
Le sujet de l'amélioration des performances des systèmes d'exploitation et de la recherche de goulots d'étranglement gagne en popularité. Dans cet article, nous parlerons d'un outil pour trouver ces endroits mêmes en utilisant l'exemple de la pile de blocs sous Linux et d'un cas de dépannage d'un hôte.
Exemple 1. Test
Rien ne marche
Les tests dans notre département sont des synthétiques sur le matériel du produit et des tests de logiciels d'application ultérieurs. Nous avons reçu un lecteur Intel Optane pour les tests. Nous avons déjà écrit sur le test des disques Optane
dans notre blog .
Le disque a été installé sur un serveur standard construit pendant une période relativement longue sous l'un des projets cloud.
Pendant le test, le disque ne s'est pas montré de la meilleure façon: pendant le test avec une profondeur de file d'attente de 1 requête pour 1 flux, en blocs de 4 Ko environ ~ 70 Ko. Et cela signifie que le temps de réponse est énorme: environ 13 microsecondes par requête!
C'est étrange, car la
spécification promet "Latence - Lire 10 µs", et nous avons obtenu 30% de plus, la différence est assez significative. Le disque a été réorganisé sur une autre plate-forme, un assemblage plus «frais» utilisé dans un autre projet.
Pourquoi ça marche?
C'est drôle, mais le lecteur sur la nouvelle plate-forme a fonctionné comme il se doit. Performances augmentées, latence diminuée, CPU par étagère, 1 flux par requête, blocs de 4 octets, ~ 106 Ko à ~ 9 microsecondes par requête.
Et puis il est temps de
comparer les paramètres pour obtenir des
performances de
jambes larges. Après tout, nous nous demandons pourquoi? Avec
perf, vous pouvez:
- Prenez des relevés de compteur matériel: le nombre d'appels d'instructions, de ratés de cache, de branches incorrectement prédites, etc. (Événements PMU)
- Supprimer les informations des points de vente statiques, le nombre d'occurrences
- Effectuer un traçage dynamique
Pour la vérification, nous avons utilisé l'échantillonnage du processeur.
L'essentiel est que
perf puisse compiler la trace de pile entière d'un programme en cours d'exécution. Naturellement, l'exécution de
perf introduira un retard dans le fonctionnement de l'ensemble du système. Mais nous avons le drapeau
-F # , où
# est la fréquence d'échantillonnage, mesurée en Hz.
Il est important de comprendre que plus la fréquence d'échantillonnage est élevée, plus il est probable qu'il intercepte un appel à une fonction particulière, mais plus le profileur apporte de freins au système. Plus la fréquence est basse, plus il est probable que nous ne verrons pas une partie de la pile.
Lorsque vous choisissez une fréquence, vous devez être guidé par le bon sens et une astuce - essayez de ne pas définir une fréquence paire, afin de ne pas vous retrouver dans une situation où un travail exécuté sur une minuterie avec cette fréquence pénètre dans les échantillons.
Un autre point qui est trompeur au départ - le logiciel doit être compilé avec le drapeau
-fno-omit-frame-pointer , si cela est bien sûr possible. Sinon, dans la trace, au lieu des noms de fonction, nous verrons
des valeurs
inconnues solides. Pour certains logiciels, les symboles de débogage sont fournis dans un package séparé, par exemple
someutil-dbg . Il est recommandé de les installer avant d'exécuter
perf .
Nous avons effectué les actions suivantes:
- Extrait de fio de git: //git.kernel.dk/fio.git, tag fio-3.9
- Ajout de l' option -fno-omit-frame-pointer à CPPFLAGS dans Makefile
- Lancement de make -j8
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1G
L'option -g est nécessaire pour capturer la pile de traces.
Vous pouvez voir le résultat par la commande:
perf report -g fractal
L'option
-g fractal est nécessaire pour que les pourcentages reflétant le nombre d'échantillons avec cette fonction et montrés par
perf soient relatifs à la fonction appelante, dont le nombre d'appels est pris à 100%.
Vers la fin de la longue pile d'appels fio sur la plate-forme «nouvelle construction», nous verrons:
Et sur la plateforme «old build»:

Super! Mais je veux de beaux flammes.
Construction de flammes
Pour être belle, il existe deux outils:
- Graphique de flamme relativement plus statique
- Flamescope , qui permet de sélectionner une période de temps spécifique parmi les échantillons collectés. Ceci est très utile lorsque le code de recherche charge le CPU avec de courtes rafales.
Ces utilitaires acceptent
perf script> result comme entrée.
Téléchargez le
résultat et envoyez-le via des tuyaux à
svg :
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svg
Ouvrez dans un navigateur et profitez d'une image cliquable.
Vous pouvez utiliser une autre méthode:
- Ajouter le résultat au flamescope / exemple /
- Exécutez python ./run.py
- On passe par le navigateur vers le port 5000 de l'hôte local
Que voyons-nous finalement?
