Le marché des services cloud connaît une croissance rapide tant dans le monde qu'en Russie. De plus en plus d'entreprises transfèrent leurs applications et leurs données, y compris celles critiques pour l'entreprise, vers le cloud. Selon les spécialistes du marketing, cela permet aux entreprises d'utiliser les solutions cloud innovantes les plus avancées, réduisant les coûts d'investissement (conversion de CAPEX en OPEX), plus rapidement pour mettre de nouveaux produits sur le marché et lancer de nouveaux services. Et de tels arguments ne laissent pas les clients potentiels indifférents. Ce n'est pas un hasard si le taux de croissance du marché du cloud russe est nettement supérieur à la croissance du marché des infrastructures informatiques traditionnelles et classiques.
Progressivement, les doutes sur la fiabilité et la sécurité des nuages se dissipent. Comme l'a
montré une récente
étude iKS-Consulting , près de 40% des entreprises russes interrogées considèrent l'utilisation des clouds publics comme une opportunité d'améliorer la sécurité de leurs systèmes informatiques. Le service cloud d'infrastructure le plus populaire est la location de serveurs virtuels. En deuxième place dans la popularité est le service de sauvegarde dans le cloud (Backup-as-a-Service). Environ un tiers des répondants utilisent des services cloud pour héberger le stockage et l'infrastructure DR.
Parallèlement, avec la dépendance croissante des entreprises vis-à-vis de l'informatique, les exigences de fiabilité des services informatiques, y compris les services cloud, augmentent. Et souvent, il est nécessaire de fournir non seulement une fiabilité matérielle, mais également une tolérance aux catastrophes.
Selon les recherches , près des trois quarts des organisations dans le monde ne sont pas totalement convaincues de pouvoir restaurer leurs systèmes et leurs données. Les temps d'arrêt imprévus et les pertes de données coûtent aux entreprises du monde entier plus de 1,7 milliard de dollars par an. Selon les
recherches d'Acronis , en Russie, seulement 2% des entreprises interrogées sont absolument convaincues que leur infrastructure informatique résistera à tous les tests. La moitié des spécialistes russes s'attendent à de longues interruptions de son travail en cas de catastrophe naturelle ou d'accident. Selon les statistiques mondiales, 93% des entreprises qui ont perdu leur centre de données pendant seulement 10 jours font faillite en un an.
Dans tous les systèmes techniquement complexes, les accidents sont inévitables, mais ils peuvent être rendus non critiques pour les entreprises. Pour éviter de telles situations, des systèmes de cluster résistants aux catastrophes sont créés qui éliminent pratiquement les temps d'arrêt en cas d'accidents et de pannes.
Un autre point important qui ne doit pas être oublié lors de la conception d'une infrastructure informatique résistante aux catastrophes concerne les postes de travail des utilisateurs. Il est nécessaire de reprendre les processus métier, et pas seulement de basculer vers le serveur de sauvegarde ou d'augmenter la base de données. La tolérance aux catastrophes commence au bureau du client. Même un bureau de secours avec des emplois d'employés n'est pas la meilleure option. Les postes de travail virtuels (VDI) ou d'autres formes de lieu de travail dans le cloud peuvent être une bonne solution. L'accès à un tel poste de travail dans une machine virtuelle du centre de données est facile à organiser à partir de n'importe quel ordinateur du réseau de succursales.
Innovation cloud
L'opérateur de télécommunications russe
MasterTel et Lenovo ont conjointement préparé et mis en œuvre un projet de cloud
résistant aux catastrophes appelé
Innovate Cloud Technology . Sur la base de ce cloud, des services IaaS hautement fiables sont fournis à un large éventail de clients qui souhaitent déployer une infrastructure informatique critique dans le cloud. Le cloud était basé sur le cluster de métro espacé entre deux sites - DataPro et IXellerate data centers à Moscou.
