Bonjour encore!
Chers collègues, le dernier jour de janvier, nous lançons le cours
«MS SQL Server Developer» , dans le cadre duquel nous avons eu une leçon ouverte thématique. Nous y avons expliqué comment MS SQL Server exécute une requête SELECT, discuté dans quel ordre et ce qui est analysé, et avons également plongé un peu dans la lecture du plan de requête.
Conférencier -
Kristina Kucherova , architecte de modèle de données à la Sberbank de Russie.
Objectifs et itinéraire du webinaireLes objectifs suivants ont été fixés au début du webinaire:
- Découvrez comment le serveur exécute la demande et pourquoi cela se produit de cette manière.
- Apprendre à lire un plan de requête.
Pour les atteindre, l'enseignant a préparé un parcours simple mais efficace:
 Pourquoi ai-je besoin d'un plan de requête?
Pourquoi ai-je besoin d'un plan de requête?Le plan de requête est un outil très utile que, malheureusement, de nombreux développeurs n'utilisent pas. À première vue, il peut sembler qu'il n'est pas nécessaire de connaître la mécanique de la demande. Cependant, si vous comprenez ce qui se passe dans SQL Server, vous pouvez écrire une requête plus efficace. Et cela aidera beaucoup, par exemple, lors de l'optimisation.
Comment voyons-nous une requête SELECT?Voyons à quoi ressemble la requête SELECT:
SELECT [champ1], [champ2] ...
| Quels domaines choisissons-nous?
|
DE [table]
| D'où?
|
O [[conditions]
| Où sont les conditions
|
GROUPE PAR [champ1]
| Regrouper par champs
|
AYANT [conditions]
| Avoir telle ou telle condition
|
COMMANDER PAR [field1]
| Commande (trier)
|
Comment comprendre où aller pour les données?La première chose que le serveur essaie de comprendre quand une demande arrive est où aller pour les données. La commande FROM répond à cette question, car c'est ici que nous aurons une liste de tables (ou le nom d'une table).
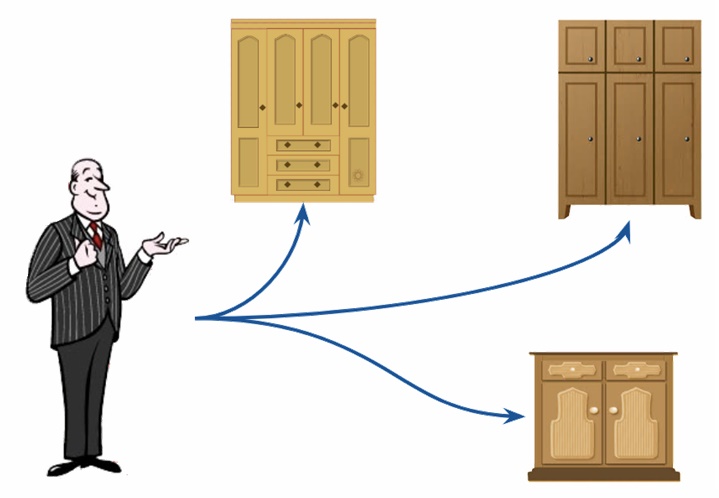
Pour plus de clarté, imaginons que notre serveur est une sorte de majordome, que nous commandons pour venir nous chercher en vacances. En conséquence, le majordome commence à réfléchir, mais dans quel placard sont les choses nécessaires (dans quelle table avez-vous besoin de prendre les données)? Et pour que notre majordome puisse facilement terminer sa tâche, nous utilisons FROM.
 Comment comprendre quelles données prendre?
Comment comprendre quelles données prendre?Disons que le majordome a trouvé le bon placard et l'a ouvert. Mais quelles choses prendre? Peut-être que nous allons dans une station de ski? Ou peut-être sur une plage chaude et ensoleillée? Pour que nos choses correspondent à la météo, la commande WHERE est utile pour nous, qui définit les conditions, c'est-à-dire nous permet de filtrer les données. S'il fait chaud, nous prenons des ardoises, des chemises et des maillots de bain, s'il fait froid - mitaines, chaussettes tricotées, pulls)).
