
Note du traducteur
La plupart des logiciels modernes ne sont pas monolithiques, mais se composent de nombreuses parties qui interagissent les unes avec les autres. Dans cette situation, il est nécessaire que la communication des parties interactives du système ait lieu dans un seul langage (malgré le fait que ces parties elles-mêmes peuvent être écrites dans différents langages de programmation et s'exécuter sur différentes machines). Pour simplifier la solution à ce problème, aide gRPC - open-source-framework de Google, publié en 2015. Il résout immédiatement un certain nombre de problèmes, permettant:
- utiliser le langage Protocol Buffers pour décrire l'interaction des services;
- générer un code de programme basé sur le protocole décrit pour 11 langues différentes à la fois pour la partie client et la partie serveur;
- mettre en œuvre l'autorisation entre les composants en interaction;
- utiliser à la fois une interaction synchrone et asynchrone.
gRPC me semblait être un cadre assez intéressant, et j'étais intéressé à en savoir plus sur la véritable expérience de Dropbox dans la construction d'un système basé sur celui-ci. L'article contient de nombreux détails liés à l'utilisation du chiffrement, à la construction d'un système fiable, observable et productif, au processus de migration de l'ancienne solution RPC vers la nouvelle.
Clause de non-responsabilitéL'article d'origine ne contient pas de description de gRPC et certains points peuvent ne pas vous sembler clairs. Si vous n'êtes pas familier avec gRPC ou d'autres cadres similaires (par exemple, Apache Thrift), je vous recommande de vous familiariser d'abord avec les idées principales (il suffira de lire deux petits articles sur le site officiel:
"Qu'est-ce que gRPC?" Et
"Concepts gRPC" ).
Merci à Aleksey Ivanov alias
SaveTheRbtz pour avoir écrit l'article original et aidé à traduire les endroits difficiles.
Dropbox gère de nombreux services écrits dans différentes langues et traitant des millions de demandes par seconde. Au cœur de notre architecture orientée services se trouve Courier, une infrastructure RPC basée sur gPC. Au cours de son développement, nous avons beaucoup appris sur l'extensibilité de gRPC, l'optimisation des performances et la transition du système RPC précédent.
Remarque: la publication contient des extraits de code pour Python et Go. Nous utilisons également Rust et Java.Route vers gRPC
Courier n'est pas le premier framework Dropbox RPC. Avant même de commencer à diviser le système Python monolithique en services séparés, nous avions besoin d'une base fiable pour échanger des données entre services - d'autant plus que le choix d'un cadre aurait des conséquences à long terme.
Avant cela, Dropbox a expérimenté différents cadres RPC. Tout d'abord, nous avions un protocole individuel pour la sérialisation et la désérialisation manuelles. Certains services, tels que la
journalisation basée sur Scribe , utilisaient
Apache Thrift . En même temps, notre infrastructure RPC principale était un protocole HTTP / 1.1 avec des messages sérialisés en utilisant Protobuf.
Création d'un cadre, nous avons choisi parmi plusieurs options. Nous pourrions introduire Swagger (maintenant connu sous le nom d'
OpenAPI ) dans l'ancien framework RPC,
introduire un nouveau standard ou construire un framework basé sur Thrift ou gRPC. Le principal argument en faveur de gRPC était la possibilité d'utiliser des protobufs préexistants. De plus, le multiplexage HTTP / 2 et le transfert de données bidirectionnel ont été utiles pour nos tâches.
Remarque: si fbthrift existait à ce moment, nous examinerions probablement de plus près les solutions Thrift.Ce que Courier apporte à gRPC
Courier n'est pas un protocole RPC; c'est un moyen d'intégrer gRPC dans une infrastructure existante. Le cadre était censé être compatible avec nos outils d'authentification, d'autorisation et de découverte de services, ainsi que la collecte, la journalisation et le suivi des statistiques. Nous avons donc créé Courier.
Bien que dans certains cas, nous utilisons Bandaid comme proxy gRPC, la plupart de nos services communiquent directement entre eux pour minimiser l'impact du RPC sur la latence.Il était important pour nous de réduire la quantité de code de routine qui doit être écrit. Étant donné que Courier sert de cadre général pour le développement de services, il contient des fonctionnalités dont tout le monde a besoin. La plupart d'entre eux sont activés par défaut et peuvent être contrôlés par des arguments de ligne de commande, et certains sont cochés avec une case à cocher.
Sécurité: identité de service et authentification mutuelle TLS
Courier met en œuvre notre mécanisme d'identification de service standard. Chaque serveur et client se voit attribuer un certificat TLS individuel délivré par notre propre autorité de certification. L'identifiant personnel codé par certificat, qui est utilisé pour l'authentification mutuelle - le serveur vérifie le client, le client vérifie le serveur.
Dans TLS, où nous contrôlons les deux côtés de la connexion, nous avons introduit des restrictions strictes. Tous les RPC internes nécessitent un cryptage
PFS . La version requise de TLS est 1.2 et supérieure. Nous avons également limité le nombre d'algorithmes symétriques et asymétriques, préférant
ECDHE-ECDSA-AES128-GCM-SHA256 .
Après avoir traversé l'identification et le déchiffrement de la demande, le serveur vérifie si le client dispose des autorisations nécessaires. Les listes de contrôle d'accès (ACL) et les limites de vitesse peuvent être configurées à la fois pour les services en général et pour les méthodes individuelles. Leurs paramètres peuvent également être modifiés via notre système de fichiers distribué (AFS). Grâce à cela, les propriétaires de services peuvent réduire la charge en quelques secondes, sans même redémarrer les processus. Courier se chargera de s'abonner aux notifications et de mettre à jour la configuration.
Le service d'identité est un identifiant global pour les listes de contrôle d'accès, les limites de vitesse, les statistiques, etc. De plus, il est cryptographiquement sécurisé.Voici un exemple de configuration ACL et de limite de vitesse utilisée dans notre
service de reconnaissance optique de formes :
limits: dropbox_engine_ocr: # All RPC methods. default: max_concurrency: 32 queue_timeout_ms: 1000 rate_acls: # OCR clients are unlimited. ocr: -1 # Nobody else gets to talk to us. authenticated: 0 unauthenticated: 0
 Nous envisageons la possibilité de passer au format SVID (document SPIFFE vérifié cryptographiquement), ce qui permettra de combiner notre framework avec de nombreux projets open source.
Nous envisageons la possibilité de passer au format SVID (document SPIFFE vérifié cryptographiquement), ce qui permettra de combiner notre framework avec de nombreux projets open source.Observabilité: statistiques et suivi
Avec un seul identifiant, vous pouvez facilement trouver des journaux, des statistiques, des fichiers de trace et d'autres données sur Courier.
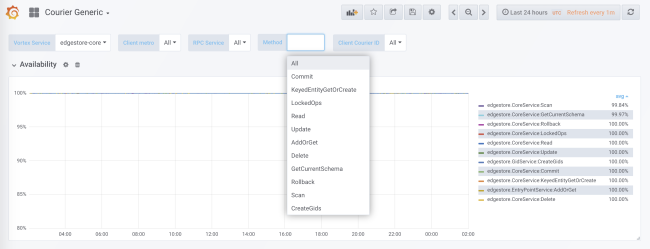
Lors de la génération de code, une collecte de statistiques est ajoutée pour chaque service et chaque méthode à la fois côté client et côté serveur. Les statistiques côté serveur sont divisées par ID client. Dans la configuration standard, vous recevrez des données détaillées sur la charge, les erreurs et le temps de retard pour chaque service utilisant Courier.
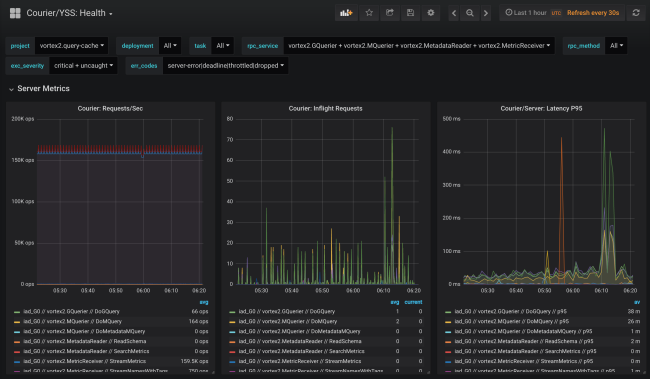
Les statistiques Courier incluent des données sur la disponibilité et la latence côté client, ainsi que sur le nombre de demandes et la taille de la file d'attente côté serveur. Il existe d'autres graphiques utiles, en particulier des histogrammes du temps de réponse pour chaque méthode et le temps des prises de contact TLS pour chaque client.
L'un des avantages de notre génération de code est la possibilité d'initialisation statique des structures de données, telles que les histogrammes et les graphiques de trace. Cela minimise l'impact sur les performances.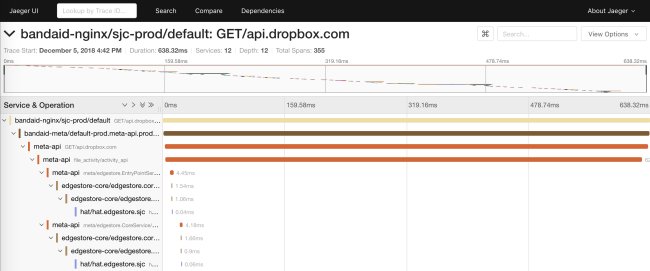
L'ancien système RPC distribuait uniquement
request_id sur l'API. Cela a permis de combiner les données des journaux de différents services. Chez Courier, nous avons introduit une API basée sur un sous-ensemble des spécifications
OpenTracing . Nous avons écrit nos propres bibliothèques côté client, et côté serveur nous avons implémenté une solution basée sur Cassandra et
Jaeger .

Le traçage nous permet de générer des diagrammes de dépendance d'un service lors de l'exécution. Cela aide les ingénieurs à voir toutes les dépendances transitives d'un service particulier. De plus, la fonction est utile pour suivre les dépendances indésirables après le déploiement.
Fiabilité: délais et déconnexion
Courier fournit un emplacement central pour implémenter les fonctions client courantes (par exemple, les délais d'attente) dans différentes langues. Nous avons progressivement ajouté diverses fonctionnalités, souvent basées sur les résultats d'une analyse «posthume» des problèmes émergents.
Délais
Chaque demande gRPC a un délai indiquant le délai d'expiration du client. Comme les talons Courier distribuent automatiquement les métadonnées connues, le délai de demande est même transféré en dehors de l'API. Dans le processus, les délais reçoivent un affichage natif. Par exemple, dans Go, ils sont représentés par le résultat de
context.Context de la méthode
WithDeadline .
En fait, nous avons pu résoudre des classes entières de problèmes de fiabilité en obligeant les ingénieurs à fixer des délais pour définir les services appropriés.
Cette approche va même au-delà du RPC. Par exemple, notre ORM MySQL sérialise un contexte RPC avec une échéance dans un commentaire de requête SQL. Notre proxy SQL peut analyser les commentaires et «tuer» les requêtes lorsque la date limite se produit. Et en prime lors du débogage des appels de base de données, nous avons une requête SQL liée à une requête RPC spécifique.
Déconnecter
Un autre problème courant rencontré par les clients du système RPC précédent était la mise en œuvre de l'algorithme du retard exponentiel individuel et des fluctuations sur demande répétée.
Nous avons essayé de trouver une solution intelligente au problème de déconnexion dans Courier, en commençant par l'implémentation du tampon LIFO (dernier entré, premier sorti) entre le service et le pool de tâches.
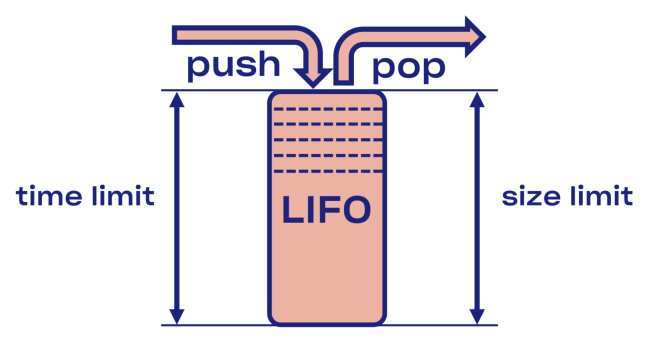
En cas de surcharge, LIFO se déconnecte automatiquement. La file d'attente, qui est importante, est limitée non seulement par la taille, mais aussi
par le temps (la demande ne peut passer dans la file d'attente qu'un certain temps).
Moins LIFO - modification de l'ordre de traitement des demandes. Si vous souhaitez conserver la commande d'origine, utilisez CoDel . Là aussi, il y a la possibilité de se déconnecter, et l'ordre de traitement des demandes restera le même.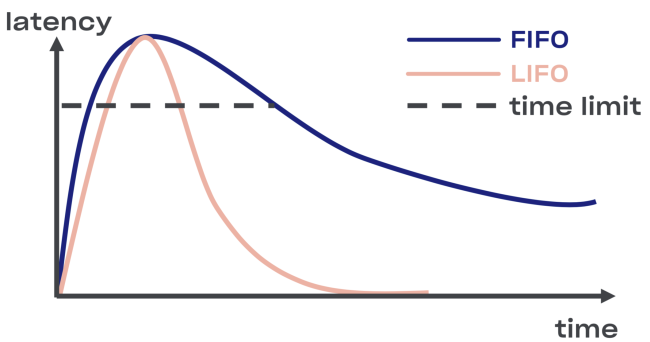
Introspection: débogage des points de terminaison
Bien que les points de terminaison de débogage ne fassent pas directement partie de Courier, ils sont largement utilisés dans Dropbox et sont trop utiles pour ne pas être mentionnés.
Pour des raisons de sécurité, vous pouvez les ouvrir sur un port séparé ou sur un socket Unix (pour contrôler l'accès à l'aide des autorisations de fichier). Vous devez également envisager l'authentification TLS mutuelle, avec laquelle les développeurs devront fournir leurs certificats pour accéder aux points de terminaison (principalement non seulement en lecture seule).Exécution
La possibilité d'analyser l'état d'un service pendant son fonctionnement est très utile pour le débogage. Par exemple,
la mémoire dynamique et les profils CPU sont accessibles via des points de terminaison HTTP ou gRPC .
Nous prévoyons d'utiliser cette opportunité dans la procédure de vérification canarienne - pour automatiser la recherche de la différence entre les anciennes et les nouvelles versions du code.Les noeuds finaux permettent de modifier l'état d'un service lors de l'exécution. En particulier, les services basés sur Golang peuvent configurer dynamiquement
GCPercent .
La bibliothèque
L'exportation automatique de données spécifiques à la bibliothèque en tant que point de terminaison RPC peut être utile pour les développeurs de bibliothèque. Par exemple, la bibliothèque
malloc peut transférer des statistiques internes dans un vidage . Autre exemple: un point de terminaison de débogage peut modifier le niveau de journalisation du service à la volée.
Rpc
Bien sûr, le dépannage dans les protocoles cryptés et codés n'est pas facile. Par conséquent, introduire autant d'outils que possible au niveau RPC est une bonne idée. Un exemple d'une telle API introspective
est la solution Channelz .
Niveau d'application
La possibilité d'apprendre les options au niveau de l'application peut également être utile. Un bon exemple est un point de terminaison avec des informations générales sur l'application (avec un hachage de fichiers source ou d'assembly, une ligne de commande, etc.). Il peut être utilisé par un système d'orchestration pour vérifier l'intégrité lors du déploiement d'un service.
Optimisation des performances
En étendant notre infrastructure gRPC à l'échelle requise, nous avons trouvé plusieurs goulots d'étranglement spécifiques à Dropbox.
Consommation de ressources des poignées de main TLS
Dans les services qui servent de nombreuses relations, à la suite des négociations TLS, la charge CPU combinée peut être assez grave (en particulier lors du redémarrage d'un service populaire).
Afin d'améliorer les performances lors de la signature, nous avons remplacé les paires de clés RSA-2048 par l'ECDSA P-256. Voici des exemples de leurs performances (remarque: avec RSA, la vérification de signature est plus rapide).
RSA: ~/c0d3/boringssl bazel run -- //:bssl speed -filter 'RSA 2048' Did ... RSA 2048 signing operations in .............. (1527.9 ops/sec) Did ... RSA 2048 verify (same key) operations in .... (37066.4 ops/sec) Did ... RSA 2048 verify (fresh key) operations in ... (25887.6 ops/sec)
ECDSA: ~/c0d3/boringssl bazel run -- //:bssl speed -filter 'ECDSA P-256' Did ... ECDSA P-256 signing operations in ... (40410.9 ops/sec) Did ... ECDSA P-256 verify operations in .... (17037.5 ops/sec)
Étant donné que la vérification avec RSA-2048 est environ trois fois plus rapide qu'avec ECDSA P-256, vous pouvez choisir RSA pour les certificats racine et de fin afin d'augmenter la vitesse de fonctionnement. Mais du point de vue de la sécurité, tout n'est pas aussi simple: vous construirez des chaînes de différentes primitives cryptographiques, et donc, le niveau des paramètres de sécurité résultants sera le plus bas. Et si vous souhaitez améliorer les performances, nous vous déconseillons d'utiliser des certificats de la version RSA-4096 (et supérieure) en tant que certificats racine et de fin.
Nous avons également constaté que le choix d'une bibliothèque TLS (et d'indicateurs de compilation) a un impact significatif sur les performances et la sécurité. Comparez, par exemple, la version LibreSSL sur macOS X Mojave avec OpenSSL auto-écrit sur le même matériel.
LibreSSL 2.6.4: ~ openssl speed rsa2048 LibreSSL 2.6.4 ... sign verify sign/s verify/s rsa 2048 bits 0.032491s 0.001505s 30.8 664.3
OpenSSL 1.1.1a: ~ openssl speed rsa2048 OpenSSL 1.1.1a 20 Nov 2018 ... sign verify sign/s verify/s rsa 2048 bits 0.000992s 0.000029s 1208.0 34454.8
Cependant, le moyen le plus rapide de créer une négociation TLS est de ne pas la créer du tout! Nous avons inclus la prise en charge de la reprise de session dans gRPC-core et gRPC-python, réduisant ainsi la charge sur le processeur pendant le déploiement.
Le chiffrement est peu coûteux
Beaucoup pensent à tort que le chiffrement coûte cher. En fait, même les ordinateurs modernes les plus simples effectuent un chiffrement symétrique presque instantanément. Un processeur standard est capable de crypter et d'authentifier les données à une vitesse de 40 Gb / s par cœur:
~/c0d3/boringssl bazel run -- //:bssl speed -filter 'AES' Did ... AES-128-GCM (8192 bytes) seal operations in ... 4534.4 MB/s
Néanmoins, nous devions encore configurer gRPC pour nos blocs de mémoire, fonctionnant à une vitesse de 50 Gb / s. Nous avons constaté que si la vitesse de chiffrement est approximativement égale à la vitesse de copie, il est important de minimiser le nombre d'opérations de
mémcpy. De plus, nous avons apporté quelques modifications au gRPC lui-même.
Les protocoles authentifiés et chiffrés ont évité de nombreux problèmes désagréables (par exemple, la corruption de données par le processeur, DMA ou sur le réseau). Même si vous n'utilisez pas gRPC, nous vous recommandons d'utiliser TLS pour les contacts internes.Canaux de données à haute latence (BDP)
Note du traducteur: le sous-titre original utilisait le terme
produit retardateur de bande passante , qui n'a pas de traduction établie en russe.
Le réseau fédérateur Dropbox comprend de nombreux centres de données . Parfois, les nœuds situés dans différentes régions doivent communiquer via RPC, par exemple, pour la réplication. Lors de l'utilisation de TCP, le noyau du système est responsable de limiter la quantité de données transmises dans une connexion particulière (dans /
proc / sys / net / ipv4 / tcp_ {r, w} mem ), bien que gRPC basé sur HTTP / 2 ait son propre outil contrôle du débit. La limite supérieure de BDP
dans grpc-go est strictement limitée à 16 Mo , ce qui peut déclencher un goulot d'étranglement.
net.Server Golang ou grpc.Server
Initialement, dans notre code Go, nous prenions en charge HTTP / 1.1 et gRPC avec un seul
net.Server . La solution avait un sens en termes de maintien du code du programme, mais cela ne fonctionnait pas du tout parfaitement. La distribution de HTTP / 1.1 et gRPC sur les serveurs et la migration de gRPC vers grpc.Server ont considérablement amélioré la bande passante Courier et l'utilisation de la mémoire.
golang / protobuf ou gogo / protobuf
Le passage à gRPC peut augmenter le coût du marshaling et du démarshaling. Pour le code Go, nous avons pu réduire considérablement la charge CPU sur les serveurs Courier en passant à
gogo / protobuf .
Comme toujours, la transition vers gogo / protobuf s'est accompagnée de quelques inquiétudes , mais si vous limitez raisonnablement la fonctionnalité, il ne devrait y avoir aucun problème.Détails d'implémentation
Dans cette section, nous allons approfondir le dispositif Courier, examiner les schémas de protobuf et des exemples de talons de différentes langues. Tous les exemples sont tirés du service Test, que nous avons utilisé lors des tests d'intégration de Courier.
Description du service
Jetez un œil à un extrait de la définition du service de test:
service Test { option (rpc_core.service_default_deadline_ms) = 1000; rpc UnaryUnary(TestRequest) returns (TestResponse) { option (rpc_core.method_default_deadline_ms) = 5000; } rpc UnaryStream(TestRequest) returns (stream TestResponse) { option (rpc_core.method_no_deadline) = true; } ... }
Comme indiqué ci-dessus, un délai est requis pour toutes les méthodes de messagerie. En utilisant l'option suivante, vous pouvez définir la date limite pour l'ensemble du service:
option (rpc_core.service_default_deadline_ms) = 1000;
Dans le même temps, chaque méthode peut être définie à sa propre échéance, annulant l'échéance de l'ensemble du service (le cas échéant):
option (rpc_core.method_default_deadline_ms) = 5000;
Dans de rares cas où la date limite n'a pas de sens (par exemple, lors du suivi d'une ressource), le développeur peut la désactiver:
option (rpc_core.method_no_deadline) = true;
En plus de cela, la description du service doit contenir une documentation API détaillée, éventuellement avec des exemples d'utilisation.
Génération de talon
Pour offrir une plus grande flexibilité, Courier génère ses propres stubs sans compter sur la fonctionnalité d'intercepteur fournie par gRPC (à l'exception de Java, dans lequel l'API d'intercepteur a une puissance suffisante). Comparons nos talons avec les talons Golang standard.
Voici à quoi ressemblent les stubs de serveur gRPC par défaut:
func _Test_UnaryUnary_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) { in := new(TestRequest) if err := dec(in); err != nil { return nil, err } if interceptor == nil { return srv.(TestServer).UnaryUnary(ctx, in) } info := &grpc.UnaryServerInfo{ Server: srv, FullMethod: "/test.Test/UnaryUnary", } handler := func(ctx context.Context, req interface{}) (interface{}, error) { return srv.(TestServer).UnaryUnary(ctx, req.(*TestRequest)) } return interceptor(ctx, in, info, handler) }
Tout le traitement se déroule à l'intérieur: décodage du protobuf, lancement des intercepteurs (voir la variable
interceptor dans le code), lancement du gestionnaire UnaryUnary.
Jetez maintenant un œil aux talons Courier:
func _Test_UnaryUnary_dbxHandler( srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) ( interface{}, error) { defer processor.PanicHandler() impl := srv.(*dbxTestServerImpl) metadata := impl.testUnaryUnaryMetadata ctx = metadata.SetupContext(ctx) clientId = client_info.ClientId(ctx) stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId) stats.TotalCount.Inc() req := &processor.UnaryUnaryRequest{ Srv: srv, Ctx: ctx, Dec: dec, Interceptor: interceptor, RpcStats: stats, Metadata: metadata, FullMethodPath: "/test.Test/UnaryUnary", Req: &test.TestRequest{}, Handler: impl._UnaryUnary_internalHandler, ClientId: clientId, EnqueueTime: time.Now(), } metadata.WorkPool.Process(req).Wait() return req.Resp, req.Err }
Il y a pas mal de code ici, alors analysons-le.
Tout d'abord, nous reportons l'appel au gestionnaire de panique, qui est responsable de la collecte automatique des erreurs. Cela nous permettra de collecter toutes les exceptions non interceptées dans le référentiel central pour l'agrégation et les rapports ultérieurs:
defer processor.PanicHandler()
Une autre raison pour laquelle nous exécutons notre propre gestionnaire de panique est de s'assurer que l'application se bloque en cas d'erreur. Dans ce cas, le gestionnaire HTTP golang / net standard ignorera le problème et continuera à traiter les nouvelles demandes (même endommagées et incohérentes).
Ensuite, nous transmettons le contexte, redéfinissant les valeurs en fonction des métadonnées de la demande entrante:
ctx = metadata.SetupContext(ctx) clientId = client_info.ClientId(ctx)
Nous créons également (et cache pour plus d'efficacité) des statistiques client côté serveur pour une agrégation plus détaillée:
stats := metadata.StatsMap.GetOrCreatePerClientStats(clientId)
Cette ligne crée des statistiques pour chaque client (c'est-à-dire un identifiant TLS) pendant l'exécution. Nous avons également des statistiques sur toutes les méthodes pour chaque service. Puisque le générateur de stub a accès à toutes les méthodes pendant la génération de code, nous pouvons les créer statiquement à l'avance, évitant ainsi de ralentir le programme.
Après cela, nous créons une structure de demande, la transférons dans le pool de tâches et attendons l'exécution:
req := &processor.UnaryUnaryRequest{ Srv: srv, Ctx: ctx, Dec: dec, Interceptor: interceptor, RpcStats: stats, Metadata: metadata, ... } metadata.WorkPool.Process(req).Wait()
Veuillez noter qu'à ce stade, nous n'avons pas décodé le protobuf, ni lancé l'intercepteur. Avant cela, le pool d'accès, la priorisation et la limitation du nombre de requêtes exécutées doivent passer par le pool de tâches.
Notez que la bibliothèque gRPC prend en charge l'interface TAP, ce qui vous permet d'intercepter les demandes à une vitesse incroyable. L'interface fournit l'infrastructure pour la construction de limiteurs de vitesse efficaces avec une consommation de ressources minimale.Codes d'erreur spécifiques pour différentes applications
Notre générateur de stub permet également aux développeurs d'attribuer des codes d'erreur spécifiques à l'application à l'aide d'options spéciales:
enum ErrorCode { option (rpc_core.rpc_error) = true; UNKNOWN = 0; NOT_FOUND = 1 [(rpc_core.grpc_code)="NOT_FOUND"]; ALREADY_EXISTS = 2 [(rpc_core.grpc_code)="ALREADY_EXISTS"]; ... STALE_READ = 7 [(rpc_core.grpc_code)="UNAVAILABLE"]; SHUTTING_DOWN = 8 [(rpc_core.grpc_code)="CANCELLED"]; }
Les erreurs gRPC et d'application se propagent au sein du service, et à la frontière de l'API, toutes les erreurs sont remplacées par UNKNOWN. Grâce à cela, nous pouvons éviter de transférer le problème vers d'autres services, ce qui peut entraîner un changement dans leur sémantique.
Modifications de Python
Les stubs Python ajoutent un paramètre de contexte explicite à tous les gestionnaires Courier:
from dropbox.context import Context from dropbox.proto.test.service_pb2 import ( TestRequest, TestResponse, ) from typing_extensions import Protocol class TestCourierClient(Protocol): def UnaryUnary( self, ctx, # type: Context request, # type: TestRequest ):
Au début, cela avait l'air bizarre, mais au fil du temps, les développeurs se sont habitués au
ctx explicite comme ils le faisaient auparavant.
Veuillez noter que nos talons sont entièrement tapés pour
mypy , qui est compensé lors d'une refactorisation majeure. De plus, l'intégration avec certains IDE (par exemple PyCharm) est simplifiée.
En continuant à suivre la tendance du typage statique, nous ajoutons des annotations mypy aux protocoles eux-mêmes:
class TestMessage(Message): field: int def __init__(self, field : Optional[int] = ..., ) -> None: ... @staticmethod def FromString(s: bytes) -> TestMessage: ...
Ces annotations éviteront de nombreux bogues courants, tels que l'attribution d'une valeur de
None à un champ de type
chaîne , par exemple
.Ce code
est disponible ici .
Processus de migration
La création d'une nouvelle pile RPC n'est pas une tâche facile, mais elle ne se situe même pas à côté du processus de transition complète vers celle-ci, si vous regardez du point de vue de la complexité de fonctionnement. Par conséquent, nous avons essayé de rendre aussi facile que possible pour les développeurs de passer de l'ancien RPC à Courier. La migration étant souvent accompagnée d'erreurs, nous avons décidé de l'implémenter par étapes.
Étape 0: geler l'ancien RPC
Tout d'abord, nous avons figé l'ancien RPC pour ne pas tirer sur une cible en mouvement. Cela a également incité les gens à passer à Courier, car toutes les nouvelles fonctionnalités telles que le traçage n'étaient disponibles que dans les services sur Courier.
Étape 1: interface commune pour les anciens RPC et Courier
Nous avons commencé par définir une interface commune pour les anciens RPC et Courier. Notre génération de code était censée garantir que les deux versions des stubs correspondaient à cette interface:
type TestServer interface { UnaryUnary( ctx context.Context, req *test.TestRequest) ( *test.TestResponse, error) ... }
Étape 2: migrer vers la nouvelle interface
Après cela, nous avons commencé à basculer chaque service vers une nouvelle interface, tout en continuant à utiliser l'ancien RPC. Souvent, les changements de code étaient une énorme différence, affectant toutes les méthodes du service et ses clients. Cette étape étant la plus problématique, nous avons voulu éliminer complètement le risque en ne changeant qu'une chose à la fois.
Des services simples avec un petit nombre de méthodes et le droit de faire des erreurs peuvent être migrés simultanément, sans prêter attention à nos avertissements.Étape 3: migrer les clients vers RPC Courier
Au cours du processus de migration, nous avons commencé à lancer simultanément des serveurs anciens et nouveaux sur différents ports de la même machine. La commutation de l'implémentation RPC côté client a été effectuée en changeant une ligne:
class MyClient(object): def __init__(self): - self.client = LegacyRPCClient('myservice') + self.client = CourierRPCClient('myservice')
Veuillez noter qu'avec ce modèle, vous pouvez transférer un client à la fois, en commençant par ceux qui ont un niveau de SLA inférieur.
Étape 4: nettoyage
, , RPC ( ). — .
Conclusions
, Courier — RPC-, , Dropbox.
, Courier:
- — . .
- — , .
- , . Codegen.
- . , , . , : .
- RPC- — , . . .
Courier, gRPC , , , .
gRPC Python , C++ Python Rust . ALTS TLS- (, ).