
Les réseaux sociaux sont aujourd'hui l'un des produits Internet les plus populaires et l'une des principales sources de données pour l'analyse. Au sein des réseaux sociaux eux-mêmes, la tâche la plus difficile et la plus intéressante dans le domaine de la science des données est considérée comme la formation d'un fil d'actualité. En effet, afin de répondre aux demandes croissantes de l'utilisateur pour la qualité et la pertinence du contenu, il est nécessaire d'apprendre à collecter des informations à partir de nombreuses sources, à calculer la prévision de la réaction de l'utilisateur et à équilibrer entre des dizaines de métriques concurrentes dans le test A / B. Et de grandes quantités de données, des charges de travail élevées et des exigences strictes en termes de vitesse de réponse rendent la tâche encore plus intéressante.
Il semblerait qu'aujourd'hui les tâches de classement aient déjà été étudiées de long en large, mais si vous regardez de plus près, ce n'est pas si simple. Le contenu du flux est très hétérogène - il s'agit d'une photo d'amis et de mémos, de vidéos virales, de longues lectures et de pop scientifique. Pour tout assembler, vous avez besoin de connaissances dans différents domaines: vision par ordinateur, travail avec des textes, systèmes de recommandation et, sans faute, outils de stockage et de traitement de données modernes et très chargés. Trouver une personne avec toutes les compétences est extrêmement difficile aujourd'hui, donc le tri de la bande est vraiment une tâche d'équipe.
Odnoklassniki a commencé à expérimenter différents algorithmes de classement de ruban en 2012, et en 2014, l'apprentissage automatique a également rejoint ce processus. Cela a été rendu possible, tout d'abord, grâce aux progrès réalisés dans le domaine des technologies de travail avec les flux de données. Tout en commençant à collecter les affichages d'objets et leurs attributs dans
Kafka et à agréger les journaux à l'aide de
Samza , nous avons pu créer un ensemble de données pour les modèles de formation et
calculer les fonctionnalités les plus «attractives» : les objets Click Through Rate et les prévisions du système de recommandation «sur la base» du
travail de collègues de LinkedIn .

Il est rapidement devenu évident que le cheval de bataille de la régression logistique ne peut pas retirer la bande seule, car l'utilisateur peut avoir une réaction très diverse: classe, commentaire, clic, masquage, etc., et le contenu peut être très différent - photo un ami, un message de groupe ou un vidosik inscrit par un ami. Chaque réaction pour chaque type de contenu a sa propre spécificité et sa propre valeur commerciale. En conséquence, nous sommes arrivés au concept d'une «
matrice de régressions logistiques »: un modèle distinct est construit pour chaque type de contenu et chaque réaction, puis leurs prévisions sont multipliées par une matrice de poids formée à la main en fonction des priorités commerciales actuelles.