L'étape suivante consiste à attacher ces données à des groupes, ce qui se produit avec GROUP BY (T-shirts séparément, chaussettes séparément). Selon les résultats du regroupement, une condition supplémentaire peut être imposée à l'aide de HAVING (par exemple, éliminer les éléments non appariés). En fin de compte, nous ajoutons tout en utilisant ORDER BY, obtenant la valise finie des choses à la sortie, ou plutôt, un bloc de données ordonné.

Soit dit en passant, il y a une nuance, mais elle consiste dans le fait qu'il y a une différence entre les conditions qui doivent être écrites dans OERE et celles dans HAVING. Mais c'est mieux à voir dans la vidéo.
Nous continuons. Le chemin d'exécution de la demande est enregistré en
tant que plan de demande dans le cache, c'est-à-dire que notre majordome écrit tout, car il est un bon majordome - et si vous voulez répéter votre commande l'année prochaine? Et de tels plans, en principe, peuvent être nombreux.
Types de connexions dans le plan de requêteIl existe trois connexions que vous pouvez rencontrer en termes de requête:
- Boucle imbriquée.
- Fusionner la jointure.
- Hash join.
Avant de nous attarder sur chacun d'eux plus en détail, résumons pourquoi nous devrions même lire le plan de requête. Ceci est en fait très utile car vous apprendrez:
- quel indice est utilisé;
- dans quel ordre adhérez-vous;
- ce qui est sélectionné dans le tampon;
- combien le serveur dépense des ressources pour l'opération;
- quelle est la différence entre un plan hypothétique et un plan réel.
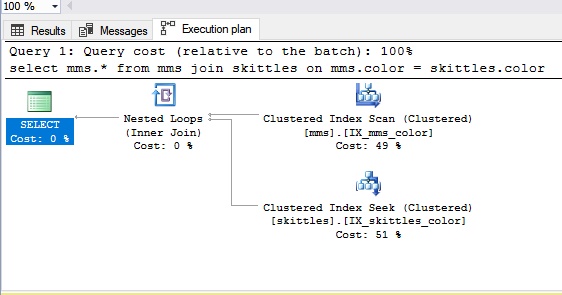
Boucle imbriquéeDisons que nous devons joindre les données de différentes tables. Présentons ces tableaux comme ... une petite quantité de chocolats Skittles et l'emballage complet de M&M.

Lors de la connexion d'un type de boucle imbriquée, nous prenons le bonbon Skittles, puis nous obtenons le bonbon aveugle du package de M&M. Si nous ne tombons pas sur un bonbon de la même couleur (c'est notre condition), nous obtenons le suivant, c'est-à-dire qu'il y a un buste habituel. Par conséquent, nous pouvons dire que la connexion en boucle imbriquée convient mieux à de petites quantités de données. De toute évidence, s'il y a beaucoup de données, la suppression n'est pas la meilleure option.

Voyons à quoi cela ressemble dans le panneau SQL:
 Fusionner la jointure
Fusionner la jointureUne connexion est utilisée pour de grandes quantités de données. Lorsque vous avez une jointure de fusion, vos deux tables ont un index par lequel elles peuvent être jointes. Dans le cas des bonbons, c'est comme si nous les avions disposés à l'avance par couleur.
Cela ressemble à ceci:

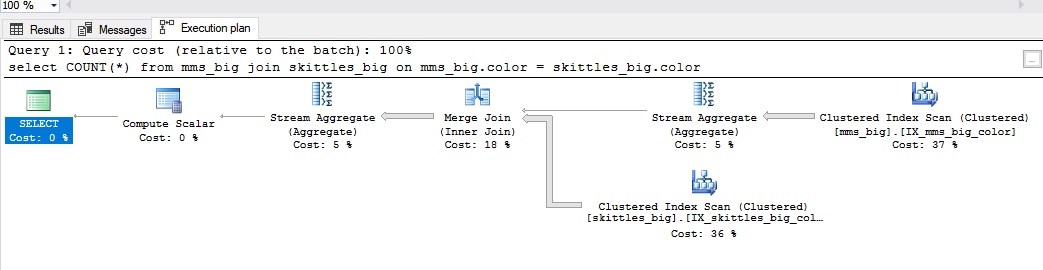
La fusion de jointure est bonne dans les cas suivants:
- grands ensembles de données;
- les mêmes champs de connexion du même type;
- les champs de connexion ont des indices.
