Quand je pense au fonctionnement des clients RPC naïfs, je me souviens d'une blague:
La cour.
"Accusé, pourquoi avez-vous tué une femme?"
- Je suis dans le bus, le chef d'orchestre s'approche de la femme, lui demandant d'acheter un billet. La femme a ouvert son sac à main, a sorti son sac à main, a fermé son sac à main, a sorti son sac à main, a fermé son sac à main, a ouvert son sac à main, a mis son sac à main là-dedans, a fermé son sac à main, a ouvert son sac à main, a sorti son sac à main, a ouvert son sac à main, a sorti son sac à main, a fermé son sac à main, a ouvert son sac à main, a mis son sac à l'intérieur. , ferma son sac, ouvrit son sac, y mit son sac.
- Et quoi?
- Le contrôleur lui a donné un ticket. Une femme a ouvert son sac à main, a sorti son sac à main, a fermé son sac à main, a ouvert son sac à main, a fermé son sac à main, a ouvert son sac à main, a mis son sac à main là, a fermé son sac à main, a ouvert son sac à main, a mis son ticket là, a fermé son sac à main, a ouvert son sac à main, a sorti son sac à main, a fermé son sac à main, a ouvert son sac à main , mettez le sac dedans, fermez le sac, ouvrez le sac, mettez le sac dedans, fermez le sac.
"Prenez le changement", vint la voix du contrôleur. La femme ... a ouvert son sac à main ...
"Oui, il ne suffit pas de la tuer", le procureur ne résiste pas.
"Alors je l'ai fait."
© S. Altov

À peu près la même chose se produit dans le processus de demande-réponse, si vous l'abordez frivolement:
- le processus utilisateur écrit une requête sérialisée dans le socket, la copiant réellement dans le tampon de socket au niveau du système d'exploitation;
C'est une opération assez difficile, car il est nécessaire de faire un changement de contexte (même si cela peut être «facile»); - lorsqu'il apparaît à l'OS que quelque chose peut être écrit sur le réseau, un paquet est formé (la demande est à nouveau copiée) et envoyé à la carte réseau;
- la carte réseau écrit le paquet sur le réseau (éventuellement après la mise en mémoire tampon);
- (en cours de route, un paquet peut être mis en mémoire tampon plusieurs fois dans les routeurs);
- enfin, le paquet arrive à l'hôte de destination et est mis en mémoire tampon sur la carte réseau;
- la carte réseau envoie une notification au système d'exploitation, et lorsque le système d'exploitation trouve l'heure, elle copie le paquet dans sa mémoire tampon et définit l'indicateur prêt sur le descripteur de fichier;
- (vous devez toujours vous rappeler d'envoyer l'ACK en réponse);
- après un certain temps, l'application serveur se rend compte que le descripteur est prêt (à l'aide d'epoll) et copie un jour la demande dans le tampon d'application;
- et enfin, l'application serveur traite la demande.
Comme vous le savez, la réponse est transmise exactement de la même manière que dans la direction opposée. Ainsi, chaque demande passe du temps notable sur le système d'exploitation pour sa maintenance, et chaque réponse passe à nouveau le même temps.
Cela est devenu particulièrement visible après Meltdown / Spectre, car les correctifs publiés ont entraîné une augmentation significative du coût des appels système. Début janvier 2018, notre cluster Redis a soudainement commencé à consommer un an et demi à deux fois plus de CPU, car Amazon a appliqué les correctifs de noyau appropriés pour couvrir ces vulnérabilités. (Certes, Amazon a appliqué une nouvelle version du correctif un peu plus tard, et la consommation du processeur a chuté presque aux niveaux précédents. Mais le connecteur a déjà commencé à naître.)
