Cet article a été écrit en collaboration avec ananaskelly .
Présentation
Bonjour à tous, Habr! Travaillant au Center for Speech Technology à Saint-Pétersbourg, nous avons acquis une petite expérience dans la résolution des problèmes de classification et de détection des événements acoustiques et avons décidé que nous sommes prêts à les partager avec vous. Le but de cet article est de vous présenter quelques tâches et de parler du concours de traitement automatique du son DCASE 2018 . En vous parlant du concours, nous nous passerons de formules et définitions complexes liées à l'apprentissage automatique, de sorte que la signification générale de l'article sera comprise par un large public .
Pour ceux qui étaient intéressés par l' assemblage du classificateur , nous avons préparé un petit code python, et en utilisant le lien sur le github, vous pouvez trouver un cahier, où nous utilisons l'exemple de la deuxième piste du concours DCASE pour créer un réseau convolutionnel simple sur des kéros pour classer des fichiers audio. Là, nous parlons un peu du réseau et des fonctionnalités utilisées pour la formation, et comment utiliser une architecture simple pour obtenir un résultat proche de la ligne de base ( MAP @ 3 = 0,6).
De plus, les approches de base pour résoudre les problèmes (base) proposées par les organisateurs seront décrites ici. Également à l'avenir, il y aura plusieurs articles où nous parlerons plus en détail et en détail à la fois de notre expérience de participation au concours et des solutions proposées par d'autres participants au concours. Des liens vers ces articles apparaîtront progressivement ici.
Certes, beaucoup de gens n'ont absolument aucune idée d'une sorte de «DCASE» , alors essayons de déterminer de quel type de fruit il s'agit et avec quoi il est mangé. Le concours « DCASE » a lieu chaque année, et chaque année plusieurs tâches sont consacrées à la résolution de problèmes dans le domaine de la classification des enregistrements audio et de la détection des événements acoustiques. Tout le monde peut participer au concours, c'est gratuit, pour cela il suffit de s'inscrire simplement sur le site en tant que participant. À l'issue du concours, une conférence est organisée sur les mêmes thèmes, mais contrairement au concours lui-même, la participation est déjà payante et nous n'en parlerons plus. Les récompenses pour les meilleures décisions ne sont généralement pas utilisées, mais il existe des exceptions (par exemple, la 3e tâche en 2018). Cette année, les organisateurs ont proposé les 5 tâches suivantes:
- Classification des scènes acoustiques (subdivisées en 3 sous-tâches)
A. Ensembles de données de formation et de test enregistrées sur le même appareil
Ensembles de données de formation et de test enregistrées sur différents appareils
C. La formation est autorisée en utilisant des données non fournies par les organisateurs - Classification des événements acoustiques
- Détection des chants d'oiseaux
- Détection d'événements acoustiques dans la maison à l'aide d'un ensemble de données faiblement étiqueté
- Classification de l'activité du ménage dans la pièce selon l'enregistrement multicanal
À propos de la détection et de la classification
Comme nous pouvons le voir, les noms de toutes les tâches contiennent l'un des deux mots: «détection» ou «classification». Clarifions quelle est la différence entre ces concepts afin qu'il n'y ait pas de confusion.
Imaginez que nous ayons un enregistrement audio sur lequel un chien aboie à un moment, et un chat miaule à un autre, et il n'y a tout simplement pas d'autres événements là-bas. Ensuite, si nous voulons comprendre exactement quand ces événements se produisent, nous devons résoudre le problème de la détection d'un événement acoustique. Autrement dit, nous devons connaître les heures de début et de fin de chaque événement. Après avoir résolu le problème de détection, nous savons exactement quand les événements se produisent, mais nous ne savons pas exactement qui émet les sons trouvés - alors nous devons résoudre le problème de classification, c'est-à-dire déterminer ce qui s'est exactement passé dans une période de temps donnée.
Pour comprendre la description des tâches du concours, ces exemples suffiront, ce qui signifie que la partie introductive est terminée, et nous pouvons procéder à une description détaillée des tâches elles-mêmes.
