Numéros de latence que chaque programmeur devrait connaître - un tableau des «retards que chaque programmeur devrait connaître». Il contient les valeurs moyennes de temps pour effectuer des opérations informatiques de base en 2012. Il existe plusieurs vues alternatives pour ce tableau, et en voici une.
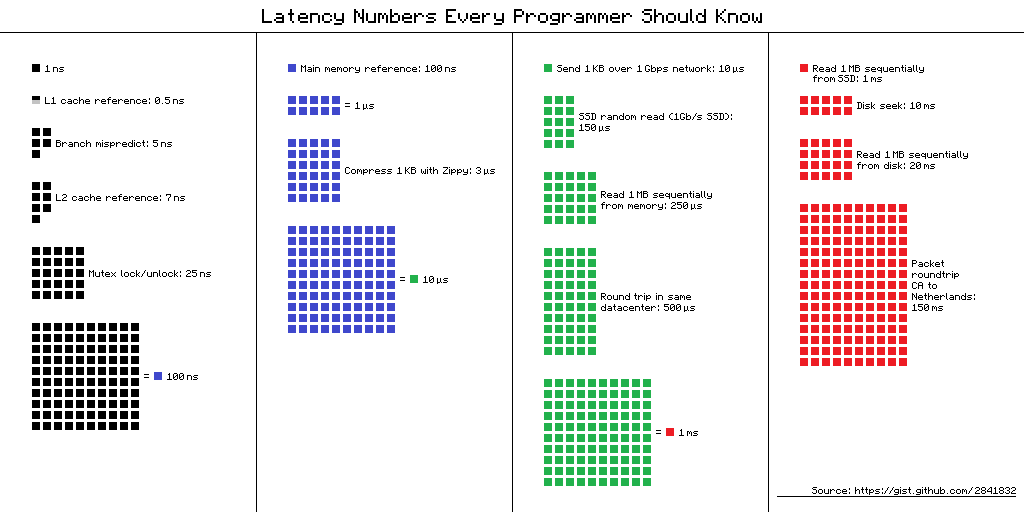 Lien vers la source du schéma
Lien vers la source du schémaMais quel est l'avantage pour les développeurs mobiles de ces informations en 2019? Il semble que non, mais
Dmitry Kurkin (
SClown ) de l'équipe Yandex.Navigator a pensé: "A quoi ressemblerait la table pour un iPhone moderne?" Ce qui en est
ressorti , dans une version texte révisée du rapport de Dmitry sur
AppsConf .
À quoi ça sert?
Pourquoi les programmeurs devraient-ils connaître ces chiffres? Et sont-ils pertinents pour les développeurs mobiles? Il y a deux tâches principales qui peuvent être résolues à l'aide de ces chiffres.
Comprendre l'échelle de temps d'un ordinateur
Prenez une situation simple - une conversation téléphonique. Nous pouvons facilement dire quand ce processus est rapide et quand il est long: quelques secondes est très rapide, quelques minutes est une conversation moyenne et une heure ou plus est très longue. Le chargement des pages est similaire: en moins d'une seconde - rapidement, quelques secondes - supportable, et une minute est un désastre, l'utilisateur peut ne pas attendre le téléchargement.
Mais qu'en est-il des opérations telles que l'ajout d'un numéro à un tableau - l'insertion très rapide dont les gens aiment parfois parler lors des entretiens? Combien cela prend-il sur un smartphone? Nanosecondes, microsecondes ou millisecondes? J'ai rencontré peu de gens qui pouvaient dire qu'une milliseconde, c'est long, mais dans notre cas, c'est le cas.
Le rapport de la vitesse de divers composants informatiques
Le temps d'exécution des opérations sur divers appareils peut varier de plusieurs dizaines ou centaines de fois. Par exemple, le temps d'accès à la mémoire principale est 100 fois différent de l'accès au cache L1. C'est une grande différence, mais pas infinie. Si nous avons une signification spécifique pour cela, alors lors de l'optimisation de nos applications, nous pouvons évaluer s'il y aura un gain de temps ou non.

"Chiffres de latence" dans la vraie vie
Quand j'ai vu ces chiffres, je me suis intéressé à la différence entre le cache et l'accès à la mémoire. Si je mets soigneusement mes données dans 64 Ko, ce qui n'est pas si petit, alors mon code fonctionnera 100 fois plus vite - c'est rapide, tout volera!

J'ai immédiatement voulu vérifier tout cela, le montrer à mes collègues et l'appliquer dans la mesure du possible. J'ai décidé de commencer avec l'outil standard qu'Apple propose - XCTest avec MeasureBlock. Le test s'est organisé comme suit: a alloué un tableau, l'a rempli de nombres, leur XOR'il et a répété l'algorithme 10 fois, c'est sûr. Après cela, j'ai regardé combien de temps cela prend pour un élément.
| Taille du tampon | Durée totale | Temps pour la chirurgie |
| 50 kb | 1,5 ms | 30 ns |
| 500 kb | 12 ms | 24 ns |
| 5000 kb | 85 ms | 17 ns |
La taille du tampon a augmenté 100 fois, et le temps pour l'opération non seulement n'a pas augmenté 100 fois, mais a diminué presque 2 fois.
Messieurs, officiers, ils nous ont trahis?!Après un tel résultat, de grands doutes ont surgi en moi que ces chiffres peuvent être vus dans la vraie vie. Il peut ne pas être possible pour une application régulière de détecter cette différence. Ou peut-être que sur la plate-forme mobile, tout est différent.
