'une machine Java.
Résumé
Par conséquent, la marge d'application étudiée dans notre exemple d'application présente une marge de performance supérieure à 5 fois.
Pour augmenter la productivité, il est nécessaire de calculer un nombre suffisant de pools de processeurs dans les paramètres de l'application. Deux instances pour une application spécifique suffisent et l'utilisation des 15 disponibles est redondante.
Après l'étude, les résultats suivants ont été obtenus:
- L'intensité de l'utilisateur pendant 1 mois a été déterminée et surveillée.
- La marge de performance d'une instance de l'application a été identifiée.
- Les résultats sont obtenus sur les erreurs qui se produisent sous un grand flux.
- Des goulots d'étranglement pour la poursuite des travaux sur l'augmentation de la productivité ont été identifiés.
- Le nombre minimal suffisant d'instances pour le bon fonctionnement de l'application a été identifié. Et, en conséquence, l'utilisation excessive des capacités a été révélée.
Les résultats de l'étude ont constitué la base du projet de transfert de composants dans des conteneurs, dont nous discuterons dans les articles suivants. Maintenant, nous pouvons dire avec certitude combien de conteneurs et avec quelles caractéristiques il faut avoir, comment utiliser leurs capacités de manière rationnelle et sur quoi travailler pour garantir une bonne performance.
Venez dans notre salle de chat télégramme confortable où vous pouvez toujours demander des conseils, aider vos collègues et simplement parler de la recherche sur la productivité.
C'est tout pour aujourd'hui. Posez des questions dans les commentaires et abonnez-vous au blog Yandex.Money - bientôt nous parlerons du phishing et de la façon de l'éviter.