Malheureusement, tous les connecteurs Go largement connus de Redis et Memcached fonctionnent exactement comme ceci: le connecteur crée un pool de connexions, et lorsqu'il doit envoyer une demande, il extrait une connexion du pool, y écrit une demande, puis attend une réponse. (Il est particulièrement triste que le connecteur vers Memcached ait été écrit par Brad Fitzpatrick lui-même.) Et certains connecteurs ont une implémentation si infructueuse de ce pool que le processus de suppression de la connexion du pool devient un botnet en soi.
Il existe deux façons de faciliter ce travail difficile de transfert de demande / réponse:
- Utilisez un accès direct à la carte réseau: DPDK, netmap, PF_RING, etc.
- N'envoyez pas chaque demande / réponse dans un package distinct, mais combinez-les, si possible, dans des packages plus volumineux, c'est-à-dire répartissez la charge de travail avec le réseau pour plusieurs requêtes. Ensemble plus de plaisir!
Bien entendu, la première option est possible. Mais, tout d'abord, c'est pour les courageux, car vous devez écrire l'implémentation TCP / IP vous-même (par exemple, comme dans ScyllaDB). Et deuxièmement, de cette façon, nous facilitons la situation d'un seul côté - de celui que nous écrivons nous-mêmes. Je ne veux pas (encore) réécrire Redis, donc les serveurs consommeront la même quantité, même si le client utilise le cool DPDK.
La deuxième option est beaucoup plus simple et, surtout, facilite la situation immédiatement sur le client et sur le serveur. Par exemple, une base de données en mémoire se targue de pouvoir desservir des millions de RPS, tandis que Redis ne peut pas en desservir quelques centaines de milliers . Cependant, ce succès n'est pas tant la mise en œuvre de cette base en mémoire que la décision une fois acceptée que le protocole sera complètement asynchrone, et les clients devraient utiliser cette asynchronie chaque fois que possible. Ce que de nombreux clients (en particulier ceux utilisés dans les tests de performances) mettent en œuvre avec succès en envoyant des demandes via une connexion TCP et, si possible, en les envoyant ensemble au réseau.
Un article bien connu montre que Redis peut également fournir un million de réponses par seconde si un pipeline est utilisé. L'expérience personnelle dans le développement d'histoires en mémoire indique également que le pipelage réduit considérablement la consommation de CPU SYS et vous permet d'utiliser le processeur et le réseau beaucoup plus efficacement.
La seule question est de savoir comment utiliser le pipelining, si dans les demandes d'application dans Redis arrivent souvent une à la fois? Et si un serveur est manquant et que Redis Cluster est utilisé avec un grand nombre de fragments, alors même lorsqu'un paquet de demandes est rencontré, il se divise en demandes uniques pour chaque fragment.
La réponse, bien sûr, est «évidente»: faire un pipeline implicite, collecter les demandes de tous les goroutines fonctionnant en parallèle sur un serveur Redis et les envoyer via une connexion.
Soit dit en passant, la pose implicite de tuyaux n'est pas si rare dans les connecteurs dans d'autres langages: nodejs node_redis , C # RedisBoost , aioredis de python et bien d'autres. Beaucoup de ces connecteurs sont écrits au-dessus des boucles d'événements, et la collecte de requêtes à partir de "flux de calcul" parallèles semble donc naturelle. Dans Go, l'utilisation des interfaces synchrones est encouragée et, apparemment, parce que peu de gens décident d'organiser leur propre «boucle».
Nous voulions utiliser Redis le plus efficacement possible et avons donc décidé d'écrire un nouveau "meilleur" connecteur (tm): RedisPipe .
Comment faire la pose implicite de tuyaux?
Le schéma de base:
- Les goroutines de la logique d'application n'écrivent pas les demandes directement au réseau, mais les transmettent au collecteur de goroutines;
- si possible, le collectionneur recueille un tas de demandes, les écrit sur le réseau et les transmet au lecteur de goroutine;
- Goroutine-reader lit les réponses du réseau, les compare avec les requêtes correspondantes, et informe les goroutines de la logique de la réponse arrivée.