En choisissant un partenaire pour ce projet, la société MasterTel a été guidée, tout d'abord, par la capacité du vendeur à fournir rapidement la solution la plus complète à un prix raisonnable. Pour implémenter le cloud, lancé en octobre 2018, une équipe de spécialistes Lenovo Professional Services a été impliquée. MasterTel agit en tant que fournisseur de services cloud et opérateur de télécommunications qui organise des canaux de communication sécurisés et fournit des lignes de fibre optique directes, est responsable du fonctionnement du cloud et de son support.
Innovate Cloud Technology est un cloud privé pour les entreprises, offrant des services cloud en temps réel hautement fiables et évolutifs IaaS, BaaS, DRaaS, VDS, etc. Que propose l'utilisation des services Innovate Cloud Technology?
Haute fiabilité
Actuellement, la plupart des projets cloud offrent en fait une capacité de location. En règle générale, il s'agit de la création de serveurs virtuels (le service de centre de données commercial le plus courant en Russie) et de l'accès à un pool de ressources déjà constitué. Dans le cas d'Innovate Cloud Technology, le client peut effectuer tous les réglages en ligne, les ressources sont allouées et libérées dynamiquement et payées après coup, exclusivement pour les ressources utilisées, comme il sied à un service cloud classique.
Mais la caractéristique la plus importante d'Innovate Cloud Technology est peut-être sa grande fiabilité. Les clients peuvent tirer parti d'une infrastructure cloud à haute disponibilité et stocker des données hautement critiques dans des centres de données DataPro et IXcellelle géographiquement dispersés. Ces sites garantissent à eux seuls la fiabilité et un haut niveau de sécurité physique et informatique. MasterTel fournit des canaux de communication haute vitesse fiables et un accès aux deux centres de données.
Innovate Cloud Technology est une ressource cloud avec une disponibilité SLA garantie à 99,99%. Cependant, ce cloud se distingue non seulement par sa haute fiabilité, mais également par sa tolérance aux catastrophes, car il s'agit d'un cluster de virtualisation géographiquement dispersé sur deux sites de niveau III.
Data Center DataPro
Ce centre de données Tier III dans la rue. Aviamotornaya à Moscou est l'un des rares centres de données commerciaux russes à avoir reçu la certification Uptime Design and Facility. Toutes les technologies et solutions utilisées dans le centre de données sont certifiées, ce qui signifie une tolérance maximale aux pannes, une disponibilité garantie des ressources et une assurance contre les situations inattendues.
Centre de gestion DataPro Data Center. La certification internationale de la conception et de l'installation Uptime signifie qu'elle est conçue et construite conformément à toutes les normes applicables pour la catégorie de fiabilité de niveau III.
La sécurité est responsable de la sécurité du centre de données lui-même et des environs. Le système de sécurité comprend plus de 350 caméras réseau. Pour une alimentation électrique ininterrompue et garantie, des alimentations sans coupure (UPS) sont utilisées, des groupes électrogènes diesel (DGU) sont utilisés pour soutenir le fonctionnement du centre de données lors d'un accident prolongé dans le réseau d'alimentation.
Dans le centre de données DataPro, il y a deux entrées indépendantes de 10 kV de la sous-station Mosenergo, et les câbles sont posés dans différents collecteurs, fournissant l'énergie électrique nécessaire à l'installation. L'alimentation du datacenter est en fait réservée selon le schéma 2N.
IXcellerate Moscow One
Le centre de données Moscow One d'IXcellerate est également certifié Tier III Uptime Institute dans la catégorie Design. L'installation répond également au niveau de fiabilité de niveau 3 dans les catégories «projet», «construction» et «exploitation» selon la méthodologie IBM Reliability Rating System. IXcellerate Moscow One est techniquement implémenté et garanti au niveau SLA avec un indicateur de disponibilité de 99,999%. La superficie totale du centre de données IXcellerate Moscow One à Degunino est de 15 741 mètres carrés. m. La capacité nominale de l'installation atteint 13,7 MW. Les clients des centres de données comprennent une centaine d'entreprises internationales et russes.
La réussite des tests de certification de l'Uptime Institute prouve que le complexe informatique IXcellerate est conçu conformément aux pratiques du monde moderne dans la construction de centres de données.
