Dans cet article, je veux parler de la façon dont nous avons créé un système de recherche de vêtements similaires (plus précisément des vêtements, des chaussures et des sacs) à partir de photographies. Il s'agit, en termes commerciaux, d'un service de recommandation basé sur des réseaux de neurones.
Comme la plupart des solutions informatiques modernes, nous pouvons comparer le développement de notre système avec l'ensemble constructeur Lego, lorsque nous prenons beaucoup de petits détails, des instructions et créons un modèle prêt à l'emploi à partir de cela. Voici une telle instruction: quels détails prendre et comment les appliquer pour que votre GPU puisse sélectionner des produits similaires sur une photo, vous trouverez dans cet article.
De quelles parties est construit notre système:
- détecteur et classificateur de vêtements, chaussures et sacs sur images;
- robot, indexeur ou module pour travailler avec des catalogues électroniques de magasins;
- module de recherche d'images similaires;
- API JSON pour une interaction pratique avec n'importe quel appareil et service;
- interface Web ou application mobile pour afficher les résultats.
À la fin de l'article, nous décrirons tous les «râteaux» sur lesquels nous avons marché pendant le développement et des recommandations sur la façon de les neutraliser.
Énoncé du problème et création de la rubrique
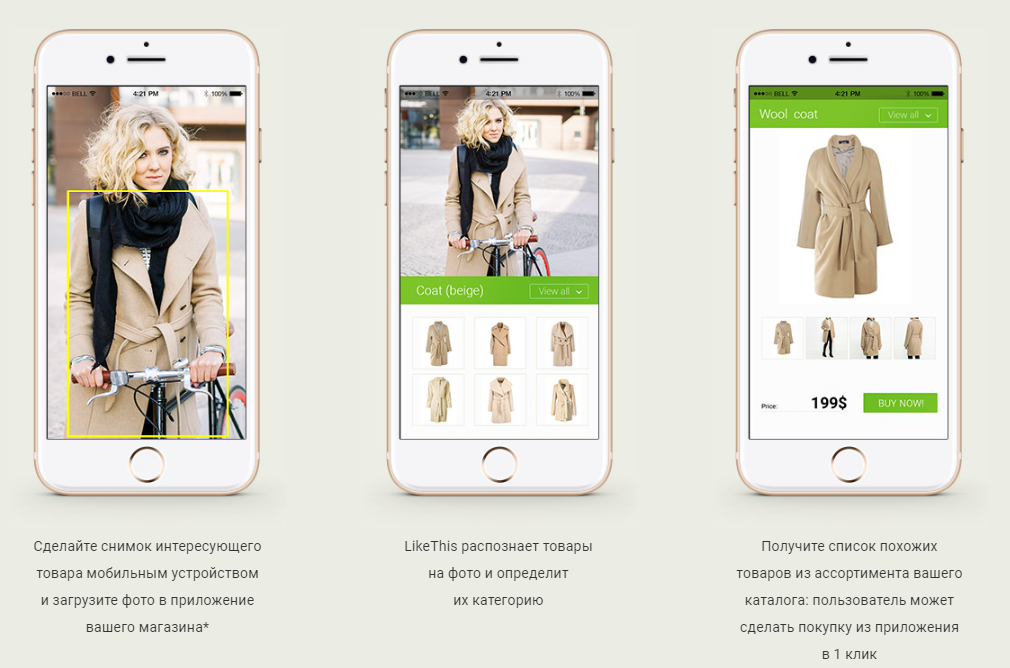
La tâche et le principal cas d'utilisation du système semblent assez simples et clairs:
- l'utilisateur soumet à l'entrée (par exemple via une application mobile) une photographie dans laquelle se trouvent des vêtements et / ou des sacs et / ou des chaussures;
- le système détermine (détecte) tous ces objets;
- trouve à chacun d'eux les produits les plus similaires (pertinents) dans de véritables boutiques en ligne;
- donne aux produits utilisateur la possibilité d'accéder à une page de produit spécifique pour achat.
En termes simples, l'objectif de notre système est de répondre à la fameuse question: "Et vous n'avez pas la même chose, uniquement avec des boutons en nacre?"
