Article préparé par: Alexander Virilin xscrew - auteur, chef du service d'infrastructure réseau, Leonid Klyuyev - éditeur
Nous continuons de vous familiariser avec la structure interne de
Yandex.Cloud . Aujourd'hui, nous parlerons des réseaux - nous vous expliquerons comment fonctionne l'infrastructure de réseau, pourquoi elle utilise le paradigme MPLS impopulaire pour les centres de données, quelles autres décisions complexes nous avons dû prendre dans le processus de construction d'un réseau cloud, comment nous le gérons et quel type de surveillance nous utilisons.
Le réseau dans le cloud se compose de trois couches. La couche inférieure est l'infrastructure déjà mentionnée. Il s'agit d'un réseau physique «de fer» à l'intérieur des centres de données, entre les centres de données et dans les lieux de connexion aux réseaux externes. Un réseau virtuel est construit au-dessus de l'infrastructure réseau et les services réseau sont construits au-dessus du réseau virtuel. Cette structure n'est pas monolithique: les couches se croisent, le réseau virtuel et les services réseau interagissent directement avec l'infrastructure réseau. Étant donné que le réseau virtuel est souvent appelé superposition, nous appelons généralement la sous-infrastructure de réseau.

Désormais, l'infrastructure Cloud est basée dans la région centrale de la Russie et comprend trois zones d'accès, c'est-à-dire trois centres de données indépendants répartis géographiquement. Indépendant - indépendant les uns des autres dans le contexte des réseaux, de l'ingénierie et des systèmes électriques, etc.
À propos des caractéristiques. La géographie de l'emplacement des centres de données est telle que le temps d'aller-retour (RTT) du temps d'aller-retour entre eux est toujours de 6 à 7 ms. La capacité totale des canaux a déjà dépassé 10 térabits et ne cesse de croître, car Yandex dispose de son propre réseau de fibre optique entre les zones. Comme nous ne louons pas de canaux de communication, nous pouvons rapidement augmenter la capacité de la bande entre les DC: chacun d'eux utilise un équipement de multiplexage spectral.
Voici la représentation la plus schématique des zones:
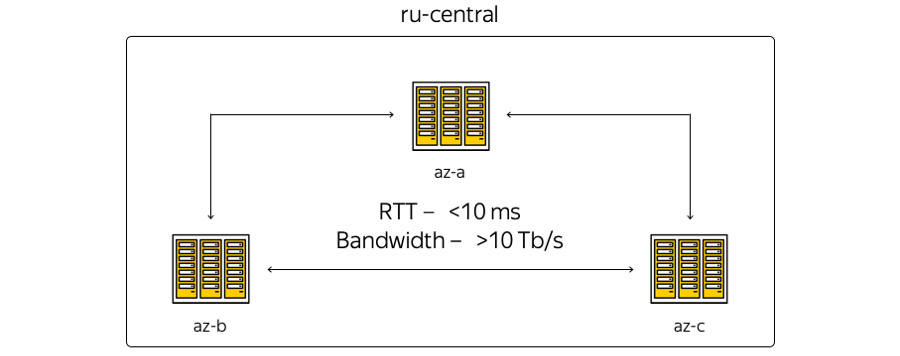
La réalité, quant à elle, est légèrement différente:
Voici le réseau de base actuel de Yandex dans la région. Tous les services Yandex fonctionnent en plus, une partie du réseau est utilisée par le Cloud. (Il s'agit d'une image à usage interne, par conséquent, les informations de service sont délibérément cachées. Néanmoins, il est possible d'estimer le nombre de nœuds et de connexions.) La décision d'utiliser le réseau de base était logique: nous ne pouvions rien inventer, mais réutiliser l'infrastructure actuelle - «souffert» au cours des années de développement.
Quelle est la différence entre la première photo et la seconde? Tout d'abord, les zones d'accès ne sont pas directement liées: des sites techniques sont situés entre elles. Les sites ne contiennent pas d'équipement serveur - seuls des périphériques réseau pour assurer la connectivité y sont placés. Les points de présence où Yandex et Cloud se connectent au monde extérieur sont connectés à des sites techniques. Tous les points de présence fonctionnent pour toute la région. Soit dit en passant, il est important de noter que du point de vue de l'accès externe à partir d'Internet, toutes les zones d'accès au Cloud sont équivalentes. En d'autres termes, ils offrent la même connectivité, c'est-à-dire la même vitesse et le même débit, ainsi que des latences tout aussi faibles.
