
Une fois de plus, en conduisant une voiture dans ma ville natale et en faisant le tour d'une autre fosse, je me suis dit: de si bonnes routes existaient-elles partout dans notre pays et j'ai décidé que nous devrions évaluer objectivement la situation avec la qualité des routes dans notre pays.
Formalisation des tâches
En Russie, les exigences de qualité des routes sont décrites dans GOST R 50597-2017 «Routes et routes. Exigences pour l'état opérationnel acceptables dans les conditions de sécurité routière. Méthodes de contrôle. " Ce document définit les exigences pour couvrir la chaussée, les bords de route, les bandes de séparation, les trottoirs, les voies piétonnes, etc., et établit également les types de dommages.
Étant donné que la tâche de déterminer tous les paramètres des routes est assez vaste, j'ai décidé de le réduire pour moi-même et de me concentrer uniquement sur le problème de la détermination des défauts dans la couverture de la chaussée. Dans GOST R 50597-2017, les défauts suivants dans le revêtement de la chaussée sont distingués:
- nids de poule
- les pauses
- rabattements
- quarts
- peignes
- suivre
- liant transpirant
J'ai décidé de m'attaquer à ces défauts.
Collecte de données
Où puis-je obtenir des photographies qui représentent des sections suffisamment grandes de la chaussée, et même en référence à la géolocalisation? La réponse est venue en strass - panoramas sur les cartes de Yandex (ou Google), cependant, après un peu de recherche, j'ai trouvé plusieurs autres options alternatives:
- émission de moteurs de recherche d'images pour les demandes pertinentes;
- photos sur des sites pour recevoir des plaintes (Rosyama, citoyen en colère, vertu, etc.)
- Opendatascience a incité un projet à détecter les défauts de la route avec un ensemble de données marqué - github.com/sekilab/RoadDamageDetector
Malheureusement, une analyse de ces options a montré qu'elles ne me convenaient pas très bien: l'émission de moteurs de recherche a beaucoup de bruit (beaucoup de photos qui ne sont pas des routes, différents rendus, etc.), les photos des sites pour recevoir des plaintes ne contiennent que des photos avec de grandes violations de la surface asphaltée , il y a pas mal de photos avec de petites violations de couverture et sans violations sur ces sites, l'ensemble de données du projet RoadDamageDetector est collecté au Japon et ne contient pas d'échantillons avec de grandes violations de couverture, ainsi que des routes sans couverture du tout.
Étant donné que les options alternatives ne conviennent pas, nous utiliserons des panoramas Yandex (j'ai exclu l'option panorama Google, car le service est présenté dans moins de villes en Russie et est mis à jour moins fréquemment). Il a décidé de collecter des données dans les villes de plus de 100 000 habitants, ainsi que dans les centres fédéraux. J'ai fait une liste de noms de villes - il y en avait 176, plus tard il s'avère que seulement 149 d'entre elles ont des panoramas. Je ne vais pas me plonger dans les fonctionnalités de l'analyse des tuiles, je dirai qu'au final, j'ai obtenu 149 dossiers (un pour chaque ville) dans lesquels il y avait au total 1,7 million de photos. Par exemple, pour Novokuznetsk, le dossier ressemblait à ceci:

