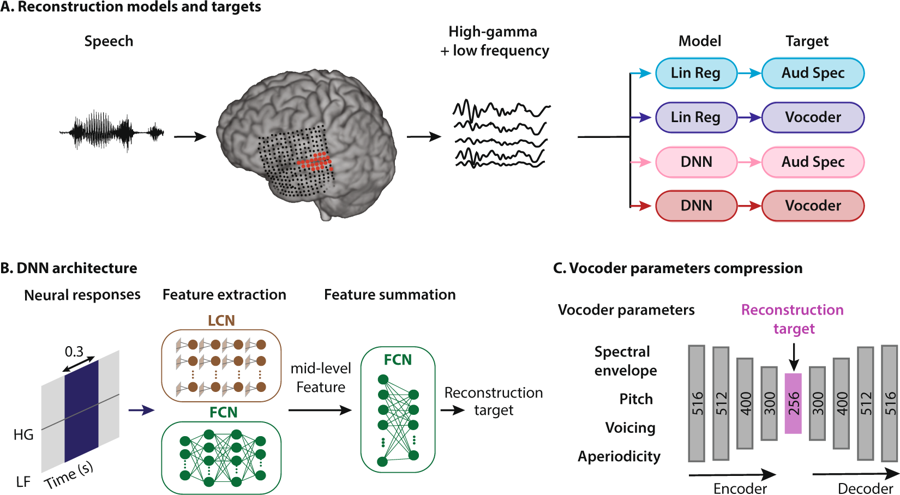
 Schéma de la méthode de reconstruction de la parole. Une personne écoute les mots, en conséquence, les neurones de son cortex auditif sont activés. Les données sont interprétées de quatre manières: en combinant deux types de modèles de régression et deux types de représentations vocales, elles pénètrent ensuite dans le système de réseau neuronal pour extraire des caractéristiques qui sont ensuite utilisées pour configurer les paramètres du vocodeur
Schéma de la méthode de reconstruction de la parole. Une personne écoute les mots, en conséquence, les neurones de son cortex auditif sont activés. Les données sont interprétées de quatre manières: en combinant deux types de modèles de régression et deux types de représentations vocales, elles pénètrent ensuite dans le système de réseau neuronal pour extraire des caractéristiques qui sont ensuite utilisées pour configurer les paramètres du vocodeurLes neuroingénieurs de la Columbia University (USA) ont été les premiers au monde à
créer un système qui traduit les pensées humaines en un discours compréhensible et reconnaissable, voici l'
enregistrement sonore de mots (mp3) synthétisés par l'activité cérébrale.
En observant l'activité dans le cortex auditif, le système restaure les mots qu'une personne entend avec une clarté sans précédent. Bien sûr, ce n'est pas la notation des pensées au sens littéral du terme, mais un pas important a été franchi dans cette direction. En effet, des schémas similaires d'activité cérébrale se produisent dans le cortex cérébral lorsqu'une personne s'imagine écouter la parole ou lorsqu'elle prononce mentalement des mots.
Cette percée scientifique utilisant les technologies de l'intelligence artificielle nous rapproche de la création d'interfaces neuronales efficaces qui connectent l'ordinateur directement au cerveau. Il aidera également les personnes qui ne peuvent pas parler et celles qui se remettent d'un AVC ou pour une autre raison qui sont temporairement ou constamment incapables de prononcer des mots à communiquer.
Des décennies de recherche ont prouvé que, dans le processus de parler ou même de parler mentalement, des modèles d'activité de contrôle apparaissent dans le cerveau. De plus, un modèle de signal distinct (et reconnaissable) apparaît lorsque nous écoutons quelqu'un ou imaginons que nous écoutons. Les experts tentent depuis longtemps d'enregistrer et de déchiffrer ces schémas afin de «libérer» les pensées d'une personne du crâne - et de les traduire automatiquement sous forme orale.
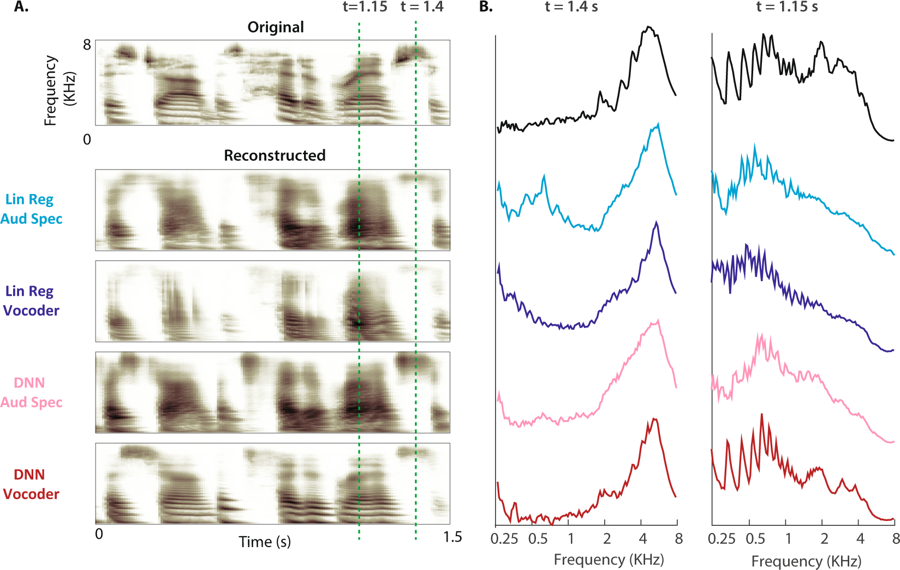 (A) Le spectrogramme original d'un échantillon de parole est illustré ci-dessus. Les spectrogrammes auditifs reconstruits des quatre modèles sont présentés ci-dessous. (B) La puissance de magnitude des bandes de fréquences pendant la parole non voisée (t = 1,4 s) et vocale (t = 1,15 s: l'écart est indiqué par des lignes en pointillés pour le spectrogramme original et quatre reconstructions)
