Il y a longtemps, dans une galaxie lointaine, très lointaine, une entreprise était passée d'une start-up à quelque chose de beaucoup plus grand, mais pendant un certain temps, le service informatique était encore compact et très efficace. Cette société a hébergé
sur des centaines de serveurs Windows virtuels, et bien sûr, ces serveurs ont été surveillés. Avant même de rejoindre l'entreprise, NetIQ avait été choisie comme solution de surveillance.
L'une de mes nouvelles tâches consistait à prendre en charge NetIQ. La personne, qui a déjà travaillé avec NetIQ, a beaucoup parlé de son expérience avec NetIQ, malheureusement, si j'essaie de le mettre ici, ce ne serait qu'une longue lignée de caractères '****'. J'ai vite compris pourquoi. Steve Jobs tourne probablement dans sa tombe en regardant l'interface comme ceci:
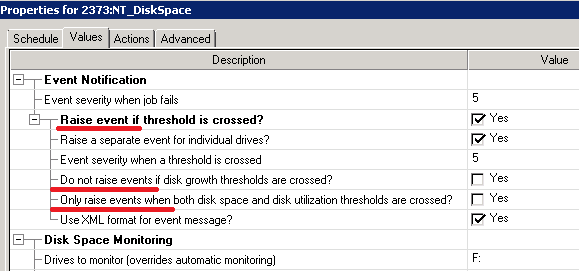
Dans une ligne, la logique de la case à cocher est positive (
événement déclencheur ), dans la suivante est négative (
événement non déclencheur ). Alors, comment fonctionne '
Raise event only i f'? Je n'en ai aucune idée.
Cependant, il y avait bien pire avec NetIQ: son agent de surveillance était très fragile. Beaucoup plus vulnérable que Windows lui-même. Mémoire insuffisante? L'agent est en panne. Le CPU est à 100%? L'agent ne répond pas. 0 octets libres sur un lecteur de disque? Eh bien, pour envoyer un message d'alerte, un agent doit d'abord l'enregistrer dans un fichier sur un disque ... Alors oui, vous ne recevez aucune alerte dans ce cas.
Cependant, «ne réparez pas ce qui n'est pas cassé», et d'une manière ou d'une autre, nous avons vécu avec jusqu'à ce que notre entreprise soit achetée par une entreprise beaucoup plus grande. Lorsqu'une grande entreprise en achète une petite, la petite se dissipe sous forme de gouttelettes d'eau dans une mer. Cependant, dans notre cas, nous (du point de vue informatique) n'étions pas beaucoup plus petits que l'informatique d'une plus grande entreprise, et il était évident dès le début que la fusion serait très délicate. Si délicat que pendant un certain temps, nous avons été laissés seuls en tant que service indépendant et que tous les processus commerciaux et informatiques ont été conservés de la même manière, juste sous l'égide du nouveau nom. Cela me rappelle le moment où
THE RING était allongé sur la lave mais n'a pas encore commencé à fondre.

Pendant ce temps, j'avais mis à niveau NetIQ de la version 7 à la version 8, puis à la version 9. C'est à ce moment que tous nos problèmes ont commencé. Nous utilisions NetIQ pour surveiller seulement quelques éléments de base: la disponibilité d'un serveur, la mémoire, le processeur, l'espace disque et le plus important pour nous - l'état des services locaux. Lorsqu'un type de démarrage de service local a été défini sur «Automatique», il doit toujours être en cours d'exécution (sinon nous le considérons comme ayant planté). Il ne devrait pas y avoir de cas comme celui-ci:

