Les voitures sans pilote ne peuvent se passer de comprendre ce qui se trouve autour et où exactement. En décembre dernier, le développeur Viktor Otliga
vitonka a fait une présentation sur la détection d'objets 3D au
Data-Christmas tree . Victor travaille en direction des véhicules sans pilote Yandex, dans le groupe traitant de la situation de la circulation (et enseigne également au ShAD). Il a expliqué comment nous résolvons le problème de la reconnaissance des autres usagers de la route dans un nuage de points en trois dimensions, en quoi ce problème diffère de la reconnaissance des objets dans une image et comment tirer profit du partage de différents types de capteurs.
- Bonjour à tous! Je m'appelle Victor Otliga, je travaille au bureau Yandex de Minsk et je développe des véhicules sans pilote. Aujourd'hui, je vais parler d'une tâche assez importante pour les drones - la reconnaissance des objets 3D autour de nous.

Pour rouler, vous devez comprendre ce qui vous entoure. Je vais vous dire brièvement quels capteurs et capteurs sont utilisés sur les véhicules sans pilote et lesquels nous utilisons. Je vais vous dire quelle est la tâche de détection des objets 3D et comment mesurer la qualité de la détection. Ensuite, je vais vous dire sur quoi cette qualité peut être mesurée. Et puis je ferai une brève revue des bons algorithmes modernes, y compris ceux sur lesquels nos solutions sont basées. Et au final - petits résultats, une comparaison de ces algorithmes, dont le nôtre.

Voilà à quoi ressemble notre prototype fonctionnel de voiture sans pilote. Un tel taxi peut être loué par toute personne sans chauffeur dans la ville d'Innopolis en Russie, ainsi qu'à Skolkovo. Et si vous regardez bien, il y a un gros dé sur le dessus. Qu'y a-t-il à l'intérieur?

À l'intérieur d'un simple ensemble de capteurs. Il existe une antenne GNSS et GSM pour déterminer où se trouve la voiture et communiquer avec le monde extérieur. Où sans un capteur aussi classique qu'un appareil photo. Mais aujourd'hui, nous nous intéresserons aux lidars.


Lidar produit environ un tel nuage de points autour de lui, qui ont trois coordonnées. Et vous devez travailler avec eux. Je vais vous expliquer comment, à l'aide d'une image de caméra et d'un nuage lidar, reconnaître des objets.
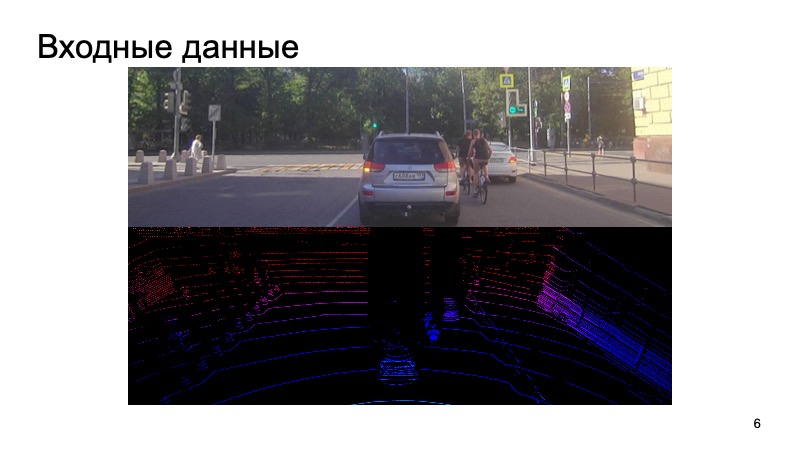
Quel est le défi? L'image de la caméra entre dans l'entrée, la caméra est synchronisée avec le lidar. Il serait étrange d'utiliser l'image de l'appareil photo il y a une seconde, de prendre le nuage lidar d'un moment complètement différent et d'essayer de reconnaître des objets dessus.