Avant de vous précipiter dans le pool de codage, de balisage et de formation des réseaux de neurones, vous devez déterminer assez clairement les catégories qui seront à l'intérieur de votre système, c'est-à-dire les catégories que le réseau de neurones détectera. Il est important de comprendre que plus la liste des catégories est large et détaillée, plus elle est universelle, car un grand nombre de petites catégories étroites telles que la mini-robe, la robe midi, la maxi-robe peuvent toujours être combinées avec une seule touche dans une catégorie de type robe MAIS PAS vice versa. En d'autres termes, le rubricator doit être bien pensé et compilé au tout début du projet, afin de ne pas refaire le même travail 3 fois plus tard. Nous avons compilé le rubricator, en prenant comme base plusieurs grands magasins, tels que Lamoda.ru, Amazon.com, et avons essayé de le rendre aussi large que possible d'une part, et aussi polyvalent que possible, d'autre part, de sorte qu'il serait plus facile d'associer des catégories de détecteurs à différentes catégories à l'avenir boutiques en ligne (je vais vous en dire plus sur la façon de créer ce groupe dans la section des robots et des indexeurs). Voici un exemple de ce qui s'est passé.
 Exemples de catégories
Exemples de catégoriesDans notre catalogue, il n'y a actuellement que 205 catégories: vêtements pour femmes, vêtements pour hommes, chaussures pour femmes, chaussures pour hommes, sacs, vêtements pour nouveau-nés. La version complète de notre classificateur est disponible
sur le lien .
Indexeur ou module pour travailler avec des catalogues électroniques de magasins
Afin de rechercher des produits similaires à l'avenir, nous devons créer une base étendue de ce que nous recherchons. D'après notre expérience, la qualité de la recherche d'images similaires dépend directement de la taille de la base de recherche, qui doit dépasser au moins 100 000 images, et de préférence 1 million d'images. Si vous ajoutez 1-2 petites boutiques en ligne à la base de données, vous n'obtiendrez probablement pas de résultats impressionnants simplement parce que dans 80% des cas, il n'y a rien de vraiment similaire à l'article souhaité dans votre catalogue.
Donc, pour créer une grande base de données d'images dont vous avez besoin pour traiter les catalogues de diverses boutiques en ligne, voici ce que ce processus comprend:
- Vous devez d'abord trouver les flux XML des magasins en ligne, vous pouvez généralement les trouver soit librement disponibles sur Internet, soit en faisant la demande auprès du magasin lui-même, ou dans divers agrégateurs tels que Admitad;
- le flux est traité (analysé) par un programme spécial - un robot, qui télécharge toutes les images du flux, les place sur le disque dur (plus précisément, sur le stockage réseau auquel votre serveur est connecté), écrit toutes les méta-informations sur les marchandises dans la base de données;