Un bon fio passe beaucoup de temps à
voter :
Un mauvais fio passe du temps n'importe où, mais pas dans les sondages:
À première vue, il semble que l'interrogation ne fonctionne pas sur l'ancien hôte, mais partout le noyau 4.15 est du même assemblage et l'interrogation est activée par défaut sur les disques NVMe. Vérifiez si l'interrogation est activée dans
sysfs :
Pendant les tests, des appels
preadv2 avec l'indicateur
RWF_HIPRI sont
utilisés - une condition nécessaire pour que l'interrogation fonctionne. Et, si vous étudiez attentivement le graphique de la flamme (ou la capture d'écran précédente de la sortie du
rapport de performance), vous pouvez le trouver, mais cela prend très peu de temps.
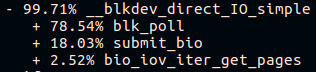
La deuxième chose visible est la pile d'appels différente pour la fonction submit_bio () et le manque d'appels à io_schedule (). Examinons de plus près la différence à l'intérieur de submit_bio ().
Plate-forme lente "ancienne construction":
Plateforme rapide "fraîche":
Il semble que sur une plate-forme lente, la demande va un long chemin vers l'appareil, tout en entrant dans le
planificateur kyber . Vous pouvez en savoir plus sur les planificateurs d'E / S dans
notre article .
Une fois le
kyber éteint, le même test fio a montré une latence moyenne d'environ 10 microsecondes, comme indiqué dans la spécification. Super!
Mais d'où vient la différence dans une autre microseconde?
Et si un peu plus profond?
Comme déjà mentionné,
perf vous permet de collecter des statistiques à partir de compteurs matériels. Essayons de voir le nombre d'échecs de cache et d'instructions par cycle:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10


Les résultats montrent qu'une plate-forme rapide exécute plus d'instructions pour le cycle du processeur et présente un pourcentage plus faible de ratés de cache pendant l'exécution. Bien entendu, nous n'entrerons pas dans les détails du fonctionnement des différentes plateformes matérielles dans le cadre de cet article.
Exemple 2. Épicerie
Quelque chose ne va pas
Dans le travail d'un système de stockage distribué, une augmentation de la charge sur le CPU sur l'un des hôtes a été observée avec une augmentation du trafic entrant. Les hôtes sont des pairs, des pairs et ont un matériel et des logiciels identiques.
Regardons la charge CPU:
~
Le problème est survenu à 09:23:46 et nous voyons que le processus a fonctionné dans l'espace du noyau exclusivement pendant toute la seconde. Voyons ce qui se passait à l'intérieur.
Pourquoi si lent?
Dans ce cas, nous avons prélevé des échantillons de l'ensemble du système:
perf record -a -g -- sleep 22 perf script > perf.results
L'option
-a est nécessaire ici pour que
perf supprime les traces de tous les CPU.
Ouvrez
perf.results avec
flamescope pour suivre le moment de l'augmentation de la charge du processeur.
Nous avons devant nous une "carte thermique" dont les deux axes (X et Y) représentent le temps.
Sur l'axe X, l'espace est divisé en secondes, et sur l'axe Y, en segments de 20 millisecondes en X secondes. Le temps passe de bas en haut et de gauche à droite. Les carrés les plus brillants ont le plus grand nombre d'échantillons. Autrement dit, le processeur à ce moment-là a fonctionné le plus activement.
En fait, nous nous intéressons à la tache rouge au milieu. Sélectionnez-le avec la souris, cliquez et voyez ce qu'il cache:
En général, il est déjà évident que le problème est le
fonctionnement lent
tcp_recvmsg et
skb_copy_datagram_iovec .
Pour plus de clarté, comparez avec des exemples d'un autre hôte sur lequel la même quantité de trafic entrant ne pose pas de problème:
Sur la base du fait que nous avons la même quantité de trafic entrant, des plates-formes identiques qui fonctionnent depuis longtemps sans s'arrêter, nous pouvons supposer que les problèmes sont survenus du côté du fer. La fonction
skb_copy_datagram_iovec copie les données de la structure du noyau vers la structure dans l'espace utilisateur pour les transmettre à l'application. Il y a probablement des problèmes de mémoire hôte. Dans le même temps, il n'y a aucune erreur dans les journaux.
Nous redémarrons la plateforme. Lors du chargement du BIOS, nous voyons un message concernant une barre de mémoire cassée. Remplacement, l'hôte démarre et le problème avec un CPU surchargé n'est plus reproduit.
Postscript
Performances du système avec perf
De manière générale, sur un système occupé, l'exécution de
perf peut
entraîner un retard dans le traitement des demandes. La taille de ces retards dépend également de la charge sur le serveur.
Essayons de trouver ce retard:
~
La différence n'est pas très visible, seulement environ 8 nanosecondes.
Voyons ce qui se passe si vous augmentez la charge:
~
Ici, la différence devient déjà perceptible. On peut dire que le système a ralenti de moins de 1%, mais essentiellement perdre environ 7 kiops sur un système lourdement chargé peut entraîner des problèmes.
Il est clair que cet exemple est synthétique, néanmoins il est très révélateur.
Essayons d'exécuter un autre test synthétique qui calcule les nombres premiers -
sysbench :
~
Ici, vous pouvez voir que même le temps de traitement minimum a augmenté de 270 microsecondes.
Au lieu d'une conclusion
Perf est un outil très puissant pour analyser les performances du système et le débogage. Cependant, comme pour tout autre outil, vous devez garder le contrôle et vous rappeler que tout système chargé sous surveillance étroite fonctionne moins bien.
Liens connexes: