Ceci est la première partie de l'article dans laquelle je parlerai de la façon dont nous avons construit le processus de travail sur un grand projet de migration de base de données: sur les expériences sûres, la planification d'équipe et l'interaction entre équipes. Dans les articles suivants, je parlerai plus en détail des problèmes techniques que nous avons résolus: la mise à l'échelle et la tolérance aux pannes de PostgreSQL et les tests de charge.
Pendant longtemps, la base de données principale de Miro (ex-RealtimeBoard) était Redis. Nous y avons stocké toutes les informations de base: données sur les utilisateurs, les comptes, les tableaux, etc. Tout a fonctionné rapidement, mais nous avons rencontré un certain nombre de problèmes.
Problèmes avec Redis- Dépendance à la latence du réseau. Maintenant, dans notre cloud, il est environ 20 heures de Moscou, mais lorsque vous l'augmentez, l'application commencera à fonctionner très lentement.
- Le manque d'index dont nous avons besoin au niveau de la logique métier. Leur mise en œuvre indépendante peut compliquer la logique métier et conduire à une incohérence des données.
- La complexité du code rend également difficile le maintien de la cohérence des données.
- Intensité des ressources des requêtes avec sélections.
Ces problèmes, associés à une augmentation de la quantité de données sur les serveurs, ont été à l'origine de la migration de la base de données.
Énoncé du problème
La décision sur la migration a été prise. L'étape suivante consiste à comprendre quelle base de données convient à notre modèle de données.
Nous avons mené une étude pour sélectionner la base de données optimale pour nous et nous sommes installés sur PostgreSQL. Notre modèle de données s'intègre bien avec une base de données relationnelle: PostgreSQL dispose d'outils intégrés pour assurer la cohérence des données, il existe un type JSONB et la possibilité d'indexer certains champs dans JSONB. Cela nous convient.
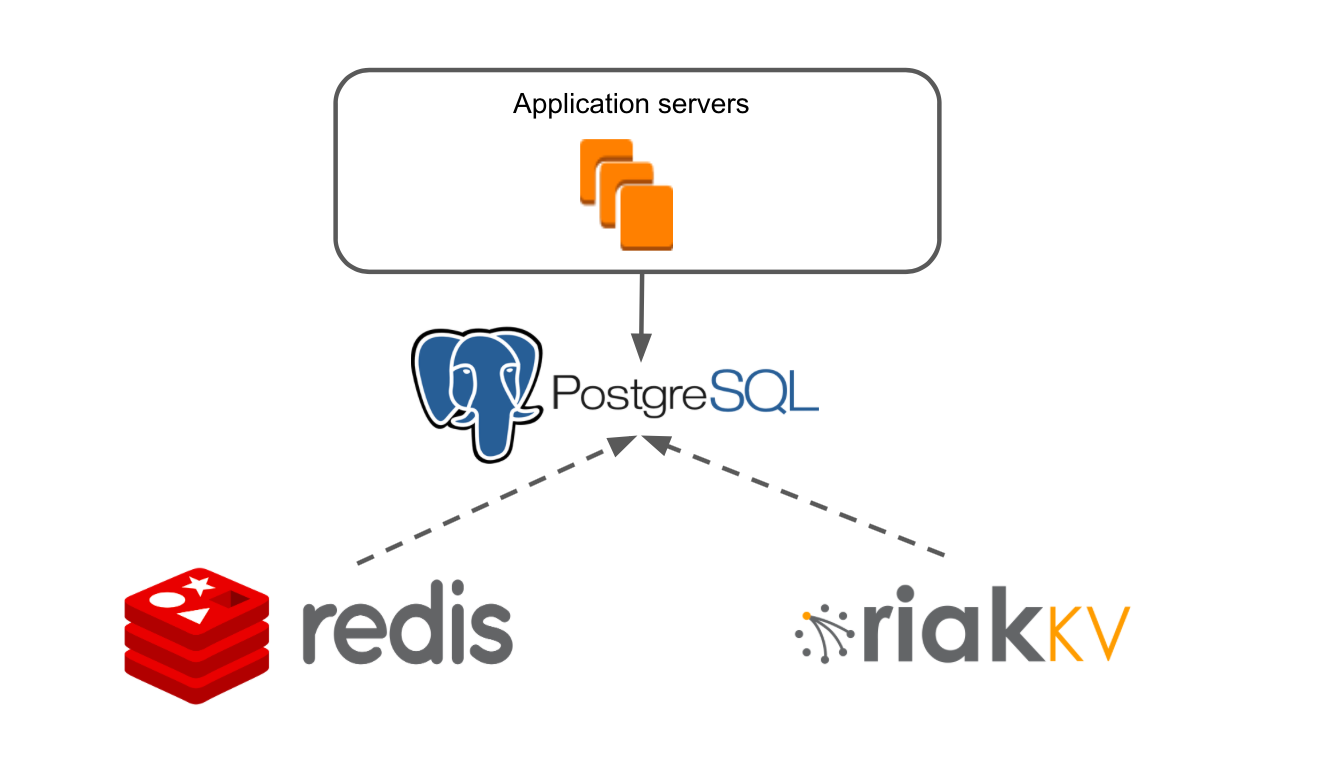
L'architecture simplifiée de notre application ressemblait à ceci: il y a des serveurs d'applications qui accèdent à Redis et RiakKV via la couche de données.
Notre serveur d'applications est une application Java monolithique. La logique métier est écrite dans un framework adapté à NoSQL. L'application possède son propre système transactionnel, qui vous permet de fournir plusieurs utilisateurs sur n'importe laquelle de nos cartes.