Quelque chose doit être notifié de la réponse. Un programmeur astucieux de Go dira certainement: "Par le canal!"
Mais ce n'est pas la seule primitive de synchronisation possible et pas la plus efficace même dans l'environnement Go. Et puisque différentes personnes ont des besoins différents, nous rendrons le mécanisme extensible, permettant à l'utilisateur d'implémenter l'interface (appelons-le Future ):
type Future interface { Resolve(val interface{}) }
Et puis le schéma de base ressemblera à ceci:
type future struct { req Request fut Future } type Conn struct { c net.Conn futmtx sync.Mutex wfutures []future futtimer *time.Timer rfutures chan []future } func (c *Conn) Send(r Request, f Future) { c.futmtx.Lock() defer c.futmtx.Unlock() c.wfutures = append(c.wfutures, future{req: r, fut: f}) if len(c.wfutures) == 1 { futtimer.Reset(100*time.Microsecond) } } func (c *Conn) writer() { for range c.futtimer.C { c.futmtx.Lock() futures, c.wfutures = c.wfutures, nil c.futmtx.Unlock() var b []byte for _, ft := range futures { b = AppendRequest(b, ft.req) } _, _err := ccWrite(b) c.rfutures <- futures } } func (c *Conn) reader() { rd := bufio.NewReader(cc) var futures []future for { response, _err := ParseResponse(rd) if len(futures) == 0 { futures = <- c.rfutures } futures[0].fut.Resolve(response) futures = futures[1:] } }
Bien sûr, c'est un code très simplifié. Omis:
- établissement de connexion;
- Délais d'E / S
- gestion des erreurs de lecture / écriture;
- rétablir la connexion;
- la possibilité d'annuler la demande avant de l'envoyer au réseau;
- optimisation de l'allocation de mémoire (réutilisation de la mémoire tampon et des tableaux à terme).
Toute erreur d'E / S (y compris un délai d'attente) dans le code réel conduit à une résolution de toutes les erreurs futures correspondant aux demandes envoyées et en attente d'être envoyées.
La couche de connexion n'est pas impliquée dans la nouvelle tentative de demande, et s'il est nécessaire (et possible) de relancer la demande, cela peut être fait à un niveau d'abstraction plus élevé (par exemple, dans la mise en œuvre de la prise en charge de Redis Cluster décrite ci-dessous).
Remarque. Au départ, le circuit semblait un peu plus compliqué. Mais dans le processus d'expériences simplifiées à une telle option.
Remarque 2. Des exigences très strictes sont imposées à la méthode Future.Resolve: elle doit être aussi rapide que possible, pratiquement non bloquante et en aucun cas panique. Cela est dû au fait qu'il est appelé de manière synchrone dans le cycle du lecteur, et tout "frein" entraînera inévitablement une dégradation. La mise en œuvre de Future.Resolve doit faire le minimum nécessaire d'actions linéaires: réveiller l'expectatif; peut-être gérer l'erreur et envoyer une nouvelle tentative asynchrone (utilisée dans l'implémentation de la prise en charge du cluster).
Effet
Une bonne référence est la moitié de l'article!
Une bonne référence est celle qui est la plus proche possible de la lutte contre l'utilisation en termes d'effets observés. Et ce n'est pas facile à faire.
L'option de référence , qui, il me semble, ressemble assez à la vraie:
- le "script" principal émule 5 clients parallèles,
- dans chaque "client", pour chaque 300-1000 rps "souhaités", la goroutine est déclenchée (3 gorutins sont déclenchés pour 1000 rps, 124 gorutins sont exécutés pour 128000 rps),
- gorutin utilise une instance distincte du limiteur de débit et envoie des requêtes en série aléatoire - de 5 à 15 requêtes.
Le caractère aléatoire de la série de requêtes nous permet d'obtenir une distribution aléatoire de la série dans la chronologie, qui reflète plus correctement la charge réelle.
