Bonjour, Habr!
En décembre, notre collègue d'Advanced Analytics, Leonid Sherstyuk, a remporté la première place dans le domaine du Machine Learning et Big Data dans le championnat de l'industrie II DigitalSkills. Il s'agit d'une branche «numérique» de concours professionnels bien connus organisés par WorldSkills Russia. Au total, plus de 200 personnes ont participé au championnat, ont concouru pour le leadership dans 25 compétences numériques - Protection des entreprises contre les menaces de sécurité intérieure, Marketing Internet, Développement de jeux informatiques et d'applications multimédias, Technologies quantiques, Internet des objets, Design industriel, etc.

Dans le cas du Machine Learning, la tâche de surveiller et de détecter les défauts dans les pipelines des centrales nucléaires, des oléoducs et des gazoducs à l'aide d'un système de contrôle ultrasonique semi-automatique a été proposée.
Leonid racontera ce qui s'est passé lors de la compétition et comment il a réussi à gagner sous la coupe.
WorldSkills est une organisation internationale qui organise des concours de compétences professionnelles dans le monde entier. Traditionnellement, des représentants d'entreprises industrielles et des étudiants des universités concernées ont participé à ces concours, démontrant leurs compétences dans les spécialités professionnelles. Récemment, des nominations numériques ont commencé à apparaître au concours, où de jeunes spécialistes rivalisent dans les compétences de la robotique, du développement d'applications, de la sécurité de l'information et dans d'autres professions que vous ne pouvez même pas appeler des travailleurs. Dans l'une de ces nominations - en apprentissage automatique et en travaillant avec les mégadonnées - j'ai participé à Kazan au concours DigitalSkills, organisé sous les auspices de WS.
La compétence pour le concours étant nouvelle, il m'était difficile d'imaginer à quoi m'attendre. Au cas où, j'ai répété tout ce que je sais sur le travail avec les bases de données et l'informatique distribuée, les métriques et les algorithmes de formation, les critères statistiques et les méthodes de prétraitement. Connaissant les critères d'évaluation approximatifs, je ne comprenais pas comment il serait possible d'intégrer un travail à part entière avec Hadoop et de créer un chat bot en 6 courtes sessions.
L'ensemble du concours se déroule sur 3 jours, sur 6 séances. Chaque session est de 3 heures avec une pause, pour laquelle vous devez effectuer plusieurs tâches qui sont significativement liées les unes aux autres. Au début, il peut sembler que le temps est suffisant, mais en réalité, il a fallu un rythme effréné pour réussir à tout faire conçu.
Lors du concours, on s'attendait à ce qu'il ne soit pas censé fonctionner avec des données volumineuses, et l'ensemble du pool de tâches a été réduit à l'analyse d'un ensemble de données limité.
En fait, on nous a demandé de répéter le parcours d'un des organisateurs, auprès duquel les clients sont venus avec leur problème et leurs données, et de qui ils attendaient une offre commerciale d'ici quelques semaines.
Nous avons travaillé avec les données du PUZK (système de contrôle ultrasonique semi-automatique). Le système est conçu pour vérifier les joints dans le pipeline pour les fissures et les défauts. L'installation elle-même se déplace le long d'un rail monté sur le tuyau et effectue à chaque étape 16 mesures. Dans des conditions idéales et en l'absence de défauts, certains capteurs devraient donner le signal maximum, d'autres - zéro; en réalité, les données étaient très bruyantes et répondre à la question de savoir s'il y avait un défaut à un endroit donné devenait une tâche non triviale.
 Installation du système PUZK
Installation du système PUZKLa première journée a été consacrée à la connaissance des données, au nettoyage, à la compilation de statistiques descriptives. Nous avons reçu des informations de base minimales sur l'installation et les types de capteurs montés sur l'appareil. En plus du prétraitement des données, nous avons dû déterminer à quel type appartiennent les capteurs et comment ils se trouvent sur l'appareil.
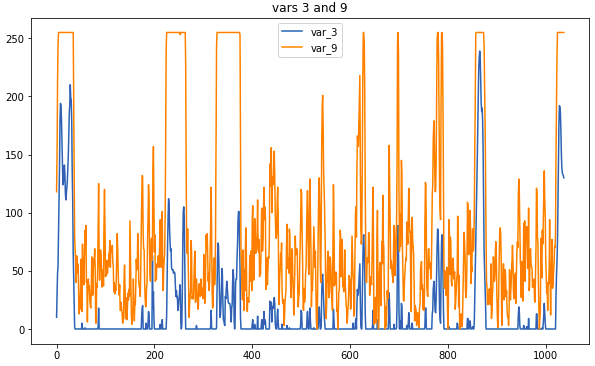 Exemples de données: voici à quoi ressemblent les capteurs associés
Exemples de données: voici à quoi ressemblent les capteurs associésLa principale opération de prétraitement consiste à remplacer les mesures par une moyenne mobile. Si la fenêtre était trop grande, il y avait un risque de perdre trop d'informations, mais les corrélations qui aident à déterminer le type seraient plus visuelles. Certaines connexions étaient visibles sans prétraitement; cependant, nous n'avons pas eu le temps d'examiner attentivement les données brutes, de sorte que l'utilisation de corrélogrammes est indispensable.
