Les jeux sont utilisés depuis des décennies comme l'un des principaux moyens de tester et d'évaluer le succès des systèmes d'intelligence artificielle. Au fur et à mesure que les opportunités se développaient, les chercheurs ont recherché des jeux d'une complexité toujours croissante, qui refléteraient les différents éléments de la pensée nécessaires pour résoudre les problèmes scientifiques ou appliqués du monde réel. Ces dernières années, StarCraft est considéré comme l'une des stratégies en temps réel les plus polyvalentes et complexes et l'une des plus populaires sur la scène des sports électroniques de l'histoire, et maintenant StarCraft est également devenu le principal défi pour la recherche en IA.
AlphaStar est le premier système d'intelligence artificielle capable de vaincre les meilleurs joueurs professionnels. Dans une série de matchs qui ont eu lieu le 19 décembre, AlphaStar a remporté une victoire écrasante sur Grzegorz Komincz (
MaNa ) contre
Liquid , l'un des
joueurs les
plus forts du monde , avec un score de 5: 0. Avant cela, un match de démonstration réussi a également été joué contre son coéquipier Dario Wünsch (
TLO ). Les matchs ont eu lieu selon toutes les règles professionnelles sur une
carte de tournoi spéciale et sans aucune restriction.
Malgré des succès importants dans des jeux tels
qu'Atari ,
Mario ,
Quake III Arena et
Dota 2 , les techniciens de l'IA ont combattu sans succès la complexité de StarCraft. Les meilleurs
résultats ont été obtenus en construisant manuellement les éléments de base du système, en imposant diverses restrictions aux règles du jeu, en dotant le système de capacités surhumaines ou en jouant sur des cartes simplifiées. Mais même ces nuances ne permettaient pas de se rapprocher du niveau des joueurs professionnels. Contrairement à cela, AlphaStar joue un jeu à part entière en utilisant des réseaux de neurones profonds, qui sont formés sur la base de données brutes de jeu, en utilisant des méthodes d'
enseignement avec un professeur et d'
apprentissage avec renforcement .
Défi principal
StarCraft II est un univers fantastique fictif avec un gameplay riche à plusieurs niveaux. Avec l'édition originale, c'est le jeu le plus grand et le plus réussi de tous les temps, qui a été combattu en tournois pendant plus de 20 ans.

Il existe de nombreuses façons de jouer, mais la plus courante dans les sports électroniques est les tournois en tête-à-tête composés de 5 matchs. Pour commencer, le joueur doit choisir l'une des trois races - zergs, protoss ou terrans, chacune ayant ses propres caractéristiques et capacités. Par conséquent, les joueurs professionnels se spécialisent le plus souvent dans une course. Chaque joueur commence par plusieurs unités de travail qui extraient des ressources pour construire des bâtiments, d'autres unités ou développer des technologies. Cela permet au joueur de saisir d'autres ressources, de construire des bases plus sophistiquées et de développer de nouvelles capacités pour déjouer l'adversaire. Pour gagner, le joueur doit équilibrer très délicatement l'image de l'économie globale, appelée "macro", et le contrôle de bas niveau des unités individuelles, appelé "micro".
La nécessité d'équilibrer les objectifs à court terme et à long terme et de s'adapter aux situations imprévues pose un grand défi aux systèmes qui, en fait, s'avèrent souvent être totalement inflexibles. La résolution de ce problème nécessite une percée dans plusieurs domaines de l'IA:
Théorie des jeux : StarCraft est un jeu où, comme dans «Stone, Scissors, Paper», il n'y a pas de stratégie gagnante unique. Par conséquent, dans le processus d'apprentissage, l'IA doit constamment explorer et élargir les horizons de ses connaissances stratégiques.
Informations incomplètes : contrairement aux échecs ou au go, où les joueurs voient tout ce qui se passe, dans StarCraft, les informations importantes sont souvent cachées et doivent être activement extraites via l'intelligence.
Planification à long terme : comme dans les tâches du monde réel, les relations de cause à effet peuvent ne pas être instantanées. Un jeu peut également durer une heure ou plus, donc les actions effectuées au début d'un jeu peuvent n'avoir absolument aucune signification à long terme.