Par le nombre de photos téléchargées, les villes étaient réparties comme suit:
TableVille
| Nombre de photos, pcs
|
|---|
Moscou
| 86048
|
Saint-Pétersbourg
| 41376
|
Saransk
| 18880
|
Podolsk
| 18560
|
Krasnogorsk
| 18208
|
Lyubertsy
| 17760
|
Kaliningrad
| 16928
|
Kolomna
| 16832
|
Mytishchi
| 16192
|
Vladivostok
| 16096
|
Balashikha
| 15968
|
Petrozavodsk
| 15968
|
Ekaterinbourg
| 15808
|
Veliky Novgorod
| 15744
|
Naberezhnye Chelny
| 15680
|
Krasnodar
| 15520
|
Nizhny Novgorod
| 15488
|
Khimki
| 15296
|
Tula
| 15296
|
Novossibirsk
| 15264
|
Tver
| 15200
|
Miass
| 15104
|
Ivanovo
| 15072
|
Vologda
| 15008
|
Joukovski
| 14976
|
Kostroma
| 14912
|
Samara
| 14880
|
Korolev
| 14784
|
Kaluga
| 14720
|
Cherepovets
| 14720
|
Sébastopol
| 14688
|
Pushkino
| 14528
|
Yaroslavl
| 14464
|
Oulianovsk
| 14400
|
Rostov-sur-le-Don
| 14368
|
Domodedovo
| 14304
|
Kamensk-Uralsky
| 14208
|
Pskov
| 14144
|
Yoshkar-Ola
| 14080
|
Kerch
| 14080
|
Mourmansk
| 13920
|
Togliatti
| 13920
|
Vladimir
| 13792
|
Aigle
| 13792
|
Syktyvkar
| 13728
|
Dolgoprudny
| 13696
|
Khanty-Mansiysk
| 13664
|
Kazan
| 13600
|
Engels
| 13440
|
Arkhangelsk
| 13280
|
Bryansk
| 13216
|
Omsk
| 13120
|
Syzran
| 13088
|
Krasnoyarsk
| 13056
|
Shchelkovo
| 12928
|
Penza
| 12864
|
Chelyabinsk
| 12768
|
Cheboksary
| 12768
|
Nizhny Tagil
| 12672
|
Stavropol
| 12672
|
Ramenskoye
| 12640
|
Irkoutsk
| 12608
|
Angarsk
| 12608
|
Tyumen
| 12512
|
Odintsovo
| 12512
|
Ufa
| 12512
|
Magadan
| 12512
|
Perm
| 12448
|
Kirov
| 12256
|
Nizhnekamsk
| 12224
|
Makhachkala
| 12096
|
Nizhnevartovsk
| 11936
|
Koursk
| 11904
|
Sotchi
| 11872
|
Tambov
| 11840
|
Pyatigorsk
| 11808
|
Volgodonsk
| 11712
|
Ryazan
| 11680
|
Saratov
| 11616
|
Dzerzhinsk
| 11456
|
Orenburg
| 11456
|
Monticule
| 11424
|
Volgograd
| 11264
|
Izhevsk
| 11168
|
Chrysostome
| 11136
|
Lipetsk
| 11072
|
Kislovodsk
| 11072
|
Surgut
| 11040
|
Magnitogorsk
| 10912
|
Smolensk
| 10784
|
Khabarovsk
| 10752
|
Kopeysk
| 10688
|
Maykop
| 10656
|
Petropavlovsk-Kamchatsky
| 10624
|
Taganrog
| 10560
|
Barnaul
| 10528
|
Sergiev Posad
| 10368
|
Elista
| 10304
|
Sterlitamak
| 9920
|
Simferopol
| 9824
|
Tomsk
| 9760
|
Orekhovo-Zuevo
| 9728
|
Astrakhan
| 9664
|
Evpatoria
| 9568
|
Noginsk
| 9344
|
Chita
| 9216
|
Belgorod
| 9120
|
Biysk
| 8928
|
Rybinsk
| 8896
|
Severodvinsk
| 8832
|
Voronezh
| 8768
|
Blagoveshchensk
| 8672
|
Novorossiysk
| 8608
|
Ulan-Ude
| 8576
|
Serpukhov
| 8320
|
Komsomolsk-on-Amur
| 8192
|
Abakan
| 8128
|
Norilsk
| 8096
|
Yuzhno-Sakhalinsk
| 8032
|
Obninsk
| 7904
|
Essentuki
| 7712