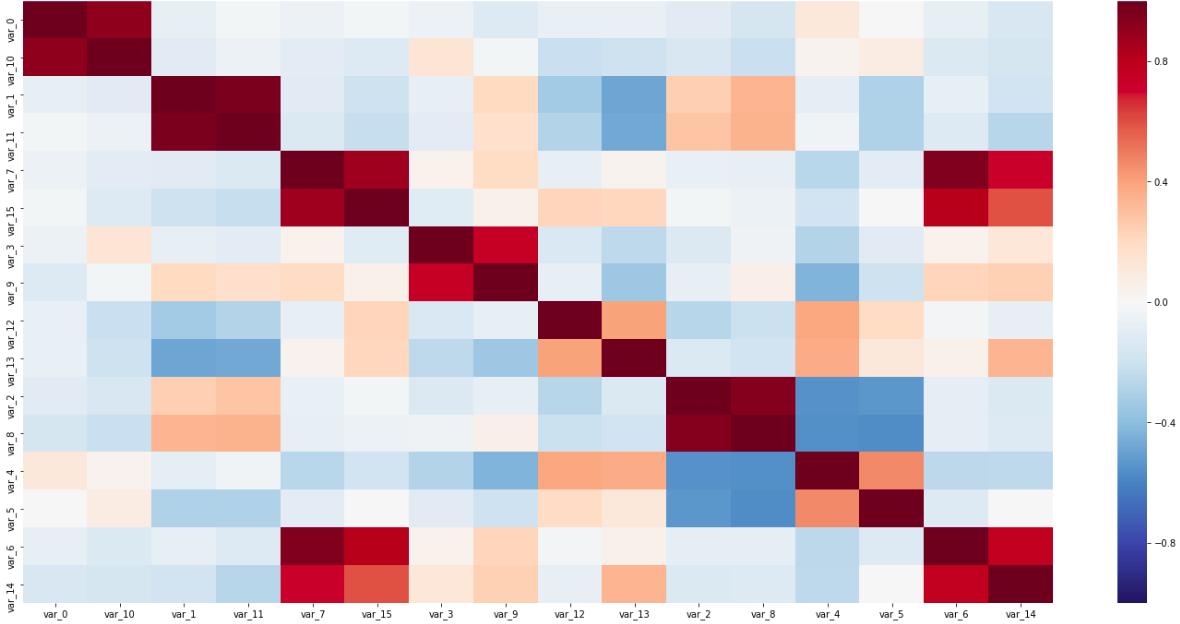 Matrice de corrélation
Matrice de corrélationSur cette matrice, les deux paires de capteurs le long de la diagonale, étroitement liées l'une à l'autre, et les variables inversement corrélatives sont visibles; Tout cela a permis de déterminer les types de capteurs.
Le dernier élément obligatoire était de réduire les capteurs à une coordonnée. Étant donné que l'appareil de mesure comportait nettement plus d'une étape de mesure et que les capteurs étaient espacés sur l'ensemble de l'appareil, il s'agissait d'une étape obligatoire avant toute nouvelle utilisation des données pour la formation.
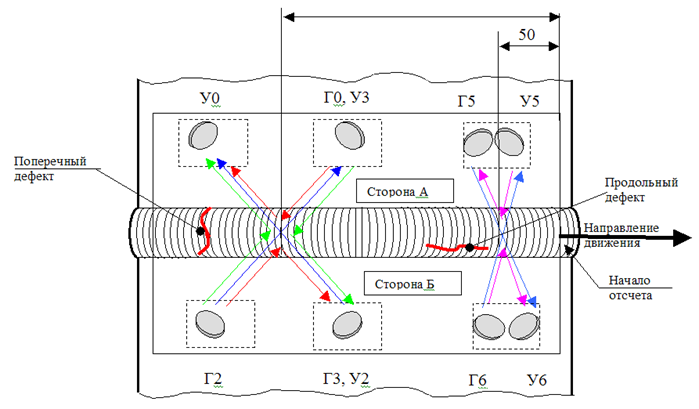
\
Disposition des capteurs sur l'installationLe schéma de l'installation des capteurs sur l'appareil montre que nous devons trouver les distances entre les trois groupes de capteurs. Le moyen le plus simple et le plus rapide consiste à déterminer sur quel segment de l'appareil chaque capteur doit être allumé, puis à rechercher la corrélation maximale, en décalant une partie des mesures d'un pas.
Cette étape a été compliquée par le fait que mes hypothèses sur le type de capteurs n'étaient pas garanties, j'ai donc dû examiner toutes les corrélations, types, schémas et les relier en un seul système cohérent.