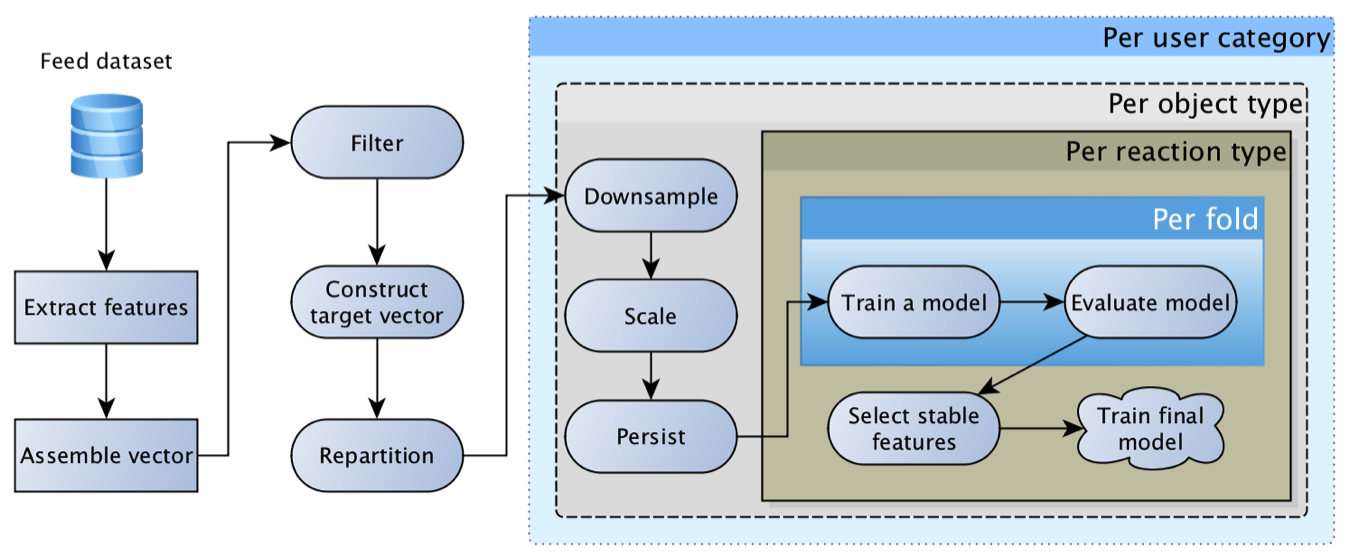
Ce modèle était extrêmement viable et a longtemps été le principal. Au fil du temps, il a acquis des fonctionnalités de plus en plus intéressantes: pour les objets, pour les utilisateurs, pour les auteurs, pour la relation de l'utilisateur avec l'auteur, pour ceux qui ont interagi avec l'objet, etc. En conséquence, les premières tentatives de remplacer la régression par un réseau de neurones se sont soldées par un triste "caractéristiques que nous avons sont trop nulles, le maillage ne donne pas un coup de pouce".
Dans ce cas, le coup de pouce le plus tangible du point de vue de l'activité des utilisateurs a été fourni par des améliorations techniques plutôt qu'algorithmiques: récupérez plus de candidats pour le classement, suivez plus précisément les faits de l'émission, optimisez la vitesse de réponse de l'algorithme et approfondissez l'historique de navigation. Ces améliorations ont souvent donné des unités, et parfois même des dizaines de pour cent d'augmentation d'activité, tandis que la mise à jour du modèle et l'ajout d'une fonctionnalité ont souvent donné des dixièmes de pour cent d'augmentation.

Une difficulté distincte dans les expériences de mise à jour du modèle était de créer un rééquilibrage du contenu - la distribution des prévisions du «nouveau» modèle pouvait souvent différer considérablement de son prédécesseur, ce qui conduisait à une redistribution du trafic et des commentaires. Par conséquent, il est difficile d'évaluer la qualité du nouveau modèle, car vous devez d'abord calibrer l'équilibre du contenu (répétez le processus de définition des poids de la matrice à des fins commerciales). Après avoir étudié l'
expérience de collègues de Facebook , nous avons réalisé que le modèle
doit être calibré , et une régression isotonique a été ajoutée en plus de la régression logistique :).
Souvent en train de préparer de nouveaux attributs de contenu, nous avons vécu de la frustration - un modèle simple utilisant des techniques collaboratives de base peut donner 80%, voire 90% du résultat, tandis qu'un réseau de neurones à la mode, formé pendant une semaine sur des GPU super chers, détecte parfaitement les chats et les voitures, mais donne une augmentation métriques uniquement dans le troisième chiffre. Un effet similaire peut souvent être observé lors de la mise en œuvre de modèles thématiques, de fastText et d'autres intégrations. Nous avons réussi à surmonter la frustration en regardant la validation sous le bon angle: les performances des algorithmes collaboratifs s'améliorent considérablement à mesure que les informations sur l'objet s'accumulent, tandis que pour les objets «frais», les attributs de contenu donnent un coup de pouce tangible.
