Il s'agit d'un nouvel article d'une
discussion sur les tâches des entretiens dans Google . Lorsque j'y ai travaillé, j'ai proposé de telles tâches aux candidats. Puis il y a eu une fuite et ils ont été interdits. Mais la pièce a un revers: je peux maintenant expliquer librement la solution.
Excellente nouvelle pour commencer: j'ai quitté Google! Je suis heureux de vous informer que je travaille actuellement en tant que responsable technique pour Reddit à New York! Mais cette série d'articles se poursuivra.
Avertissement: Bien que l'entretien des candidats soit l'une de mes fonctions professionnelles, sur ce blog, je partage des observations personnelles, des histoires et des opinions personnelles. Veuillez ne pas considérer cela comme une déclaration officielle de Google, Alphabet, Reddit, de toute autre personne ou organisation.Question
Après les
deux derniers articles sur les progrès du cheval dans la composition d'un numéro de téléphone, j'ai reçu des critiques selon lesquelles ce n'est pas un problème réaliste. Peu importe l'utilité d'étudier les capacités de réflexion du candidat, mais je dois admettre que la tâche est vraiment un peu irréaliste. Même si j'ai quelques réflexions sur la corrélation entre les questions d'entrevue et la réalité, je vais les laisser pour l'instant. Soyez sûr, j'ai lu des commentaires partout et j'ai quelque chose à répondre, mais pas maintenant.
Mais lorsque la tâche de dépasser le cheval a été interdite il y a plusieurs années, j'ai pris à cœur la critique et j'ai essayé de la remplacer par une question un peu plus pertinente pour le périmètre de Google. Et quoi de plus pertinent pour Google que la mécanique des requêtes de recherche? J'ai donc trouvé cette question et l'ai utilisée pendant longtemps avant qu'elle ne soit également rendue publique et interdite. Comme précédemment, je formulerai la question, plongerai dans son explication, puis dirai comment je l'ai utilisée dans les entretiens et pourquoi je l'aime.
La question est donc.
Imaginez que vous gérez un moteur de recherche populaire et que vous voyez deux demandes dans les journaux: disons, «Notes d'approbation d'Obama» et «Niveau de popularité d'Obama» (si je me souviens bien, ce sont de vrais exemples de la base de questions, bien qu'ils soient un peu dépassés maintenant ...) . Nous voyons différentes requêtes, mais tout le monde sera d'accord: les utilisateurs recherchent essentiellement les mêmes informations, donc les requêtes doivent être considérées comme équivalentes lors du comptage du nombre de requêtes, de l'affichage des résultats, etc.
Comment déterminez-vous si deux requêtes sont synonymes?Formalisons la tâche. Supposons qu'il existe deux ensembles de paires de chaînes: les paires de synonymes et les paires de requêtes.
Plus précisément, voici un exemple d'entrée pour illustrer:
SYNONYMS = [ ('rate', 'ratings'), ('approval', 'popularity'), ] QUERIES = [ ('obama approval rate', 'obama popularity ratings'), ('obama approval rates', 'obama popularity ratings'), ('obama approval rate', 'popularity ratings obama') ]
Il est nécessaire de produire une liste de valeurs logiques: les requêtes dans chaque paire sont-elles synonymes.
Toutes les nouvelles questions ...
À première vue, il s'agit d'une tâche simple. Mais plus vous pensez longtemps, plus cela devient difficile. Un mot peut-il avoir plusieurs synonymes? L'ordre des mots est-il important? Les relations synonymes sont-elles transitives, c'est-à-dire que si A est synonyme de B et B est synonyme de C, A est-il synonyme de C? Les synonymes peuvent-ils couvrir quelques mots, comment «USA» est-il synonyme des expressions «États-Unis d'Amérique» ou «États-Unis»?
Une telle ambiguïté permet immédiatement de faire ses preuves auprès d'un bon candidat. La première chose qu'il fait est de rechercher de telles ambiguïtés et d'essayer de les résoudre. Tout le monde le fait de différentes manières: certains approchent le conseil d'administration et essaient de résoudre manuellement des cas spécifiques, tandis que d'autres examinent la question et voient immédiatement les lacunes. Dans tous les cas, l'identification de ces problèmes à un stade précoce est cruciale.