Texte masquéLes mauvaises options étaient:
a) utiliser un limiteur de débit pour tous les gorutins du «client» et y recourir pour chaque demande - cela entraîne une consommation excessive du processeur par le limiteur de débit lui-même, ainsi qu'une augmentation de la rotation dans le temps du goroutin, ce qui dégrade les performances de RedisPipe à des vitesses moyennes (mais inexplicablement s'améliore à haut);
b) utiliser un limiteur de débit pour tous les gorutins du «client» et envoyer des requêtes en série - le limiteur de débit ne mange pas déjà tant le CPU, mais l'alternance des goroutines dans le temps ne fait qu'augmenter;
c) utiliser un limiteur de débit pour chaque goroutine, mais envoyer la même série de 10 demandes - dans ce scénario, les goroutines se réveillent trop simultanément, ce qui améliore injustement les résultats de RedisPipe.
Les tests ont eu lieu sur une instance AWS c5-2xlarge à quatre cœurs. La version de Redis est 5.0.
Le rapport de l'intensité de requête souhaitée, l'intensité totale résultante et consommée par le radis CPU:
| rps prévus | redigo
rps /% cpu | redispipe pas d'attente
rps /% cpu | redispipe 50µs
rps /% cpu | redispipe 150µs
rps /% cpu |
|---|
| 1000 * 5 | 5015/7% | 5015/6% | 5015/6% | 5015/6% |
| 2000 * 5 | 10022/11% | 10022/10% | 10022/10% | 10022/10% |
| 4000 * 5 | 20036/21% | 20036/18% | 20035/17% | 20035/15% |
| 8000 * 5 | 40020/45% | 40062/37% | 40060/26% | 40056/19% |
| 16000 * 5 | 79994/71% | 80102/58% | 80096/33% | 80090/23% |
| 32000 * 5 | 159590/96% | 160 180/80% | 160.167 / 39% | 160 150/29% |
| 64000 * 5 | 187774/99% | 320 313/98% | 320 283/47% | 320 258/37% |
| 92000 * 5 | 183206/99% | 480 443/97% | 480 407/52% | 480 366/42% |
| 128000 * 5 | 179744/99% | 640,484 / 97% | 640,488 / 55% | 640 428/46% |
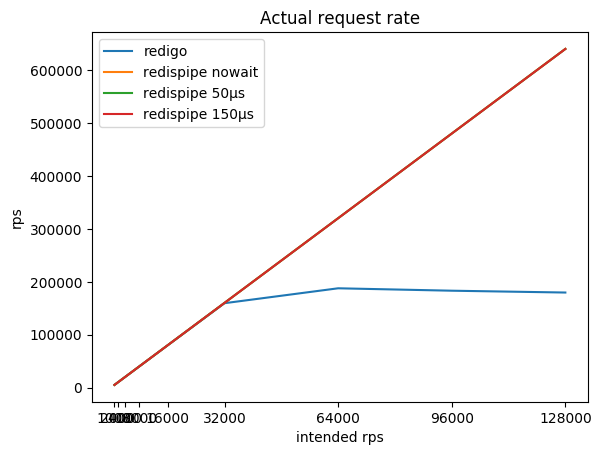
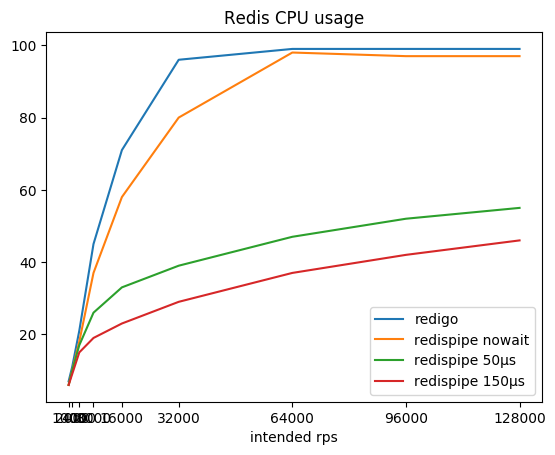
Vous pouvez remarquer qu'avec un connecteur fonctionnant selon le schéma classique (demande / réponse + pool de connexions), Redis mange assez rapidement le cœur du processeur, après quoi il devient impossible d'obtenir plus de 190 krps.
