Dans des articles précédents, ils ont déjà écrit sur le fonctionnement de notre technologie de reconnaissance de texte:
Jusqu'en 2018, la reconnaissance des caractères japonais et chinois était organisée de la même manière: tout d'abord, à l'aide de classificateurs raster et d'entités. Mais avec la reconnaissance des hiéroglyphes, il y a des difficultés:
- Un grand nombre de classes à distinguer.
- Caractère de l'appareil plus complexe dans son ensemble.

Il est aussi difficile de dire sans équivoque combien de caractères l'alphabet chinois possède par écrit, car il est exact de compter le nombre de mots en russe. Mais le plus souvent, en écriture chinoise, environ 10 000 caractères sont utilisés. Avec eux, nous avons limité le nombre de classes utilisées en reconnaissance.
Les deux problèmes décrits ci-dessus conduisent également au fait que pour atteindre une qualité élevée, vous devez utiliser un grand nombre de signes et ces signes eux-mêmes sont calculés sur les images des caractères plus longtemps.
Pour que ces problèmes n'entraînent pas de ralentissements sévères dans l'ensemble du système de reconnaissance, j'ai dû utiliser beaucoup d'heuristiques, visant principalement à couper rapidement un nombre important de hiéroglyphes, auxquels cette image ne ressemble définitivement pas. Cela n'a toujours pas aidé à la fin, mais nous voulions porter notre technologie à un tout nouveau niveau.
Nous avons commencé à étudier l'applicabilité des réseaux de neurones convolutifs afin d'augmenter à la fois la qualité et la vitesse de reconnaissance des hiéroglyphes. Je voulais remplacer l'unité entière pour reconnaître un seul caractère pour ces langues à l'aide de réseaux de neurones. Dans cet article, nous décrirons comment nous avons finalement réussi.
Une approche simple: un réseau de convolution pour reconnaître tous les hiéroglyphes
En général, l'utilisation de réseaux convolutifs pour la reconnaissance de caractères n'est pas du tout une idée nouvelle.
Historiquement, ils ont été utilisés pour la
première fois précisément pour cette tâche en 1998. Certes, il ne s'agissait pas de hiéroglyphes imprimés, mais de lettres et de chiffres anglais manuscrits.
En 20 ans, la technologie dans le domaine du deep learning a bien sûr fait un bond en avant. Incluant des architectures plus avancées et de nouvelles approches d'apprentissage.
L'architecture présentée dans le diagramme ci-dessus (LeNet), en fait, et est aujourd'hui très bien adaptée à des tâches aussi simples que la reconnaissance de texte imprimé. «Simple», je l'appelle par rapport à d'autres tâches de vision par ordinateur telles que la recherche et la reconnaissance des visages.
Il semblerait que la solution ne soit nulle part plus simple. Nous prenons un réseau neuronal, un échantillon de hiéroglyphes étiquetés et le formons pour le problème de classification. Malheureusement, il s'est avéré que tout n'est pas si simple. Toutes les modifications possibles de LeNet pour la tâche de classification de 10 000 hiéroglyphes n'ont pas fourni une qualité suffisante (au moins comparable au système de reconnaissance que nous avons déjà).
Pour atteindre la qualité requise, nous avons dû envisager des architectures plus profondes et plus complexes: WideResNet, SqueezeNet, etc. Avec leur aide, il a été possible d'atteindre le niveau de qualité requis, mais ils ont donné un fort ralentissement de la vitesse - 3-5 fois par rapport à l'algorithme de base sur le CPU.
Quelqu'un peut demander: "Quel est l'intérêt de mesurer la vitesse du réseau sur le CPU, si cela fonctionne beaucoup plus vite sur le processeur graphique (GPU)"? Ici, il convient de faire une remarque concernant le fait que la vitesse de l'algorithme sur le CPU est principalement importante pour nous. Nous développons une technologie pour la large gamme de produits de reconnaissance d'ABBYY. Dans le plus grand nombre de scénarios, la reconnaissance se fait côté client, et nous ne pouvons pas savoir qu'il dispose d'un GPU.
Donc, à la fin, nous sommes arrivés au problème suivant: un réseau de neurones pour reconnaître tous les caractères en fonction du choix de l'architecture fonctionne trop mal ou trop lentement.
Modèle de reconnaissance de hiéroglyphes de réseau neuronal à deux niveaux
J'ai dû chercher un autre moyen. En même temps, je ne voulais pas abandonner les réseaux de neurones. Il semblait que le plus gros problème était un grand nombre de classes, à cause de quoi il était nécessaire de construire des réseaux d'architecture complexe. Par conséquent, nous avons décidé que nous ne formerions pas un réseau pour un grand nombre de classes, c'est-à-dire pour l'ensemble de l'alphabet, mais plutôt que nous formerions de nombreux réseaux pour un petit nombre de classes (sous-ensembles de l'alphabet).