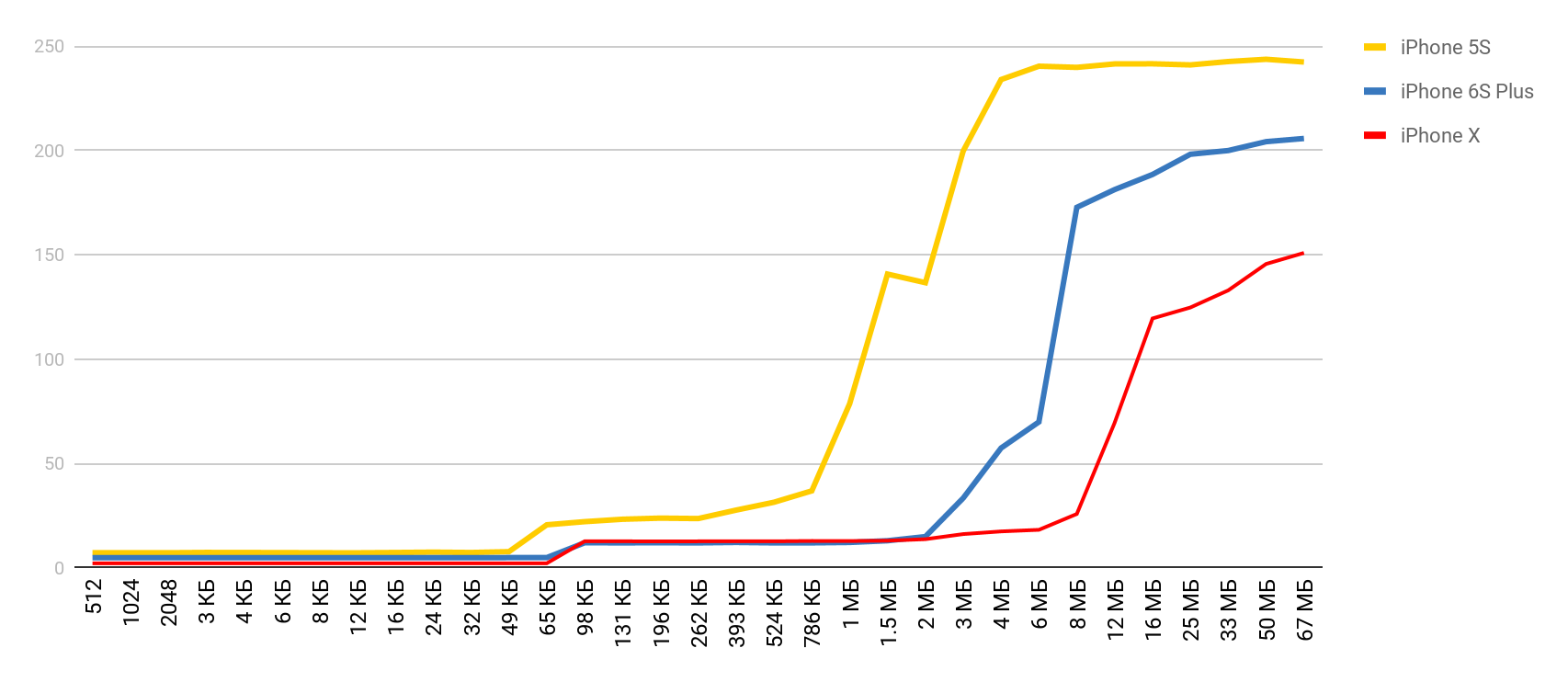
J'ai commencé à chercher un moyen de voir la différence de performances entre les caches et la mémoire principale. Au cours de la recherche, je suis tombé sur un article où l'auteur se plaignait d'avoir un benchmark en cours d'exécution sur son Mac et iPhone et n'a pas montré ces retards. J'ai pris cet outil et j'ai obtenu le résultat - comme dans une pharmacie. Le temps d'accès à la mémoire augmentait assez clairement lorsque la taille du tampon dépassait la taille du cache correspondant.
 LMbench
LMbench m'a aidé à obtenir ces résultats. Il s'agit d'une référence créée par Larry McVoy, l'un des développeurs du noyau Linux, qui vous permet de mesurer le temps d'accès à la mémoire, le coût de commutation des threads et des opérations du système de fichiers, et même le temps que prennent les opérations du processeur principal: addition, soustraction, etc. Selon cette référence Texas Instruments a présenté
des données de mesure
intéressantes pour ses processeurs. LMBench est écrit en C, il n'a donc pas été difficile de l'exécuter sur iOS.
Coûts de la mémoire
Armé d'un outil aussi merveilleux, j'ai décidé de faire des mesures similaires, mais pour un appareil mobile réel - pour l'iPhone. Les principales mesures ont été effectuées sur le 5S, puis j'ai obtenu les résultats alors que d'autres appareils tombaient entre mes mains. Par conséquent, si le périphérique n'est pas spécifié, il s'agit de 5S.
Accès mémoire
Pour ce test, un tableau spécial est utilisé, qui est rempli d'éléments qui se référencent. Chacun des éléments est un pointeur vers un autre élément. Le tableau n'est pas traversé par un index, mais par des transitions d'un nœud à un autre. Ces éléments sont dispersés à travers le tableau de sorte que, lors de l'accès à un nouvel élément, le plus souvent possible, il n'était pas dans le cache, mais déchargé de la RAM. Cet arrangement interfère autant que possible avec les caches.