Piste 1. Classification des scènes acoustiques
La première tâche consiste à déterminer l'environnement (scène acoustique) dans lequel le son a été enregistré, par exemple, «Station de métro», «Aéroport» ou «Rue piétonne». La solution à ce problème peut être utile pour évaluer l'environnement avec un système d'intelligence artificielle, par exemple, dans les voitures avec pilote automatique.
Dans cette tâche, les ensembles de données mobiles TUT Urban Acoustic Scenes 2018 et TUT Urban Acoustic Scenes 2018, qui ont été préparés par l'Université de technologie de Tampere (Finlande), ont été présentés pour la formation. Une description détaillée de la préparation de l'ensemble de données, ainsi que la solution de base, est décrite dans l' article .
Au total, 10 scènes acoustiques ont été présentées pour le concours, que les participants devaient prévoir.
Sous-tâche A
Comme nous l'avons déjà dit, la tâche est divisée en 3 sous-tâches, dont chacune diffère par la qualité des enregistrements audio. Par exemple, dans la sous-tâche A, des microphones spéciaux ont été utilisés pour l'enregistrement, qui étaient situés dans les oreilles humaines. Ainsi, l'enregistrement stéréo s'est rapproché de la perception humaine du son. Les participants ont eu la possibilité d'utiliser cette approche de l'enregistrement afin d'améliorer la qualité de reconnaissance de la scène acoustique.
Sous-tâche B
Dans la sous-tâche B, d'autres appareils (par exemple, des téléphones portables) ont également été utilisés pour l'enregistrement. Les données de la sous-tâche A ont été converties en format mono, la fréquence d'échantillonnage a été réduite, il n'y a pas de simulation de «l'audibilité» du son par une personne dans l'ensemble de données pour cette tâche, mais il y a plus de données pour la formation.
Sous-tâche C
L'ensemble de données pour la sous-tâche C est le même que pour la sous-tâche A, mais pour résoudre ce problème, il est autorisé d'utiliser toutes les données externes que le participant peut trouver. Le but de résoudre ce problème est de savoir s'il est possible d'améliorer le résultat obtenu dans la sous-tâche A en utilisant des données tierces.
La qualité des décisions sur cette piste a été évaluée par la métrique de précision .
La ligne de base de cette tâche est un réseau de neurones convolutionnels à deux couches qui apprend des logarithmes de petits spectrogrammes des données audio originales. L'architecture proposée utilise les techniques standard BatchNormalization et Dropout. Le code sur GitHub peut être vu ici .
Piste 2. Classification des événements acoustiques
Dans cette tâche, il est proposé de créer un système qui classe les événements acoustiques. Un tel système peut être un ajout aux maisons intelligentes, augmenter la sécurité dans les endroits surpeuplés ou faciliter la vie des personnes malentendantes.
L'ensemble de données pour cette tâche se compose de fichiers extraits de l' ensemble de données Freesound et balisés à l'aide de balises de l' AudioSet de Google. Plus en détail, le processus de préparation de l'ensemble de données est décrit par un article préparé par les organisateurs du concours.
Revenons à la tâche elle-même, qui présente plusieurs fonctionnalités.
Tout d'abord, les participants ont dû créer un modèle capable d'identifier les différences entre des événements acoustiques de nature très différente. L'ensemble de données est divisé en classe 41, il présente divers instruments de musique, des sons émis par des humains, des animaux, des sons domestiques et plus encore.
Deuxièmement, en plus du balisage habituel des données, il existe également des informations supplémentaires sur la vérification manuelle de l'étiquette. Autrement dit, les participants savent quels fichiers de l'ensemble de données ont été vérifiés par la personne pour vérifier leur conformité à l'étiquette, et lesquels ne le sont pas. Comme la pratique l'a montré, les participants qui ont utilisé ces informations supplémentaires d'une manière ou d'une autre ont remporté des prix pour résoudre ce problème.
