Bill Kennedy a déclaré dans une conférence sur son merveilleux cours de
programmation Ultimate Go :
De nombreux développeurs cherchent à optimiser leur code. Ils prennent une ligne et la réécrivent, disant que cela deviendra plus rapide. Besoin d'arrêter. Dire que tel ou tel code est plus rapide n'est possible qu'après avoir été profilé et effectué des benchmarks. La bonne aventure n'est pas la bonne approche pour écrire du code.
Je souhaite depuis longtemps montrer avec un exemple pratique comment cela peut fonctionner. Et l'autre jour, mon attention a été attirée sur le code suivant, qui pourrait simplement être utilisé comme un tel exemple:
builds := store.Instance.GetBuildsFromNumberToNumber(stageBuild.BuildNumber, lastBuild.BuildNumber) tempList := model.BuildsList{} for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchURLs = b.ReversePatchURLs b.ExtractedSize = b.RPatchExtractedSize tempList = append(tempList, b) }
Ici, dans tous les éléments de la tranche de
builds renvoyée par la base de données,
PatchURLs est remplacé par
ReversePatchURLs ,
ExtractedSize par
RPatchExtractedSize et reverse est effectué - l'ordre des éléments est modifié de sorte que le dernier élément devient le premier et le premier dernier.
À mon avis, le code source est un peu compliqué à lire et peut être optimisé. Ce code exécute un algorithme simple composé de deux parties logiques: la modification des éléments de tranche et le tri. Mais pour que le programmeur puisse isoler ces deux composants, cela prendra du temps.
Malgré le fait que les deux parties sont importantes, le code inverse n'est pas aussi souligné que nous le souhaiterions. Il est dispersé sur trois lignes déchirées: initialisation d'une nouvelle tranche, itération d'une tranche existante dans l'ordre inverse, ajout d'un élément à la fin d'une nouvelle tranche. Néanmoins, on ne peut ignorer les avantages incontestables de ce code: le code fonctionne et est testé, et parlant objectivement, il est tout à fait adéquat. La perception subjective du code par un développeur individuel ne peut pas être une excuse pour le réécrire. Malheureusement ou heureusement, nous ne réécrivons pas le code simplement parce que nous ne l'aimons tout simplement pas (ou, comme cela arrive souvent, tout simplement parce qu'il n'est pas le nôtre, voir
Fatal fault ).
Mais que faire si nous parvenons non seulement à améliorer la perception du code, mais aussi à l'accélérer de manière significative? C'est une question complètement différente. Vous pouvez proposer plusieurs algorithmes alternatifs qui exécutent les fonctionnalités intégrées dans le code.
Première option: itération sur tous les éléments d'une boucle de
plage ; Pour inverser la tranche d'origine à chaque itération, ajoutez un élément au début du tableau final. Ainsi, nous pourrions nous débarrasser de la lourdeur
car , variable
i , utiliser la fonction
len , il est difficile de percevoir l'itération sur les éléments de la fin, et également de réduire la quantité de code de deux lignes (de sept lignes à cinq), et plus le code est petit, moins il est probable qu'il le permette une erreur.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*store.Build{build}, tempList...) }
Après avoir supprimé l'énumération de tranche de la fin, nous avons clairement fait la distinction entre les opérations de modification des éléments (3e ligne) et l'inverse du tableau d'origine (4e ligne).
L'idée principale de la deuxième option est d'exploser davantage la variation des éléments et le tri. Tout d'abord, nous trions les éléments et les modifions, puis trions la tranche par une opération distincte. Cette méthode nécessitera une implémentation supplémentaire de l'interface de tri pour la tranche, mais elle augmentera la lisibilité et séparera et isolera complètement l'inverse des éléments changeants, et la méthode
inverse indiquera définitivement au lecteur le résultat souhaité.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(sort.IntSlice(keys)))
La troisième option est presque une répétition de la seconde, mais
sort.Slice est utilisé pour le tri, ce qui augmente la quantité de code d'une ligne, mais évite l'implémentation supplémentaire de l'interface de tri.
for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id })
À première vue, en termes de complexité interne, nombre d'itérations, fonctions appliquées, le code initial et le premier algorithme sont proches; les deuxième et troisième options peuvent sembler plus difficiles, mais il est impossible de dire sans équivoque laquelle des quatre options est optimale.
Nous nous sommes donc interdits de prendre des décisions basées sur des hypothèses non étayées par des preuves, mais il est évident que le plus intéressant ici est le comportement de la fonction d'ajout lors de l'ajout d'un élément à la fin et au début de la tranche. Après tout, en fait, cette fonction n'est pas aussi simple qu'il y paraît.