En outre, il existe des équipements sur les points de présence, auxquels - s'il existe des ressources sur site et une volonté d'étendre l'infrastructure locale avec des installations cloud - les clients peuvent se connecter via un canal garanti. Cela peut être fait avec l'aide de partenaires ou par vous-même.
Le réseau central est utilisé par le Cloud comme transport MPLS.
MPLS
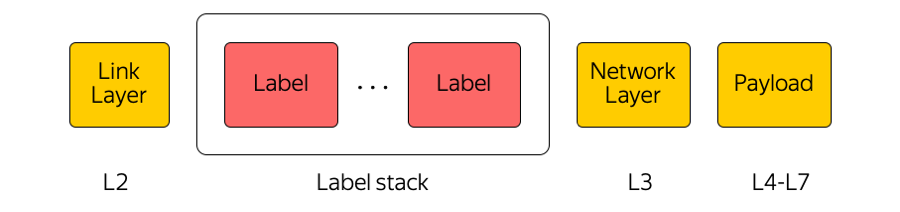
La commutation d'étiquettes multiprotocole est une technologie largement utilisée dans notre industrie. Par exemple, lorsqu'un paquet est transféré entre des zones d'accès ou entre une zone d'accès et Internet, les équipements de transport ne prêtent attention qu'à l'étiquette supérieure, sans «penser» à ce qui se trouve en dessous. De cette façon, MPLS vous permet de masquer la complexité du cloud à la couche de transport. En général, nous, dans le Cloud, aimons beaucoup MPLS. Nous l'avons même intégré au niveau inférieur et l'avons utilisé directement dans l'usine de commutation du centre de données:

(En fait, il existe de nombreux liens parallèles entre les commutateurs Leaf et les épines.)
Pourquoi MPLS?
Certes, MPLS n'est pas souvent trouvé dans les réseaux de centres de données. Souvent, des technologies complètement différentes sont utilisées.
Nous utilisons MPLS pour plusieurs raisons. Tout d'abord, nous avons trouvé pratique d'unifier les technologies du plan de contrôle et du plan de données. Autrement dit, au lieu de certains protocoles dans le réseau du centre de données, d'autres protocoles dans le réseau central et la jonction de ces protocoles - un seul MPLS. Ainsi, nous avons unifié la pile technologique et réduit la complexité du réseau.
Deuxièmement, dans le Cloud, nous utilisons diverses appliances réseau, telles que Cloud Gateway et Network Load Balancer. Ils doivent communiquer entre eux, envoyer du trafic vers Internet et vice versa. Ces appliances réseau peuvent être mises à l'échelle horizontalement avec une charge croissante, et puisque le Cloud est construit selon le modèle d'hyperconvergence, elles peuvent être lancées à n'importe quel endroit du point de vue du réseau dans le centre de données, c'est-à-dire dans un pool de ressources commun.
Ainsi, ces appliances peuvent démarrer derrière n'importe quel port du commutateur rack où se trouve le serveur et commencer à communiquer via MPLS avec le reste de l'infrastructure. Le seul problème dans la construction d'une telle architecture était l'alarme.
Alarme
La pile de protocoles MPLS classique est assez complexe. C'est d'ailleurs l'une des raisons de la non-prolifération du MPLS dans les réseaux de centres de données.
À notre tour, nous n'avons utilisé ni IGP (Interior Gateway Protocol), ni LDP (Label Distribution Protocol), ni d'autres protocoles de distribution d'étiquettes. Seul BGP (Border Gateway Protocol) Label-Unicast est utilisé. Chaque appliance, qui s'exécute, par exemple, comme une machine virtuelle, crée une session BGP avant le commutateur Leaf monté en rack.