NetIQ a donc cessé de surveiller l'état des services. Après une semaine d'expérimentation et une autre semaine d'appels avec le support de NetIQ, nous avions appris que «
ce n'était pas un bug, c'était une fonctionnalité » et l'alerte n'était déclenchée que lorsqu'un processus se terminait avec un code de sortie spécifique. Et nos services se sont écrasés avec TOUT code.
À ce moment-là, il était trop tard pour revenir en arrière. Comme vous le comprenez, dès que nous avons découvert que notre infrastructure critique n'était pas surveillée, nous n'avions immédiatement ... eh ... rien fait. Parce qu'à cette époque, le processus de «fusion» de notre entreprise en une plus grande a atteint une phase active, et cela ressemblait à ceci:
J'entendais des sons de tonnerre de très loin et il semblait que les dieux d'Olympe décidaient du sort du monde, alors que j'essayais de les distraire avec mon petit problème technique. En même temps, je ne pouvais pas dormir sachant que notre système de surveillance était à moitié aveugle.
Après avoir réalisé qu'il n'y avait rien à attendre, j'ai décidé de créer une solution rapide et sale - un minuscule scanner de service qui devrait parcourir tous les serveurs pour vérifier les services et envoyer des e-mails pour les services qui étaient en panne, exactement comme l'ancienne version de NetIQ l'a fait. Vous pourriez penser que le script PowerShell est la meilleure façon de le faire, mais ... Si tout ce que vous avez est un marteau, tout ressemble à un clou. Si vous êtes un DBA qui travaille avec SQL depuis la version 6.0 alors ... Voici un court extrait du code, pour que vous puissiez comprendre de quoi je parle:
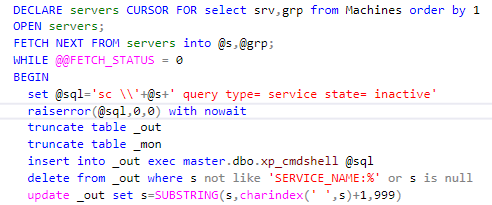
Il ne m'a fallu que quelques heures pour écrire la première solution. Au cours des prochains jours, j'ai ajouté un audit, des paramètres et d'autres choses fantaisistes. Après avoir examiné ce que la commande WMIC pouvait faire, je n'ai pas pu m'arrêter. Je ne me souviens pas exactement de ce qui s'est passé au cours des 2 semaines suivantes - tout était un peu flou, mais quand je me suis réveillé, toutes les fonctionnalités de NetIQ ont été implémentées en utilisant du SQL pur.
Je n'ai pas simplement copié la fonctionnalité NetIQ «telle quelle», j'avais mis en œuvre tout ce dont j'avais toujours rêvé. Dans l'alerte par e-mail de LOWDISK, vous obtenez également un PDF joint avec un graphique de croissance de l'utilisation du disque afin que vous puissiez instantanément comprendre si la croissance est réelle ou si quelque chose s'est mal passé. Faible mémoire - et vous obtenez non seulement le graphique, mais aussi une distribution de mémoire par processus, plus pour w3wp.exe vous obtenez un nom de pool ajouté. J'avais également mis en place des rappels intelligents avec protection contre les inondations et bien d'autres choses fantaisistes. BTW, la liste des serveurs virtuels a été extraite automatiquement des référentiels VMware. En regardant simplement les sujets d'alerte dans un client mobile, vous pouvez dire instantanément ce qui se passe - même sans ouvrir les e-mails:

Les développeurs modernes se sont habitués à créer des niveaux d'abstraction dans une mesure où cela nuit à leur capacité à écrire un code simple et direct. Ils ne peuvent pas créer un système de surveillance sans dire: "Ok, donc pour n'importe quel serveur, nous pouvons exécuter n'importe quel ensemble de scripts avec des règles à partir d'un référentiel ... Quelle flexibilité ...". Mais la surveillance de quelques éléments fondamentaux comme la mémoire, le processeur, le disque et l'état des services est unique. En mettant en œuvre la vérification de ces conditions de base avec un niveau d'abstraction, elles se terminent par un code qui fonctionne également mal dans tous les cas. Ceci est un exemple du système SCOM. Je suis sûr qu'il a été mis en œuvre exactement par les spécifications:

Mais le principal avantage du nouveau système était qu'il n'y avait aucun agent. Aucun agent - rien à installer, rien à casser. Le système était simple et fiable comme hummer.
Peu le mois prochain, je suis venu travailler et j'ai passé une heure ou deux à travailler sur ma nouvelle création - lentement, sans délais ni ETA, ne laissant pratiquement aucune dette technique. Au bout d'un moment, je me suis forcé à arrêter.
NetIQ était toujours en production, mais les gens préféraient définitivement les alertes du nouveau système, plus fiables et informatives. Peu à peu, j'ai déplacé tous les «abonnés» alertes vers le nouveau système, tout en maintenant l'ancien système en vie. Pendant ce temps, le processus de «fusion» de notre ancienne entreprise en une plus grande avait atteint son stade final:

Eh bien, tout a une fin. J'ai même été surpris d'avoir eu la chance de jouer avec de telles choses dans une grande entreprise bureaucratique. Après un mois de préparation, on m'a dit que «
ok, dans une semaine, nous avons fermé NetIQ et passer à SCOM en tant que norme d'entreprise ». J'ai fermé NetIQ (je dois admettre que je le détestais tellement que c'était l'un des moments les plus heureux de ma carrière) et j'ai commencé à attendre l'arrivée de SCOM. Mais il n'y en avait pas. Rien depuis une semaine, un mois, et même un quart.
Nous n'avons obtenu SCOM qu'après 6 mois complets - quelqu'un avait oublié le coût des licences pour le grand nombre de serveurs que nous avions. Au cours de ces 6 mois, de nombreux départements sont devenus tellement dépendants du nouveau système, qui a non seulement gardé les alertes mais aussi les mesures de performance et les inventaires qu'il était hors de question de le fermer. C'est devenu un deuxième système de sauvegarde. Pour les auditeurs il y a SCOM, pour les choses vraiment utiles - il y a ma création.
De temps en temps, des gestionnaires à différents niveaux de la hiérarchie ont dépassé les alertes de ce système et ont demandé - qu'est-ce que c'est? Récemment, j'avais expliqué toute l'histoire derrière ce produit. Ils ont ri et ont laissé ce système vivre, et pour moi, c'était une chance d'écrire un code comme quand j'étais étudiant - guidé non par des spécifications mais basé sur ma propre compréhension, comme un hobby. C'était très amusant.
Article en russe