Nous synchronisons en quelque sorte les caméras et les lidars, c'est une tâche difficile distincte, mais nous y parvenons avec succès. Ces données entrent en entrée, et à la fin, nous voulons obtenir des boîtes, des boîtes de délimitation qui limitent l'objet: piétons, cyclistes, voitures et autres usagers de la route et pas seulement.
La tâche était fixée. Comment allons-nous l'évaluer?

Le problème de la reconnaissance 2D d'objets dans une image a été largement étudié.
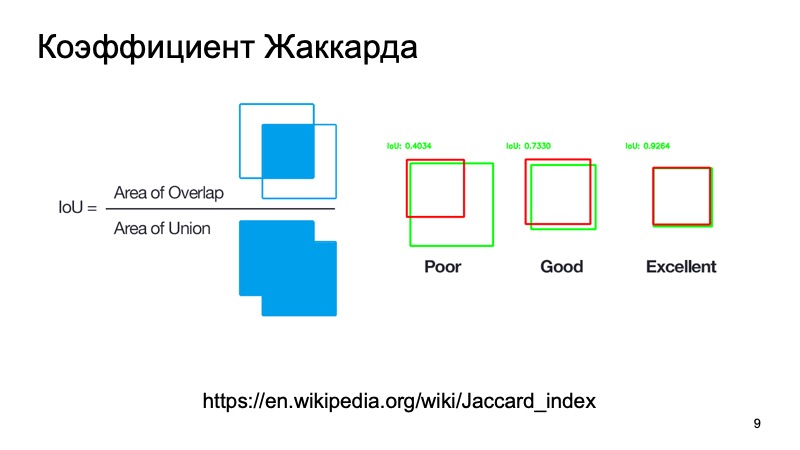
Vous pouvez utiliser des métriques standard ou leurs analogues. Il y a un coefficient Jacquard ou une intersection sur l'union, un merveilleux coefficient qui montre à quel point nous avons détecté un objet. Nous pouvons prendre une boîte où, comme nous le supposons, l'objet est situé, et une boîte où il se trouve réellement. Comptez cette métrique. Il existe des seuils standard - disons que pour les voitures, ils prennent souvent un seuil de 0,7. Si cette valeur est supérieure à 0,7, nous pensons avoir réussi à détecter l'objet, que l'objet est là. Nous sommes grands, nous pouvons aller plus loin.
De plus, afin de détecter un objet et de comprendre qu'il se trouve quelque part, nous voudrions prendre une sorte de confiance que nous voyons vraiment l'objet là-bas, et le mesurer aussi. Vous pouvez mesurer simple, considérer la précision moyenne. Vous pouvez prendre la courbe de rappel de précision et la zone en dessous et dire: plus elle est grande, mieux c'est.
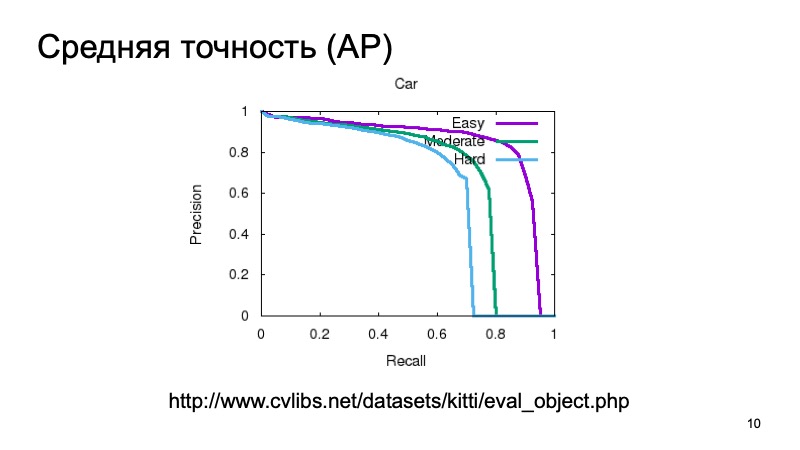
Habituellement, pour mesurer la qualité de la détection 3D, ils prennent un ensemble de données et le divisent en plusieurs parties, car les objets peuvent être proches ou plus éloignés, ils peuvent être partiellement masqués par autre chose. Par conséquent, l'échantillon de validation est souvent divisé en trois parties. Objets faciles à détecter, de complexité moyenne et complexes, distants ou fortement obscurcis. Et ils mesurent séparément en trois parties. Et dans les résultats de la comparaison, nous prendrons également une telle partition.
Vous pouvez mesurer la qualité comme en 3D, un analogue d'intersection sur union, mais pas le rapport des surfaces, mais, par exemple, les volumes. Mais une voiture sans pilote, en règle générale, ne se soucie pas vraiment de ce qui se passe dans la coordonnée Z. Nous pouvons prendre une vue plongeante d'en haut et prendre une sorte de métrique, comme si nous regardions tout cela en 2D. L'homme navigue plus ou moins en 2D, et un véhicule sans pilote est le même. La hauteur de la boîte n'est pas très importante.