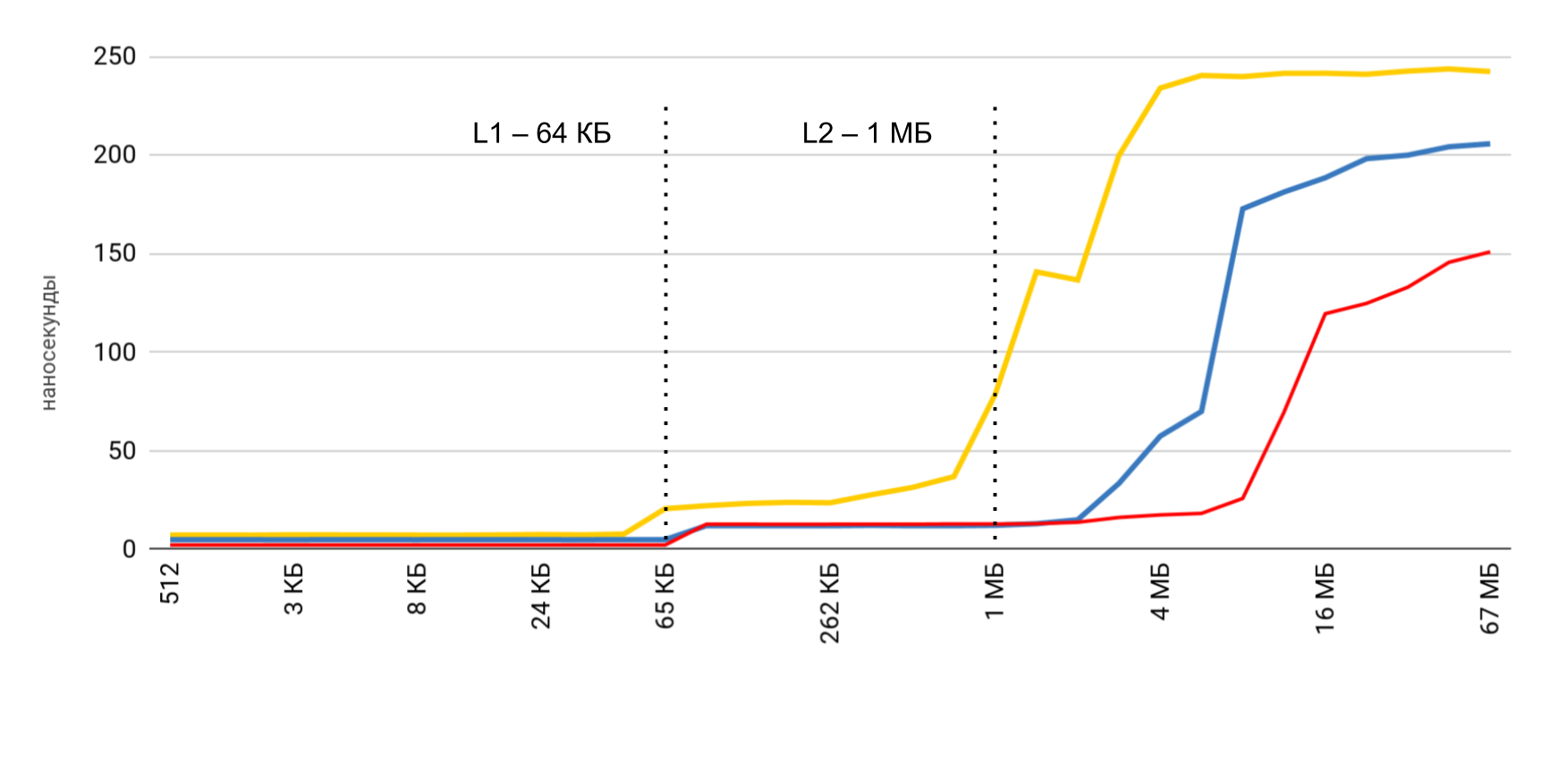
Vous avez déjà vu le résultat préliminaire. Dans le cas du cache L1, c'est moins de 10 nanosecondes, pour L2 c'est quelques dizaines de nanosecondes, et dans le cas de la mémoire principale, le temps passe à des centaines de nanosecondes.
Vitesse de lecture et d'écriture
Trois opérations principales sont mesurées:
- lecture ( p [i] + ) - nous lisons les éléments et les ajoutons au montant total;
- record ( p [i] = 1 ) - un nombre constant est écrit dans chaque élément;
- lecture et écriture ( p [i] = p [i] * 2 ) - nous retirons l'élément, le modifions et réécrivons la nouvelle valeur.
Lorsque vous travaillez avec le tampon, 2 approches sont utilisées: dans le premier cas, seul un quatrième élément est utilisé et dans le second, tous les éléments sont séquentiellement.
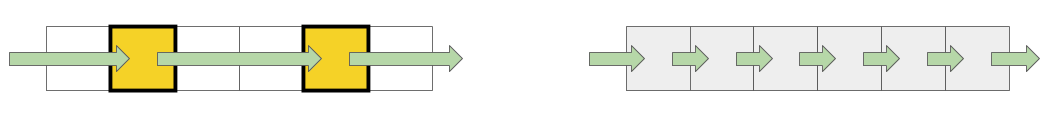
La vitesse la plus élevée est obtenue avec une petite taille de tampon, puis il y a des étapes claires, selon les tailles des caches L1 et L2. La chose la plus intéressante est que lorsque les données sont lues séquentiellement, aucune réduction de vitesse ne se produit. Mais dans le cas des passes, des étapes claires sont visibles.
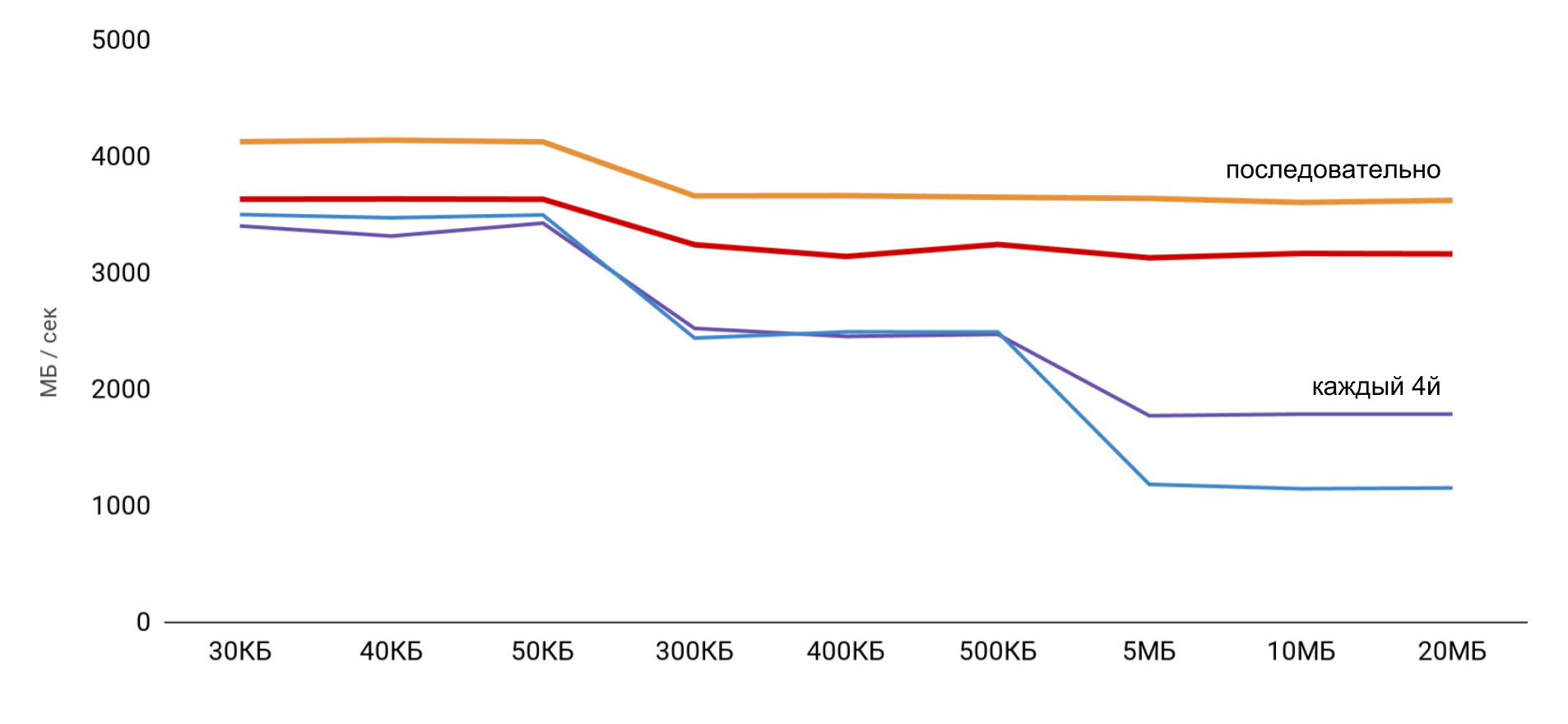
Pendant la lecture séquentielle, le système d'exploitation parvient à charger les données nécessaires dans le cache, donc pour toute taille de tampon, je n'ai pas besoin d'accéder à la mémoire - toutes les données nécessaires sont obtenues à partir du cache. Cela explique pourquoi je n'ai pas vu la différence de temps dans mon test de base.