Hash JoinLa jointure par hachage est utilisée pour de grandes quantités de données non triées. Pour rejoindre les tables dans ce cas, vous devez créer quelque chose qui imite l'index.
Exemple de jointure par hachage:
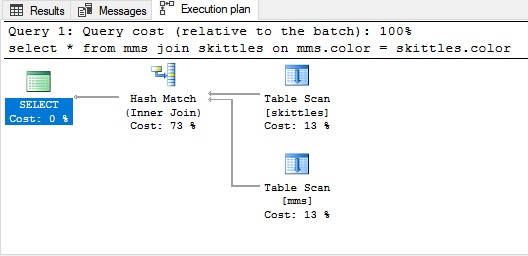
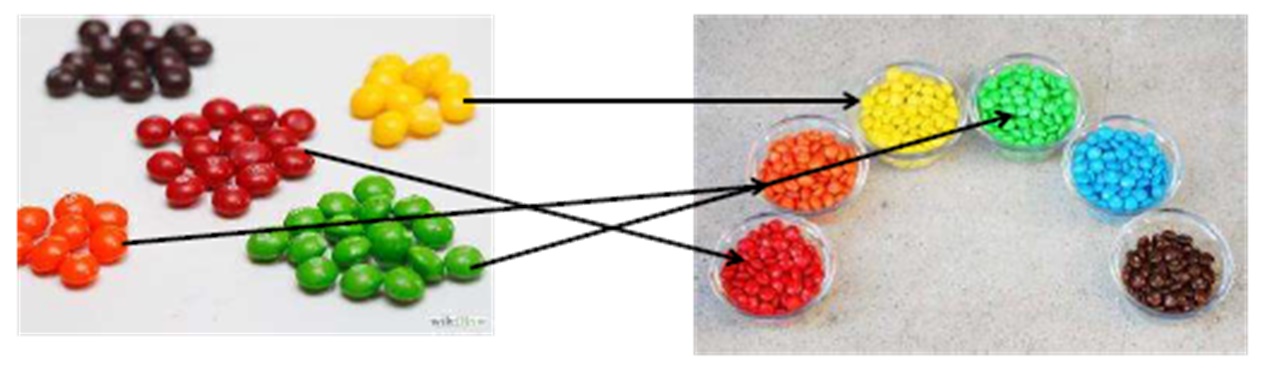
Pour plus de clarté, nous rappelons nos bonbons:

L'utilisation de Hash Join implique 2 phases d'action:
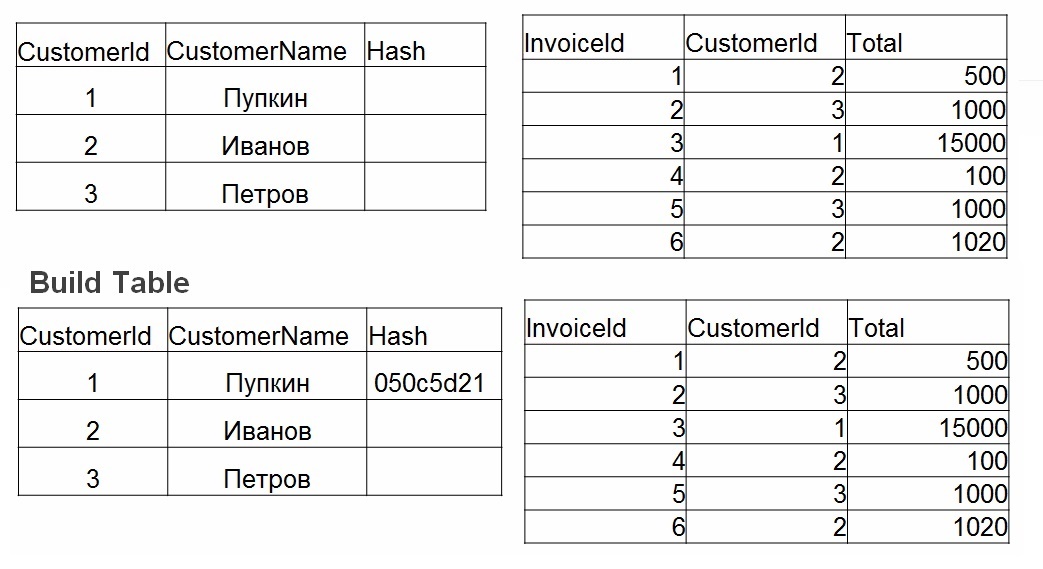
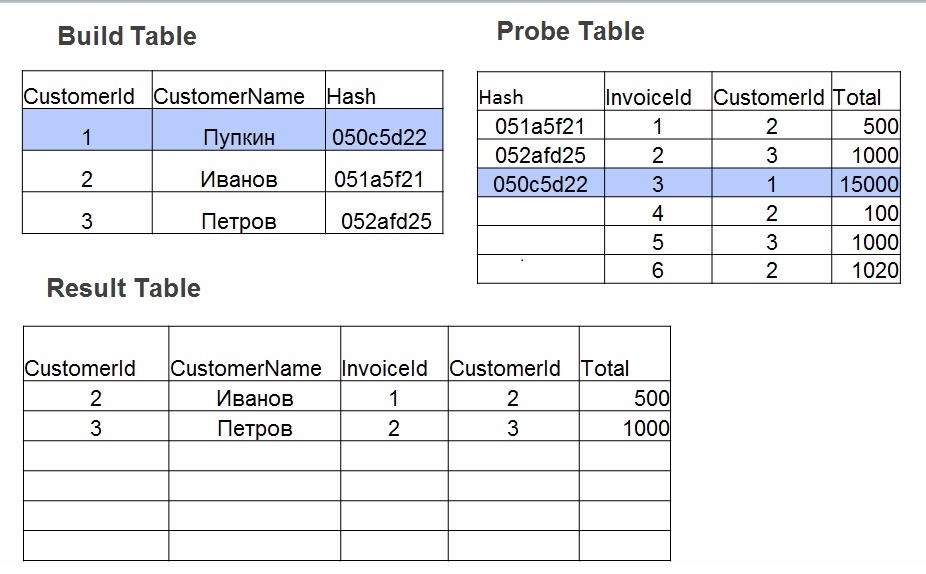
- Build - une table de hachage est construite sur la plus petite table. Pour chaque valeur du tableau n ° 1, un hachage est considéré. La valeur est stockée dans une table de hachage et le hachage calculé est utilisé comme clé.
- Sonde. Pour chaque ligne du tableau n ° 2, la valeur de hachage est calculée pour les champs spécifiés dans join (operator =). Un hachage est recherché dans la table de hachage, les valeurs des champs sont vérifiées.
Lorsque la jonction de hachage est bonne:
- grand ensemble de données;
- pas d'indices marginaux.
Un point important: s'il n'y a pas assez de mémoire, l'enregistrement ira à tempdb - sur le disque.
Amis, en plus de ce qui précède, la leçon ouverte comprenait également d'autres points intéressants, qui sont mieux vus en regardant la vidéo. Nous vous suggérons de visiter la
journée portes ouvertes du cours "Développeur MS SQL Server", où vous pourrez poser toutes vos questions au professeur.
L'enseignante PS
Kristina Kucherova remercie Jes Schultz Borland pour sa
présentation avec PASS Summitt Execution Plans: The Secret to Query Tuning Success, qui a été utilisé pour préparer la leçon ouverte.