La phase de «compréhension du problème» est d'une grande importance. J'aime appeler le génie logiciel une discipline fractale. Comme les fractales, l'approximation révèle une complexité supplémentaire. Vous pensez que vous comprenez le problème, puis regardez de plus près - et vous voyez que vous avez manqué une subtilité ou des détails de la mise en œuvre qui peuvent être améliorés. Ou une approche différente du problème.
 Ensemble MandelbrotLe calibre d'un ingénieur est largement déterminé par la profondeur avec laquelle il peut comprendre le problème.
Ensemble MandelbrotLe calibre d'un ingénieur est largement déterminé par la profondeur avec laquelle il peut comprendre le problème. La transformation d'un énoncé vague du problème en un ensemble détaillé d'exigences est la première étape de ce processus, et un euphémisme délibéré vous permet d'évaluer dans quelle mesure le candidat est adapté à de nouvelles situations.
Nous laissons de côté des questions triviales, telles que «Les lettres majuscules sont-elles importantes?» Qui n'affectent pas l'algorithme principal. Je donne toujours la réponse la plus simple à ces questions (dans ce cas, «supposons que toutes les lettres sont déjà prétraitées et converties en minuscules»)Partie 1. (Pas tout à fait) un cas simple
Si les candidats posent des questions, je commence toujours par le cas le plus simple: un mot peut avoir plusieurs synonymes, l'ordre des mots est important, les synonymes ne sont pas transitifs. Cela donne au moteur de recherche des fonctionnalités assez limitées, mais il a suffisamment de subtilités pour une interview intéressante.
Un aperçu de haut niveau est le suivant: divisez la requête en mots (par exemple, par des espaces) et comparez les paires correspondantes pour rechercher des mots et des synonymes identiques. Visuellement, cela ressemble à ceci:
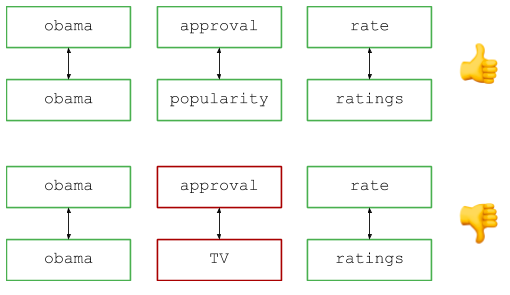
Dans le code:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif words_are_synonyms(w1, w2): continue result = False break output.append(result) return output
Facile, non? Algorithmiquement, c'est assez simple. Pas de programmation dynamique, récursivité, structures complexes, etc. Manipulation simple de la bibliothèque standard et d'un algorithme qui fonctionne en temps linéaire, non?
Mais il y a plus de nuances qu'il n'y paraît à première vue. Bien sûr, l'élément le plus difficile est la comparaison des synonymes. Bien que le composant soit facile à comprendre et à décrire, il existe de nombreuses façons de faire des erreurs. Je vais vous parler des erreurs les plus courantes.
Pour plus de clarté: aucune erreur ne disqualifiera un candidat; si cela, je signale simplement une erreur dans l'implémentation, elle corrige, et nous continuons. Cependant, une interview est avant tout une lutte contre le temps. Vous ferez, remarquerez et corrigerez des erreurs, mais il faut du temps qui peut être consacré à une autre, par exemple, pour créer une solution plus optimale. Presque tout le monde fait des erreurs, c'est normal, mais les candidats qui les réduisent affichent de meilleurs résultats simplement parce qu'ils passent moins de temps à les corriger.
C'est pourquoi j'aime ce problème. Si le mouvement d'un chevalier nécessite une compréhension de la compréhension de l'algorithme, puis (j'espère) une implémentation simple, alors la solution ici est beaucoup d'étapes dans la bonne direction. Chaque étape représente un petit obstacle à travers lequel le candidat peut soit gracieusement sauter par-dessus, soit trébucher et se lever. Grâce à l'expérience et à l'intuition, les bons candidats évitent ces petits pièges - et obtiennent une solution plus détaillée et correcte, tandis que les plus faibles consacrent du temps et de l'énergie aux erreurs et restent généralement avec le mauvais code.
À chaque entretien, j'ai vu une combinaison différente de succès et d'échec, ce sont les erreurs les plus courantes.
Des tueurs de performances aléatoires
Tout d'abord, certains candidats ont implémenté la détection des synonymes en parcourant simplement la liste des synonymes:
... elif (w1, w2) in synonym_words: continue ...