Les résultats des mesures des opérations de lecture et d'écriture ont montré que dans une application normale, il est assez difficile d'obtenir l'accélération estimée de 100 fois. D'une part, le système lui-même cache assez bien les données, et même avec de grands tableaux, nous sommes très susceptibles de trouver des données dans le cache. Et d'autre part, travailler avec diverses variables peut facilement nécessiter un accès à la mémoire et la perte de centaines de nanosecondes gagnées.
| L1 | L2 | La mémoire |
| Numéros de latence | 1 ns | 7 ns | 100 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns |
| iPhone X | 2 ns | 12 ns | 146 ns |
Coûts d'enfilage
Ensuite, je voulais obtenir des données similaires pour travailler avec des threads afin de
comprendre le coût de l'utilisation du multithreading : combien cela coûte-t-il de créer un thread et de passer d'un thread à un autre. Pour nous, ce sont des opérations fréquentes, et je veux comprendre la perte.
Instruments. Trace système
System Trace aide beaucoup à suivre le travail des threads dans l'application. Cet outil a été décrit en détail lors de la
WWDC 2016 . L'outil permet de voir les transitions par conditions de flux et présente des données sur les flux dans trois catégories principales: les appels système, l'utilisation de la mémoire et les conditions de flux.
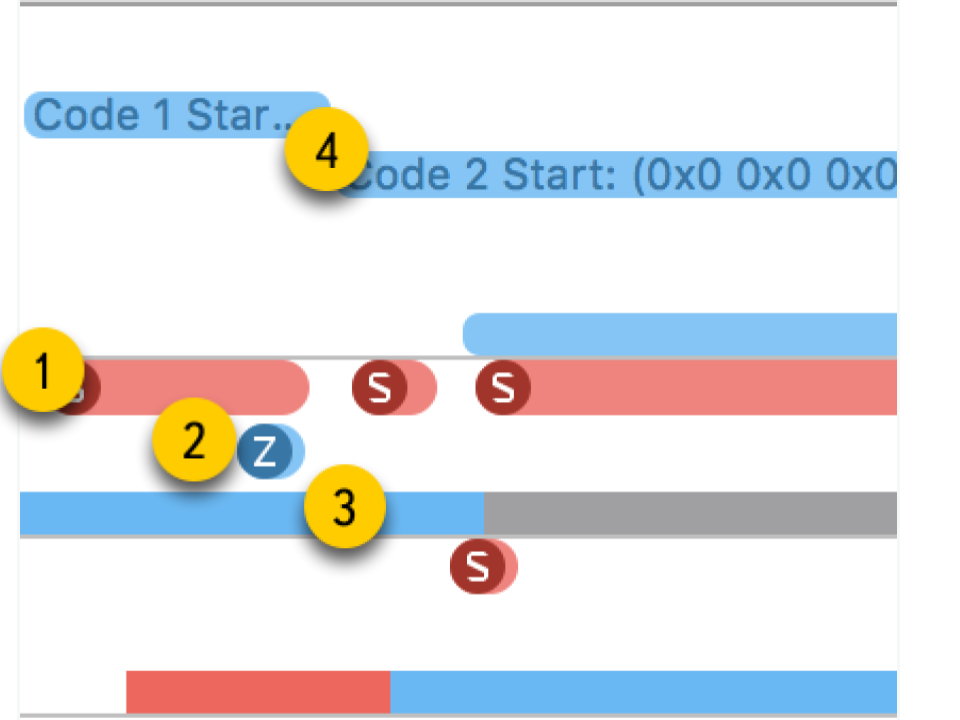
- Appels système Ils sont présentés sous forme de "saucisses" rouges. Lorsque vous les pointez, vous pouvez voir le nom de la méthode système et la durée de l'exécution. Souvent, dans les applications d'application, un tel appel système ne se produit pas directement: nous utilisons quelque chose, qui à son tour appelle déjà la méthode système. Vous ne devez pas compter sur le fait qu'ici les méthodes de votre code seront visibles.
- Opérations de mémoire . Ils sont présentés sous forme de "saucisses" bleues. Cela inclut des opérations telles que l'allocation de mémoire, la libération, la remise à zéro, etc.
- Statut du flux . Couleur bleue - un thread est en cours d'exécution, certains processeurs exécutent du code à partir de ce thread. Gris - le thread est bloqué pour une raison quelconque et ne peut pas continuer l'exécution. Rouge - le thread est prêt à fonctionner, mais pour le moment il n'y a pas de noyau libre pour exécuter son code. Couleur orange - le flux est interrompu pour un travail de priorité plus élevée.
- Points d'intérêt . Ce sont des étiquettes spéciales qui peuvent être organisées par code en appelant
kdebug_signpost . Les étiquettes peuvent être uniques (un endroit spécifique dans le code) ou sous forme de plage (pour mettre en évidence toute la procédure). En utilisant de telles étiquettes, il est beaucoup plus facile de corréler les microsecondes et les appels système avec votre application.
Coûts de création de flux
Le premier test est l'
exécution d'une tâche dans un nouveau thread . Nous créons un fil avec une certaine procédure et attendons qu'il termine son travail. En comparant le temps total avec le temps de la procédure elle-même, nous obtenons la perte totale pour démarrer la procédure dans un nouveau thread.