Temps réel : contrairement aux jeux de société traditionnels, où les participants se relaient à tour de rôle, dans StarCraft, les joueurs effectuent des actions en continu, au fil du temps.
Immense espace d'action : des centaines d'unités et de bâtiments différents doivent être surveillés simultanément, en temps réel, ce qui donne un espace combinatoire vraiment énorme d'opportunités. En plus de cela, de nombreuses actions sont hiérarchiques et peuvent changer et compléter en cours de route. Notre paramétrage du jeu donne en moyenne environ 10 à 26 actions par unité de temps.
Face à ces défis, StarCraft est devenu un grand défi pour les chercheurs en IA. Les compétitions StarCraft et StarCraft II en cours trouvent leur origine dans le lancement de l'
API BroodWar en 2009. Parmi eux,
AIIDE StarCraft AI Competition ,
CIG StarCraft Competition ,
Student StarCraft AI Tournament et
Starcraft II AI Ladder .
Remarque : En 2017, PatientZero a publié sur Habré une excellente traduction de « L'histoire des compétitions d'IA dans Starcraft ».Pour aider la communauté à explorer davantage ces problèmes, nous, en
collaboration avec Blizzard en 2016 et 2017,
avons publié la
boîte à outils PySC2 , qui comprend le plus grand éventail de rediffusions anonymisées jamais publiées. Sur la base de ce travail, nous avons combiné nos réalisations d'ingénierie et d'algorithmique pour créer l'AlphaStar.
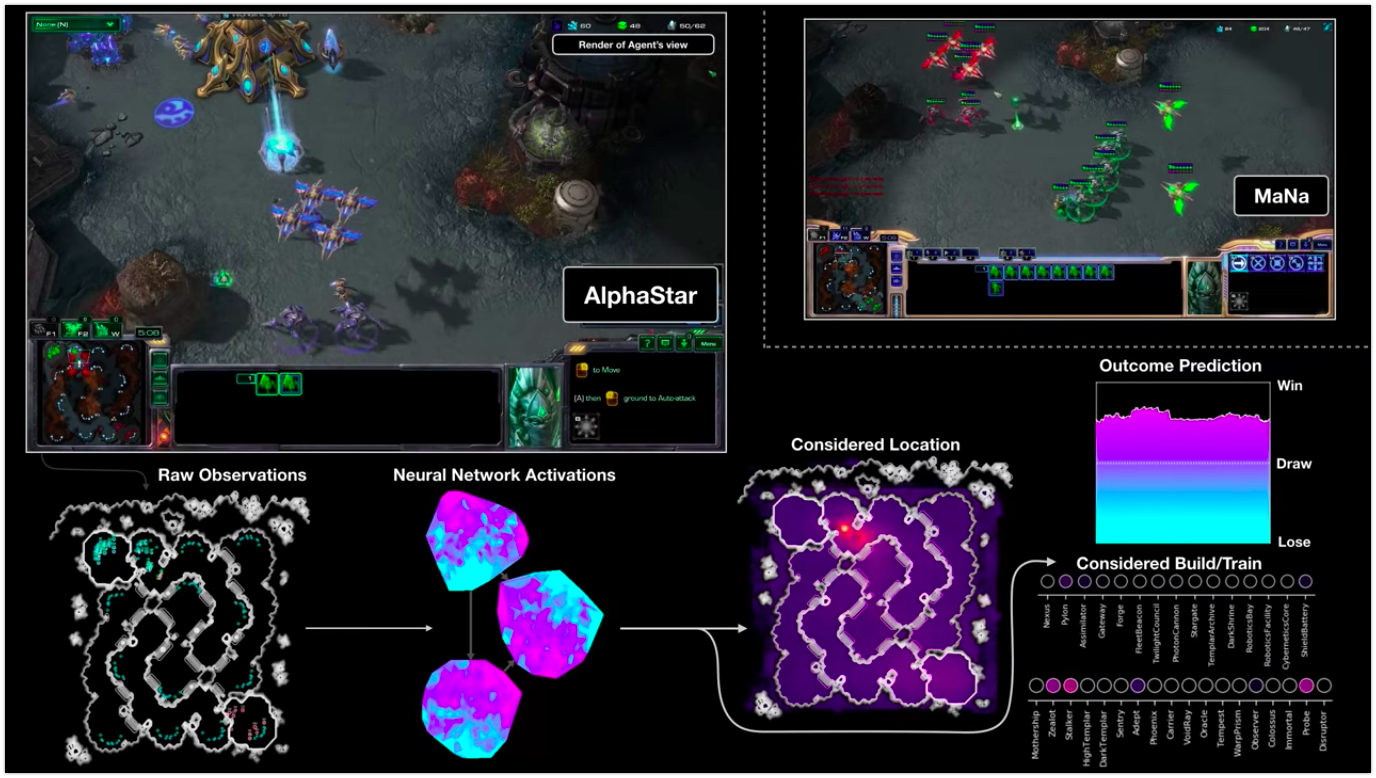
 La visualisation d'AlphaStar pendant la lutte contre MaNa montre le jeu pour le compte de l'agent - les données initiales observées, l'activité du réseau neuronal, certaines des actions proposées et les coordonnées requises, ainsi que le résultat estimé du match. La vue du joueur MaNa est également montrée, mais elle n'est bien sûr pas accessible à l'agent.