À première vue, cela semble raisonnable. Mais à y regarder de plus près, l'idée est très, très mauvaise. Pour ceux d'entre vous qui ne connaissent pas Python, le mot clé in est du sucre syntaxique pour la méthode
contains et fonctionne sur tous les conteneurs Python standard. Il s'agit d'un problème car
synonym_words est une liste qui implémente le mot clé in à l'aide de la recherche linéaire. Les utilisateurs de Python sont particulièrement sensibles à cette erreur car le langage masque les types, mais les utilisateurs C ++ et Java ont également parfois fait des erreurs similaires.
Au cours de ma carrière, je n'ai écrit que quelques fois avec un code de recherche linéaire, et chacun sur une liste de pas plus de deux douzaines d'éléments. Et même dans ce cas, il a écrit un long commentaire expliquant pourquoi il a choisi une telle approche apparemment sous-optimale. Je soupçonne que certains candidats l'ont utilisé simplement parce qu'ils ne savaient pas comment fonctionne le mot clé in dans les listes de la bibliothèque standard Python. C'est une simple erreur, pas fatale, mais une mauvaise connaissance de votre langue préférée n'est pas très bonne.
En pratique, cette erreur est facilement évitée. Tout d'abord, n'oubliez jamais vos types d'objets, même si vous utilisez un langage non typé tel que Python! Deuxièmement, n'oubliez pas que lorsque vous utilisez le mot clé
in dans la liste, une recherche linéaire démarre. S'il n'y a aucune garantie que cette liste restera toujours très petite, cela réduira les performances.
Pour que le candidat reprenne ses esprits, il suffit généralement de lui rappeler que la structure d'entrée est une liste. Il est très important d'observer comment le candidat répond à l'invite. Les meilleurs candidats essaient immédiatement de prétraiter les synonymes, ce qui est un bon début. Mais cette approche n'est pas sans écueils ...
Utilisez la bonne structure de données
D'après le code ci-dessus, il est immédiatement clair que pour implémenter cet algorithme en temps linéaire, il est nécessaire de trouver rapidement des synonymes. Et quand on parle de recherches rapides, c'est toujours une carte ou un tableau de hachages.
Peu importe que le candidat choisisse une carte ou un tableau de hachages. L'important est qu'il le mette là (au fait, n'utilisez jamais dict / hashmap avec la transition vers
True ou
False ). La plupart des candidats choisissent une sorte de dict / hashmap. L'erreur la plus courante est l'hypothèse subconsciente que chaque mot n'a pas plus d'un synonyme:
... synonyms = {} for w1, w2 in synonym_words: synonyms[w1] = w2 ... elif synonyms[w1] == w2: continue
Je ne punis pas les candidats pour cette erreur. La tâche est spécialement formulée de manière à ne pas se concentrer sur le fait que les mots peuvent avoir plusieurs synonymes, et certains candidats n'ont tout simplement pas rencontré une telle situation. Corrige le plus rapidement un bug quand je le pointe. Les bons candidats le remarquent à un stade précoce et ne passent généralement pas beaucoup de temps.
Un problème un peu plus grave est le manque de conscience que la relation des synonymes se propage dans les deux sens. Notez que dans le code ci-dessus, cela est pris en compte. Mais il existe des implémentations avec une erreur:
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) synonyms[w2].append(w1) ... elif w2 in synonyms.get(w1, tuple()): continue
Pourquoi faire deux insertions et utiliser deux fois plus de mémoire?
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) ... elif (w2 in synonyms.get(w1, tuple()) or w1 in synonyms.get(w2, tuple())): continue
Conclusion:
pensez toujours à optimiser le code ! Rétrospectivement, la permutation des fonctions de recherche est une optimisation évidente, sinon nous pouvons conclure que le candidat n'a pas pensé aux options d'optimisation. Encore une fois, je suis heureux de donner un indice, mais il vaut mieux deviner par vous-même.
Trier?
Certains candidats intelligents souhaitent trier la liste des synonymes, puis utiliser la recherche binaire. En fait, cette approche présente un avantage important: elle ne nécessite pas d'espace supplémentaire, à l'exception de la liste des synonymes (à condition que la liste puisse être modifiée).
Malheureusement, la complexité temporelle interfère: le tri d'une liste de synonymes nécessite du temps
Nlog(N) , puis un autre
log(N) pour rechercher chaque paire de synonymes, tandis que la solution de prétraitement décrite se déroule en temps linéaire puis constant. De plus, je suis catégoriquement contre de forcer le candidat à implémenter le tri et la recherche binaire sur le tableau, car: 1) les algorithmes de tri sont bien connus, donc, à ma connaissance, le candidat peut le publier sans réfléchir; 2) ces algorithmes sont diaboliquement difficiles à mettre en œuvre correctement, et souvent même les meilleurs candidats font des erreurs qui ne disent rien sur leurs compétences en programmation.