|
Bataysk
| 7648
|
Volzhsky
| 7584
|
Novocherkassk
| 7488
|
Berdsk
| 7456
|
Arzamas
| 7424
|
Pervouralsk
| 7392
|
Kemerovo
| 7104
|
Elektrostal
| 6720
|
Derbent
| 6592
|
Yakutsk
| 6528
|
Murom
| 6240
|
Nefteyugansk
| 5792
|
Reutov
| 5696
|
Birobidzhan
| 5440
|
Novokuybyshevsk
| 5248
|
Salekhard
| 5184
|
Novokuznetsk
| 5152
|
Novy Urengoy
| 4736
|
Noyabrsk
| 4416
|
Novocheboksarsk
| 4352
|
Yelets
| 3968
|
Kaspiysk
| 3936
|
Stary Oskol
| 3840
|
Artyom
| 3744
|
Zheleznogorsk
| 3584
|
Salavat
| 3584
|
Prokopyevsk
| 2816
|
Gorno-Altaysk
| 2464
|
Préparation d'un ensemble de données pour la formation
Et donc, l'ensemble de données est assemblé, comment maintenant, en ayant une photo de la section de la route et des objets qui l'entourent, découvrez la qualité de l'asphalte représenté dessus? J'ai décidé de découper un morceau de la photo mesurant 350 * 244 pixels au centre de la photo originale juste en dessous du milieu. Réduisez ensuite le morceau coupé horizontalement à une taille de 244 pixels. L'image résultante (taille 244 * 244) sera l'entrée pour l'encodeur convolutionnel:

Afin de mieux comprendre les données que je traite, les 2000 premières photos que j'ai tracées moi-même, les autres photos ont été balisées par les employés de Yandex.Tolki. Devant eux, j'ai posé une question dans le libellé suivant.
Indiquez la surface de la route que vous voyez sur la photo:
- Sol / décombres
- Pavés, tuiles, trottoirs
- Rails, voies ferrées
- Eau, grosses flaques d'eau
- Asphalte
- Il n'y a pas de route sur la photo / Objets étrangers / La couverture n'est pas visible à cause des voitures
Si l'interprète a choisi «Asphalte», un menu est apparu qui proposait d'évaluer sa qualité:
- Excellente couverture
- Légères fissures simples / nids de poule simples peu profonds
- Grandes fissures / fissures de grille / nids de poule mineurs simples
- Grands nids de poule / nids de poule profonds / revêtement détruit
Comme le montrent les tests des tâches, les interprètes de Y. Toloki ne diffèrent pas dans l'intégrité du travail - ils cliquent accidentellement sur les champs avec la souris et considèrent que la tâche est terminée. J'ai dû ajouter des questions de contrôle (dans la mission, il y avait 46 photographies, dont 12 étaient des contrôles) et permettre une acceptation retardée. Comme questions de contrôle, j'ai utilisé ces images que j'ai tracées moi-même. J'ai automatisé l'acceptation différée - Y. Toloka vous permet de télécharger les résultats du travail dans un fichier CSV et de charger les résultats de la vérification des réponses. La vérification des réponses a fonctionné comme suit - si la tâche contient plus de 5% de réponses incorrectes aux questions de contrôle, alors elle est considérée comme non satisfaite. De plus, si l'entrepreneur a indiqué une réponse qui est logiquement proche de la vérité, sa réponse est considérée comme correcte.
