Bonjour, Habr! Je m'appelle Sergey Lezhnin, je suis architecte senior à Sbertekh. L'une des directions de mon travail est le système frontal unifié. Ce système dispose d'un service de gestion des paramètres de configuration. Il est utilisé par de nombreux utilisateurs, services et applications, ce qui nécessite des performances élevées. Dans cet article, je vais vous expliquer comment ce service a évolué de la première, la plus simple, à sa version actuelle et pourquoi nous avons finalement déployé toute l'architecture à 180 degrés.

C'est là que nous avons commencé - c'est la première implémentation du service de gestion des paramètres:
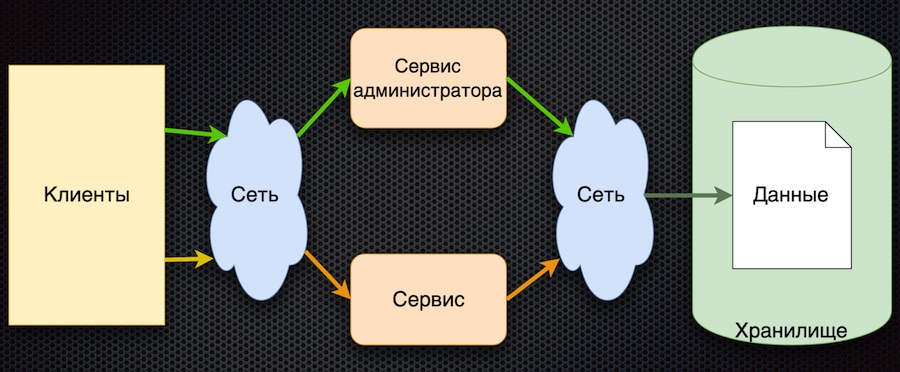
Le client demande des paramètres de configuration au service. Le service traduit la demande dans la base de données, reçoit une réponse et la renvoie au client. Dans le même temps, les administrateurs peuvent gérer les paramètres à l'aide de leur service distinct: ajouter de nouvelles valeurs, modifier les valeurs actuelles.
Cette approche a un avantage: la simplicité. Il y a plus d'inconvénients, bien qu'ils soient tous liés:
- accès fréquent au stockage sur le réseau,
- une forte concurrence pour l'accès à la base de données (nous l'avons située sur un nœud),
- mauvaise performance.
Pour réussir le test de charge, cette architecture ne devait pas fournir la charge plus que celle qui provient d'un accès direct à la base de données. En conséquence, le test de charge de ce circuit n'a pas réussi.
Deuxième étape: nous avons décidé de mettre en cache les données côté service.