Chaque fois qu'un candidat proposait une telle solution, j'étais intéressé par le temps d'exécution du programme et demandais s'il y avait une meilleure option. Pour information: si l'enquêteur vous demande s'il existe une meilleure option, la réponse est presque toujours oui. Si jamais je vous pose cette question, la réponse sera certainement celle-là.
Enfin solution
Au final, le candidat propose quelque chose de correct et raisonnablement optimal. Voici une implémentation en temps linéaire et en espace linéaire pour des conditions données:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].add(w2) output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif ((w1 in synonyms and w2 in synonyms[w1]) or (w2 in synonyms and w1 in synonyms[w2])): continue result = False break output.append(result) return output
Quelques notes rapides:
- Notez l'utilisation de
dict.get() . Vous pouvez implémenter une vérification pour voir si la clé est dans le dict, puis l'obtenir, mais c'est une approche compliquée, bien que de cette façon vous montrerez votre connaissance de la bibliothèque standard. - Personnellement, je ne suis pas un fan de code avec une
continue fréquente et certains guides de style les interdisent ou ne les recommandent pas . J'ai moi-même dans la première édition de ce code oublié la déclaration continue après avoir vérifié la longueur de la demande. Ce n'est pas une mauvaise approche, sachez simplement qu'elle est sujette aux erreurs.
Partie 2: devient plus difficile!
Les bons candidats, après avoir résolu le problème, ont encore dix à quinze minutes de temps. Heureusement, il y a un tas de questions supplémentaires, bien qu'il soit peu probable que nous écrivions beaucoup de code pendant cette période. Cependant, ce n'est pas nécessaire. Je veux savoir deux choses sur le candidat: est-il capable de développer des algorithmes et est-il capable de coder? Le problème avec le mouvement du chevalier répond d'abord à la question de développer un algorithme, puis vérifie le codage, et ici nous obtenons les réponses dans l'ordre inverse.
Au moment où le candidat a terminé la première partie de la question, il avait déjà résolu le problème du codage (étonnamment non trivial). À ce stade, je peux parler en toute confiance de sa capacité à développer des algorithmes rudimentaires et à traduire des idées en code, ainsi que de sa connaissance de son langage préféré et de sa bibliothèque standard. Maintenant, la conversation devient beaucoup plus intéressante, car les exigences de programmation peuvent être assouplies et nous allons plonger dans les algorithmes.
Pour cela, nous revenons aux principaux postulats de la première partie: l'ordre des mots est important, les synonymes sont non transitifs et pour chaque mot il peut y avoir plusieurs synonymes. Au fur et à mesure de l'entretien, je modifie chacune de ces restrictions, et dans cette nouvelle phase, le candidat et moi avons une discussion purement algorithmique. Ici, je vais donner des exemples de code pour illustrer mon point de vue, mais dans une vraie interview, nous ne parlons que d'algorithmes.
Avant de commencer, je vais expliquer ma position: toutes les actions ultérieures à ce stade de l’entretien sont principalement des «points bonus». Mon approche personnelle consiste à identifier les candidats qui franchissent exactement la première étape et sont aptes au travail. La deuxième étape est nécessaire pour mettre en valeur le meilleur. La première note est déjà très forte et signifie que le candidat est assez bon pour l'entreprise, et la deuxième note dit que le candidat est excellent et son embauche sera une grande victoire pour nous.
Transitivité: approches naïves
Tout d'abord, j'aime supprimer la contrainte de transitivité, donc si les paires A - B et B - C sont synonymes, alors les mots A et C sont également synonymes. Les candidats intelligents comprendront rapidement comment adapter leur solution précédente, bien qu'avec la suppression supplémentaire d'autres restrictions, la logique de base de l'algorithme cessera de fonctionner.