Tolérance aux catastrophes
La distribution sur deux sites nécessite l'organisation de canaux de communication redondants, la réplication des données entre les stockages. Nous avons besoin d'un mécanisme de synchronisation des données pour garantir sa pertinence en cas de défaillance d'un des nœuds et pour soutenir le fonctionnement des systèmes d'information qui nécessitent une telle synchronisation.
La configuration d'un serveur de cluster distribué géographiquement avec une connexion à un réseau de stockage commun (SAN) est souvent au cœur d'un centre de données résistant aux catastrophes. Les nœuds de cette grappe espacée sont situés sur les sites principaux et de réserve, formant un système unique. Cela garantit une disponibilité ininterrompue du service, même en cas de perte de l'un des centres de données. Grâce au clustering, il est possible de fournir une commutation automatique de charge entre les sites d'un centre de données distribué en cas d'accident.
Les systèmes de stockage de données sur ces sites peuvent se dupliquer complètement, et les sites eux-mêmes sont connectés par des canaux de communication haute vitesse redondants, ce qui vous permet de mettre en œuvre des projets avec les exigences les plus élevées en matière de fiabilité du transfert de données et de leur disponibilité, y compris la réplication synchrone des données.

Exemple de configuration de Metrocluster basé sur VMware vSphere. il est basé sur la duplication des systèmes de stockage sur deux sites géographiquement séparés avec réplication des données et équilibrage de charge possible au niveau du réseau du centre de données. Si l'un des centres de données n'est pas disponible, les machines virtuelles démarrent automatiquement sur la deuxième plate-forme. Un cluster métropolitain est pratiquement sans temps d'arrêt, le travail n'est interrompu que lors du démarrage des machines virtuelles lorsque VMware High Availability (HA) redémarre la VM sur un site distant avec un stockage situé dans le cluster.
Si vous utilisez des mécanismes d'équilibrage de charge DR (Global Server Load Balancing, GSLB), vous pouvez automatiquement basculer les utilisateurs vers le site de sauvegarde en cas de défaillance principale. Pour les utilisateurs, ce processus sera transparent.
Contrairement à DR avec réplication de données, dans le cas d'un cluster métropolitain, seuls les mêmes types de disques sont utilisés pour la mise en miroir, une configuration identique est nécessaire sur les deux sites.
Le cloud Innovate Cloud Technology basé sur VMware est conçu de cette manière. Il fournit un fonctionnement continu des applications et des données critiques dans le cloud. Tous les éléments du cluster de virtualisation sont dupliqués sur deux sites, distants l'un de l'autre de près de 30 km. Entre eux, la mise en miroir des données est configurée au niveau du système de stockage. De ce fait, des données et des services seront disponibles en cas de panne sur l'un des sites: panne de courant, panne partielle des systèmes de stockage, des contrôleurs, des canaux de communication entre le centre de données et même en cas de panne totale de l'un des sites.
Si l'un des centres de données n'est pas disponible, les machines virtuelles sont migrées vers le site de sauvegarde. Le démarrage d'une machine virtuelle sur un site de sauvegarde (Recovery Time Objective, RTO) prendra environ 3 minutes.
Les clients se voient proposer un contrat de niveau de service (SLA) détaillé. Ses principaux indicateurs: disponibilité des services au niveau de 99,99%; simple - pas plus de 4,38 minutes par mois, paramètres garantis des performances du processeur (MIPS / 1 vCPU), système de disque (IOPS, Go / s), retards dans l'accès aux systèmes de stockage. Pour leur conformité, le prestataire est financièrement responsable.
Metro Cluster Anatomy
Le cloud est construit selon le modèle architectural classique, qui implique l'achat de l'ensemble complexe du matériel et des logiciels nécessaires: serveurs avec l'organisation de l'accès physique et logique, stockage, composants réseau, logiciel de virtualisation, solutions de sécurité.