La visualisation d'AlphaStar pendant la lutte contre MaNa montre le jeu pour le compte de l'agent - les données initiales observées, l'activité du réseau neuronal, certaines des actions proposées et les coordonnées requises, ainsi que le résultat estimé du match. La vue du joueur MaNa est également montrée, mais elle n'est bien sûr pas accessible à l'agent.Comment est la formation
Le comportement AlphaStar est généré
par un réseau neuronal d' apprentissage en profondeur, qui reçoit des données brutes via l'interface (une liste d'unités et leurs propriétés) et donne une séquence d'instructions qui sont des actions dans le jeu. Plus spécifiquement, l'architecture du réseau neuronal utilise l'approche du "torse de
transformateur vers les unités, combiné avec un
noyau LSTM profond , une
tête de politique auto-régressive avec un
réseau de pointeurs et une
ligne de base de valeur centralisée "
(pour la précision des termes laissés sans traduction) . Nous pensons que ces modèles aideront à faire face à d'autres tâches importantes d'apprentissage automatique, y compris la modélisation de séquence à long terme et de grands espaces de sortie tels que la traduction, la modélisation du langage et les représentations visuelles.
AlphaStar utilise également le nouvel algorithme d'apprentissage multi-agents. Ce réseau de neurones a été initialement formé à l'aide d'une méthode d'apprentissage basée sur les enseignants basée sur des rediffusions anonymisées
disponibles via Blizzard. Cela a permis à AlphaStar d'étudier et de simuler les micro et macro-stratégies de base utilisées par les joueurs dans les tournois. Cet agent a vaincu le niveau d'IA intégré «Elite», ce qui équivaut au niveau d'un joueur dans la ligue d'or dans 95% des jeux de test.