Que mesurer?

Probablement tous ceux qui ont au moins fait face à la tâche de détecter en 3D par le nuage lidar ont entendu parler d'un ensemble de données tel que KITTI.

Dans certaines villes d'Allemagne, un ensemble de données a été enregistré, une voiture équipée de capteurs est allée, elle avait des capteurs GPS, des caméras et des lidars. Ensuite, il a été balisé sur environ 8 000 scènes et divisé en deux parties. Une partie est la formation, sur laquelle tout le monde peut se former, et la seconde est la validation, afin de mesurer les résultats. L'échantillon de validation KITTI est considéré comme une mesure de qualité. Tout d'abord, il y a un tableau des leaders sur le site du jeu de données KITTI, vous pouvez y envoyer votre décision, vos résultats sur le jeu de données de validation et comparer avec les décisions d'autres acteurs du marché ou chercheurs. Mais cet ensemble de données est également disponible publiquement, vous pouvez télécharger, ne le dire à personne, vérifier le vôtre, comparer avec vos concurrents, mais ne pas télécharger publiquement.

Les ensembles de données externes sont bons, vous n'avez pas à y consacrer votre temps et vos ressources, mais en règle générale, une voiture qui a voyagé en Allemagne peut être équipée de capteurs complètement différents. Et c'est toujours bien d'avoir votre propre jeu de données interne. De plus, il est plus difficile d'étendre un jeu de données externe au détriment des autres, mais il est plus facile de gérer le vôtre. Par conséquent, nous utilisons le merveilleux service Yandex.Tolok.