Deux centres de données à Moscou ont des zones fermées dédiées pour quatre racks avec des nœuds informatiques et de réseau. La solution repose sur des composants fabriqués par Lenovo. En tant que systèmes informatiques matériels, des serveurs 1U Lenovo ThinkSystem SR530 / SR570 / SR630 avec des adaptateurs HBA Emulex 16 Gb Gen6 FC à double port sont utilisés, des baies Lenovo Storage V3700 V2 XP sont utilisées pour le stockage de données et des commutateurs rack 10 Gigabit 32 ports sont utilisés pour le transfert de données avec Lenovo ThinkSystem NE1032 RackSwitch. Le package comprend le logiciel VMware ESXi 6.5 installé en usine sur les serveurs. Les sites sont connectés par deux canaux FC 8 Gbit / s et deux canaux Ethernet 10 Gbit / s.
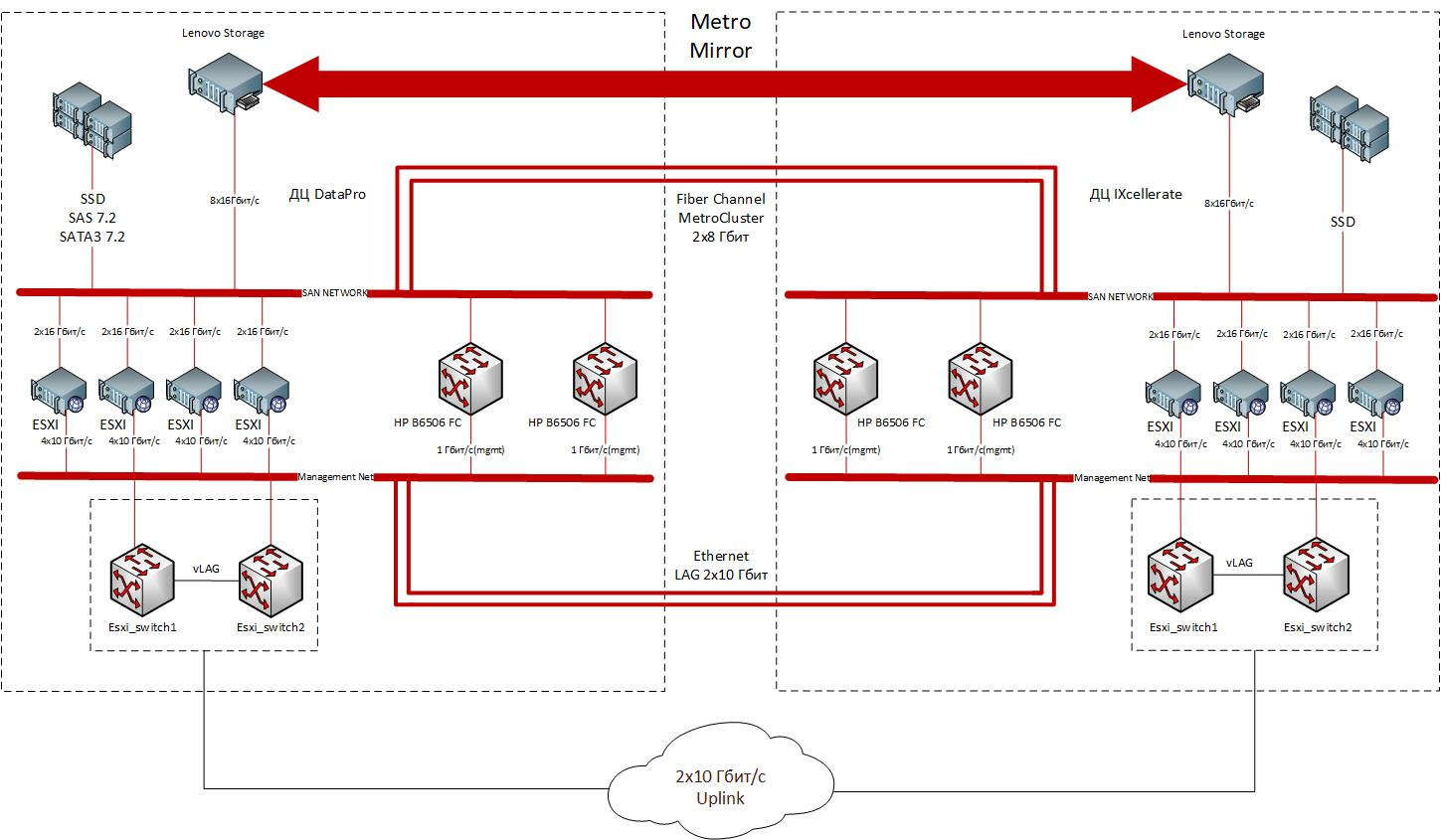
La structure d'un cluster géographiquement distribué. Réparti entre les deux sites, le cluster du métro offre une tolérance aux catastrophes et permet de fournir des services IaaS fiables à un large éventail de clients. Les sites sont connectés par des canaux Ethernet redondants (2x10 Gbit / s) et FC (2x8 Gbit / s).