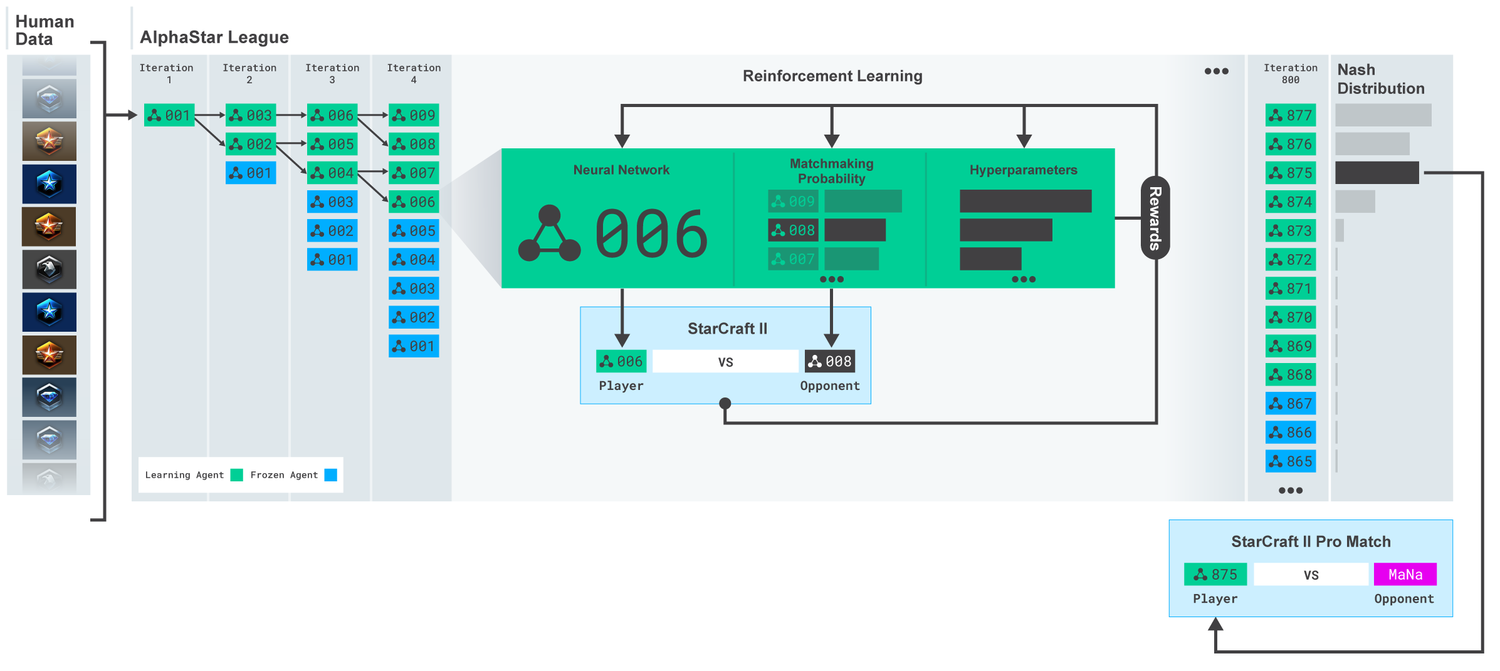 League AlphaStar. Les agents ont d'abord été formés sur la base de rediffusions de matches humains, puis sur la base de matchs compétitifs entre eux. À chaque itération, de nouveaux adversaires se ramifient et les originaux se figent. La probabilité de rencontrer d'autres adversaires et hyperparamètres détermine les objectifs d'apprentissage de chaque agent, ce qui augmente la complexité et conserve la diversité. Les paramètres de l'agent sont mis à jour avec une formation de renforcement basée sur le résultat du jeu contre les adversaires. L'agent final est sélectionné (sans remplacement) sur la base de la distribution Nash.
League AlphaStar. Les agents ont d'abord été formés sur la base de rediffusions de matches humains, puis sur la base de matchs compétitifs entre eux. À chaque itération, de nouveaux adversaires se ramifient et les originaux se figent. La probabilité de rencontrer d'autres adversaires et hyperparamètres détermine les objectifs d'apprentissage de chaque agent, ce qui augmente la complexité et conserve la diversité. Les paramètres de l'agent sont mis à jour avec une formation de renforcement basée sur le résultat du jeu contre les adversaires. L'agent final est sélectionné (sans remplacement) sur la base de la distribution Nash.Ces résultats sont ensuite utilisés pour lancer un processus d'apprentissage par renforcement multi-agents. Pour cela, une ligue a été créée où les agents adverses jouent les uns contre les autres, tout comme les gens acquièrent de l'expérience en jouant des tournois. De nouveaux rivaux ont été ajoutés par le biais de la ligue, par la duplication des agents actuels. Cette nouvelle forme d'apprentissage, empruntant quelques idées à la méthode d'apprentissage par renforcement avec des éléments d'algorithmes génétiques (
basés sur la population ), vous permet de créer un processus continu d'exploration du vaste espace stratégique du gameplay de StarCraft et d'être sûr que les agents sont capables de résister aux stratégies les plus puissantes, non oublier les anciens.
 Score MMR (Match Making Rating) - un indicateur approximatif de l'habileté du joueur. Pour les rivaux de la ligue AlphaStar pendant l'entraînement, par rapport aux ligues en ligne de Blizzard.
Score MMR (Match Making Rating) - un indicateur approximatif de l'habileté du joueur. Pour les rivaux de la ligue AlphaStar pendant l'entraînement, par rapport aux ligues en ligne de Blizzard.Au fur et à mesure que la ligue se développait et que de nouveaux agents étaient créés, des contre-stratégies apparaissaient capables de vaincre les précédentes. Alors que certains agents n'ont amélioré que les stratégies qu'ils avaient rencontrées auparavant, d'autres agents en ont créé de toutes nouvelles, notamment de nouveaux ordres de construction inhabituels, la composition des unités et la gestion des macros. Par exemple, au début, les «fromages» ont prospéré - précipitation rapide avec l'aide de
canons à photons ou de
templiers noirs . Mais au fur et à mesure que le processus d'apprentissage progressait, ces stratégies risquées ont été abandonnées, laissant la place à d'autres. Par exemple, la production d'un nombre excessif de travailleurs pour obtenir un afflux supplémentaire de ressources ou le don de deux
Oracles pour frapper les travailleurs de l'ennemi et saper son économie. Ce processus est similaire à la façon dont les joueurs réguliers ont découvert de nouvelles stratégies et vaincu les anciennes approches populaires, au cours des nombreuses années écoulées depuis la sortie de StarCraft.
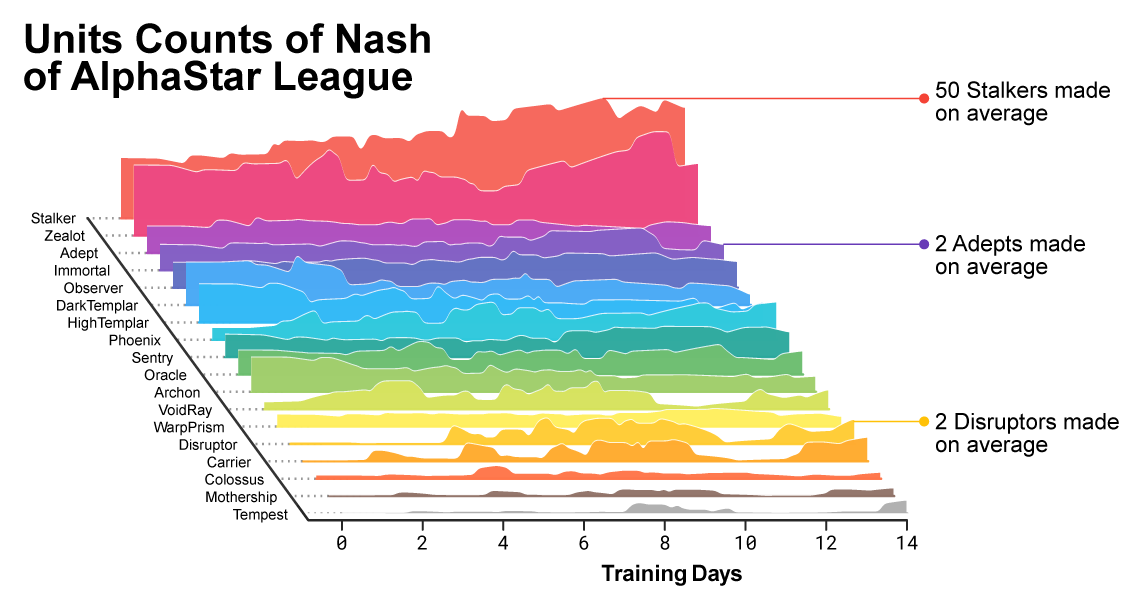 Au fur et à mesure que la formation progressait, il était évident que la composition des unités utilisées par les agents évoluait.
Au fur et à mesure que la formation progressait, il était évident que la composition des unités utilisées par les agents évoluait.Pour assurer la diversité, chaque agent était doté de son propre objectif d'apprentissage. Par exemple, quels adversaires cet agent devrait-il vaincre, ou toute autre motivation intrinsèque qui détermine le jeu de l'agent. Un certain agent peut avoir pour objectif de vaincre un adversaire spécifique, et l'autre toute une sélection d'adversaires, mais uniquement des unités spécifiques. Ces objectifs ont changé tout au long du processus d'apprentissage.
 Visualisation interactive (des fonctionnalités interactives sont disponibles dans l' article d'origine ), qui montre des rivaux avec la Ligue AlphaStar. L'agent qui a joué contre TLO et MaNa est marqué séparément.
Visualisation interactive (des fonctionnalités interactives sont disponibles dans l' article d'origine ), qui montre des rivaux avec la Ligue AlphaStar. L'agent qui a joué contre TLO et MaNa est marqué séparément.Les coefficients (poids) du réseau neuronal de chaque agent ont été mis à jour à l'aide d'un entraînement par renforcement basé sur des jeux avec des adversaires afin d'optimiser leurs objectifs d'apprentissage spécifiques. La règle pour la mise à jour du poids est un nouvel algorithme d'apprentissage efficace "algorithme d'apprentissage par renforcement
acteur-critique hors politique avec
relecture d'expérience ,
apprentissage par imitation de soi et
distillation de politique "
(pour la précision des termes laissés sans traduction) .
 L'image montre comment un agent (point noir), qui a été sélectionné à la suite du match contre MaNa, a développé sa stratégie par rapport aux adversaires (points colorés) dans le processus d'entraînement. Chaque point représente un adversaire dans la ligue. La position du point montre la stratégie et la taille - la fréquence avec laquelle il est choisi comme adversaire pour l'agent MaNa dans le processus d'apprentissage.
L'image montre comment un agent (point noir), qui a été sélectionné à la suite du match contre MaNa, a développé sa stratégie par rapport aux adversaires (points colorés) dans le processus d'entraînement. Chaque point représente un adversaire dans la ligue. La position du point montre la stratégie et la taille - la fréquence avec laquelle il est choisi comme adversaire pour l'agent MaNa dans le processus d'apprentissage.Pour former AlphaStar, nous avons créé un système distribué évolutif basé sur
Google TPU 3, qui fournit le processus de formation parallèle de toute une population d'agents avec des milliers de copies en cours d'exécution de StarCraft II. AlphaStar League a duré 14 jours en utilisant 16 TPU pour chaque agent. Au cours de la formation, chaque agent a accumulé jusqu'à 200 ans d'expérience en jouant à StarCraft en temps réel. La version finale d'AlphaStar Agent contient tous
les composants de
distribution de League
Nash . En d'autres termes, le mélange de stratégies le plus efficace découvert au cours des jeux. Et cette configuration peut être exécutée sur un GPU de bureau standard. Une description technique complète est en préparation pour publication dans une revue scientifique à comité de lecture.
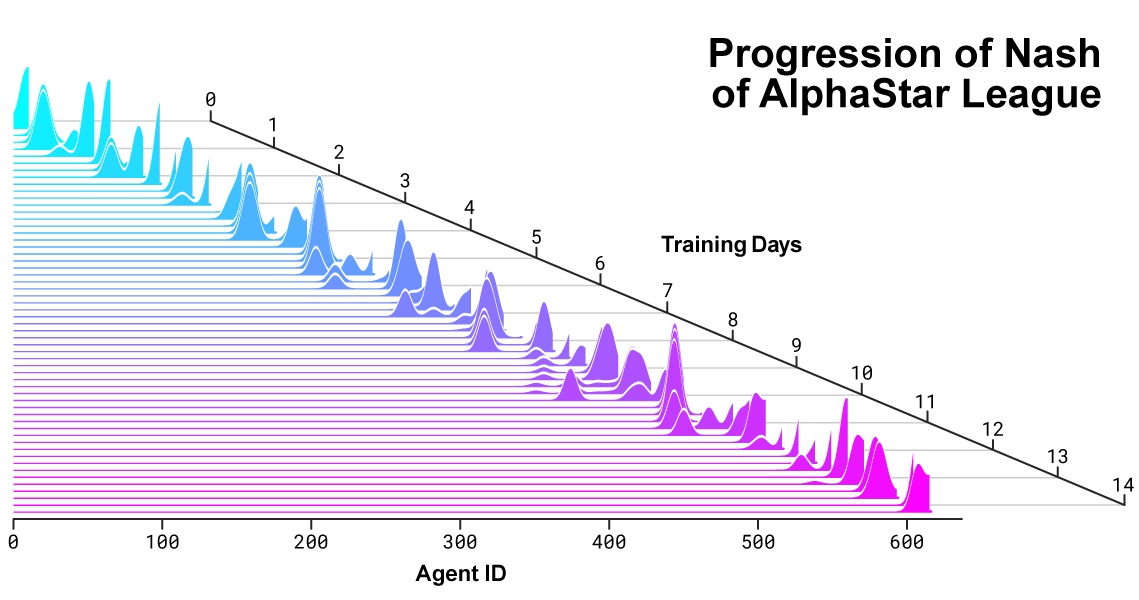 Répartition de Nash entre rivaux lors du développement de la ligue et de la création de nouveaux adversaires. La distribution Nash, qui est l'ensemble le moins exploitable de concurrents complémentaires, apprécie les nouveaux acteurs, démontrant ainsi une progression continue par rapport à tous les concurrents antérieurs.