Dans System Trace, vous pouvez voir clairement comment tout se passe vraiment:
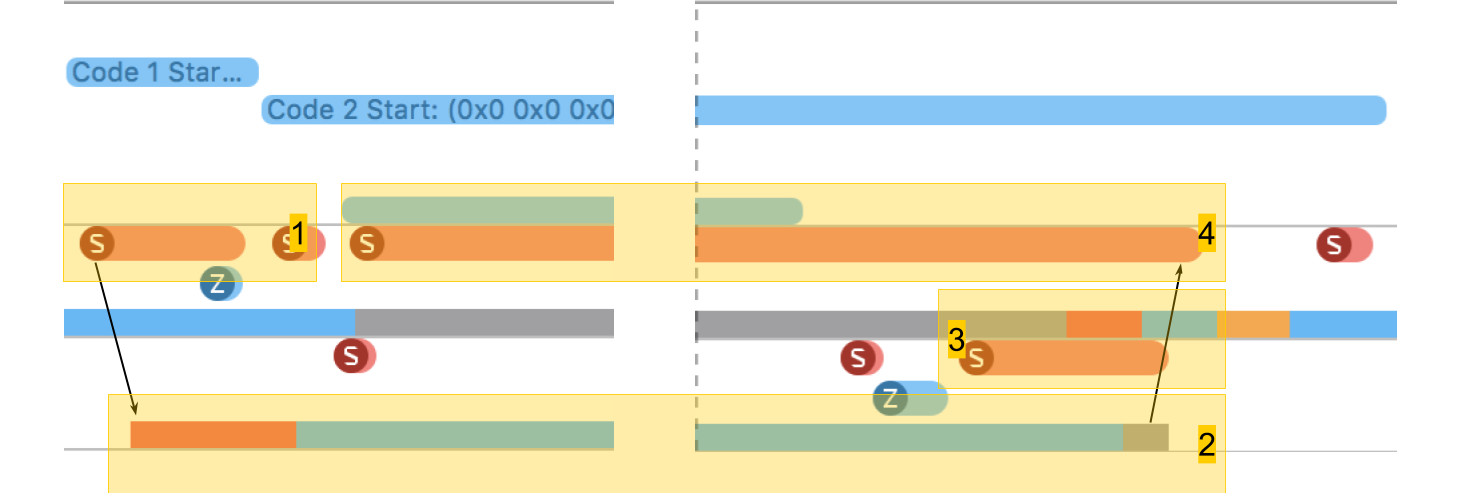
- Créez un flux.
- Le nouveau thread dans lequel notre procédure s'exécute. La zone rouge au début indique que le thread a été créé, mais pendant un certain temps, il n'a pas pu être exécuté, car il n'y avait pas de noyau libre.
- L'achèvement du flux. Fait intéressant, la procédure d'achèvement du thread lui-même est encore plus importante que sa création. Bien qu'il semble que la suppression soit toujours plus rapide.
- En attente de la fin de la procédure, qui était dans le schéma d'origine, et elle se termine après la fin du flux - pendant un certain temps, la méthode s'en rend compte et, après cela, rend compte. Cette durée est légèrement plus longue que l'achèvement du flux.
En conséquence, la création d'un flux nécessite des coûts assez importants: iPhone 5S - 230 microsecondes, 6S - 50 microsecondes.
L'achèvement du flux prend presque 2 fois plus de temps que la création , la jointure prend également un temps tangible. Lorsque nous travaillons avec la mémoire, nous avons obtenu des centaines de nanosecondes, ce qui est 100 fois moins que des dizaines de microsecondes.
| frais généraux | créer | fin | rejoindre |
| iPhone 5s | 230 μs | 40 μs | 70 μs | 30 μs |
| iPhone 6s Plus | 50 μs | 12 μs | 20 μs | 7 μs |
Temps de commutation du sémaphore
Le prochain test est des
mesures sur le travail du sémaphore . Nous avons 2 threads pré-créés, et pour chacun d'eux il y a un sémaphore. Les flux signalent alternativement le sémaphore du voisin et attendent le leur. En se transmettant des signaux, les flux jouent au ping-pong, se ravivent. Cette double itération donne un temps de commutation double sémaphore.
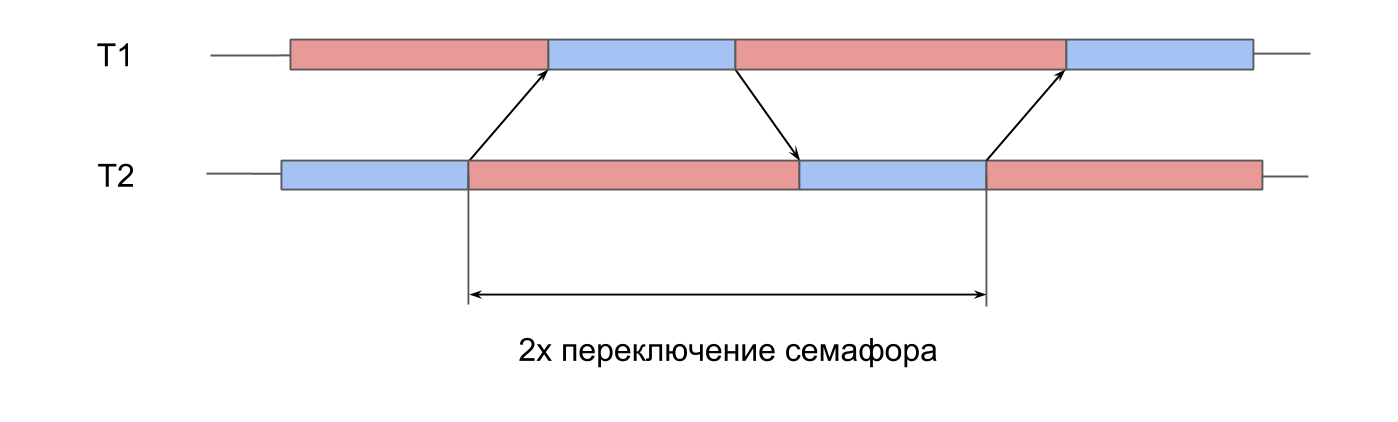
Dans System Trace, tout se ressemble:
- Un signal est donné pour le sémaphore du deuxième flux. On voit que cette opération est très courte.
- Le deuxième thread est déverrouillé, l'attente sur son sémaphore se termine.
- Un signal est donné pour le sémaphore du premier flux.
- Le premier thread est débloqué, l'attente sur son sémaphore se termine.