Nous avons finalisé notre système de tâches spéciales. À l'utilisateur qui veut aider avec le balisage et obtenir une récompense pour cela, nous distribuons une image de la caméra, distribuons un nuage lidar que vous pouvez faire pivoter, zoomer, dézoomer et lui demander de mettre des boîtes qui limitent nos zones de délimitation afin qu'une voiture ou un piéton y pénètre ou autre chose. Ainsi, nous collectons des échantillons internes pour un usage personnel.
Supposons que nous ayons décidé quelle tâche nous allons résoudre, comment nous supposerons que nous l'avons fait bien ou mal. Nous avons pris quelque part les données.
Quels sont les algorithmes? Commençons par 2D. La tâche de détection 2D est très bien connue et étudiée.
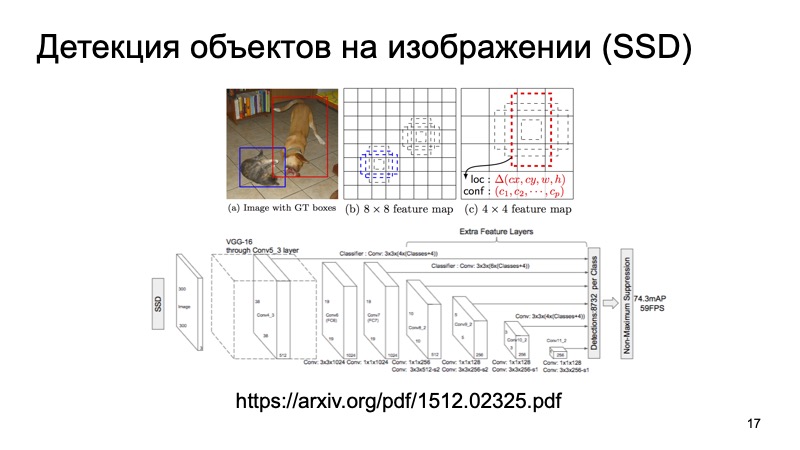
Certes, beaucoup de gens connaissent l'algorithme SSD, qui est l'une des méthodes de pointe pour détecter les objets 2D, et en principe, nous pouvons supposer que, d'une certaine manière, le problème de la détection d'objets dans l'image est assez bien résolu. Si quelque chose, nous pouvons utiliser ces résultats comme une sorte d'informations supplémentaires.
Mais notre nuage lidar a ses propres caractéristiques qui le distinguent grandement de l'image. Premièrement, elle est très clairsemée. Si l'image est une structure dense, les pixels sont proches, tout est dense, alors le nuage est très mince, il n'y a pas tellement de points et il n'a pas de structure régulière. Purement physiquement, il y a beaucoup plus de points près de là que dans la distance, et plus vous allez loin, moins il y a de points, moins il y a de précision, plus il est difficile de déterminer quelque chose.
Eh bien, les points, en principe, du cloud viennent dans un ordre incompréhensible. Personne ne garantit qu'un point sera toujours antérieur à un autre. Ils viennent dans un ordre relativement aléatoire. Vous pouvez en quelque sorte accepter de les trier ou de les réorganiser à l'avance, puis de soumettre les modèles à l'entrée, mais cela sera assez gênant, vous devez prendre le temps de les modifier, etc.
Nous aimerions trouver un système qui sera invariant à nos problèmes, résoudra tous ces problèmes. Heureusement, l'année dernière, CVPR a présenté un tel système. Il y avait une telle architecture - PointNet. Comment fonctionne-t-elle?

Un nuage de n points arrive à l'entrée, chacun avec trois coordonnées. Ensuite, chaque point est en quelque sorte normalisé par une petite transformation spéciale. De plus, il est conduit à travers un réseau entièrement connecté afin d'enrichir ces points de signes. Ensuite, la transformation a lieu et, à la fin, elle s'enrichit en plus. À un moment donné, n points sont obtenus, mais chacun a environ 1024 caractéristiques, ils sont en quelque sorte standardisés. Mais jusqu'à présent, nous n'avons pas résolu le problème concernant l'invariance des déplacements, des virages, etc. Ici, il est proposé de faire un maximum de regroupement, de prendre le maximum parmi les points sur chaque canal et d'obtenir un vecteur de 1024 signes, qui sera un descripteur de notre nuage, qui contiendra des informations sur l'ensemble du nuage. Et puis avec ce descripteur, vous pouvez faire beaucoup de choses différentes.
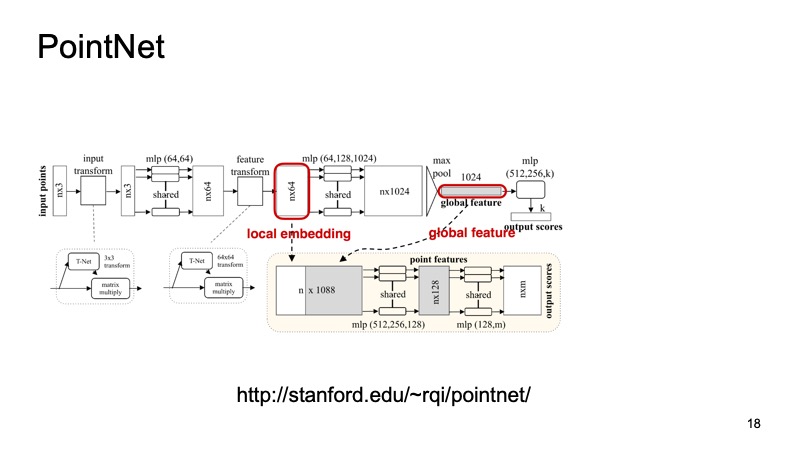
Par exemple, vous pouvez le coller aux descripteurs de points individuels et résoudre le problème de segmentation, pour chaque point afin de déterminer à quel objet il appartient. C'est juste une route ou une personne ou une voiture. Et voici les résultats de l'article.