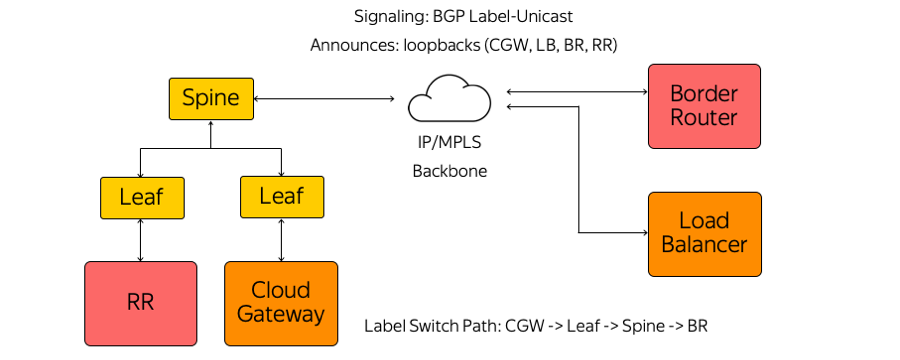
Une session BGP est construite à une adresse pré-connue. Il n'est pas nécessaire de configurer automatiquement le commutateur pour exécuter chaque appliance. Tous les commutateurs sont préconfigurés et cohérents.
Au sein d'une session BGP, chaque appliance envoie son propre bouclage et reçoit des bouclages du reste des appareils avec lesquels elle devra échanger du trafic. Des exemples de tels dispositifs sont plusieurs types de réflecteurs de route, de routeurs de bordure et d'autres appareils. Par conséquent, des informations sur la façon de se rejoindre s'affichent sur les appareils. À partir de la passerelle Cloud via le commutateur Leaf, le commutateur Spine et le réseau jusqu'au routeur frontière, un chemin de commutateur d'étiquette est créé. Les commutateurs sont des commutateurs L3 qui se comportent comme un routeur de commutation d'étiquettes et ne connaissent pas la complexité qui les entoure.
MPLS à tous les niveaux de notre réseau, entre autres, nous a permis d'utiliser le concept de manger votre propre nourriture pour chien.
Mangez votre propre nourriture pour chien
D'un point de vue réseau, ce concept implique que nous vivons dans la même infrastructure que nous fournissons à l'utilisateur. Voici des schémas de racks dans les zones d'accessibilité:

L'hôte cloud prend la charge de l'utilisateur, contient ses machines virtuelles. Et littéralement, un hôte voisin dans un rack peut supporter la charge d'infrastructure du point de vue du réseau, y compris les réflecteurs d'itinéraire, les serveurs de gestion, de surveillance, etc.
Pourquoi cela at-il été fait? Il y avait une tentation d'exécuter des réflecteurs de route et tous les éléments d'infrastructure dans un segment distinct tolérant aux pannes. Ensuite, si le segment d'utilisateurs était tombé en panne quelque part dans le centre de données, les serveurs d'infrastructure continueraient à gérer l'ensemble de l'infrastructure réseau. Mais cette approche nous a semblé vicieuse - si nous ne faisons pas confiance à notre propre infrastructure, comment pouvons-nous la fournir à nos clients? Après tout, absolument tout le Cloud, tous les réseaux virtuels, les services utilisateur et cloud fonctionnent en plus.
Par conséquent, nous avons abandonné un segment distinct. Nos éléments d'infrastructure fonctionnent dans la même topologie réseau et la même connectivité réseau. Naturellement, ils fonctionnent en triple instance - tout comme nos clients lancent leurs services dans le Cloud.
Usine IP / MPLS
Voici un exemple de diagramme de l'une des zones de disponibilité:
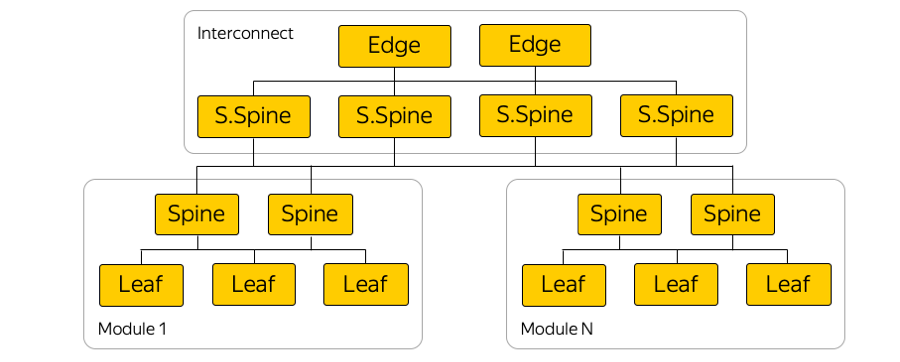
Dans chaque zone de disponibilité, il y a environ cinq modules et dans chaque module une centaine de racks. Commutateurs montés sur châssis, ils sont connectés au sein de leur module par le niveau Spine, et la connectivité inter-modules est assurée via l'interconnexion réseau. Il s'agit du niveau suivant, qui comprend les commutateurs dits Super-Spines et Edge, qui connectent déjà les zones d'accès. Nous avons délibérément abandonné la L2, nous ne parlons que de la connectivité IP / MPLS L3. BGP est utilisé pour distribuer les informations de routage.