- puis un autre processus est lancé - l'indexeur, qui calcule des vecteurs binaires à 128 dimensions pour chaque image. Vous pouvez combiner le robot et l'indexeur en un seul module ou programme, mais nous avons historiquement développé qu'il s'agissait de processus différents. Cela est principalement dû au fait qu'au départ, nous avons calculé des descripteurs (hachages) pour chaque image distribuée sur un grand parc de machines, car il s'agissait d'un processus très gourmand en ressources. Si vous ne travaillez qu'avec des réseaux de neurones, alors la 1ère machine avec un GPU vous suffit;
- les vecteurs binaires sont écrits dans la base de données, tous les processus sont terminés et le tour est joué - votre base de données de produits est prête pour une recherche ultérieure;
- mais une petite astuce demeure: puisque tous les magasins ont des catalogues différents avec des catégories différentes à l'intérieur, alors vous devez comparer les catégories de tous les flux contenus dans votre base de données avec les catégories du détecteur (plus précisément, le classificateur) de marchandises, nous appelons cela le processus de cartographie. Il s'agit d'une routine manuelle, mais très utile, au cours de laquelle l'opérateur, éditant manuellement un fichier XML régulier, compare les catégories de flux dans la base de données avec les catégories du détecteur. Voici le résultat:
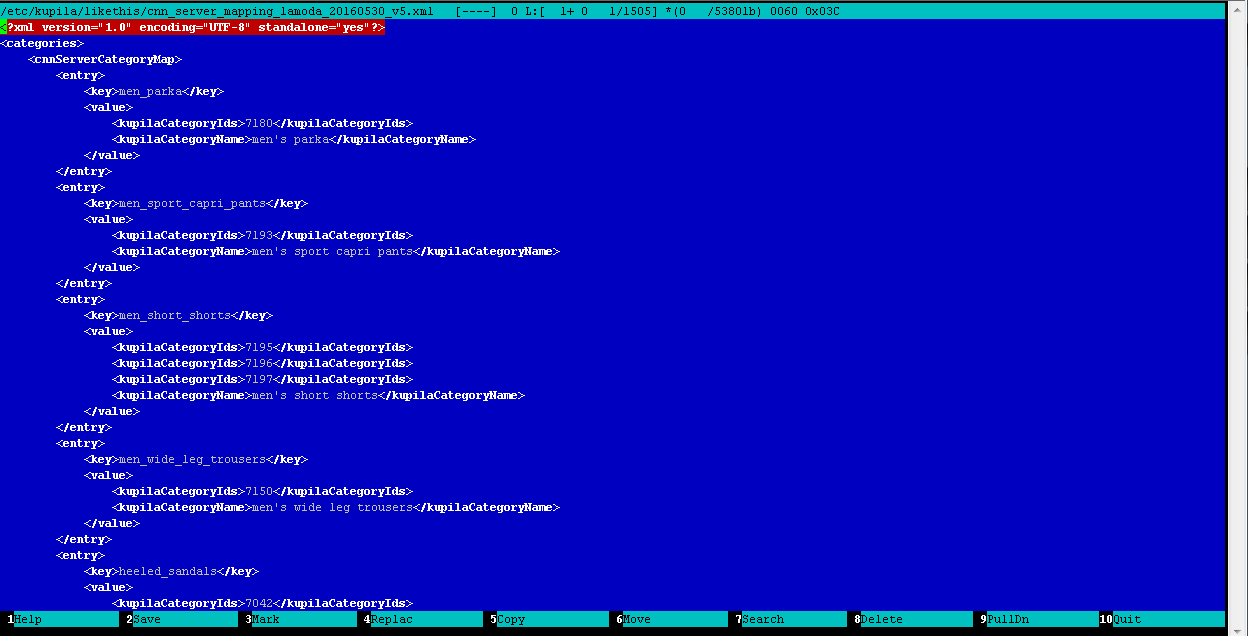 Exemple de fichier de mappage de catégorie: catalog-classifier
Exemple de fichier de mappage de catégorie: catalog-classifierDétection et classification
Afin de trouver quelque chose de similaire à ce que notre œil a trouvé sur la photo, nous devons d'abord détecter ce «quelque chose» (c'est-à-dire localiser et sélectionner l'objet). Nous avons parcouru un long chemin dans la création d'un détecteur, à partir de la formation de cascades OpenCV qui ne fonctionnaient pas du tout sur cette tâche, et se terminant par une technologie moderne pour détecter et classifier
R-FCN et le classificateur basé sur le réseau neuronal
ResNet .
En tant que données utilisées pour la formation et les tests (les soi-disant échantillons de formation et de test), nous avons pris toutes sortes d'images sur Internet:
- recherche sur les images Google / Yandex;
- ensembles de données balisés par des tiers;
- réseaux sociaux;
- sites de magazines de mode;
- Boutiques Internet de vêtements, chaussures, sacs.
Le balisage a été effectué à l'aide d'un outil samopisny, le résultat du balisage a été des ensembles d'images et des fichiers * .seg, qui stockent les coordonnées des objets et les étiquettes de classe pour eux. En moyenne, de 100 à 200 images ont été étiquetées pour chaque catégorie, le nombre total d'images dans 205 classes était de 65 000.
Une fois que les échantillons de formation et de test sont prêts, nous avons fait une double vérification du balisage, en donnant toutes les images à un autre opérateur. Cela nous a permis de filtrer un grand nombre d'erreurs qui affectent fortement la qualité de la formation du réseau neuronal, c'est-à-dire le détecteur et le classificateur. Ensuite, nous commençons à former le réseau neuronal à l'aide d'outils standard et «décollons» le prochain instantané du réseau neuronal «dans la chaleur du jour» dans quelques jours. En moyenne, le temps de formation du détecteur et classificateur sur le volume de données de 65 000 images sur un GPU Titan X est d'environ 3 jours.