Pour le deuxième jour, nous avons dû préparer les données pour la formation et effectuer un regroupement sur les points, puis construire un classificateur.
Lors de la préparation des données, j'ai supprimé les lectures trop corrélatives et, en tant que caractéristique synthétique, j'ai ajouté la moyenne mobile, la dérivée et le score z. Sans aucun doute, la synthèse de nouvelles variables peut se jouer assez largement, mais le temps impose ses limites.
Le regroupement pourrait aider à séparer les points défectueux de tout le monde. J'ai essayé 3 méthodes: k-means, Birch et DBScan, mais, malheureusement, aucune n'a donné un bon résultat.
Pour l'algorithme prédictif, on nous a donné une liberté totale; seul le format devant être obtenu en sortie a été spécifié. L'algorithme était censé fournir une table (ou des données qui lui sont réductibles), dans laquelle une ligne correspond à une fissure, et aux colonnes ses caractéristiques (telles que la longueur, la largeur, le type et le côté). Cela m'a semblé l'option la plus simple, dans laquelle nous faisons une prédiction pour chaque point de l'échantillon d'essai, puis combinons les voisins dans une fissure. En conséquence, j'ai fait 3 classificateurs qui ont répondu aux questions suivantes: de quel côté de la couture se trouve le défaut, à quelle profondeur va-t-il et à quel type appartient-il (longitudinal ou transversal).
Ici, la profondeur à prévoir par régression est frappante; cependant, dans l'échantillon balisé, je n'ai trouvé que 5 profondeurs uniques, j'ai donc trouvé cette simplification acceptable.
 Mesures d'évaluation des algorithmes
Mesures d'évaluation des algorithmesDe tous les algorithmes (j'ai réussi à essayer la régression logistique, l'arbre décisif et le boost de gradient), le boosting, comme prévu, a fait le mieux. Les métriques sont sans aucun doute très agréables, mais il est assez difficile d'évaluer le fonctionnement des algorithmes sans résultats dans un nouvel ensemble de test. Les organisateurs ne sont jamais revenus avec des mesures spécifiques, se limitant à un commentaire général selon lequel personne n'a fait le test aussi bien que sur un échantillon retardé.
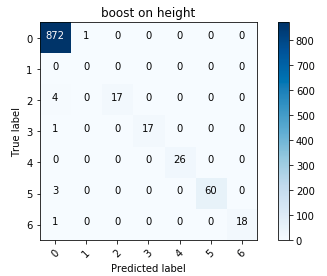 Matrice d'erreur pour le boost
Matrice d'erreur pour le boostEn général, j'étais satisfait des résultats; en particulier, réduire la hauteur à une variable catégorielle a payé.
Au cours de la dernière journée, nous avons dû regrouper les algorithmes formés dans un produit qu'un client potentiel pourrait utiliser et préparer une présentation de notre solution prête pour l'entreprise.
Ici, le perfectionnisme m'a aidé à écrire du code relativement propre, qui n'a pas disparu même dans un temps limité. À partir des morceaux de code prêts à l'emploi, le prototype s'est développé rapidement et j'ai eu le temps de déboguer les erreurs. Contrairement aux étapes précédentes, la performance de la solution a ici joué un rôle plus important, plutôt que de répondre à des critères formels.
 Produit fini - Utilitaire CLI
Produit fini - Utilitaire CLIVers la fin de la session, j'ai obtenu un utilitaire CLI qui accepte un dossier source en entrée et renvoie des tableaux avec les résultats de la prédiction sous une forme pratique pour le technologue.
À l'étape finale, j'ai eu l'occasion de parler de mes succès et de voir à quoi les autres participants étaient parvenus. Même selon des critères stricts, nos décisions étaient complètement différentes - quelqu'un a réussi à se regrouper, d'autres ont habilement utilisé des méthodes linéaires. Au cours des présentations, les candidats ont souligné leurs points forts - certains misaient sur la vente du produit, d'autres plus profondément plongés dans les détails techniques; Il y avait de beaux graphismes et des interfaces de solutions adaptatives.
 Le principal avantage de ma solution tient sur une seule diapositive
Le principal avantage de ma solution tient sur une seule diapositiveEt la compétition en général?
Les concours de ce type sont une excellente occasion de découvrir à quelle vitesse vous êtes en mesure d'effectuer des tâches typiques de votre spécialité. Les critères ont été compilés de telle manière que celui qui obtient les meilleurs résultats (comme, par exemple, sur Kaggle) obtient le plus de points, mais qui est le plus susceptible d'effectuer des opérations typiques du travail quotidien dans l'industrie. À mon avis, la participation et la victoire à de telles compétitions peuvent en dire autant à un employeur potentiel qu'une expérience dans l'industrie, aux hackathons et à Kaggle.
Lenonid Sherstyuk,
Analyste de données, analytique avancée, SIBUR