Nous avons utilisé RiakKV pour stocker des données à partir de tableaux d'archives qui ne se sont pas ouverts pendant 7 jours.
Ajoutez PostgreSQL à ce schéma. Nous faisons fonctionner les serveurs d'applications avec la nouvelle base de données. Copiez les données de Redis et RiakKV vers PostgreSQL. Le problème est résolu!
Rien de compliqué, mais il y a des nuances:- Nous avons 2,2 millions d'utilisateurs enregistrés. Chaque jour, Miro emploie 50 000 utilisateurs, la charge de pointe pouvant atteindre 14 000 en même temps. Les utilisateurs ne devraient pas rencontrer d'erreurs dues à notre travail, ils ne devraient généralement pas remarquer le moment de passer à une nouvelle base.
- 1 To de données dans la base de données ou 410 millions d'objets.
- Sortie continue de nouvelles fonctionnalités par d'autres équipes, dont le travail ne doit pas nous gêner.
Options pour résoudre le problème
Nous avons été confrontés à un choix de deux options pour la migration des données:
- Arrêtez le développement du service → réécrivez le code sur le serveur → testez la fonctionnalité → lancez une nouvelle version.
- Effectuez une migration en douceur: transférez progressivement des parties du produit vers une nouvelle base de données, prenant en charge PostgreSQL et Redis et n'interrompant pas le développement de nouvelles fonctionnalités.
Arrêter le développement d'un service est une perte de temps que nous pourrions utiliser pour la croissance, ce qui signifie une perte d'utilisateurs et de parts de marché. Ceci est essentiel pour nous, nous avons donc choisi l'option avec une migration en douceur. Malgré le fait que dans la complexité, ce processus peut être comparé au remplacement des roues d'une voiture pendant la conduite.
Lors de l'évaluation du travail, nous avons divisé notre produit en blocs principaux: utilisateurs, comptes, tableaux, etc. Par ailleurs, des travaux ont été menés pour créer l'infrastructure PostgreSQL. Et ils mettent des risques dans l'évaluation en cas de problème (comme cela s'est produit).
Sprints et objectifs
L'étape suivante consiste à constituer une équipe de cinq personnes afin que chacun se déplace à la bonne vitesse vers un objectif commun.