Mais comment l'adapter? Une approche courante consiste à conserver un ensemble complet de synonymes pour chaque mot en fonction des relations transitives. Chaque fois que nous insérons un mot dans un ensemble de synonymes, nous l'ajoutons également aux ensembles correspondants pour tous les mots de cet ensemble:
synonyms = defaultdict(set) for w1, w2 in synonym_words: for w in synonyms[w1]: synonyms[w].add(w2) synonyms[w1].add(w2) for w in synonyms[w2]: synonyms[w].add(w1) synonyms[w2].add(w1)
Veuillez noter que lors de la création du code, nous avons déjà exploré cette solution.Cette solution fonctionne, mais loin d'être optimale. Pour comprendre les raisons, nous estimons la complexité spatiale de cette solution. Chaque synonyme doit être ajouté non seulement à l'ensemble du mot initial, mais également aux ensembles de tous ses synonymes. S'il existe un synonyme, une entrée est ajoutée. Mais si nous avons 50 synonymes, vous devez ajouter 50 entrées. Dans la figure, cela ressemble à ceci:
Notez que nous sommes passés de trois clés et six enregistrements à quatre clés et douze enregistrements. Un mot avec 50 synonymes nécessitera 50 touches et près de 2500 entrées. L'espace nécessaire pour représenter un mot augmente de façon quadratique avec une augmentation de l'ensemble des synonymes, ce qui est plutôt inutile.
Il existe d'autres solutions, mais je n'irai pas trop loin pour ne pas gonfler l'article. Le plus intéressant d'entre eux est l'utilisation de la structure de données synonyme pour construire un graphe orienté, puis une recherche en premier pour trouver le chemin entre deux mots. C'est une excellente solution, mais la recherche devient de taille linéaire dans l'ensemble des synonymes du mot. Comme nous effectuons cette recherche plusieurs fois pour chaque demande, cette approche n'est pas optimale.
Transitivité: utilisation d'ensembles disjoints
Il s'avère que la recherche de synonymes est possible pendant un temps (presque) constant grâce à une structure de données appelée ensembles disjoints. Cette structure offre des possibilités légèrement différentes d'un ensemble de données classique.
La structure d'ensemble habituelle (hashset, treeset) est un conteneur qui vous permet de déterminer rapidement si un objet se trouve à l'intérieur ou à l'extérieur de celui-ci. Les ensembles disjoints résolvent un problème complètement différent: au lieu de définir un élément spécifique, ils vous permettent de déterminer
si deux éléments appartiennent au même ensemble . De plus, la structure le fait pour un temps
O(a(n)) extrêmement rapide, où
a(n) est la fonction Ackerman inverse. Si vous n'avez pas étudié les algorithmes avancés, vous ne connaissez peut-être pas cette fonction qui, pour toutes les entrées raisonnables, est en fait exécutée en temps constant.
À un niveau élevé, l'algorithme fonctionne comme suit. Les ensembles sont représentés par des arbres avec des parents pour chaque élément. Étant donné que chaque arbre a une racine (un élément qui est son propre parent), nous pouvons déterminer si deux éléments appartiennent au même ensemble en traçant leurs parents jusqu'à la racine. Si deux éléments ont une racine, ils appartiennent à un ensemble. La combinaison d'ensembles est également simple: il suffit de trouver les éléments racine et de faire de l'un d'eux la racine de l'autre.
Jusqu'ici tout va bien, mais jusqu'à présent, aucune vitesse éblouissante n'a été observée. Le génie de cette structure réside dans une procédure appelée
compression . Supposons que vous ayez l'arborescence suivante:
Imaginez que vous vouliez savoir si
rapide et
hâtif sont synonymes. Passez par chaque parent - et trouvez la même racine
rapide . Supposons maintenant que nous effectuions une vérification similaire pour les mots
rapides et
rapides . Encore une fois, nous montons à la racine, et à grande
vitesse, nous empruntons le même chemin. La duplication des travaux peut-elle être évitée?
Il s'avère que vous le pouvez. Dans un sens, chaque élément de cet arbre est destiné à venir au
jeûne . Au lieu de parcourir l'arborescence entière à chaque fois, pourquoi ne pas changer le parent de tous
les descendants
rapides pour raccourcir la route vers la racine? Ce processus est appelé compression et, dans les ensembles disjoints, il est intégré à l'opération de recherche racine. Par exemple, après la première opération de comparaison
rapide et
rapide, la structure comprendra qu'il s'agit de synonymes et compressera l'arborescence comme suit:
Pour tous les mots entre rapide et rapide, le parent a été mis à jour, la même chose s'est produite avec hâteMaintenant, tous les appels suivants se produiront en temps constant, car chaque nœud de cet arbre pointe vers
rapide . Il n'est pas très facile d'évaluer la complexité temporelle des opérations: en fait, elle n'est pas constante, car elle dépend de la profondeur des arbres, mais elle est proche de constante, car la structure est rapidement optimisée. Pour simplifier, nous supposons que le temps est constant.