RedisPipe vous permet d'extraire toute la puissance requise de Redis. Et plus nous nous arrêtons pour collecter des requêtes parallèles, moins Redis consomme de CPU. Un avantage tangible est déjà obtenu à 4 krps du client (20 krps au total) si une pause de 150 microsecondes est utilisée.
Même si la pause n'est pas explicitement utilisée lorsque Redis repose sur le CPU, le retard apparaît de lui-même. De plus, les demandes commencent à être mises en mémoire tampon par le système d'exploitation. Cela permet à RedisPipe d'augmenter le nombre de requêtes exécutées avec succès lorsque le connecteur classique baisse déjà ses pattes.
C'est le résultat principal, pour lequel il fallait créer un nouveau connecteur.
Que se passe-t-il alors avec la consommation du processeur sur le client et avec les demandes retardées?
| rps prévus | redigo
% cpu / ms | redispipe nowait
% cpu / ms | redispipe 50ms
% cpu / ms | redispipe 150ms
% cpu / ms |
|---|
| 1000 * 5 | 13 / 0,03 | 20 / 0,04 | 46 / 0,16 | 44 / 0,26 |
| 2000 * 5 | 25 / 0,03 | 33 / 0,04 | 77 / 0,16 | 71 / 0,26 |
| 4000 * 5 | 48 / 0,03 | 60 / 0,04 | 124 / 0,16 | 107 / 0,26 |
| 8000 * 5 | 94 / 0,03 | 119 / 0,04 | 178 / 0,15 | 141 / 0,26 |
| 16000 * 5 | 184 / 0,04 | 206 / 0,04 | 228 / 0,15 | 177 / 0,25 |
| 32000 * 5 | 341 / 0,08 | 322 / 0,05 | 280 / 0,15 | 226 / 0,26 |
| 64000 * 5 | 316 / 1,88 | 469 / 0,08 | 345 / 0,16 | 307 / 0,26 |
| 92000 * 5 | 313 / 2,88 | 511 / 0,16 | 398 / 0,17 | 366 / 0,27 |
| 128000 * 5 | 312 / 3,54 | 509 / 0,37 | 441 / 0,19 | 418 / 0,29 |
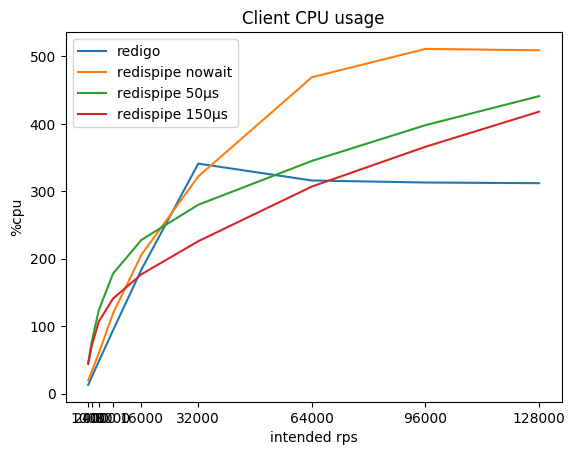
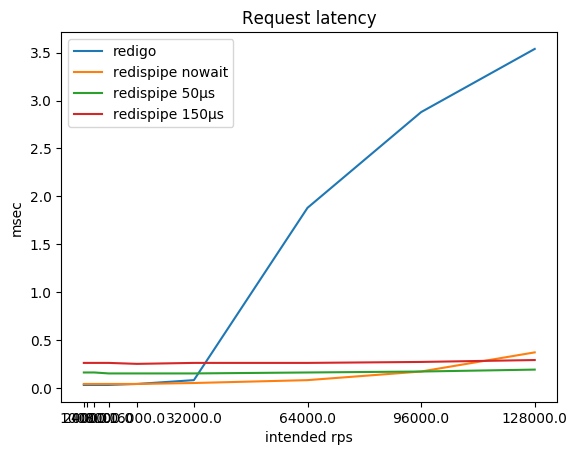
Vous pouvez remarquer que sur les petits rps, RedisPipe lui-même consomme plus de CPU que le "concurrent", surtout si une petite pause est utilisée. Cela est principalement dû à l'implémentation de minuteries dans Go et à l'implémentation des appels système utilisés dans le système d'exploitation (sous Linux, c'est futexsleep), car en mode «sans pause», la différence est nettement moins importante.