Nous avons deux points: le début du travail sur la tâche et le but final. Idéal lorsque nous nous dirigeons directement vers l'objectif. Mais il arrive souvent que nous voulions aller dans le bon sens, mais cela se passe comme suit:
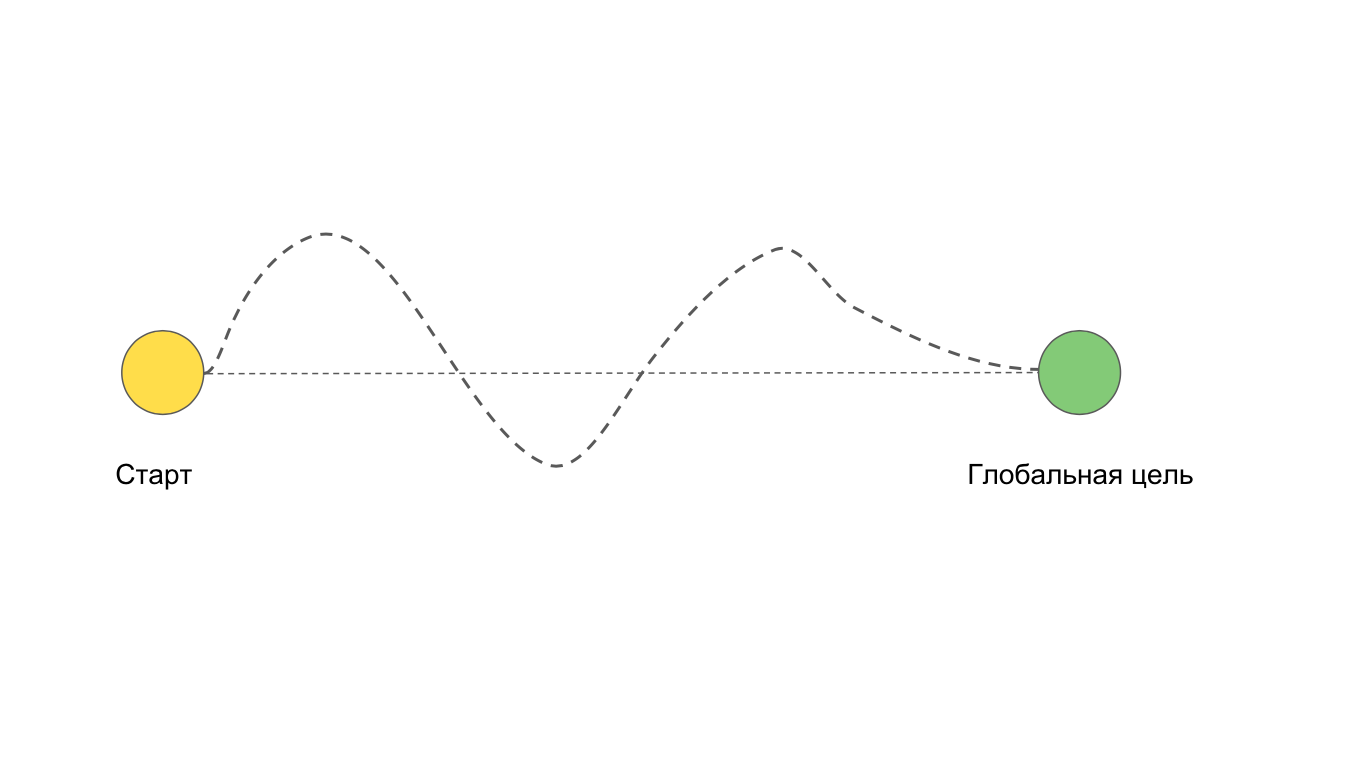
Par exemple, en raison de difficultés et de problèmes qui ne pouvaient pas être prévus à l'avance.
Une situation est possible dans laquelle nous n'atteindrons pas du tout l'objectif. Par exemple, si nous procédons à une refactorisation en profondeur ou à la réécriture de l'application entière.