Avec ce concept, nous implémentons des ensembles non liés à notre problème:
class DisjointSet(object): def __init__(self): self.parents = {} def get_root(self, w): words_traversed = [] while self.parents[w] != w: words_traversed.append(w) w = self.parents[w] for word in words_traversed: self.parents[word] = w return w def add_synonyms(self, w1, w2): if w1 not in self.parents: self.parents[w1] = w1 if w2 not in self.parents: self.parents[w2] = w2 w1_root = self.get_root(w1) w2_root = self.get_root(w2) if w1_root < w2_root: w1_root, w2_root = w2_root, w1_root self.parents[w2_root] = w1_root def are_synonymous(self, w1, w2): return self.get_root(w1) == self.get_root(w2)
En utilisant cette structure, vous pouvez prétraiter des synonymes et résoudre le problème en temps linéaire.Note et notes
À ce stade, nous avons atteint la limite de ce qu'un candidat peut montrer en 40 à 45 minutes d'entrevue. À tous les candidats qui ont fait face à la partie introductive et qui ont fait des progrès significatifs dans la description (pas la mise en œuvre) d'ensembles non liés, j'ai attribué la note «Hautement recommandé pour l'emploi» et leur ai permis de poser des questions. Je n'ai jamais vu un candidat aller aussi loin et il me reste beaucoup de temps.En principe, il existe encore des variantes du problème de la transitivité: par exemple, supprimer la restriction sur l'ordre des mots ou sur plusieurs synonymes d'un mot. Chaque décision sera difficile et délicieuse, mais je les laisserai pour plus tard.Le mérite de cette tâche est qu'elle permet aux candidats de faire des erreurs. Le développement logiciel quotidien consiste en des cycles sans fin d'analyse, d'exécution et de raffinement. Ce problème permet aux candidats de démontrer leurs capacités à chaque étape. Considérez les compétences nécessaires pour obtenir le score maximum sur cette question:- Analyser l'énoncé du problème et déterminer où il n'est pas clairement formulé , développer une formulation non ambiguë. Continuez à le faire pendant que vous résolvez et que de nouvelles questions surgissent. Pour une efficacité maximale, effectuez ces opérations le plus tôt possible, car plus le travail est avancé, plus il faudra de temps pour corriger l'erreur.
- , . , .
- . , , .
- , . ,
continue , , .
- , : , , , . , , , .
- . — , . — .
Aucune de ces compétences ne peut être apprise des manuels (à l'exception peut-être des structures de données et des algorithmes). La seule façon de les acquérir est de pratiquer régulièrement et largement, ce qui est en bon accord avec ce dont l'employeur a besoin: des candidats expérimentés qui sont capables d'appliquer efficacement leurs connaissances. Le but des interviews était de trouver de telles personnes, et la tâche de cet article m'a bien aidé pendant longtemps.Plans futurs
Comme vous pouvez le comprendre, la tâche a finalement été connue du public . Depuis lors, j'ai utilisé plusieurs autres questions, en fonction de ce que les intervieweurs précédents m'ont demandé et de mon humeur (poser une question est tout le temps ennuyeux). J'utilise toujours quelques questions, donc je vais les garder secrètes, mais certaines ne le sont pas! Vous pouvez les trouver dans les articles suivants.Dans un avenir proche, je prévois deux articles. Tout d'abord, comme promis ci-dessus, je vais expliquer la solution aux deux problèmes restants pour cette tâche. Je ne leur ai jamais posé de questions lors des interviews, mais elles sont intéressantes en elles-mêmes. En outre, je partagerai mes réflexions et mon opinion personnelle sur la procédure de recherche d'employés en informatique, ce qui est particulièrement intéressant pour moi maintenant, car je recherche des ingénieurs pour mon équipe dans Reddit.Comme toujours, si vous souhaitez être informé de la sortie de nouveaux articles, suivez-moi sur Twitter ou sur Medium . Si vous avez aimé cet article, n'oubliez pas de voter pour lui ou de laisser un commentaire.Merci d'avoir lu!PS: Vous pouvez examiner le code de tous les articles dans le dépôt GitHub ou jouer avec eux en direct grâce à mes bons amis de repl.it .