Ici, les données de la demande sont initialement chargées dans le cache partagé et sont renvoyées du cache lors des demandes suivantes. L'administrateur de service gère non seulement les données, mais les marque également dans le cache afin que, lorsqu'elles changent, elles soient mises à jour.
Nous avons donc réduit le nombre d'accès au référentiel. Dans le même temps, la synchronisation des données s'est avérée simple, car le service administrateur a accès au cache en mémoire et contrôle la réinitialisation. En revanche, en cas de défaillance du réseau, le client ne pourra pas recevoir de données. Et en général, la logique d'obtention des données est compliquée: s'il n'y a pas de données dans le cache, vous devez les récupérer dans la base de données, les mettre dans le cache et ensuite les renvoyer. Besoin de se développer davantage.
La troisième étape du développement est la mise en cache des données côté client:
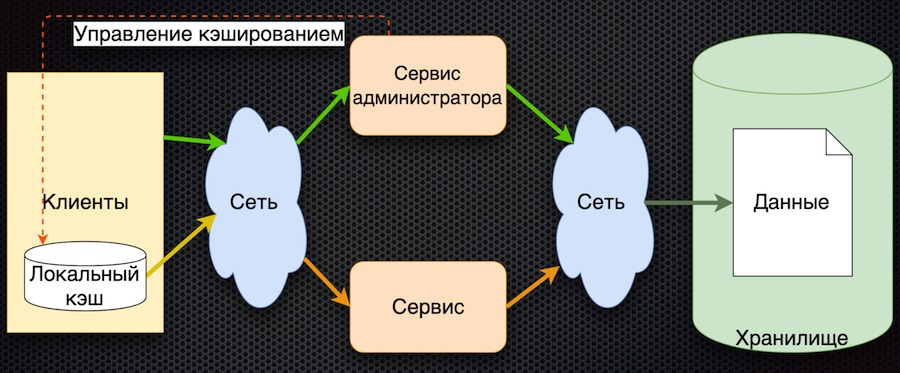
Le client dispose d'un shell pour accéder au service (le «module client»), qui cache le cache de données local. Si les données demandées ne sont pas dans le cache lors de la demande, le service est appelé. Le service demande des paramètres à la base de données et les renvoie. Par rapport au schéma précédent, la gestion de la mise en cache est ici compliquée. Pour réinitialiser les paramètres, le service doit informer les clients que ces paramètres ont changé.
Dans cette architecture, nous réduisons le nombre d'appels au service et à la base de données. Maintenant, si le paramètre est déjà demandé, il reviendra au client sans accéder au réseau, même si le service ou la base de données n'est pas disponible. D'un autre côté, le gros inconvénient est que la logique d'échange de données avec le client est compliquée, vous devez également le notifier via un service - par exemple, la file d'attente de messages. Le client doit s'abonner au sujet, il reçoit des notifications sur la modification des paramètres et dans son cache, le client doit les réinitialiser pour obtenir de nouvelles valeurs. Schéma assez compliqué.
Enfin, nous arrivons à la dernière étape en ce moment. En cela, nous avons été aidés par les principes de base formulés dans le Manifeste réactif.
- Réactif: le système répond le plus rapidement possible.
- Résilient: le système continue de répondre même en cas de panne.
- Élastique: le système utilise les ressources en fonction de la charge.
- Message Driven: fournit une messagerie asynchrone et gratuite entre les composants du système.
Le schéma correspondant à cette approche s'est avéré assez simple:
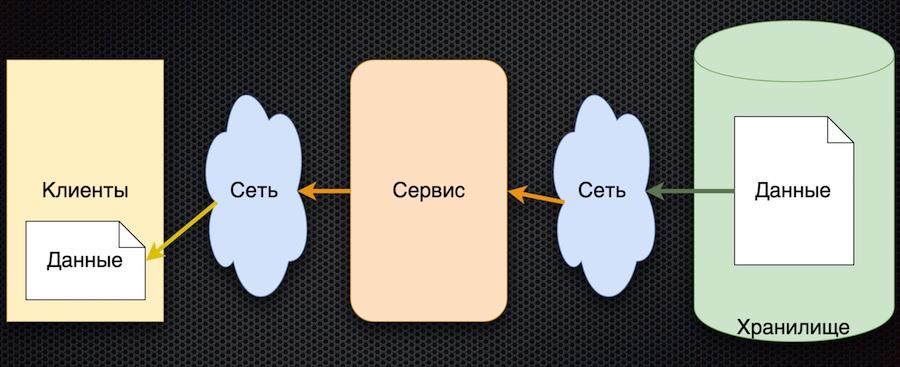
Le principe général est le suivant: le client souscrit au paramètre de configuration et lorsque ses valeurs changent, le serveur en informe le client. Le schéma ci-dessus est légèrement simplifié: il ne reflète pas que lorsqu'un client s'inscrit, il doit s'initialiser et obtenir la valeur initiale. Mais il y a ensuite l'essentiel: les flèches ont changé de direction. Auparavant, un client ou un cache demandait activement un service pour les modifications de données, mais maintenant le service lui-même envoie des événements sur les modifications de données, et ils sont mis à jour par le client.
Cette architecture présente plusieurs avantages importants. Le nombre d'appels au service et au stockage est réduit, car le client ne le demande pas activement. En fait, l'appel pour chaque paramètre souhaité ne se produit qu'une seule fois, lors de la souscription. Ensuite, le client reçoit déjà simplement un flux de modifications. La disponibilité des données augmente car le client a toujours une valeur - elle est mise en cache. Et en général, ce schéma d'échange de paramètres est assez simple.
Le seul inconvénient de cette architecture est l'incertitude de l'initialisation des données. Jusqu'à la première mise à jour par abonnement, la valeur du paramètre reste indéfinie. Mais cela peut être résolu en définissant les valeurs des paramètres par défaut du client, qui sont remplacées par les valeurs réelles lors de la première mise à jour.
Sélection de technologies
Après avoir approuvé le schéma, nous avons commencé la recherche de produits pour sa mise en œuvre.
Choisissez entre
Vertx.io ,
Akka.io et
Spring Boot .

Le tableau résume les caractéristiques qui nous intéressent. Vertx et Akka ont des acteurs, et Sping Boot a une bibliothèque de microservices qui est essentiellement proche des acteurs. De même avec la réactivité: Spring Boot a sa propre bibliothèque WebFlux qui implémente les mêmes fonctionnalités. Nous avons estimé la légèreté approximativement dans le tableau. Quant aux langages, sur les trois options, Vertx est considéré comme un polyglotte: il prend en charge Java, Scala, Kotlin et JavaScript. Akka a Scala et Java; Kotlin peut probablement aussi être utilisé, mais il n'y a pas de support direct. Spring a Java, Kotlin et Groovy.
En conséquence, Vertx a gagné. Soit dit en passant, ils ont beaucoup parlé de lui lors de la conférence JUG, et en effet de nombreuses entreprises l'utilisent. Voici une capture d'écran du site du développeur:

Sur Vertx.io, le schéma d'implémentation de notre solution est le suivant:

Nous avons décidé de stocker les paramètres non pas dans la base de données, mais dans le référentiel Git. Nous pouvons très bien utiliser cette source de données relativement lente car le client ne demande pas activement de paramètres et le nombre de hits est réduit.
Un lecteur (verticle) lit les données du référentiel Git dans la mémoire de l'application pour accélérer l'accès des utilisateurs aux données. Ceci est important, par exemple, lors de la souscription à des paramètres. De plus, le lecteur traite les mises à jour - relit et marque les données, remplace les anciennes par de nouvelles.
Event Bus est un service Vertx qui envoie des événements entre les verticales ainsi que via des ponts. Y compris à travers le pont websocket, qui est utilisé dans ce cas. Lorsque des événements de changement de paramètre arrivent, le bus d'événements les envoie au client.
Enfin, côté client, un simple client web est implémenté ici, qui souscrit aux événements (changements de paramètres) et affiche ces changements sur les pages.
Comment ça marche
Nous montrons comment tout fonctionne grâce à une application Web.
Nous lançons la page d'application dans le navigateur. Nous souscrivons aux changements de données clés. Ensuite, nous allons à la page du projet dans le GitLab local, modifions les données au format JSON et les enregistrons dans le référentiel. L'application affiche la modification correspondante, dont nous avions besoin.
C’est tout. Vous pouvez trouver le code source de la démo dans mon
dépôt git , et poser des questions dans les commentaires.