Avec l'augmentation de la vitesse par seconde, la surcharge des minuteries est compensée par une baisse de la surcharge pour la mise en réseau et après 16 krps par client, l'utilisation de RedisPipe avec une pause de 150 microsecondes commence à apporter des avantages tangibles.
Bien sûr, après que Redis se soit reposé sur le CPU, la latence des requêtes utilisant le connecteur classique commence à augmenter. Je ne suis pas sûr, cependant, qu'en pratique, vous atteignez souvent 180 krps à partir d'une instance Redis. Mais si c'est le cas, gardez à l'esprit que vous pourriez avoir des problèmes.
Tant que Redis ne s'exécute pas dans le CPU, la latence de la demande souffre bien sûr de l'utilisation d'une pause. Ce compromis est intentionnellement posé dans le connecteur. Cependant, ce compromis n'est perceptible que si Redis et le client sont sur le même hôte physique. Selon la topologie du réseau, un aller-retour vers un hôte voisin peut aller de cent microsecondes à une milliseconde. En conséquence, la différence de retard déjà au lieu de neuf fois (0,26 / 0,03) devient trois fois (0,36 / 0,13) ou n'est mesurée que par quelques dizaines de pour cent (1,26 / 1,03).
Dans notre charge de travail, lorsque Redis est utilisé comme cache, l'attente totale des réponses de la base de données avec un échec de cache est supérieure à l'attente totale des réponses de Redis, car on pense que l'augmentation du délai n'est pas significative.
Le principal résultat positif est une tolérance à la croissance de la charge: si soudainement la charge sur le service augmente N fois, Redis ne consommera pas le même CPU N fois plus. Pour résister au quadruplement de la charge de 160 krps à 640 krps, Redis n'a dépensé que 1,6 fois plus de CPU, augmentant la consommation de 29 à 46%. Cela nous permet de ne pas avoir peur que Redis se plie soudainement. L'évolutivité de l'application ne sera pas non plus déterminée par le fonctionnement du connecteur et le coût de la connectivité réseau (lire: Coûts du processeur SYS).
Remarque. Le code de référence fonctionne avec de petites valeurs. Pour effacer ma conscience, j'ai répété le test avec des valeurs de taille 768 octets. La consommation de CPU par le radis a augmenté de façon marquée (jusqu'à 66% sur une pause de 150 µs), et le plafond pour un connecteur classique tombe à 170 krps. Mais toutes les proportions observées sont restées les mêmes, et donc les conclusions.
Cluster
Pour la mise à l'échelle, nous utilisons Redis Cluster . Cela nous permet d'utiliser Redis non seulement comme cache, mais aussi comme stockage volatile et en même temps de ne pas perdre de données lors de l'expansion / compression d'un cluster.
Redis Cluster utilise le principe du client intelligent, c'est-à-dire le client doit surveiller l'état du cluster lui-même et également répondre aux erreurs auxiliaires renvoyées par le "radis" lorsque le "bouquet" se déplace d'instance en instance.