Vous remarquerez peut-être que cet algorithme fait un très bon travail. En particulier, j'aime beaucoup cette petite table dans laquelle certaines des données sur le comptoir ont été jetées, et il a néanmoins déterminé où sont les pieds et où se trouve le comptoir. Et cet algorithme, en particulier, peut être utilisé comme une brique pour construire d'autres systèmes.
Une approche qui utilise cela est l'approche Frustum PointNets ou l'approche pyramidale tronquée. L'idée est quelque chose comme ça: reconnaissons les objets en 2D, nous sommes bons à le faire.
Puis, sachant comment fonctionne la caméra, nous pouvons estimer dans quelle zone l'objet qui nous intéresse, la machine, peut se trouver. Pour projeter, découpez uniquement cette zone, et déjà sur elle, résolvez le problème de trouver un objet intéressant, par exemple une machine. C'est beaucoup plus facile que de rechercher n'importe quel nombre de voitures dans le cloud. La recherche d'une voiture exactement dans le même nuage semble être beaucoup plus claire et plus efficace.
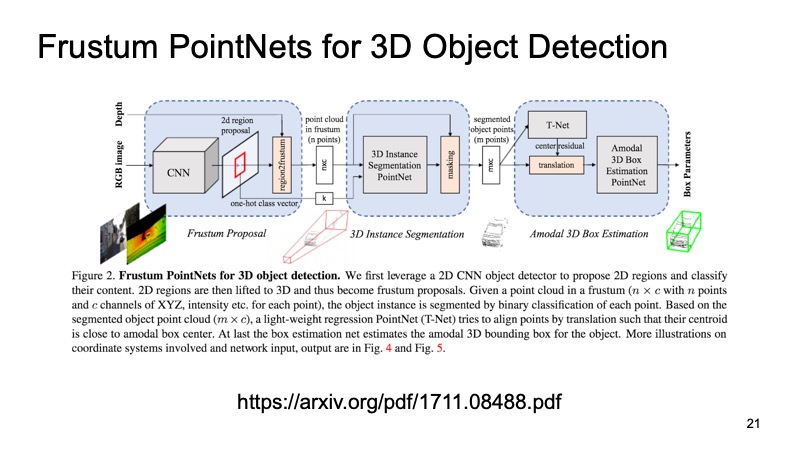
L'architecture ressemble à ceci. Tout d'abord, nous sélectionnons en quelque sorte les régions qui nous intéressent, dans chaque région, nous faisons une segmentation, puis nous résolvons le problème de trouver une boîte englobante qui limite l'objet qui nous intéresse.