Append fonctionne
comme suit : il ajoute un nouvel élément à la tranche existante si sa capacité est supérieure à la longueur totale, ou réserve en mémoire une place pour une nouvelle tranche, en copiant les données de la première tranche, en ajoutant les données de la seconde et en renvoyant un nouveau comme résultat. tranche.
La nuance la plus intéressante dans le travail de cette fonction est l'algorithme utilisé pour réserver de la mémoire pour un nouveau tableau. Étant donné que l'opération la plus coûteuse consiste à allouer un nouveau morceau de mémoire, les développeurs de Go ont fait une petite astuce pour rendre l'opération d'
ajout moins chère. Au début, afin de ne pas réserver à nouveau la mémoire à chaque fois qu'un élément est ajouté, la quantité de mémoire est allouée avec une certaine marge - deux fois l'original, mais après un certain nombre d'éléments, la taille de la section de mémoire nouvellement réservée ne devient pas plus de deux fois, mais de 25%.
Compte tenu de la nouvelle compréhension de la fonction
append, la réponse à la question: "Qu'est-ce qui sera plus rapide: ajouter un élément à la fin d'une tranche existante ou ajouter une tranche existante à une tranche d'un élément?" - déjà plus transparent. On peut supposer que dans le deuxième cas, par rapport au premier, il y aura plus d'allocations de mémoire, ce qui affectera directement la vitesse de travail.
Nous nous sommes donc approchés en douceur des repères. À l'aide de benchmarks, vous pouvez évaluer la charge de l'algorithme sur les ressources les plus critiques, telles que le runtime et la RAM.
Écrivons une référence pour évaluer nos quatre algorithmes, en même temps nous évaluerons quelle croissance peut nous donner le rejet du tri (afin de comprendre combien de temps total est consacré à le trier). Code de référence:
package services import ( "testing" "sort" ) type Build struct { Id int ExtractedSize int64 PatchUrls string ReversePatchUrls string RPatchExtractedSize int64 } type Builds []*Build func (a Builds) Len() int { return len(a) } func (a Builds) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Builds) Less(i, j int) bool { return a[i].Id < a[j].Id } func prepare() Builds { var builds Builds for i := 0; i < 100000; i++ { builds = append(builds, &Build{Id: i}) } return builds } func BenchmarkF1(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchUrls, b.ExtractedSize = b.ReversePatchUrls, b.RPatchExtractedSize tempList = append(tempList, b) } } } func BenchmarkF2(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*Build{build}, tempList...) } } } func BenchmarkF3(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(builds)) } } func BenchmarkF4(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id }) } } func BenchmarkF5(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } } }
Lancez le benchmark avec la commande
go test -bench =. -benchmem .
Les résultats des calculs pour les tranches 10, 100, 1000, 10 000 et 100 000 éléments sont présentés dans le graphique ci-dessous, où F1 est l'algorithme initial, F2 est l'ajout de l'élément au début du tableau, F3 est l'utilisation de
sort.Inversement pour trier, F4 est l'utilisation de
sort. , F5 - rejet du tri.
Temps d'opération Nombre d'allocations de mémoire
Nombre d'allocations de mémoire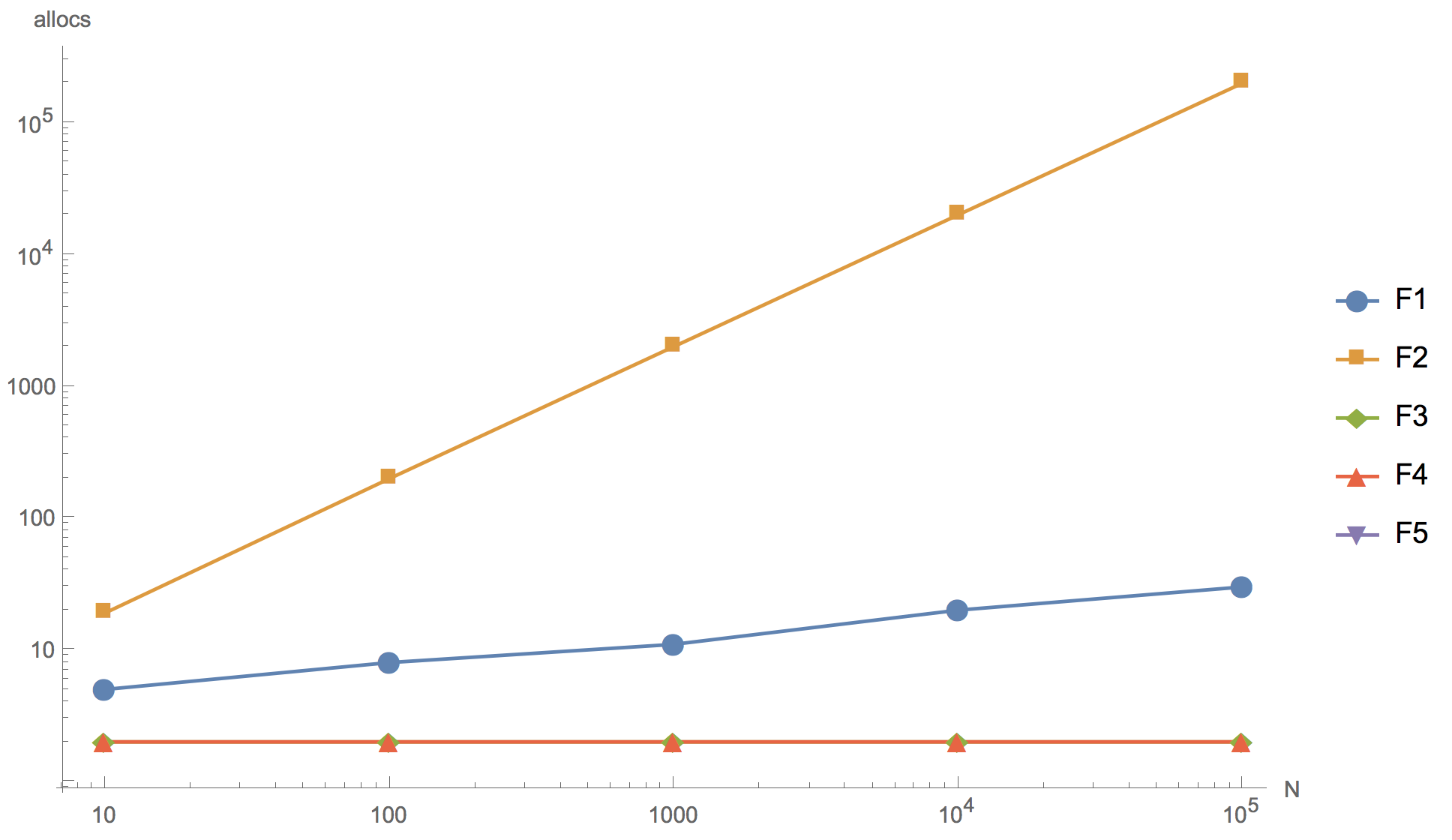
Comme vous pouvez le voir sur le graphique, vous pouvez augmenter le tableau, mais le résultat final se distingue déjà en principe sur une tranche de 10 éléments.
Aucun des algorithmes alternatifs proposés (F2, F3, F4) ne pouvait dépasser l'algorithme d'origine (F1) en vitesse. Même en dépit du fait que tous, sauf F2, ont moins d'allocations de mémoire que l'original. Le premier algorithme (F2) avec l'ajout d'un élément au début de la tranche s'est avéré le plus inefficace: comme prévu, il a trop d'allocations de mémoire, à tel point qu'il est absolument impossible de l'utiliser dans le développement de produits. Un algorithme utilisant la fonction de tri inverse intégrée (F3) est beaucoup plus lent que l'original. Et seulement l'
algorithme de tri
sort.Slice est comparable en vitesse à l'algorithme d'origine, mais il est légèrement inférieur.
Vous pouvez également remarquer que refuser le tri (F5) donne une accélération importante. Par conséquent, si vous voulez vraiment réécrire le code, vous pouvez aller dans cette direction, par exemple, en augmentant la tranche de
builds initiale de la base de données, utilisez le tri par id DESC au lieu de ASC dans la demande. Mais en même temps, nous sommes obligés d'aller au-delà des limites de la section de code considérée, ce qui comporte le risque d'introduire plusieurs changements.
Conclusions
Écrivez des repères.
Cela n'a pas de sens de passer votre temps à penser si un code particulier sera plus rapide. Les informations provenant d'Internet, les jugements de collègues et d'autres personnes, quelle que soit leur autorité, peuvent servir d'arguments auxiliaires, mais le rôle du juge en chef, décider s'il s'agit ou non d'un nouvel algorithme, devrait rester avec les références.
Go est, à première vue, un langage assez simple. La règle complète des 80⁄20 s'applique ici. Ces 20% représentent les subtilités de la structure interne de la langue, dont la connaissance distingue le novice du développeur expérimenté. La pratique de la rédaction de repères pour résoudre vos questions est l'un des moyens les moins chers et les plus efficaces d'obtenir à la fois une réponse et une compréhension plus approfondie de la structure interne et des principes du langage Go.