Répartition de Nash entre rivaux lors du développement de la ligue et de la création de nouveaux adversaires. La distribution Nash, qui est l'ensemble le moins exploitable de concurrents complémentaires, apprécie les nouveaux acteurs, démontrant ainsi une progression continue par rapport à tous les concurrents antérieurs.Comment AlphaStar agit et voit le jeu
Les joueurs professionnels comme TLO ou MaNa peuvent effectuer des centaines d'actions par minute (
APM ). Mais c'est beaucoup moins que la plupart
des robots existants qui contrôlent indépendamment chaque unité et génèrent des milliers, voire des dizaines de milliers d'actions.
Dans nos matchs contre TLO et MaNa, AlphaStar a maintenu l'APM à une moyenne de 280, ce qui est beaucoup moins que celui des joueurs professionnels, bien que ses actions puissent être plus précises. Un APM si bas est dû en particulier au fait qu'AlphaStar a commencé à étudier sur la base de replays de joueurs ordinaires et a essayé d'imiter la manière de jouer humaine. De plus, AlphaStar réagit avec un délai entre l'observation et l'action d'une moyenne d'environ 350 ms.
 Distribution d'APM AlphaStar dans les matchs contre MaNa et TLO, et le délai global entre l'observation et l'action.
Distribution d'APM AlphaStar dans les matchs contre MaNa et TLO, et le délai global entre l'observation et l'action.Lors des matchs contre TLO et MaNa, AlphaStar a interagi avec le moteur de jeu StarCraft via l'interface brute, c'est-à-dire qu'il pouvait voir directement les attributs de ses unités ennemies visibles sur la carte, sans avoir à déplacer la caméra - jouez efficacement avec une vue réduite de l'ensemble du territoire . Contrairement à cela, les personnes vivantes doivent clairement gérer «l'économie de l'attention» afin de décider constamment où concentrer l'appareil photo. Cependant, une analyse des jeux AlphaStar révèle qu'il contrôle implicitement le focus. En moyenne, un agent change son contexte d'attention environ 30 fois par minute, comme MaNa et TLO.
De plus, nous avons développé la deuxième version d'AlphaStar. En tant que joueurs humains, cette version d'AlphaStar choisit clairement quand et où déplacer la caméra. Dans ce mode de réalisation, sa perception est limitée aux informations sur l'écran, et les actions sont également autorisées uniquement sur la zone visible de l'écran.
 Performances AlphaStar lors de l'utilisation de l'interface de base et de l'interface de la caméra. Le graphique montre que le nouvel agent travaillant avec la caméra atteint rapidement des performances comparables pour l'agent utilisant l'interface de base.
Performances AlphaStar lors de l'utilisation de l'interface de base et de l'interface de la caméra. Le graphique montre que le nouvel agent travaillant avec la caméra atteint rapidement des performances comparables pour l'agent utilisant l'interface de base.Nous avons formé deux nouveaux agents, l'un utilisant l'interface de base et l'autre censé apprendre à contrôler la caméra, en jouant contre la ligue AlphaStar. Chaque agent au début a été formé avec un enseignant basé sur des correspondances humaines, suivi d'une formation avec le renforcement décrit ci-dessus. La version AlphaStar, qui utilise l'interface de la caméra, a obtenu presque les mêmes résultats que la version avec l'interface de base, dépassant la marque 7000 MMR sur notre classement interne. Dans un match de démonstration, MaNa a vaincu le prototype AlphaStar à l'aide d'une caméra. Nous avons formé cette version seulement 7 jours. Nous espérons que nous serons en mesure d'évaluer une version entièrement formée avec une caméra dans un avenir proche.