(A) Le spectrogramme original d'un échantillon de parole est illustré ci-dessus. Les spectrogrammes auditifs reconstruits des quatre modèles sont présentés ci-dessous. (B) La puissance de magnitude des bandes de fréquences pendant la parole non voisée (t = 1,4 s) et vocale (t = 1,15 s: l'écart est indiqué par des lignes en pointillés pour le spectrogramme original et quatre reconstructions)«Il s'agit de la même technologie qu'Amazon Echo et Apple Siri utilisent pour répondre verbalement à nos questions»,
explique le Dr Nima Mesgarani, auteur principal du document. Pour apprendre au vocodeur à interpréter l'activité cérébrale, les experts ont trouvé cinq patients atteints d'épilepsie qui avaient déjà subi une chirurgie cérébrale. On leur a demandé d'écouter des phrases faites par différentes personnes, tandis que les électrodes mesuraient l'activité cérébrale, qui était traitée par quatre modèles. Ces modèles neuronaux ont enseigné le vocodeur. Les chercheurs ont ensuite demandé aux mêmes patients d'écouter comment les locuteurs prononcent des nombres de 0 à 9, enregistrant les signaux cérébraux qui pouvaient être transmis par le vocodeur. Le son produit par le vocodeur en réponse à ces signaux est analysé et éliminé par plusieurs réseaux de neurones.
À la suite du traitement à la sortie du réseau neuronal, une voix de robot a été reçue qui a prononcé une séquence de nombres. Pour tester la précision de la reconnaissance, les gens ont eu la possibilité d'écouter des sons synthétisés par leur propre activité cérébrale: «Nous avons constaté que les gens peuvent comprendre et répéter les sons dans 75% des cas, ce qui est beaucoup plus élevé et dépasse toutes les tentatives précédentes», a déclaré le Dr Mesgarani.
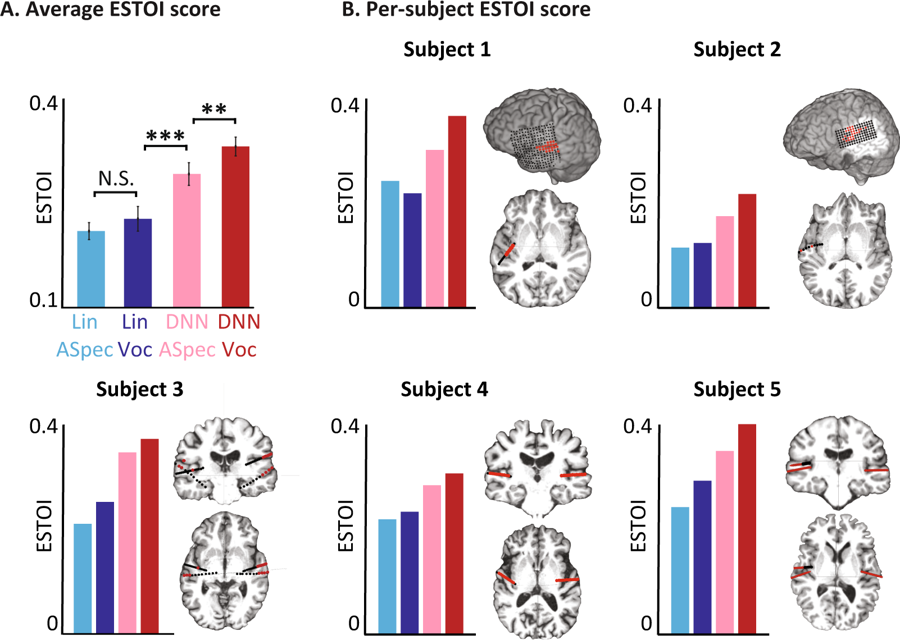 Cotes objectives pour différents modèles. (A) Score ESTOI moyen pour tous les sujets pour les quatre modèles. B) La couverture et l'emplacement des électrodes et le score ESTOI pour chacune des cinq personnes. Tout le monde a un score ESTOI plus élevé pour le vocodeur DNN que les autres modèles.
Cotes objectives pour différents modèles. (A) Score ESTOI moyen pour tous les sujets pour les quatre modèles. B) La couverture et l'emplacement des électrodes et le score ESTOI pour chacune des cinq personnes. Tout le monde a un score ESTOI plus élevé pour le vocodeur DNN que les autres modèles.Maintenant, les scientifiques prévoient de répéter l'expérience avec des mots et des phrases plus complexes. En outre, les mêmes tests seront exécutés pour les signaux du cerveau lorsqu'une personne imagine ce qu'il dit. En fin de compte, ils espèrent que le système fera partie de l'implant, ce qui traduira les pensées du porteur directement en mots.
L'article scientifique a été
publié le 29 janvier 2019 dans le domaine public dans la revue
Scientific Reports (doi: 10.1038 / s41598-018-37359-z).
Le code du programme permettant d'effectuer une analyse phonémique, de calculer des amplitudes à haute fréquence et de reconstruire un spectrogramme auditif a été rendu
public .