De plus, il faut dire que la durée des enregistrements dans l'ensemble de données varie considérablement: de 0,3 seconde à 30 secondes. Dans ce problème, la quantité de données par classe, sur laquelle le modèle doit être formé, varie également considérablement. Ceci est mieux représenté sous forme d'histogramme, le code de construction qui est tiré d'ici .
Comme vous pouvez le voir sur l'histogramme, le balisage manuel pour les classes présentées est également déséquilibré, ce qui ajoute des difficultés si vous souhaitez utiliser ces informations lors de la formation des modèles.
Les résultats de cette piste ont été évalués à l'aide de la métrique d'exactitude moyenne (précision moyenne moyenne, MAP @ 3), une démonstration assez simple du calcul de cette métrique avec des exemples et du code peut être trouvée ici .
Piste 3. Détection du chant des oiseaux
La piste suivante est la détection du chant des oiseaux. Un problème similaire se pose, par exemple, dans divers systèmes de surveillance automatique de la faune - c'est la première étape du traitement des données avant, par exemple, la classification. De tels systèmes nécessitent souvent un réglage, sont instables aux nouvelles conditions acoustiques, donc l'objectif de cette piste est de faire appel à la puissance de l'apprentissage automatique pour résoudre de tels problèmes.
Cette piste est une version étendue du concours «Bird Audio Detection challenge» organisé par St Mary’s University of London en 2017/2018. Pour les personnes intéressées , vous pouvez lire l'article des auteurs du concours, qui fournit des détails sur la formation des données, l'organisation du concours lui-même et une analyse des décisions prises.
Revenons cependant à la tâche DCASE. Les organisateurs ont fourni six ensembles de données - trois pour la formation, trois pour les tests - ils sont tous très différents - enregistrés dans différentes conditions acoustiques, à l'aide de divers appareils d'enregistrement, et il y a divers bruits en arrière-plan. Ainsi, le message principal est que le modèle ne doit pas dépendre de l'environnement ni pouvoir s'y adapter. Malgré le fait que le nom signifie «détection», la tâche n'est pas de déterminer les limites de l'événement, mais dans une classification simple - la solution finale est une sorte de classificateur binaire qui reçoit une courte entrée audio et décide s'il y a ou non des chants d'oiseaux dessus. . La métrique AUC a été utilisée pour évaluer la précision.
La plupart du temps, les participants ont essayé de réaliser la généralisation et l'adaptation par diverses augmentations de données. L'une des commandes décrit l' application de diverses techniques - modification de la résolution de fréquence dans les entités extraites, réduction préliminaire du bruit, méthode d'adaptation basée sur l'alignement des statistiques de second ordre pour différents ensembles de données. Cependant, ces méthodes, ainsi que différents types d'augmentation, donnent une très faible augmentation par rapport à la solution de base, comme le notent de nombreux participants.
Comme solution de base, les auteurs ont préparé une modification de la solution la plus réussie du concours original «Bird Audio Detection challenge». Le code, comme d'habitude, est disponible sur le github .
Piste 4. Détection d'événements acoustiques dans la maison à l'aide d'un ensemble de données faiblement étiqueté.
Dans la quatrième piste, le problème de détection est déjà résolu directement. Les participants ont reçu un ensemble de données relativement petites de données balisées - un total de 1578 enregistrements audio de 10 secondes chacun, avec uniquement un marquage de classe: il est connu que le fichier contient un ou plusieurs événements de ces classes, mais il n'y a pas de balisage temporaire. En outre, deux grands ensembles de données de données non allouées ont été fournis - 14412 fichiers contenant des événements cibles des mêmes classes que dans les échantillons d'apprentissage et de test, ainsi que 39999 fichiers contenant des événements arbitraires qui n'étaient pas inclus dans les cibles. Toutes les données sont un sous-ensemble de l' énorme ensemble de données audio compilé par google .