En fait, il y a beaucoup plus de connexions parallèles que dans l'image. Un si grand nombre de connexions ECMP (multi-trajets à coût égal) impose des exigences de surveillance particulières. De plus, il existe, à première vue, des limites inattendues dans l'équipement - par exemple, le nombre de groupes ECMP.
Connexion au serveur
En raison d'investissements puissants, Yandex construit des services de telle manière qu'une défaillance d'un serveur, d'un rack de serveur, d'un module ou même d'un centre de données complet n'entraîne jamais un arrêt complet du service. Si nous avons des problèmes de réseau - supposons qu'un commutateur de montage en rack soit cassé - les utilisateurs externes ne voient jamais cela.
Yandex.Cloud est un cas particulier. Nous ne pouvons pas dicter au client comment construire ses propres services, et nous avons décidé de niveler ce point de défaillance unique possible. Par conséquent, tous les serveurs du cloud sont connectés à deux commutateurs montés en rack.
Nous n'utilisons pas non plus de protocoles de redondance au niveau L2, mais avons immédiatement commencé à utiliser uniquement L3 avec BGP - encore une fois, pour des raisons d'unification des protocoles. Cette connexion fournit à chaque service une connectivité IPv4 et IPv6: certains services fonctionnent sur IPv4 et certains services sur IPv6.
Physiquement, chaque serveur est connecté par deux interfaces de 25 gigabits. Voici une photo du centre de données:

Vous voyez ici deux commutateurs montés en rack avec des ports de 100 gigabits. Des câbles de dérivation divergents sont visibles, divisant le port de 100 gigabits du commutateur en 4 ports de 25 gigabits par serveur. Nous appelons ces câbles "hydre".
Gestion des infrastructures
L'infrastructure de réseau Cloud ne contient aucune solution de gestion propriétaire: tous les systèmes sont soit open source avec personnalisation pour le Cloud, soit entièrement auto-écrits.
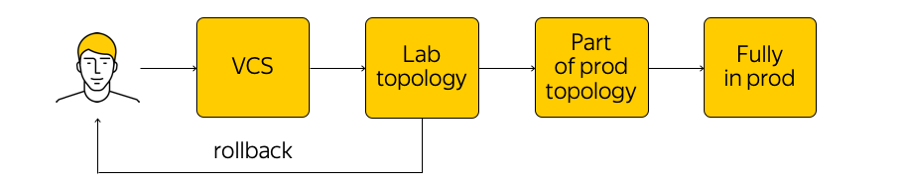
Comment cette infrastructure est-elle gérée? Ce n'est pas interdit dans le Cloud, mais il est fortement déconseillé d'aller sur un périphérique réseau et de faire des ajustements. Il y a l'état actuel du système, et nous devons appliquer les changements: arriver à un nouvel état cible. "Exécutez un script" à travers toutes les glandes, changez quelque chose dans la configuration - vous ne devriez pas faire cela. Au lieu de cela, nous apportons des modifications aux modèles, à une seule source de système de vérité, et validons notre modification au système de contrôle de version. C'est très pratique, car vous pouvez toujours effectuer une restauration, consulter l'historique, savoir qui est responsable du commit, etc.
Lorsque nous avons effectué les modifications, des configurations sont générées et nous les déployons dans la topologie de test de laboratoire. Du point de vue du réseau, il s'agit d'un petit nuage qui répète complètement toute la production existante. Nous verrons immédiatement si les changements souhaités cassent quelque chose: d'une part, par la surveillance, et d'autre part, par les retours de nos utilisateurs internes.
Si la surveillance indique que tout est calme, alors nous continuons à déployer - mais n'appliquons le changement qu'à une partie de la topologie (deux ou plusieurs accessibilités «n'ont pas le droit» de s'arrêter pour la même raison). De plus, nous continuons de suivre de près le suivi. Il s'agit d'un processus assez compliqué, dont nous parlerons ci-dessous.