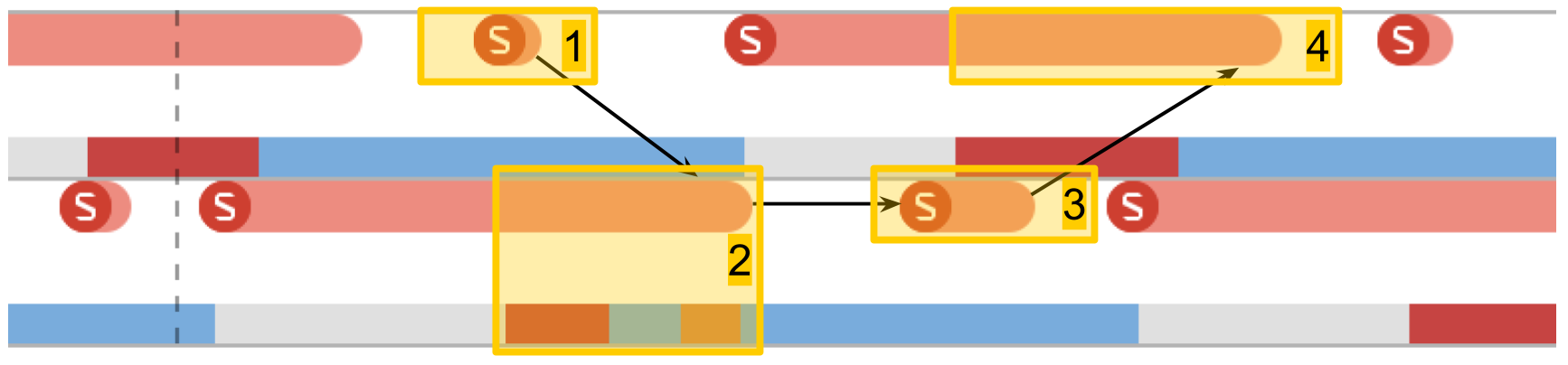
Le temps de commutation était dans les 10 microsecondes. La différence avec la création d'un thread par 50 fois est exactement la raison pour laquelle les pools de threads sont créés, et non un nouveau thread pour chaque procédure.
Pertes lors du changement de contexte du thread système
Dans les deux tests précédents, le transfert de contrôle entre les threads était complètement contrôlé - nous avons clairement compris où et où la transition devait se produire. Cependant, il arrive souvent que le système lui-même passe d'un thread à un autre. Lorsque nous exécutons plus de tâches en parallèle que les cœurs de l'appareil, le système d'exploitation doit pouvoir se commuter lui-même pour fournir à chacun du temps processeur.
Dans ce test, je voulais mesurer la perte de démarrage d'un trop grand nombre de threads. Pour ce faire, un pool de 16 threads est créé, chacun d'eux attend un sémaphore et, dès qu'il reçoit un signal, effectue une certaine procédure et signale le sémaphore en retour. Le thread principal démarre le pool entier, donnant 16 signaux, puis attend 16 signaux en réponse.
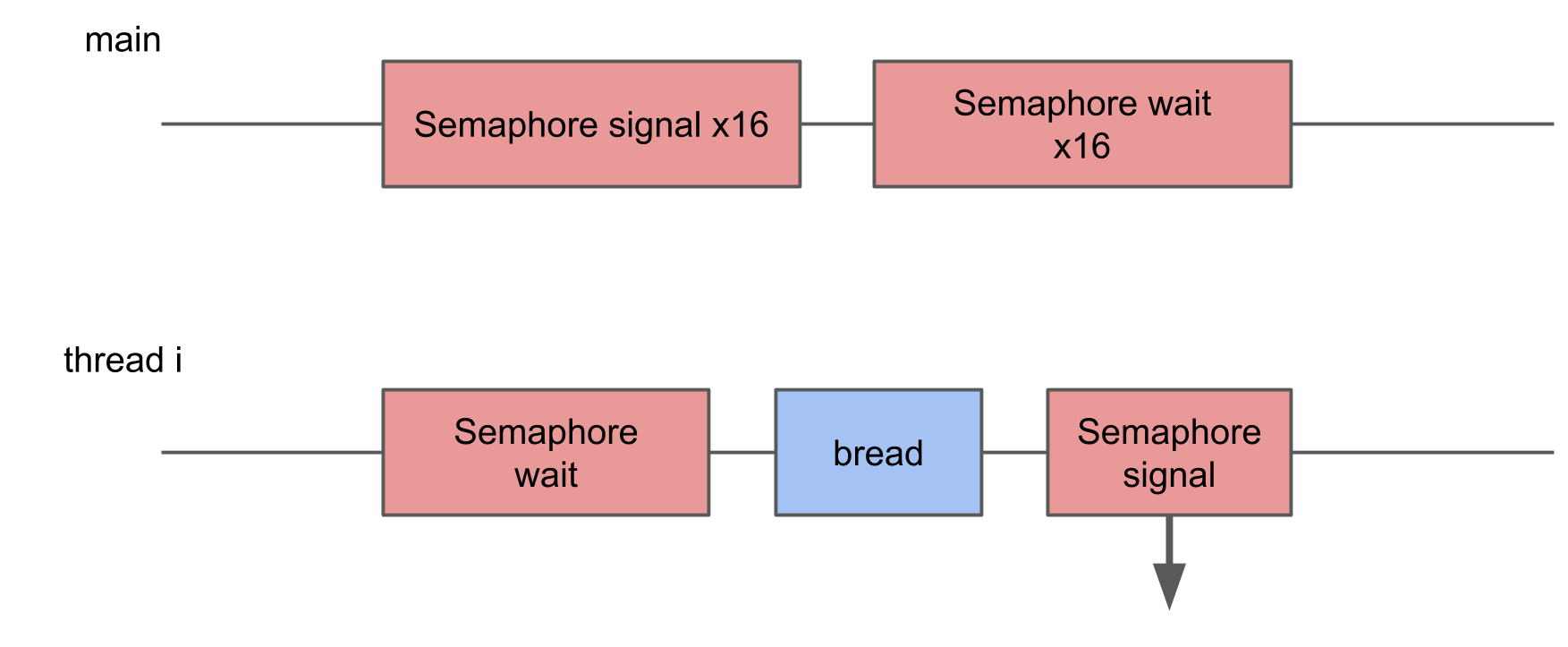
Dans System Trace, vous pouvez voir que les blocs sont dispersés de manière aléatoire, certains d'entre eux sont beaucoup plus longs que les autres. Si plusieurs commutations entraînent une augmentation du temps d'exécution de l'opération, le temps d'exécution moyen devrait en conséquence augmenter.