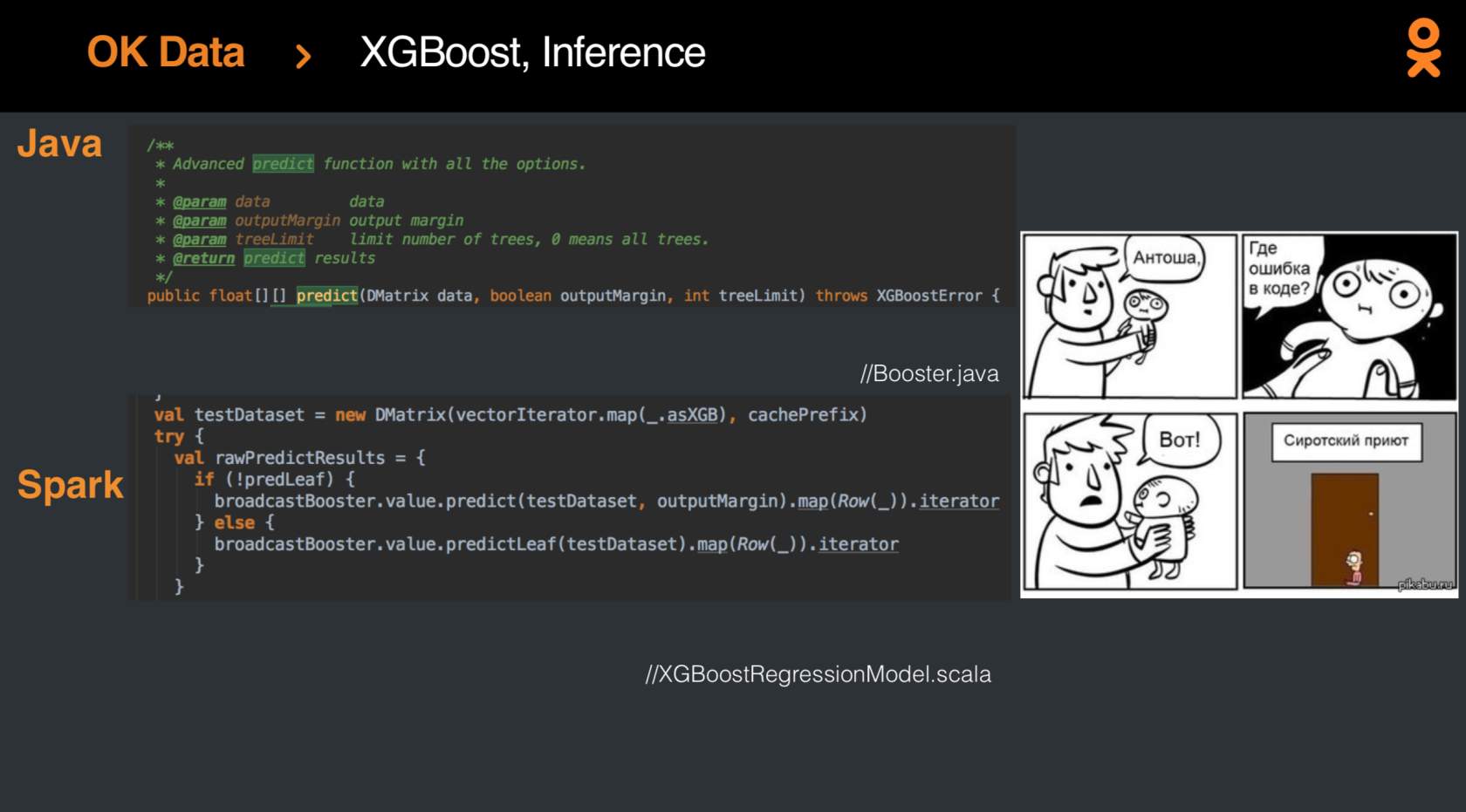
Mais, bien sûr, un jour, les résultats de la régression logistique devaient être améliorés, et des progrès ont été réalisés en appliquant le
XGBoost-Spark récemment publié. L'intégration
n'a pas été facile , mais à la fin, le modèle est finalement devenu à la mode et jeune, et les mesures ont augmenté de pour cent.
Certes, beaucoup plus de connaissances peuvent être extraites des données et le classement de la bande peut être porté à un nouveau niveau - et aujourd'hui, tout le monde a la possibilité de s'essayer à cette tâche non triviale lors de la compétition
SNA Hackathon 2019 . Le concours se déroule en deux étapes: du 7 février au 15 mars, téléchargez la solution pour l'une des trois tâches. Après le 15 mars, les résultats intermédiaires seront résumés et 15 personnes du haut du classement pour chaque tâche recevront des invitations à la deuxième étape, qui se tiendra du 30 mars au 1er avril au bureau de Moscou du groupe Mail.ru. De plus, l'invitation à la deuxième étape recevra trois personnes en tête du classement à la fin du 23 février.
Pourquoi y a-t-il trois tâches? Dans le cadre de la phase en ligne, nous proposons trois ensembles de données, dont chacun ne présente qu'un seul des aspects: image, texte ou informations sur une variété d'attributs collaboratifs. Et ce n'est qu'à la deuxième étape, lorsque des experts dans différents domaines se réuniront, que l'ensemble de données générales sera révélé, vous permettant de trouver des points pour la synergie des différentes méthodes.
Intéressé par une tâche? Rejoignez le
SNA Hackathon :)