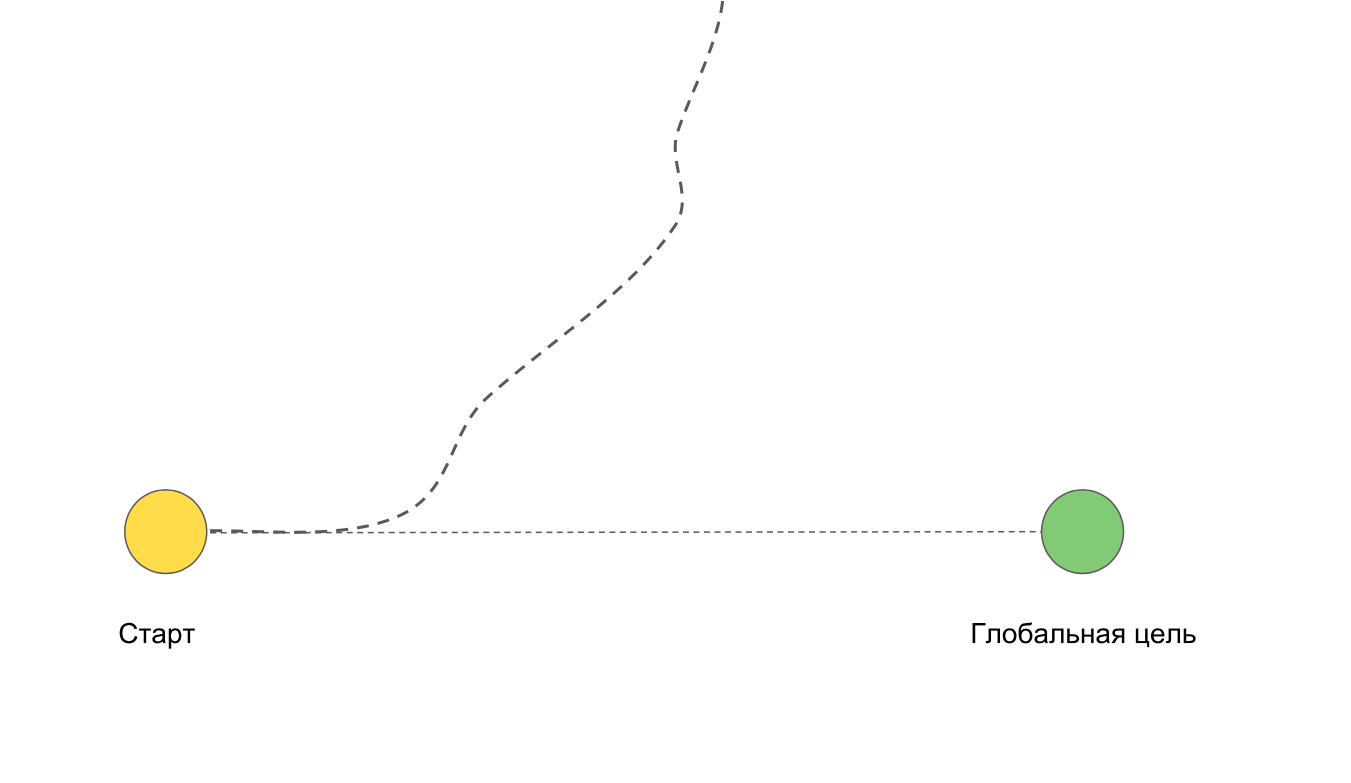
Nous avons divisé la tâche en sprints hebdomadaires pour minimiser les difficultés décrites ci-dessus. Si l'équipe part soudainement sur le côté, elle peut rapidement revenir en arrière avec un minimum de pertes pour le projet, car de courtes itérations ne vous permettent pas d'aller trop loin "dans le mauvais sens".
Chaque itération a son propre objectif, ce qui déplace l'équipe vers le grand résultat final.

Si une nouvelle tâche apparaît pendant le sprint, nous évaluons si sa mise en œuvre nous rapproche de l'objectif. Oui - prenez le prochain sprint ou changez les priorités dans l'actuel, sinon - ne le prenez pas. Si des erreurs apparaissent, nous leur accordons une priorité élevée et les corrigeons rapidement.
Il arrive que les développeurs d'un sprint doivent effectuer des tâches dans une séquence strictement définie. Ou, par exemple, le développeur remet la tâche terminée à l'ingénieur QA pour des tests urgents. Au stade de la planification, nous essayons de créer des relations similaires entre les tâches pour chaque membre de l'équipe. Cela permet à toute l'équipe de voir qui fera quoi et quand, sans oublier la dépendance aux autres.