Un réseau neuronal prêt à l'emploi doit en quelque sorte être vérifié pour la qualité, c'est-à-dire pour évaluer si la version actuelle du réseau est devenue meilleure que la précédente et de combien. Comment nous l'avons fait:
- l'échantillon de test comprenait 12 000 images et était disposé exactement de la même manière que la formation;
- nous avons écrit un petit outil qui a exécuté l'échantillon de test complet à travers le détecteur et compilé un tableau de ce type (la version complète du tableau est disponible ici );
- ce tableau est ajouté à Excel dans un nouvel onglet et comparé au précédent manuellement ou à l'aide des formules Excel intégrées;
- à la sortie, nous obtenons les indicateurs généraux du détecteur et classificateur TPR / FPR dans tout le système dans et pour chaque catégorie séparément.
 Exemple de tableau de rapport sur la qualité du détecteur et classificateur
Exemple de tableau de rapport sur la qualité du détecteur et classificateurModule de recherche d'images similaires
Après avoir détecté des articles de garde-robe sur la photo, nous démarrons le moteur de recherche d'images similaires, voici comment cela fonctionne:
- pour tous les fragments d'image découpés (biens détectés), les vecteurs de caractéristiques binaires du réseau neuronal 128 bits sont calculés en forme et en couleur (d'où ils viennent, voir ci-dessous);
- les mêmes vecteurs calculés plus tôt au stade de l'indexation pour toutes les images de marchandises stockées dans la base de données sont déjà chargés dans la mémoire RAM de l'ordinateur (car pour rechercher des similaires, il sera nécessaire de faire un grand nombre de recherches et de comparaisons par paires, nous avons chargé la base de données entière immédiatement en mémoire, ce qui nous a permis d'augmenter la vitesse de recherche est des dizaines de fois, tandis que la base d'environ 100 000 produits ne tient pas plus de 2 à 3 Go de RAM);
- les coefficients de recherche pour cette catégorie proviennent de l'interface ou de propriétés codées en dur, par exemple, dans la catégorie «robe», nous recherchons plus en couleur qu'en forme (par exemple, recherche de forme en 8 à 2 couleurs), et dans la catégorie «chaussures à talons hauts» nous regardons 1-to-1 form-color puisque la forme et la couleur sont également importantes ici;
- En outre, les vecteurs pour le recadrage (fragments) de l'image d'entrée sont comparés par paires avec l'image de la base de données, en tenant compte des coefficients (la distance de Hamming entre les vecteurs est comparée);
- en conséquence, un tableau de produits similaires à partir de la base de données est formé pour chaque fragment de produit coupé, et un poids est attribué à chaque produit (selon une formule simple, en tenant compte de la normalisation, de sorte que tous les poids se situent dans la plage de 0 à 1) pour la possibilité de sortie vers l'interface, ainsi que pour d'autres tri;
- un tableau de produits similaires est affiché dans l'interface via le web-JSON-API.
Les réseaux de neurones pour la formation de vecteurs de réseau de neurones en forme et en couleur sont formés comme suit.
- Pour former le réseau neuronal en forme, nous prenons toutes les images étiquetées, découpons les fragments selon le balisage et les répartissons dans des dossiers selon la classe: c'est-à-dire tous les pulls dans un dossier, tous les T-shirts dans un autre et toutes les chaussures à talons hauts dans le troisième, etc. d. Ensuite, nous formons un classificateur ordinaire basé sur cet échantillon. Ainsi, nous «expliquons» en quelque sorte au réseau neuronal notre compréhension de la forme de l'objet.
- Pour former le réseau neuronal en couleur, nous prenons toutes les images balisées, découpons les fragments selon le balisage et les répartissons dans des dossiers selon la couleur: c'est-à-dire que nous mettons tous les T-shirts, chaussures, sacs, etc. dans le dossier «vert». couleur verte (par conséquent, tous les objets de couleur verte s'accumulent généralement dans un dossier), dans le dossier «dépouillé», nous mettons toutes les choses dans une bande, et dans le dossier «rouge-blanc» toutes les choses rouge-blanc. Ensuite, nous formons un classifieur distinct pour ces classes, comme s'il «expliquait» au réseau neuronal sa compréhension de la couleur d'une chose.