En conséquence, j'ai obtenu environ 30 000 photos étiquetées, que j'ai décidé de distribuer en trois classes pour la formation:
- «Bon» - photos étiquetées «Asphalte: excellent revêtement» et «Asphalte: petites fissures simples»
- «Milieu» - photos étiquetées «Pavés, carreaux, trottoirs», «Rails, voies ferrées» et «Asphalte: grandes fissures / fissures de la grille / simples bosses mineures»
- «Grand» - photos intitulées «Sol / Pierre concassée», «Eau, grandes flaques d'eau» et «Asphalte: un grand nombre de nids de poule / Nids de poule profonds / Chaussée détruite»
- Photos taguées "Il n'y a pas de route sur la photo / Objets étrangers / La couverture n'est pas visible à cause des voitures" il y en avait très peu (22 pcs.) Et je les ai exclus des travaux ultérieurs
Développement et formation des classificateurs
Ainsi, les données sont collectées et étiquetées, nous procédons au développement du classificateur. Habituellement, pour les tâches de classification d'images, en particulier lors de la formation sur de petits ensembles de données, un codeur convolutionnel prêt à l'emploi est utilisé, à la sortie duquel un nouveau classificateur est connecté. J'ai décidé d'utiliser un classificateur simple sans couche cachée, une couche d'entrée de taille 128 et une couche de sortie de taille 3. J'ai décidé d'utiliser immédiatement plusieurs options prêtes à l'emploi formées sur ImageNet comme encodeurs:
- Xception
- Resnet
- Création
- Vgg16
- Densenet121
- Mobilenet
Voici la fonction qui crée le modèle Keras avec l'encodeur donné:
def createModel(typeModel): conv_base = None if(typeModel == "nasnet"): conv_base = keras.applications.nasnet.NASNetMobile(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "xception"): conv_base = keras.applications.xception.Xception(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "resnet"): conv_base = keras.applications.resnet50.ResNet50(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "inception"): conv_base = keras.applications.inception_v3.InceptionV3(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "densenet121"): conv_base = keras.applications.densenet.DenseNet121(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "mobilenet"): conv_base = keras.applications.mobilenet_v2.MobileNetV2(include_top=False, input_shape=(224,224,3), weights='imagenet') if(typeModel == "vgg16"): conv_base = keras.applications.vgg16.VGG16(include_top=False, input_shape=(224,224,3), weights='imagenet') conv_base.trainable = False model = Sequential() model.add(conv_base) model.add(Flatten()) model.add(Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.0002))) model.add(Dropout(0.3)) model.add(Dense(3, activation='softmax')) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
Pour la formation, j'ai utilisé un générateur avec augmentation (puisque les possibilités de l'augmentation intégrée à Keras me semblaient insuffisantes, j'ai alors utilisé la bibliothèque
Augmentor ):
- Pistes
- Distorsion aléatoire
- Tours
- Échange de couleur
- Quart de travail
- Modifier le contraste et la luminosité
- Ajout de bruit aléatoire
- Recadrer
Après l'augmentation, les photos ressemblaient à ceci:

Code générateur:
def get_datagen(): train_dir='~/data/train_img' test_dir='~/data/test_img' testDataGen = ImageDataGenerator(rescale=1. / 255) train_generator = datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=16, class_mode='categorical') p = Augmentor.Pipeline(train_dir) p.skew(probability=0.9) p.random_distortion(probability=0.9,grid_width=3,grid_height=3,magnitude=8) p.rotate(probability=0.9, max_left_rotation=5, max_right_rotation=5) p.random_color(probability=0.7, min_factor=0.8, max_factor=1) p.flip_left_right(probability=0.7) p.random_brightness(probability=0.7, min_factor=0.8, max_factor=1.2) p.random_contrast(probability=0.5, min_factor=0.9, max_factor=1) p.random_erasing(probability=1,rectangle_area=0.2) p.crop_by_size(probability=1, width=244, height=244, centre=True) train_generator = keras_generator(p,batch_size=16) test_generator = testDataGen.flow_from_directory( test_dir, target_size=img_size, batch_size=32, class_mode='categorical') return (train_generator, test_generator)
Le code montre que l'augmentation n'est pas utilisée pour les données de test.