En acquérant des composants d'infrastructure auprès d'un fournisseur, la fiabilité et la résilience de l'ensemble du complexe sont accrues, les conflits entre les éléments, les normes et les protocoles sont éliminés.
Les efforts conjoints des deux équipes ont permis la réalisation du projet, la préparation et le développement des spécifications techniques, l'installation des équipements, la mise en service, les tests de résistance et la mise en service du cluster métro.
Lenovo Metrocluster prévoit une sauvegarde complète de tous ses éléments: serveurs, stockage, contrôleurs, adaptateurs FC, commutateurs optiques. La réplication synchrone des données au niveau du stockage ne fournit aucun objectif de point de récupération (RPO).
La haute disponibilité a toujours été obtenue en assurant la redondance - cela est également vrai dans le cas de la préparation à des situations extrêmes, lorsque l'ensemble du centre de données doit être protégé contre les pannes de courant ou les catastrophes naturelles. En cas de défaillance de l'un des sites, un cluster dispersé géographiquement, sans interruption des processus de travail, bascule vers un deuxième centre de données. En fait, le cluster de métro est un cluster local avec un système de stockage en miroir, espacé entre deux sites.
Les clusters géographiquement distribués n'ont pas de points de défaillance critiques. Le cluster Metro implémente la réplication mutuelle synchrone des données entre les sites. En cas de problème, le passage à un autre site est totalement transparent et sans intervention de l'administrateur. L'automatisation de ce processus garantit un fonctionnement continu de toutes les applications. Les clusters Metro n'ont pas non plus besoin d'être arrêtés pour mettre à jour leur matériel ou leurs logiciels.
Par exemple, en cas de panne complète d'un serveur, ses responsabilités sont transférées sur un deuxième serveur situé sur le même site en quelques secondes. L'interruption à court terme des entrées-sorties de données qui se produit dans ce cas n'affectera pas le fonctionnement des applications, car les données sont mises en miroir de manière synchrone sur la deuxième plate-forme. En cas de problème de fonctionnement du commutateur, du câble ou du HBA Fibre Channel, une commutation de sauvegarde vers le deuxième centre de données n'est pas requise et l'utilisateur final ne subira aucune diminution des performances de l'application.
En cas de défaillance de l'ensemble du nœud de service, une interruption à court terme (plusieurs secondes) des flux d'E / S se produit: les services sont d'abord transférés vers les nœuds voisins, et la nécessité de basculer vers un nœud géographiquement distant ne se pose que si le site est complètement perturbé.
Dans cette situation, un cluster géographiquement dispersé utilise la redondance au niveau du centre de données pour surmonter l'échec, et les systèmes situés sur le deuxième site prennent en charge tous les services. Ainsi, les serveurs d'applications conservent l'accès à tous les services, mais avec des performances limitées.
Lorsque le site sur lequel la panne s'est produite entrera à nouveau en mode de fonctionnement, il sera nécessaire de ne lui transférer que les données qui ont été modifiées pendant le temps d'arrêt.Par conséquent, après avoir éliminé les problèmes locaux, le centre de données concerné pourra revenir très rapidement au fonctionnement normal.