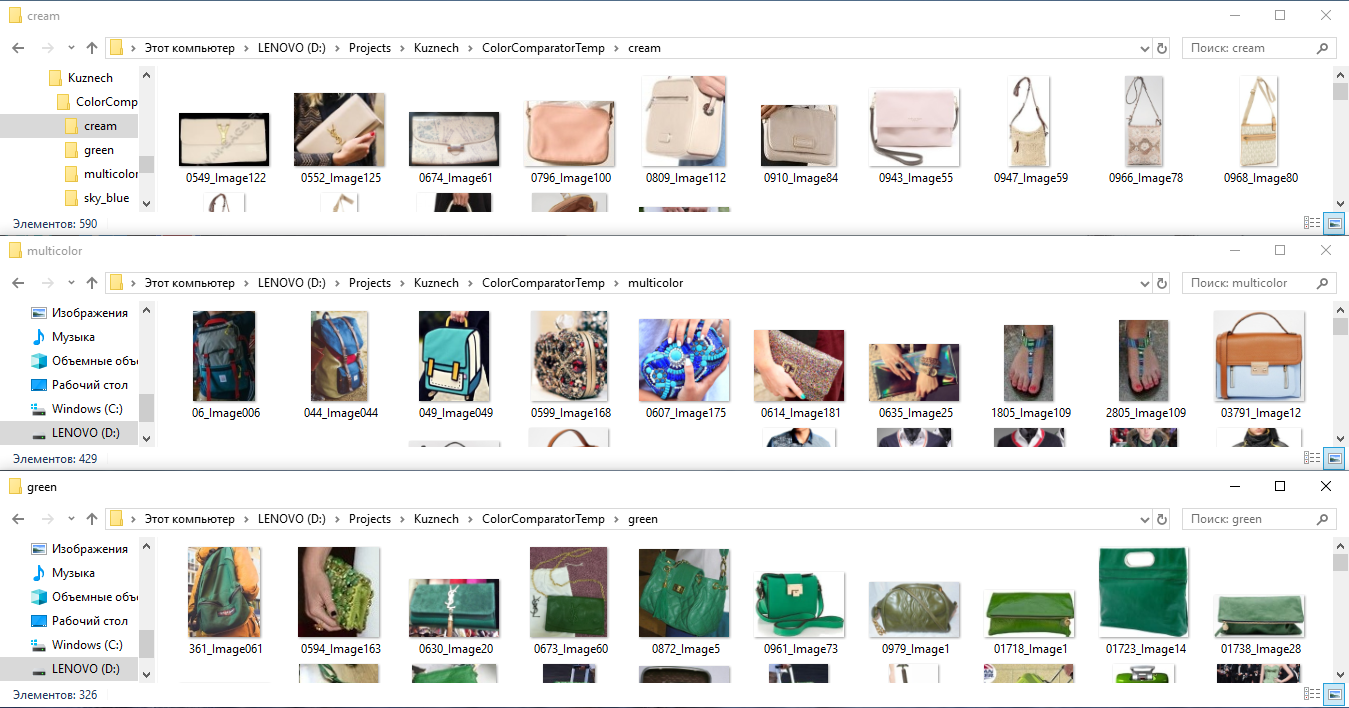 Un exemple de marquage d'images par couleur pour obtenir des vecteurs de réseaux neuronaux de signes par couleur.
Un exemple de marquage d'images par couleur pour obtenir des vecteurs de réseaux neuronaux de signes par couleur.Fait intéressant, une telle technologie fonctionne bien même sur des arrière-plans complexes, c'est-à-dire lorsque des fragments de choses sont découpés non pas clairement le long du contour (masque), mais le long d'un cadre rectangulaire, que le marqueur a défini.
La recherche de similaires est basée sur l'extraction de vecteurs de caractéristiques binaires du réseau neuronal de cette manière: la sortie de l'avant-dernière couche est prise, compressée, normalisée et binarisée. Dans notre travail, nous avons compressé en un vecteur 128 bits. Vous pouvez le faire un peu différemment, par exemple, comme décrit dans l'article de Yahoo «
Deep Learning of Binary Hash Codes for Fast Image Retrieval », mais l'essence de tous les algorithmes est à peu près la même - des images similaires à l'image sont recherchées en comparant les propriétés que le réseau neuronal opère au sein des couches.