Ces résultats montrent que le succès d'AlphaStar dans les matches contre MaNa et TLO est principalement le résultat d'une bonne gestion macro et micro, et pas seulement d'un taux de clics élevé, d'une réaction rapide ou d'un accès aux informations sur l'interface de base.
Résultats du jeu AlphaStar vs joueurs professionnels
StarCraft permet aux joueurs de choisir l'une des trois races - terrans, zerg ou protoss. Nous avons décidé qu'AlphaStar se spécialiserait actuellement dans une course en particulier, le protoss, afin de réduire le temps d'entraînement et les variations dans l'évaluation des résultats de notre ligue nationale. Mais il convient de noter qu'un processus d'apprentissage similaire peut être appliqué à n'importe quelle race. Nos agents ont été formés pour jouer à StarCraft II version 4.6.2 en mode protoss contre protoss sur la carte CatalystLE. Pour évaluer les performances d'AlphaStar, nous avons d'abord testé nos agents lors de matches contre TLO - un joueur professionnel pour les zergs et un joueur pour le niveau protoss «GrandMaster». AlphaStar a remporté des matchs avec un score de 5: 0, en utilisant un large éventail d'unités et de commandes. "J'ai été surpris de la force de l'agent", a-t-il déclaré. «AlphaStar adopte des stratégies bien connues et les bouleverse. L'agent a montré des stratégies auxquelles je n'ai jamais pensé. Et cela montre qu'il peut encore y avoir des façons de jouer qui ne sont pas encore complètement comprises. »
Après une semaine supplémentaire d'entraînement, nous avons joué contre MaNa, l'un des meilleurs joueurs de StarCraft II au monde et l'un des 10 meilleurs joueurs de protoss. AlphaStar a cette fois gagné 5-0, démontrant de solides compétences en micro-gestion et macro-stratégie. "J'ai été étonné de voir AlphaStar utiliser les approches les plus avancées et les différentes stratégies dans chaque jeu, montrant un style de jeu très humain que je ne m'attendais pas à voir", a-t-il déclaré. «J'ai réalisé à quel point mon style de jeu dépend de l'utilisation d'erreurs basées sur des réactions humaines. Et cela place le jeu à un tout autre niveau. Nous attendons tous avec enthousiasme de voir ce qui se passera ensuite. "
AlphaStar et autres problèmes difficiles
Malgré le fait que StarCraft n'est qu'un jeu, même s'il est très difficile, nous pensons que les techniques sous-jacentes à AlphaStar peuvent être utiles pour résoudre d'autres problèmes. Par exemple, ce type d'architecture de réseau de neurones est capable de simuler de très longues séquences d'actions probables, dans des jeux qui durent souvent jusqu'à une heure et contiennent des dizaines de milliers d'actions basées sur des informations incomplètes. Chaque trame dans StarCraft est utilisée comme une étape d'entrée. Dans ce cas, le réseau de neurones de chacune de ces étapes prédit la séquence d'actions attendue pour l'ensemble du jeu restant. La tâche fondamentale de faire des prévisions complexes pour de très longues séquences de données se trouve dans de nombreux problèmes du monde réel, tels que les prévisions météorologiques, la modélisation du climat, la compréhension de la langue, etc. Nous sommes très heureux de reconnaître l'énorme potentiel qui peut être appliqué dans ces domaines, en utilisant l'expérience que nous avons acquise dans le projet AlphaStar.
Nous pensons également que certaines de nos méthodes d'enseignement peuvent être utiles pour étudier la sécurité et la fiabilité de l'IA. L'un des problèmes les plus difficiles dans le domaine de l'IA est le nombre d'options dans lesquelles le système peut être erroné. , . AlphaStar, , . , - . , , , .
StarCraft - . , , ,
AlphaZero AlphaFold , représentent un pas en avant dans la mise en œuvre de notre mission de créer des systèmes intelligents qui nous aideront un jour à trouver des solutions aux problèmes scientifiques les plus complexes et fondamentaux.
11 rediffusions de tous les matchsVidéo du match de démonstration contre MaNaVidéo avec visualisation d'AlphaStar du deuxième match complet contre MaNa