Cependant, avec une augmentation du nombre de threads, le temps de fonctionnement moyen n'augmente pas.En théorie, le temps moyen doit être conservé tant que la charge correspond à la puissance de traitement. Autrement dit, le nombre de tâches correspond au nombre de cœurs.
Si vous exécutez plusieurs tâches en parallèle, le système d'exploitation, passant d'une tâche à une autre, entraînera des retards supplémentaires. Cela devrait se refléter dans le résultat.
En pratique, non seulement notre application fonctionne sur l'appareil, mais elle a encore de nombreux processus parallèles et système. Même le seul thread de notre application sera affecté par la commutation, ce qui entraîne des interruptions et des retards. Par conséquent, dans toutes les situations, il y a des retards, et il n'y a aucune différence entre créer des tâches en série ou exécuter en parallèle.

Vous trouverez ci-dessous notre tableau des numéros de latence avec des données sur les flux et le sémaphore.
| L1 | L2 | La mémoire | Sémaphore |
| Numéros de latence | 1 ns | 7 ns | 100 ns | 25 ns |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs |
| iPhone X | 2 ns | 12 ns | 146 ns | 3,2 μs |
Coûts des fichiers
Nous avons déjà de la mémoire et des threads - pour être complet, nous n'avons besoin que des opérations du système de fichiers.
Lire le fichier
Le premier test est
la vitesse de lecture - combien coûte la lecture d'un fichier. Le test se compose de deux parties. Dans la première, nous
mesurons la vitesse de lecture en tenant compte de l'ouverture, de la lecture et de la fermeture du fichier. Dans le second, nous
supposons que le fichier est constamment ouvert : nous nous positionnons quelque part et lisons autant que nous voulons.
Les résultats sont correctement vus de deux points de vue.
Lorsque le fichier est petit , il y a un temps minimal pour lire les données du fichier. Jusqu'à un kilo-octet équivaut à 5,3 microsecondes - peu importe: 1 octet, 2 ou 1 Ko - pour tous les 5,3 μs. Par conséquent, vous ne pouvez parler de vitesse que dans le cas de fichiers volumineux, lorsque le temps fixe peut déjà être négligé. L'opération d'ouverture et de fermeture du fichier prend environ le même temps pour n'importe quelle taille de fichier - dans le cas de 5S, environ 50 microsecondes.
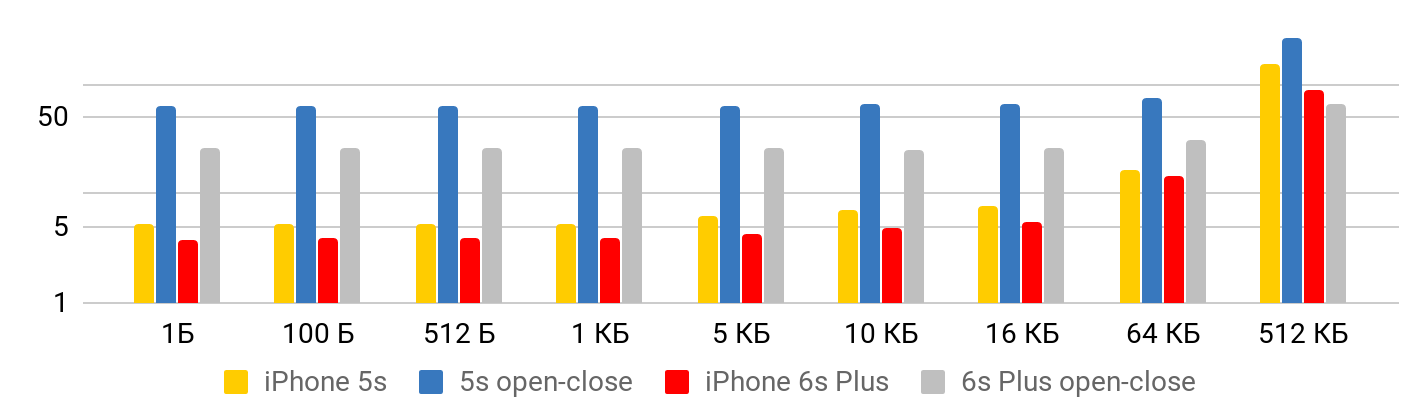
Pour la vitesse de lecture, de tels graphiques sont obtenus.
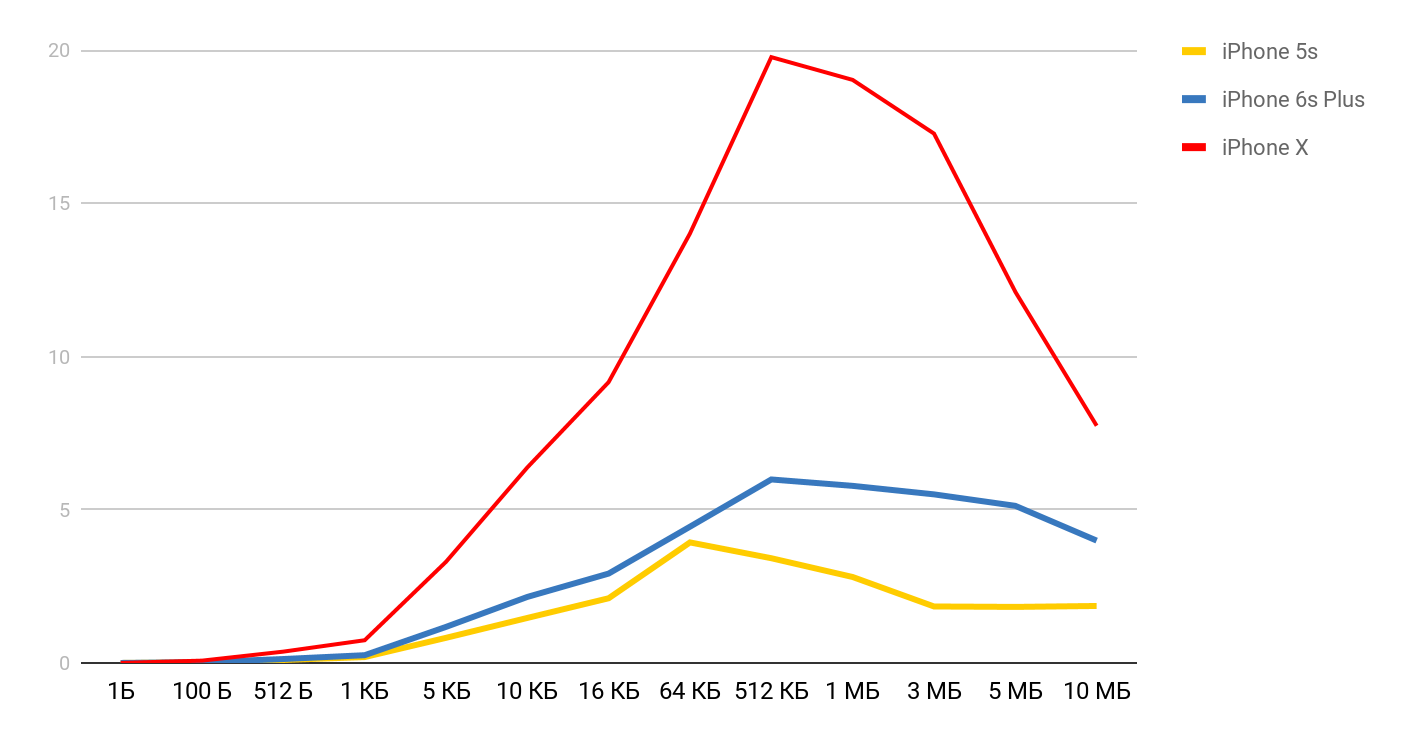
Pour l'iPhone X et un fichier de 1 Mo, la vitesse peut atteindre 20 Mo / s. Fait intéressant, la lecture d'un fichier de 1 Mo est plus efficace. Avec des fichiers de grande taille, les tailles de cache semblent être affectées. C'est pourquoi la vitesse baisse encore et se stabilise autour de 10 Mb.