L'approche a fait ses preuves. Sur les photos, vous pouvez voir que cela fonctionne assez bien, mais il présente également des inconvénients. L'approche est à deux niveaux, de ce fait, elle peut être lente. Nous devons d'abord appliquer des réseaux et reconnaître des objets 2D, puis couper, puis résoudre le problème de segmentation et d'allocation du cadre de délimitation sur un morceau du nuage, afin qu'il puisse fonctionner un peu lentement.
Une autre approche. Pourquoi ne transformons-nous pas notre nuage en une sorte de structure qui ressemble à une image? L'idée est la suivante: regardons-la d'en haut et échantillonnons notre nuage lidar. Nous obtenons des cubes d'espaces.
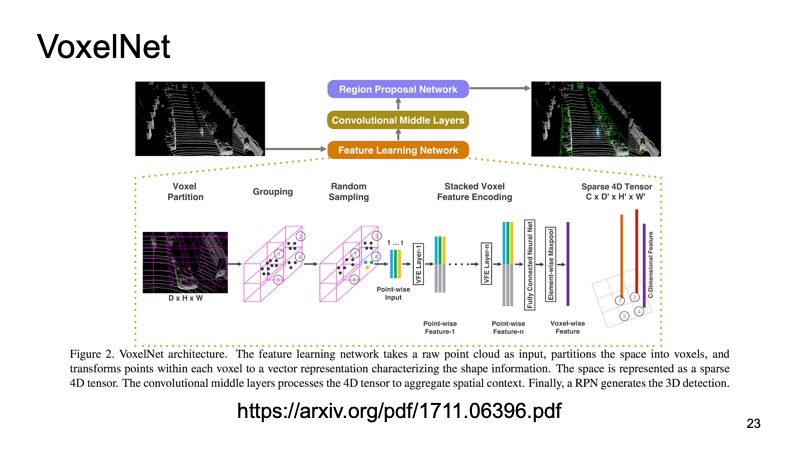
À l'intérieur de chaque cube, nous avons obtenu quelques points. Nous pouvons compter certaines fonctionnalités dessus, mais nous pouvons utiliser PointNet, qui pour chaque morceau d'espace comptera une sorte de descripteur. Nous obtiendrons un voxel, chaque voxel a une description caractéristique, et il ressemblera plus ou moins à une structure dense, comme une image. Nous pouvons déjà créer différentes architectures, par exemple une architecture de type SSD pour détecter des objets.
Cette dernière approche, qui a été l'une des toutes premières approches pour combiner les données de plusieurs capteurs. Ce serait un péché d'utiliser uniquement des données lidar alors que nous avons également des données de caméra. L'une de ces approches est appelée le réseau de détection d'objets 3D à vues multiples. Son idée est la suivante: alimenter trois canaux de données d'entrée à l'entrée d'un grand réseau.
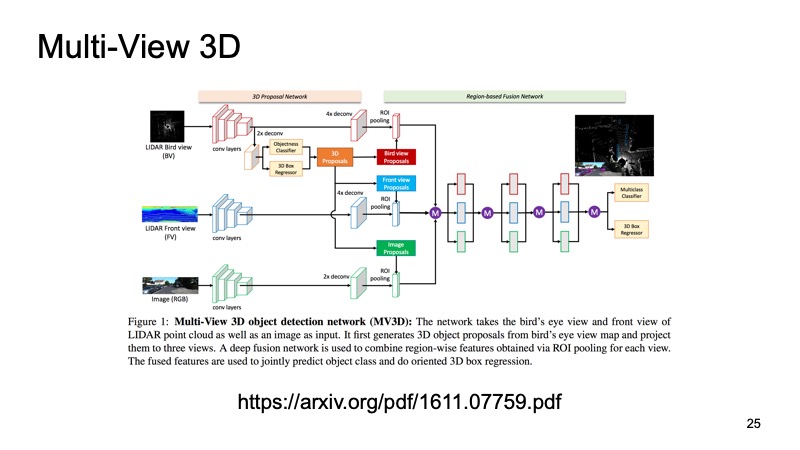
Il s'agit d'une image de la caméra et, en deux versions, d'un nuage lidar: d'en haut, avec une vue plongeante et une sorte de vue de face, ce que nous voyons devant nous. Nous soumettons cela à l'entrée du neurone, et il configurera tout en lui-même, nous donnera le résultat final - l'objet.
Je veux comparer ces modèles. Sur l'ensemble de données KITTI, sur les lecteurs de validation, la qualité est évaluée en pourcentage de précision moyenne.
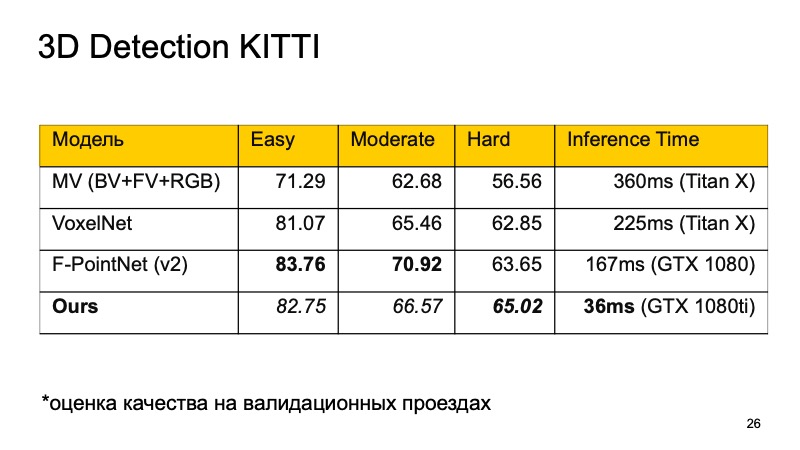
Vous remarquerez peut-être que F-PointNet fonctionne assez bien et assez rapidement, bat tout le monde dans différents domaines - du moins selon les auteurs.
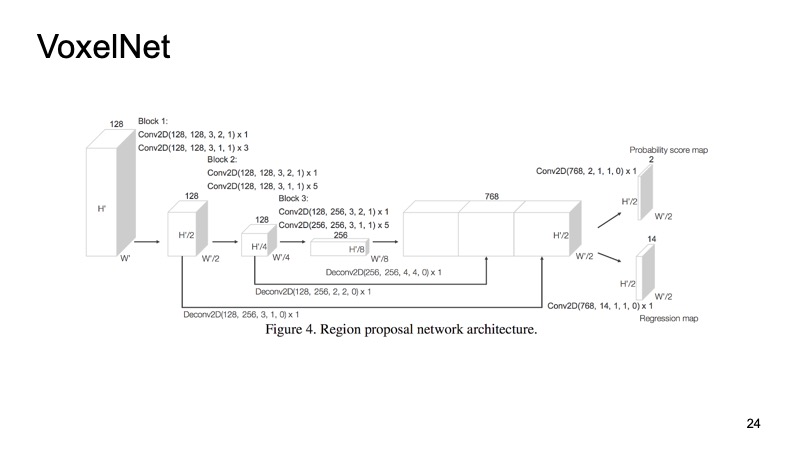
Notre approche est basée sur plus ou moins toutes les idées que j'ai énumérées. Si vous comparez, vous obtenez l'image suivante. Si nous n'occupons pas la première place, alors au moins la seconde. De plus, sur les objets difficiles à détecter, nous entrons dans les chefs. Et surtout, notre approche est assez rapide. Cela signifie qu'il est déjà assez bien applicable pour les systèmes en temps réel, et il est particulièrement important pour un véhicule sans pilote de surveiller ce qui se passe sur la route et de mettre en évidence tous ces objets.