L'équipe a des synchronisations quotidiennes et hebdomadaires. Chaque matin, nous discutons qui, quoi et dans quelle priorité fera aujourd'hui. Après chaque sprint, nous nous synchronisons les uns avec les autres pour être sûrs que tout le monde va dans la bonne direction. Assurez-vous de planifier des versions importantes ou complexes. Nous nommons des développeurs en service qui, si nécessaire, sont présents lors de la sortie et contrôlons que tout est en ordre.
La planification et la synchronisation au sein de l'équipe permettent d'impliquer tous les participants à toutes les étapes du projet. Les plans et les évaluations ne nous viennent pas d'en haut, nous les faisons nous-mêmes. Cela augmente la responsabilité et l'intérêt de l'équipe dans l'exécution des tâches.
C'est l'un de nos sprints. Nous portons tout sur la planche Miro:

Modes et expériences sécuritaires
Pendant la migration, nous avons dû garantir le fonctionnement stable du service dans des conditions de combat. Pour ce faire, vous devez vous assurer que tout est testé et qu'il n'y a aucune erreur nulle part. Pour atteindre cet objectif, nous avons décidé de rendre notre migration en douceur encore plus fluide.
L'idée était de basculer progressivement les blocs de produits vers une nouvelle base de données. Pour ce faire, nous avons proposé une séquence de modes.
Dans le premier mode «Redis Read / Write», seule l'ancienne base de données, Redis, fonctionne.
 Dans le deuxième mode «PostgreSQL Passive Write»,
Dans le deuxième mode «PostgreSQL Passive Write», nous pouvons nous assurer que l'écriture dans la nouvelle base de données est correcte et que les bases de données sont cohérentes.
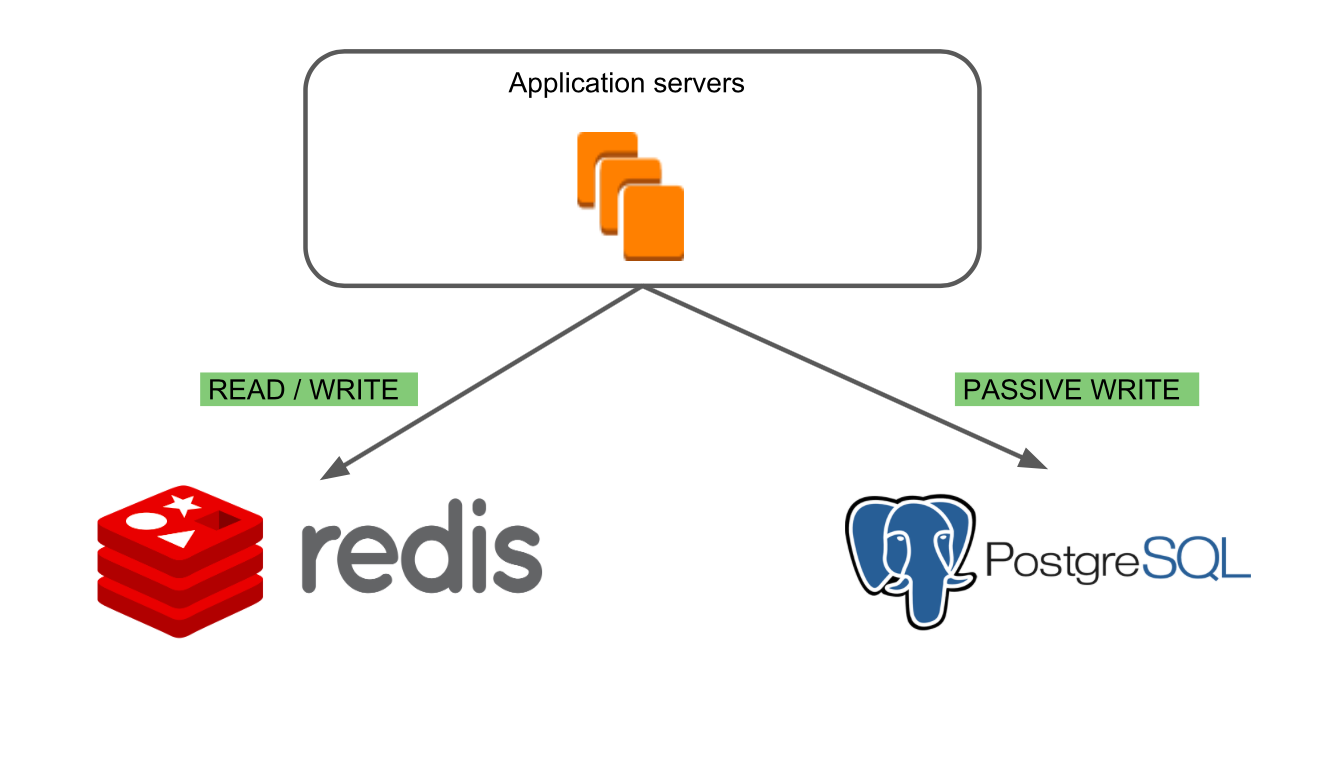 Le troisième mode «Lecture / écriture PostgreSQL, écriture passive Redis»