Ayant un générateur réglé, vous pouvez commencer à former le modèle, nous le réaliserons en deux étapes: d'abord, former uniquement notre classificateur, puis complètement le modèle entier.
def evalModelstep1(typeModel): K.clear_session() gc.collect() model=createModel(typeModel) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=4, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, ) return model def evalModelstep2(model): early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3) model.layers[0].trainable=True model.trainable=True model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss='binary_crossentropy', metrics=['accuracy']) traiGen,testGen=getDatagen() model.fit_generator(generator=traiGen, epochs=25, steps_per_epoch=30000/16, validation_steps=len(testGen), validation_data=testGen, callbacks=[early_stopping_callback] ) return model def full_fit(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] for model_name in model_names: print("#########################################") print("#########################################") print("#########################################") print(model_name) print("#########################################") print("#########################################") print("#########################################") model = evalModelstep1(model_name) model = evalModelstep2(model) model.save("~/data/models/model_new_"+str(model_name)+".h5")
Appelez full_fit () et attendez. Nous attendons depuis longtemps.
En conséquence, nous aurons six modèles formés, nous vérifierons l'exactitude de ces modèles sur une partie distincte des données étiquetées; j'ai reçu ce qui suit:
Nom du modèle
| Précision%
|
Xception
| 87,3
|
Resnet
| 90,8
|
Création
| 90,2
|
Vgg16
| 89,2
|
Densenet121
| 90,6
|
Mobilenet
| 86,5
|
En général, pas beaucoup, mais avec un si petit échantillon de formation, on ne peut pas s'attendre à plus. Pour augmenter légèrement la précision, j'ai combiné les sorties des modèles en faisant la moyenne:
def create_meta_model(): model_names=[ "xception", "resnet", "inception", "vgg16", "densenet121", "mobilenet" ] model_input = Input(shape=(244,244,3)) submodels=[] i=0; for model_name in model_names: filename= "~/data/models/model_new_"+str(model_name)+".h5" submodel = keras.models.load_model(filename) submodel.name = model_name+"_"+str(i) i+=1 submodels.append(submodel(model_input)) out=average(submodels) model = Model(inputs = model_input,outputs=out) model.compile(optimizer=keras.optimizers.Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy']) return model
La précision résultante était de 91,3%. Sur ce résultat, j'ai décidé d'arrêter.
Utilisation de Classifier
Enfin le classifieur est prêt et il peut être mis en action! Je prépare les données d'entrée et lance le classificateur - un peu plus d'une journée et 1,7 million de photos ont été traitées. Maintenant, la partie amusante est les résultats. Amenez immédiatement les dix premières et dix dernières villes dans le nombre relatif de routes avec une bonne couverture:

Tableau complet (image cliquable) Et voici la cote de qualité des routes par sujets fédéraux:
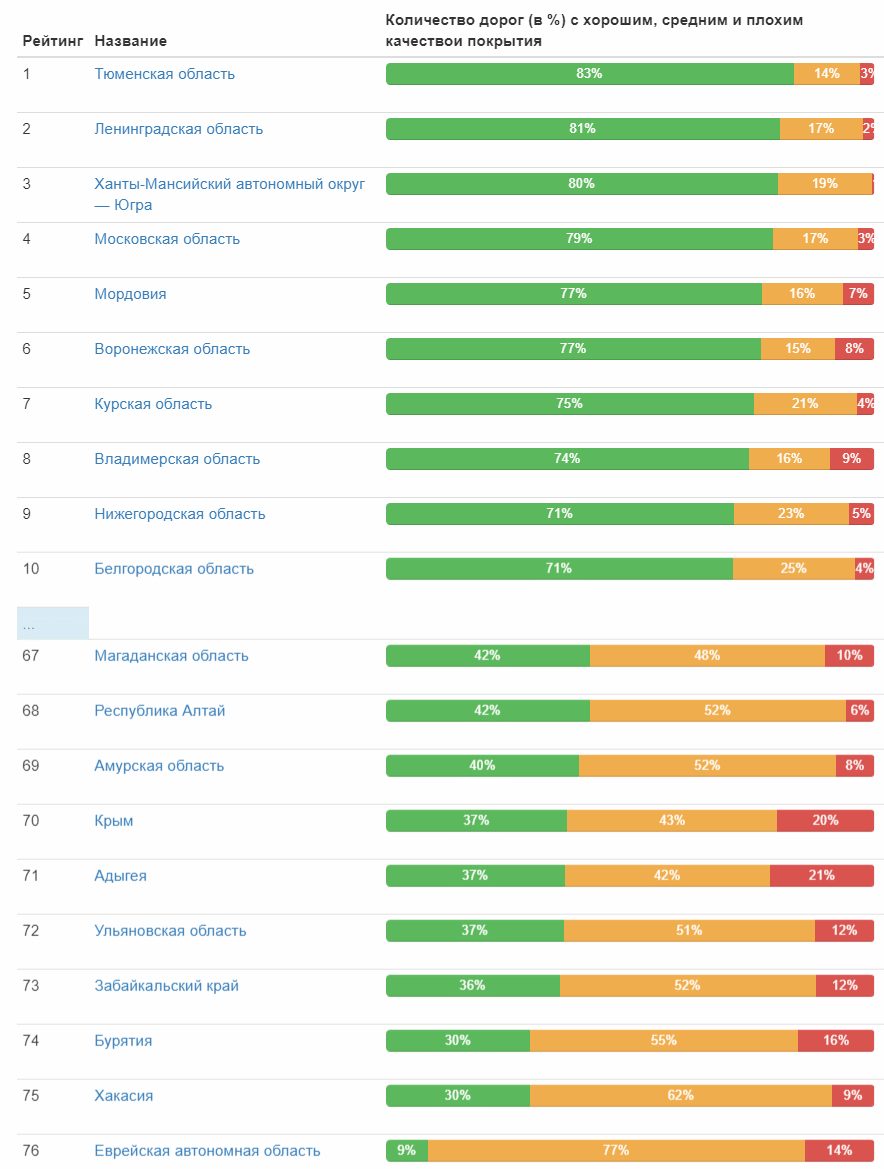
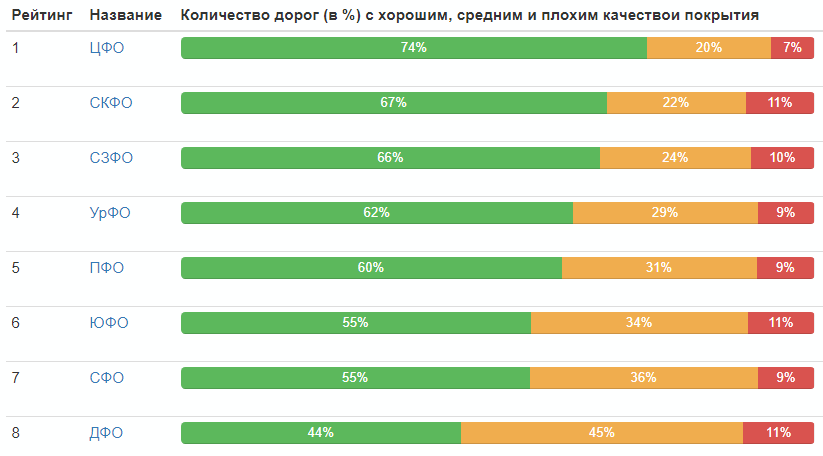
Évaluation par les districts fédéraux:
Répartition de la qualité des routes en Russie dans son ensemble:

Eh bien, c'est tout, tout le monde peut tirer des conclusions lui-même.
Enfin, je donnerai les meilleures photos de chaque catégorie (qui ont reçu la valeur maximale dans leur classe):
PS Dans les commentaires, a souligné à juste titre le manque de statistiques sur les années de réception des photographies. Je corrige et donne un tableau:
Année
| Nombre de photos, pcs
|
| 2008 | 37 |
| 2009 | 13 |
| 2010 | 157030 |
| 2011 | 60724 |
| 2012 | 42387 |
| 2013 | 12148
|
| 2014 | 141021
|
| 2015 | 46143
|
| 2016 | 410385
|
| 2017 | 324279
|
| 2018 | 581961
|