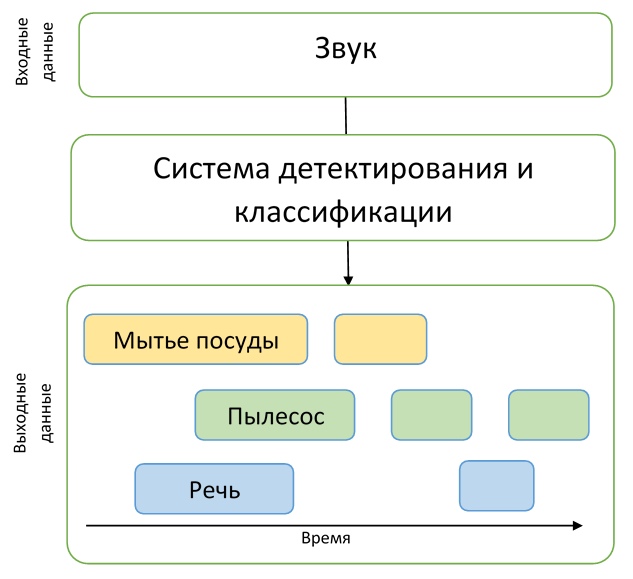
Ainsi, les participants devaient créer un modèle capable d'apprendre à partir de données faiblement étiquetées pour trouver les horodatages du début et de la fin des événements (les événements peuvent se chevaucher) et essayer de l'améliorer avec une grande quantité de données supplémentaires non marquées. De plus, il convient de noter qu'une métrique assez rigide a été utilisée dans cette piste - il était nécessaire de prédire les étiquettes temporelles des événements avec une précision de 200 ms. En général, les participants ont dû résoudre une tâche assez difficile de créer un modèle adéquat, tout en n'ayant pratiquement pas de bonnes données pour la formation.
La plupart des solutions étaient basées sur des réseaux de récurrence convolutionnels - une architecture assez populaire dans le domaine de la détection d'événements acoustiques récemment (un exemple peut être lu ici ).
La solution de base des auteurs, également sur les réseaux récursifs convolutifs, est basée sur deux modèles. Les modèles ont presque la même architecture: trois couches convolutives et une couche récursive. La seule différence est les réseaux de sortie. Le premier modèle est formé pour baliser les données non allouées pour étendre le jeu de données d'origine - ainsi, à la sortie, nous avons des classes présentes dans le fichier d'événements. Le second sert à résoudre directement le problème de détection, c'est-à-dire qu'à la sortie, nous obtenons un marquage temporaire pour le fichier. Code pour le lien .
Piste 5. Classification de l'activité du ménage dans la pièce selon l'enregistrement multicanal.
La dernière piste différait des autres principalement par le fait que les participants se voyaient proposer des enregistrements multicanaux. La tâche elle-même était dans la classification: il est nécessaire de prédire la classe d'événements qui se sont produits sur l'enregistrement. Contrairement à la piste précédente, la tâche est un peu plus simple - on sait qu'il n'y a qu'un seul événement dans l'enregistrement.
L'ensemble de données est représenté par environ 200 heures d'enregistrements sur un réseau de microphones linéaires de 4 microphones. Les événements sont toutes sortes d'activités quotidiennes - cuisiner, laver la vaisselle, activités sociales (parler au téléphone, visiter et converser personnellement), etc., la classe d'absence de tout événement est également mise en évidence.
Les auteurs de la piste soulignent que les conditions de la tâche sont relativement simples pour que les participants se concentrent directement sur l'utilisation des informations spatiales à partir d'enregistrements multicanaux. Les participants ont également eu la possibilité d'utiliser des données supplémentaires et des modèles pré-formés. La qualité a été évaluée selon la mesure F1.
Comme solution de base, les auteurs de la piste ont proposé un réseau convolutionnel simple avec deux couches convolutionnelles. Dans leur solution, l'information spatiale n'a pas été utilisée - les données de quatre microphones ont été utilisées pour l'entraînement de manière indépendante, et les prévisions ont été moyennées pendant les tests. La description et le code sont disponibles sur le lien .
Conclusion
Dans l'article, nous avons essayé de parler brièvement de la détection d'événements acoustiques et d'une compétition telle que DCASE. Peut-être qu'ils ont pu intéresser quelqu'un à participer en 2019 - le concours commence en mars.