Par conséquent, le client doit conserver les connexions à toutes les instances Redis du cluster et établir une connexion à celle requise pour chaque demande. Et c'est à cet endroit que le client utilisait auparavant (on ne va pas pointer du doigt) a été bien foiré. L'auteur, qui a surestimé la commercialisation de Go (CSP, canaux, goroutines), a implémenté la synchronisation du travail avec l'état du cluster en envoyant des rappels au goroutine central. C'est devenu un sérieux botnek pour nous. En tant que correctif temporaire, nous avons dû lancer quatre clients sur un cluster, chacun, à son tour, augmentant jusqu'à des centaines de connexions dans le pool pour chaque instance de Redis.
Par conséquent, le nouveau connecteur a été chargé d'empêcher cette erreur. Toutes les interactions avec l'état du cluster sur le chemin d'exécution de la requête se font aussi sans verrouillage que possible:
- l'état de cluster est rendu pratiquement immuable, et pas de nombreuses mutations aromatisées par des atomes
- l'accès à l'état se produit à l'aide de atomic.StorePointer / atomic.LoadPointer, et peut donc être obtenu sans blocage.
Ainsi, même pendant la mise à jour de l'état du cluster, les requêtes peuvent utiliser l'état précédent sans craindre d'attendre un verrou.
Le statut du cluster est mis à jour toutes les 5 secondes. Mais en cas de suspicion d'instabilité du cluster, la mise à jour est forcée:
func (c *Cluster) control() { t := time.NewTicker(c.opts.CheckInterval) defer t.Stop()
Si la réponse MOVED ou ASK reçue du radis contient une adresse inconnue, son ajout asynchrone à la configuration est lancé. (Je suis désolé, je n'ai pas compris comment simplifier le code, car voici le lien .) Ce n'était pas sans utiliser de verrous, mais ils sont pris pour une courte période de temps. La principale attente est réalisée en enregistrant le rappel dans le tableau - le même avenir, vue latérale.
Des connexions sont établies avec toutes les instances Redis, ainsi qu'avec les maîtres et les esclaves. Selon la politique préférée et le type de demande (lecture ou écriture), la demande peut être envoyée à la fois au maître et à l'esclave. Cela prend en compte la "vivacité" de l'instance, qui se compose à la fois des informations obtenues lors de la mise à jour de l'état du cluster et de l'état actuel de la connexion.
func (c *Cluster) connForSlot(slot uint16, policy ReplicaPolicyEnum) (*redisconn.Connection, *errorx.Error) { var conn *redisconn.Connection cfg := c.getConfig() shard := cfg.slot2shard(slot) nodes := cfg.nodes var addr string switch policy { case MasterOnly: addr = shard.addr[0]
Il y a un RoundRobinSeed.Current() cryptique RoundRobinSeed.Current() . Ceci, d'une part, est une source de hasard, et d'autre part, un hasard qui ne change pas fréquemment. Si vous sélectionnez une nouvelle connexion pour chaque demande, cela dégrade l'efficacité du pipeline. C'est pourquoi l'implémentation par défaut modifie la valeur de Current toutes les quelques dizaines de millisecondes. Afin d'avoir moins de superpositions dans le temps, chaque hôte sélectionne son propre intervalle.
Comme vous vous en souvenez, la connexion utilise le concept de Future pour les requêtes asynchrones. Le cluster utilise le même concept: un Future personnalisé s'enroule dans un cluster et celui-ci est alimenté à la connexion.