Après avoir vérifié que tout va bien, nous appliquons le changement à toute la production. À tout moment, vous pouvez revenir en arrière et revenir à l'état précédent du réseau, suivre et résoudre rapidement le problème.
Suivi
Nous avons besoin d'une surveillance différente. L'un des plus recherchés est la surveillance de la connectivité de bout en bout. À tout moment, chaque serveur doit pouvoir communiquer avec n'importe quel autre serveur. Le fait est que s'il y a un problème quelque part, alors nous voulons savoir exactement où le plus tôt possible (c'est-à-dire quels serveurs ont des problèmes d'accès les uns aux autres). Assurer la connectivité de bout en bout est notre principale préoccupation.
Chaque serveur répertorie un ensemble de tous les serveurs avec lesquels il devrait pouvoir communiquer à tout moment. Le serveur prend un sous-ensemble aléatoire de cet ensemble et envoie des paquets ICMP, TCP et UDP à toutes les machines sélectionnées. Ceci vérifie s'il y a des pertes sur le réseau, si le retard a augmenté, etc. L'ensemble du réseau est «appelé» dans l'une des zones d'accès et entre elles. Les résultats sont envoyés à un système centralisé qui les visualise pour nous.
Voici à quoi ressemblent les résultats quand tout n'est pas très bon:
Ici, vous pouvez voir quels segments de réseau il y a un problème entre (dans ce cas, A et B) et où tout va bien (A et D). Des serveurs spécifiques, des commutateurs montés en rack, des modules et des zones de disponibilité entières peuvent être affichés ici. Si l'un des éléments ci-dessus devient la source du problème, nous le verrons en temps réel.
De plus, il existe une surveillance des événements. Nous surveillons de près toutes les connexions, les niveaux de signal sur les émetteurs-récepteurs, les sessions BGP, etc. Supposons que trois sessions BGP soient construites à partir d'un segment de réseau, dont l'un a été interrompu la nuit. Si nous configurons la surveillance de sorte que la chute d'une session BGP ne soit pas critique pour nous et puisse attendre jusqu'au matin, alors la surveillance ne réveillera pas les ingénieurs réseau. Mais si la deuxième des trois sessions tombe, un ingénieur appelle automatiquement.
En plus de la surveillance de bout en bout et des événements, nous utilisons une collection centralisée de journaux, leur analyse en temps réel et leur analyse ultérieure. Vous pouvez voir les corrélations, identifier les problèmes et découvrir ce qui se passait sur l'équipement réseau.
Le sujet de surveillance est assez grand, il y a une énorme marge d'amélioration. Je veux amener le système à une plus grande automatisation et à une véritable auto-guérison.
Et ensuite?
Nous avons de nombreux plans. Il est nécessaire d'améliorer les systèmes de contrôle, la surveillance, la commutation des usines IP / MPLS et bien plus encore.
Nous recherchons également activement des commutateurs à boîtier blanc. Il s'agit d'un appareil "fer" prêt à l'emploi, un interrupteur sur lequel vous pouvez faire rouler votre logiciel. Premièrement, si tout est fait correctement, il sera possible de «traiter» les commutateurs de la même manière que pour les serveurs, de créer un processus CI / CD vraiment pratique, de déployer progressivement des configurations, etc.
Deuxièmement, s'il y a des problèmes, il est préférable de garder un groupe d'ingénieurs et de développeurs qui régleront ces problèmes plutôt que d'attendre longtemps une solution du fournisseur.
Pour que tout fonctionne, le travail est en cours dans deux directions:
- Nous avons considérablement réduit la complexité de l'usine IP / MPLS. D'une part, le niveau du réseau virtuel et les outils d'automatisation de celui-ci, au contraire, sont devenus un peu plus compliqués. D'un autre côté, le réseau sous-jacent lui-même est devenu plus facile. En d'autres termes, il existe une certaine «quantité» de complexité qui ne peut pas être sauvegardée. Il peut être "jeté" d'un niveau à un autre - par exemple, entre les niveaux du réseau ou du niveau du réseau au niveau de l'application. Et vous pouvez distribuer correctement cette complexité, ce que nous essayons de faire.
- Et bien sûr, nous finalisons notre ensemble d'outils pour gérer l'ensemble de l'infrastructure.
C'est tout ce que nous voulions parler de notre infrastructure réseau.
Voici un lien vers la chaîne Cloud Telegram avec des nouvelles et des conseils.