Créer et supprimer des fichiers
Le test consiste à
créer un fichier et à écrire des données , et à
supprimer les fichiers créés. Le résultat est pas à pas: sur les petites tailles, le temps est stable - environ 7 μs, et continue de croître. L'échelle est logarithmique.
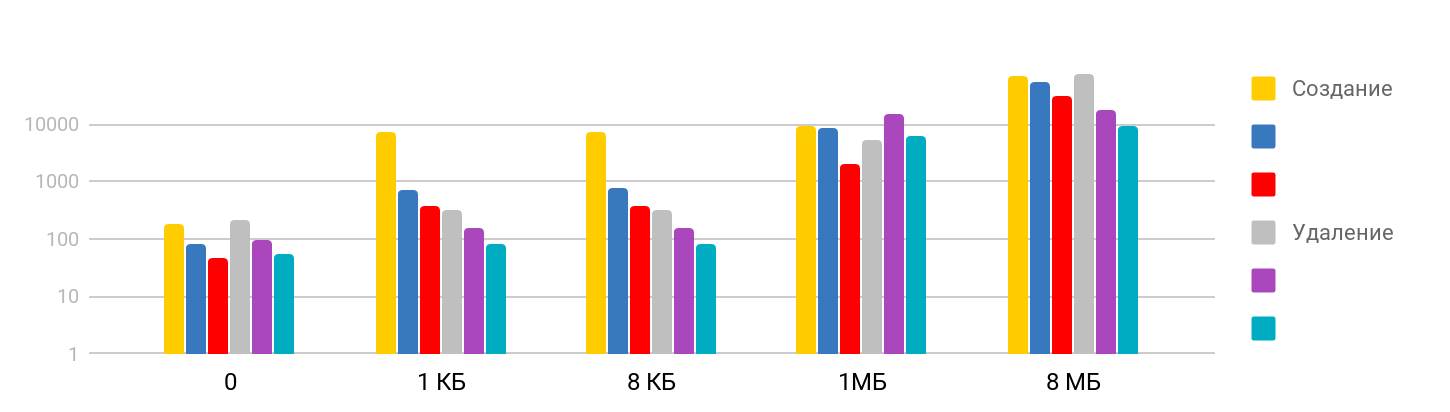
J'ai été surpris que le temps nécessaire pour supprimer un gros fichier soit proportionnel au temps nécessaire pour créer, car je supposais que la suppression était une opération rapide. Il s'avère que pour l'iPhone, la suppression dans le temps est comparable à la création d'un fichier. Le tableau récapitulatif ressemble à ceci.
| L1 | L2 | La mémoire | Sémaphore | Disque |
| Numéros de latence | 1 ns | 7 ns | 100 ns | 25 ns | 150 μs |
| iPhone 5s | 7 ns | 30 ns | 240 ns | 8 μs | 5 μs |
| iPhone 6s Plus | 5 ns | 12 ns | 200 ns | 5 μs | 4 μs |
| iPhone X | 2 ns | 12 ns | 146 ns | 3,2 μs | 1,3 μs |
Conclusion
Sur la base de ces mesures, nous avons maintenant une idée du temps nécessaire aux opérations iOS de base: l'accès à la mémoire est en nanosecondes, le travail avec des fichiers en microsecondes, la création d'un flux représente des dizaines de microsecondes et la commutation n'est que de quelques microsecondes.
Pour obtenir un blocage physiquement perceptible dans l'application, le temps d'exécution de la procédure doit dépasser 15 millisecondes (le temps qu'il faut pour mettre à jour l'écran à 60fps). C'est presque mille fois plus grand que la plupart des mesures prises dans l'article. Sur une telle échelle, une milliseconde, c'est beaucoup, et une seconde est déjà "pour toujours".
Les tests ont montré que malgré la grande différence dans le temps d'accès à la mémoire et aux caches, l'utilisation directe de ce rapport est assez difficile. Avant de compiler toutes vos données sous L1, vous devez vous assurer que dans votre cas, cela donnera vraiment un résultat.
Selon les tests des opérations avec les threads, nous avons pu nous assurer que la création et la destruction de threads nécessitent un temps considérable, mais effectuer un grand nombre d'opérations parallèles n'entraîne pas de coûts supplémentaires.
Eh bien, en conclusion, je voudrais vous rappeler la règle la plus importante lorsque vous travaillez sur les performances - d'
abord les mesures et ensuite l'optimisation !
Présentateur de profil Dmitry Kurkin sur
GitHub .
La conversion et la transformation des rapports AppsConf 2018 en articles vont de pair avec la préparation de la toute nouvelle conférence 2019. Jusqu'à présent, il n'y a que 7 sujets dans la liste des rapports acceptés , mais cette liste s'allongera tout le temps pour qu'une conférence sympa pour les développeurs mobiles ait lieu du 22 au 23 avril .
Suivez les publications, abonnez-vous à la chaîne youtube et à la newsletter et cette fois passera rapidement.