Dans les détails généraux, le système idéal a été présenté comme suit: l'alphabet est divisé en groupes de caractères similaires. Le réseau de premier niveau classe à quel groupe de caractères appartient une image donnée. Pour chaque groupe, à son tour, un réseau de deuxième niveau est formé, qui produit la classification finale au sein de chaque groupe.
Image cliquable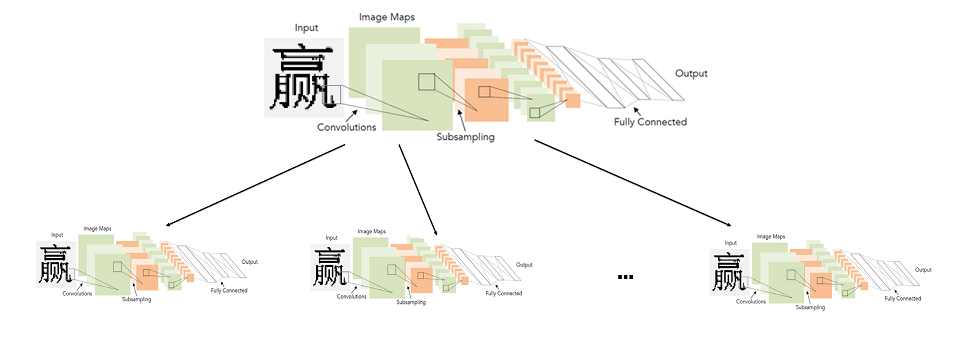
Ainsi, nous faisons le classement final en lançant deux réseaux: le premier détermine quel réseau de second niveau lancer, et le second fait déjà le classement final.
En fait, le point fondamental ici est de savoir comment diviser les personnages en groupes afin que le réseau de premier niveau puisse être rendu précis et rapide.
Construire un classificateur de premier niveau
Pour comprendre quels symboles de réseau sont plus faciles à distinguer et lesquels sont plus difficiles, il est plus facile de regarder quels signes se distinguent pour des symboles particuliers. Pour ce faire, nous avons pris un réseau de classificateurs formé pour distinguer tous les caractères de l'alphabet de bonne qualité et examiné les statistiques d'activation de l'avant-dernière couche de ce réseau - nous avons commencé à examiner les représentations des fonctionnalités finales que le réseau reçoit pour tous les caractères.
En même temps, nous savions que la photo devait être quelque chose comme ceci:
Il s'agit d'un exemple simple dans le cas de la classification d'un échantillon de chiffres manuscrits (MNIST) en 10 classes. Sur l'avant-dernière couche cachée, qui précède la classification, il n'y a que 2 neurones, ce qui facilite l'affichage de leurs statistiques d'activation dans l'avion. Chaque point du graphique correspond à un exemple de l'échantillon de test. La couleur d'un point correspond à une classe spécifique.
Dans notre cas, la dimension de l'espace caractéristique était supérieure à 128 dans l'exemple. Nous avons exécuté un groupe d'images à partir d'un échantillon de test et reçu un vecteur caractéristique pour chaque image. Après cela, ils ont été normalisés (divisés par la longueur). La photo ci-dessus montre clairement pourquoi cela vaut la peine. Nous avons regroupé les vecteurs normalisés par la méthode KMeans. Nous avons obtenu une ventilation de l'échantillon en groupes d'images similaires (du point de vue du réseau).
Mais à la fin, nous devions obtenir une partition de l'alphabet en groupes, et non une partition de l'échantillon de test. Mais la première de la seconde n'est pas difficile à obtenir: il suffit d'attribuer chaque étiquette de classe au cluster qui contient le plus d'images de cette classe. Dans la plupart des situations, bien sûr, toute la classe se retrouvera même à l'intérieur d'un cluster.
Eh bien, c'est tout, nous avons obtenu une partition de l'alphabet entier en groupes de caractères similaires. Reste alors à choisir une architecture simple et à former le classifieur pour distinguer ces groupes.
Voici un exemple de 6 groupes aléatoires qui sont obtenus en divisant l'alphabet source entier en 500 groupes:
Construction de classificateurs de deuxième niveau
Ensuite, vous devez décider des jeux de caractères cibles que les classificateurs de second niveau apprendront. La réponse semble évidente - il devrait s'agir de groupes de caractères obtenus à l'étape précédente. Cela fonctionnera, mais pas toujours avec une bonne qualité.