Initialement, en tant que technologie de recherche d'images similaires, nous avons utilisé des hachages ou des descripteurs d'images basés (calculés plus précisément) sur certains algorithmes mathématiques, tels que l'opérateur Sobel (ou hachage de contour), l'algorithme SIFT (ou points singuliers), le traçage d'un histogramme ou la comparaison du nombre d'angles dans une image . Cette technologie a fonctionné et a donné des résultats plus ou moins sains, mais les hachages ne sont en rien comparables à la technologie de recherche d'images similaires en fonction des propriétés attribuées par un réseau de neurones. Si vous essayez d'expliquer la différence en 2 mots, l'algorithme de comparaison d'images basé sur le hachage est une «calculatrice» qui est configurée pour comparer les images à l'aide d'une formule et qui fonctionne en continu. Une comparaison utilisant des fonctionnalités d'un réseau de neurones est «l'intelligence artificielle», formée par une personne pour résoudre un problème spécifique d'une certaine manière. Vous pouvez donner un exemple aussi grossier: si vous recherchez des pulls en hash à rayures noires et blanches, vous trouverez probablement toutes les choses en noir et blanc comme des similaires. Et si vous recherchez en utilisant un réseau de neurones, alors:
- dans les premiers endroits, vous trouverez tous les pulls à rayures noires et blanches,
- puis tous les pulls en noir et blanc
- puis tous les pulls à rayures.
API JSON pour une interaction pratique avec n'importe quel appareil et service
Nous avons créé une API WEB-JSON simple et pratique pour communiquer notre système avec tous les appareils et systèmes, ce qui, bien sûr, n'est pas une innovation, mais plutôt une bonne norme de développement solide.
Interface Web ou application mobile pour afficher les résultats
Pour vérifier visuellement les résultats, ainsi que pour démontrer le système aux clients, nous avons développé des interfaces simples:
Erreurs commises dans le projet
- Dans un premier temps, il est nécessaire de définir plus clairement la tâche, et il s'agit, en fonction de la tâche, de sélectionner des photographies à mettre en page. Si vous devez rechercher des photos UGC (User Generated Content) - il s'agit d'un cas et d'exemples de mise en page. Si vous avez besoin d'une recherche de photos à partir de magazines sur papier glacé, il s'agit d'un cas différent, et si vous avez besoin d'une recherche de photos où un grand objet est situé sur un fond blanc, il s'agit d'une histoire distincte et d'un échantillon complètement différent. Nous avons tout mélangé en un seul tas, ce qui a affecté la qualité du détecteur et du classificateur.
- Sur les photos, vous devez toujours marquer TOUS les objets, au moins du fait que cela convient au moins à votre tâche, par exemple, lorsque vous choisissez une sélection de garde-robe similaire, vous devez immédiatement marquer tous les accessoires (perles, lunettes, bracelets, etc.), la tête chapeaux, etc. Parce que maintenant que nous avons un énorme ensemble de formation, afin d'ajouter une autre catégorie, nous devons redistribuer TOUTES les photos, et c'est un travail très volumineux.
- La détection est probablement mieux effectuée avec un réseau de masques, la transition vers Mask-CNN et une solution moderne basée sur Detectron est l'un des domaines du développement du système.
- Ce serait bien de décider immédiatement comment vous allez déterminer la qualité de la sélection d'images similaires - il y a 2 méthodes: «à l'œil» et c'est la méthode la plus simple et la moins chère et la 2e - la méthode «scientifique», lorsque vous collectez des données auprès d '«experts» (personnes, que je teste votre algorithme de recherche similaire) et sur la base de ces données, formez un échantillon de test et un catalogue spécifiquement pour la recherche d'images similaires. Cette méthode est bonne en théorie et semble assez convaincante (pour vous et pour les clients), mais en pratique, sa mise en œuvre est difficile et assez coûteuse.
Conclusion et plans de développement ultérieurs
Cette technologie est tout à fait prête et utilisable, elle fonctionne maintenant chez l'un de nos clients dans la boutique en ligne en tant que service de recommandation. De plus, récemment, nous avons commencé à développer un système similaire dans une autre industrie (c'est-à-dire que nous travaillons maintenant avec d'autres types de marchandises).
Des plans immédiats: le transfert du réseau à Mask-CNN, ainsi que le re-marquage et le re-marquage des images pour améliorer la qualité du détecteur et du classifieur.
En conclusion, je veux dire que selon nos sentiments, une technologie similaire et en général les réseaux de neurones sont capables de résoudre jusqu'à 80% des tâches complexes et hautement intellectuelles que notre cerveau rencontre quotidiennement. La seule question est de savoir qui est le premier à mettre en œuvre une telle technologie et à décharger une personne du travail de routine, lui laissant ainsi un espace de créativité et de développement, ce qui est, à notre avis, le but le plus élevé de l'homme!
Les références