Le troisième mode «Lecture / écriture PostgreSQL, écriture passive Redis» vous permet de vérifier l'exactitude des données de lecture de PostgreSQL et de voir comment la nouvelle base de données se comporte dans des conditions de combat. Dans le même temps, Redis reste la base principale, ce qui nous a permis de trouver des cas spécifiques de travail avec des cartes pouvant conduire à des erreurs.
 Dans le dernier mode «PostgreSQL Read / Write»,
Dans le dernier mode «PostgreSQL Read / Write», seule la nouvelle base de données est en cours d'exécution.
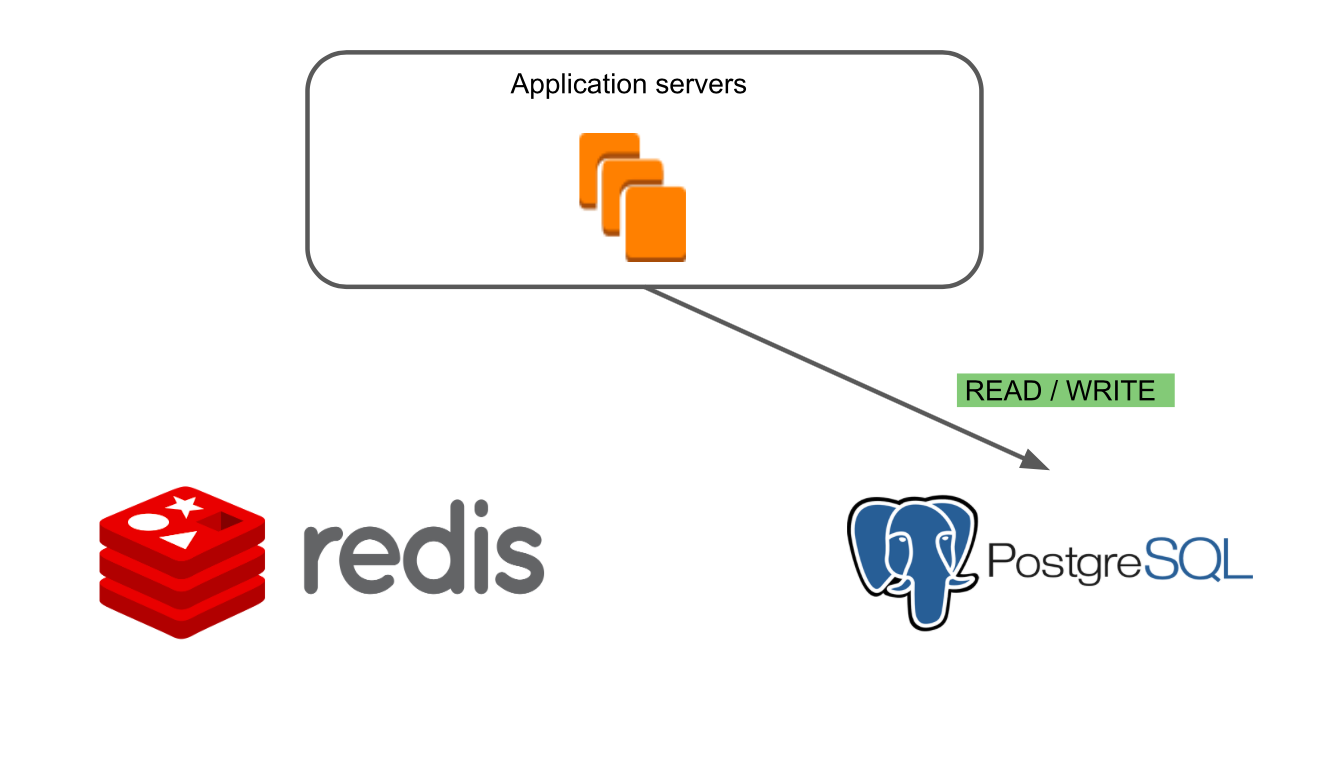
Le travail de migration pourrait affecter les principales fonctions du produit, nous devions donc être sûrs à 100% que nous ne casserons rien et que la nouvelle base de données fonctionne au moins aussi lentement que l'ancienne. Par conséquent, nous avons commencé à mener des expériences sûres avec les modes de commutation.
Nous avons commencé à changer de mode sur notre compte d'entreprise, que nous utilisons quotidiennement au travail. Après nous être assurés qu'il n'y avait aucune erreur, nous avons commencé à changer de mode sur une petite sélection d'utilisateurs externes.
La chronologie du lancement des expériences avec les modes est la suivante:
- Janvier-février: Redis lecture / écriture
- Mars-avril: écriture passive PostgreSQL
- Mai-juin: PostgreSQL en lecture / écriture, base de données principale - Redis
- Juillet-août: PostgreSQL en lecture / écriture
- Septembre-décembre: migration complète.
Si des erreurs se sont produites, nous avons eu la possibilité de les corriger rapidement, car nous pouvions nous-mêmes réaliser des versions sur des serveurs où travaillaient les utilisateurs participant à l'expérience. Nous ne dépendions pas de la version principale, nous avons donc corrigé les erreurs rapidement et à tout moment.
Collaboration entre équipes