Le fait est que le classificateur du premier niveau fait en tout cas des erreurs et elles peuvent être partiellement compensées par la construction d'ensembles du deuxième niveau comme suit:
- Nous corrigeons un certain échantillon séparé d'images de symboles (ne participant ni à la formation ni aux tests);
- Nous exécutons cet échantillon à travers un classificateur de premier niveau formé, marquant chaque image avec l'étiquette de ce classificateur (étiquette de groupe);
- Pour chaque symbole, nous considérons tous les groupes possibles auxquels le classifieur du premier niveau appartient aux images de ce symbole;
- Ajoutez ce symbole à tous les groupes jusqu'à ce que le degré de couverture requis T_acc soit atteint;
- Nous considérons les groupes finaux de symboles comme des ensembles cibles du deuxième niveau, sur lesquels les classificateurs seront formés.
Par exemple, les images du symbole «A» ont été attribuées par le classificateur de premier niveau 980 fois au 5e groupe, 19 fois au 2e groupe et 1 fois au 6e groupe. Au total, nous avons 1000 images de ce symbole.
Ensuite, nous pouvons ajouter le symbole «A» au 5e groupe et obtenir une couverture de 98% de ce symbole. Nous pouvons l'attribuer aux 5e et 2e groupes et obtenir une couverture de 99,9%. Et nous pouvons immédiatement l'attribuer à des groupes (5, 2, 6) et obtenir une couverture à 100%.
En substance, T_acc établit un certain équilibre entre la vitesse et la qualité. Plus elle est élevée, plus la qualité finale de la classification sera élevée, mais plus les ensembles cibles du deuxième niveau seront grands et plus la classification au deuxième niveau sera difficile.
La pratique montre que même avec T_acc = 1, l'augmentation de la taille des ensembles à la suite de la procédure de réapprovisionnement décrite ci-dessus n'est pas si importante - en moyenne, environ 2 fois. Évidemment, cela dépendra directement de la qualité du classificateur de premier niveau formé.
Voici un exemple du fonctionnement de cette complétion pour l'un des ensembles de la même partition en 500 groupes, qui était plus élevé:
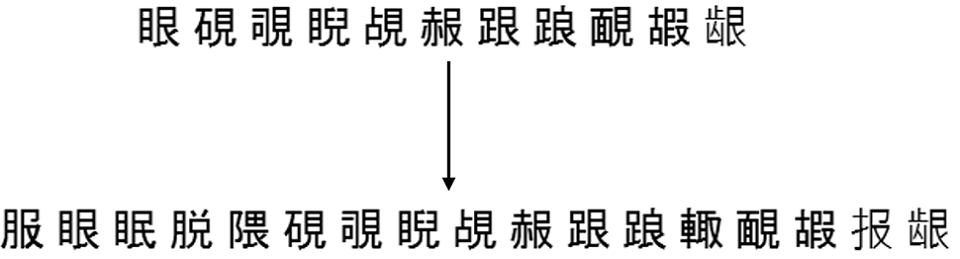
Résultats d'intégration du modèle
Les modèles à deux niveaux formés ont finalement fonctionné plus rapidement et mieux que les classificateurs précédemment utilisés. En fait, il n'était pas si facile de «se faire des amis» avec le même graphe de division linéaire (GLD). Pour ce faire, j'ai dû enseigner séparément le modèle pour distinguer les caractères des erreurs de segmentation des ordures et de segmentation a priori (pour retourner une faible confiance dans ces situations).
Résultat final de l'intégration dans l'algorithme de reconnaissance de document complet ci-dessous (obtenu sur la collection de documents chinois et japonais), la vitesse est indiquée pour l'algorithme complet:
Nous avons amélioré la qualité et accéléré à la fois en mode normal et en mode rapide, tout en transférant toute la reconnaissance des caractères aux réseaux de neurones.
Un peu sur la reconnaissance de bout en bout
Aujourd'hui, la plupart des systèmes OCR connus du public (le même Tesseract de Google) utilisent l'architecture de bout en bout des réseaux de neurones pour reconnaître les chaînes ou leurs fragments dans son intégralité. Mais ici, nous avons utilisé les réseaux de neurones précisément pour remplacer un module de reconnaissance de caractère unique. Ce n'est pas un hasard.
Le fait est que la segmentation d'une chaîne en caractères en chinois et en japonais imprimés n'est pas un gros problème en raison de l'impression à
espacement fixe . À cet égard, l'utilisation de la reconnaissance de bout en bout pour ces langues n'améliore pas considérablement la qualité, mais elle est beaucoup plus lente (au moins sur le processeur). En général, il n'est pas clair comment utiliser l'approche à deux niveaux proposée dans le contexte de bout en bout.
Au contraire, il existe des langues pour lesquelles la division linéaire en caractères est un problème clé. Des exemples explicites sont l'arabe, l'hindi. Pour l'arabe, par exemple, les solutions de bout en bout sont déjà activement étudiées avec nous. Mais c'est une histoire complètement différente.
Alexey Zhuravlev, responsable du groupe OCR New Technologies