Pourquoi envelopper un avenir personnalisé? Tout d'abord, en mode Cluster, "radish" renvoie de merveilleuses "erreurs" MOVED et ASK avec des informations où aller pour la clé dont vous avez besoin, et, après avoir reçu une telle erreur, vous devez répéter la demande à un autre hôte. Deuxièmement, étant donné que nous devons toujours implémenter la logique de redirection, alors pourquoi ne pas intégrer la nouvelle tentative de demande avec une erreur d'E / S (bien sûr, uniquement si la demande de lecture):
type request struct { c *Cluster req Request cb Future slot uint16 policy ReplicaPolicyEnum mayRetry bool } func (c *Cluster) SendWithPolicy(policy ReplicaPolicyEnum, req Request, cb Future) { slot := redisclusterutil.ReqSlot(req) policy = c.fixPolicy(slot, req, policy) conn, err := c.connForSlot(slot, policy, nil) if err != nil { cb.Resolve(err) return } r := &request{ c: c, req: req, cb: cb, slot: slot, policy: policy, mayRetry: policy != MasterOnly || redis.ReplicaSafe(req.Cmd), } conn.Send(req, r, 0) } func (r *request) Resolve(res interface{}, _ uint64) { err := redis.AsErrorx(res) if err == nil { r.resolve(res) return } switch { case err.IsOfType(redis.ErrIO): if !r.mayRetry {
Il s'agit également d'un code simplifié. La restriction sur le nombre de tentatives, la mémorisation des connexions problématiques, etc., est omise.
Le confort
Demandes asynchrones, Future est un superkule! Mais terriblement inconfortable.
L'interface est la chose la plus importante. Vous pouvez vendre n'importe quoi s'il a une belle interface. C'est pourquoi Redis et MongoDB ont gagné en popularité.
Il est donc nécessaire de transformer nos requêtes asynchrones en synchrones.
AsError ne ressemble pas à un Go-way natif pour obtenir une erreur. Mais j'aime ça, car à mon avis, le résultat est Result<T,Error> et AsError est un modèle de correspondance ersatz.
Inconvénients
Mais, malheureusement, il y a une mouche dans la pommade dans ce bien-être.
Le protocole Redis n'implique pas de réorganisation des demandes. Et en même temps, il a des demandes de blocage telles que BLPOP, BRPOP.
C'est un échec.
Comme vous le savez, si une telle demande est bloquée, elle bloquera toutes les demandes qui la suivront. Et il n'y a rien à faire à ce sujet.
Après une longue discussion, il a été décidé d'interdire l'utilisation de ces requêtes dans RedisPipe.
Bien sûr, si vous en avez vraiment besoin, vous pouvez: exposer le paramètre ScriptMode: true , et tout cela est dans votre conscience.
Alternatives
En fait, il existe encore une alternative que je n'ai pas mentionnée, mais à laquelle les lecteurs avertis ont pensé, est le roi des caches de cluster twemproxy.
Il fait pour Redis ce que fait notre connecteur: il transforme une "demande / réponse" brute et sans âme en une "pose de tuyaux" douce.
Mais twemproxy lui-même souffrira du fait qu'il devra travailler sur un système de "demande / réponse". Cette fois. Et deuxièmement, nous utilisons le «radis» ainsi que le «stockage non fiable» et parfois nous redimensionnons le cluster. Et twemproxy ne facilite en aucun cas la tâche de rééquilibrage et, en outre, nécessite un redémarrage lors du changement de la configuration du cluster.
Influence
Je n'ai pas eu le temps d'écrire un article et les vagues de RedisPipe ont déjà disparu. Un correctif a été adopté dans Radix.v3 qui ajoute un pipeline à leur pool:
Découvrez RedisPipe et découvrez si sa stratégie de pipelining / batching implicite peut être intégrée
Pipelining automatique pour les commandes dans le pool
Ils sont légèrement inférieurs en vitesse (à en juger par leurs repères; mais je ne le dirai pas avec certitude). Mais leur avantage est qu'ils peuvent envoyer des commandes de blocage à d'autres connexions à partir du pool.
Conclusion
Cela fait déjà un an que RedisPipe contribue à l'efficacité de notre service.
Et en prévision de toute "journée chaude", l'une des ressources, dont la capacité ne pose pas de problème, est le CPU sur les serveurs Redis.
Dépôt
Benchmark