En cas de perte d'hôte, VMware High Availability (HA) redémarre immédiatement la machine virtuelle sur un site distant. Si l'un des systèmes de stockage tombe en panne, le système de stockage d'un autre site annonce les chemins d'accès au disque aux hôtes restants. Les VM perdues sont redémarrées sur elles, tout se passe automatiquement.
Si la connexion entre les sites est perdue, alors tout continue à fonctionner à sa place et, dès que la connexion est rétablie, le processus de synchronisation commence.
Composition de la solution
Huit serveurs Lenovo ThinkSystem SR630 avec 2 processeurs Intel Xeon Gold 6132 14C 140 W 2,6 GHz, 32 Go de mémoire TruDDR4 2666 MHz (RDIMM), 10 baies de disque 2,5 ", disques SSD M.2 32 Go SATA et logiciel VMware ESXi 6.5 installé en usine.
| Le serveur à deux processeurs au format 1U offre la flexibilité et les performances grâce à la prise en charge des disques durs et des disques SSD avec des interfaces SAS ou SATA (12 SFF ou 4 LFF). La possibilité de connecter des disques NVMe offre des vitesses de lecture et d'écriture élevées. Le logiciel Lenovo XClarity Administrator simplifie la gestion et la maintenance de l'infrastructure. Cette solution de conception est axée sur un équilibre entre performances et prix pour prendre en charge un large éventail de charges de travail, conçu pour un fonctionnement continu à une température de 45 ° C.
|
Deux systèmes de stockage Lenovo Storage V3700 V2 XP avec SSD SAS 2,5 "1,92 To et disque dur 10K 1,2" 2,5 ", avec logiciel Easy Tier, FlashCopy et Remote Mirroring.
| Un ensemble d'outils de stockage fonctionnels vous permet de résoudre efficacement les problèmes avec de gros volumes de données et avec un accès multithread aux ressources d'information.V3700 V2 XP offre la possibilité de consolider les charges, prend en charge la formation de systèmes de stockage capables de prendre en charge de nombreuses applications exigeantes. Le système des processeurs Intel se caractérise par des performances élevées et une vitesse d'échange de données via le bus SAS, des outils fonctionnels qui n'étaient auparavant disponibles que dans les appareils haut de gamme. Le stockage offre une interface Web avec des fonctions de gestion intégrées, fournit la formation de configurations de travail flexibles et leur déploiement rapide à l'aide de la virtualisation, des applications de sauvegarde à l'aide de FlashCopy. Il prend en charge la mise à l'échelle verticale jusqu'à 240 disques 2,5 pouces ou 120 disques dans un facteur de forme 3,5 pouces. Vous pouvez utiliser neuf unités d'extension pour évoluer.
|
Stockage pour Lenovo V3700 V2 avec 20 disques durs 2 To 2,5 "7,2 K
| Le système fournit un ensemble d'outils qui assurent la virtualisation, la mise à l'échelle et la gestion unifiées. Il s'agit d'une solution hybride dotée de capacités de virtualisation. Stockage Lenovo Storage V3700 V2 a deux contrôleurs RAID, vous permet d'utiliser n'importe quel format de stockage - à la fois les disques durs 3,5 "et le HDD ou SSD 2,5". SHD est livré en standard avec un logiciel système avec les fonctions de virtualisation du stockage interne, de provisionnement fin, de migration de données unidirectionnelle, de FlashCopy (64 copies). Fonctionnalités supplémentaires - FlashCopy (2048 copies), Easy Tier, Remote Mirroring.
|
32- Ethernet 10 / Lenovo ThinkSystem NE1032 SFP+ SR.
| 24 10GBase-T 8 SFP+ 10 / . Lenovo Cloud NOS, . NE1032 . L2/L3 IP-, BGP, , Lenovo XClarity.
|
Fibre Channel Lenovo B6505 FC SAN c 12 SFP 16 /.
| Fibre Channel 5- -. - 16 /.
|