Pendant la migration, nous avons souvent croisé des équipes qui ont publié de nouvelles fonctionnalités. Nous avons une base de code unique et, dans le cadre de leur travail, les équipes peuvent modifier les structures existantes dans une nouvelle base de données ou en créer de nouvelles. Dans le même temps, des intersections d'équipes pour le développement et le retrait de nouvelles fonctionnalités pourraient se produire. Par exemple, l'une des équipes produit a promis à l'équipe marketing de publier une nouvelle fonctionnalité à une date précise; l'équipe marketing a prévu une campagne publicitaire pour cette période; Une équipe commerciale attend une fonctionnalité et une campagne pour commencer à communiquer avec de nouveaux clients. Il s'avère que tout le monde dépend les uns des autres, et retarder les délais d'une équipe perturbe les plans de l'autre.
Pour éviter de telles situations, nous avons élaboré, avec d'autres équipes, une feuille de route unique pour l'épicerie, synchronisée plusieurs fois par trimestre, et avec certaines équipes chaque semaine.
Conclusions
Ce que nous avons appris au cours de ce projet:
- N'ayez pas peur de vous lancer dans des projets complexes. Après décomposition, évaluation et développement d'approches du travail, les projets complexes cessent de paraître impossibles.
- Ne perdez pas de temps et d'efforts sur les estimations préliminaires, la décomposition et la planification. Cela permet de mieux comprendre le problème avant de commencer à travailler dessus et de comprendre le volume et la complexité du travail.
- Risque dans les projets techniques et organisationnels difficiles. Au cours du travail, vous rencontrerez sûrement un problème qui n'a pas été pris en compte lors de la planification.
- Ne migrez pas sauf si cela est nécessaire.
Dans les articles suivants, je parlerai davantage des problèmes techniques que nous avons résolus lors de la migration.