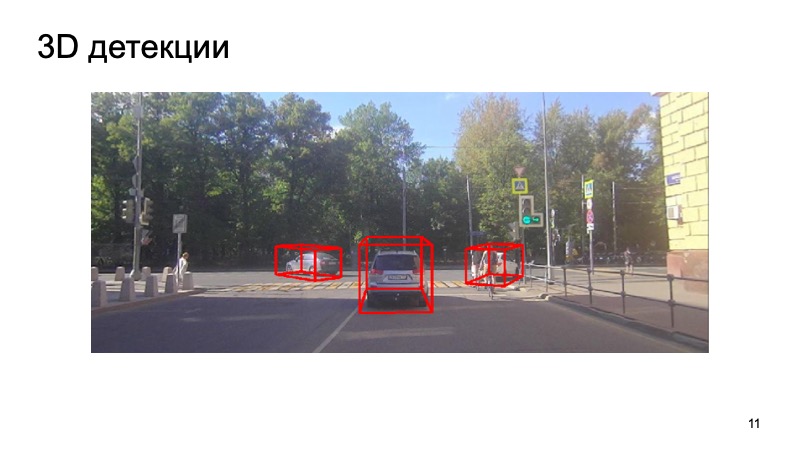
En conclusion - un exemple de notre détecteur:
On voit que la situation est compliquée: certains objets sont fermés, certains ne sont pas visibles par la caméra. Piétons, cyclistes. Mais le détecteur s'en sort assez bien. Je vous remercie!