Les services doivent être écrits de manière à ce que des fonctionnalités minimales soient toujours maintenues, même en cas de défaillance des composants critiques. Ilya Sidorov, le chef d'une des équipes de développement de produits du backend Yandex.Taxi, a expliqué dans son rapport comment nous laissons l'utilisateur commander une voiture lorsque certaines parties du système ne fonctionnent pas, et par quelle logique nous activons les versions simplifiées du service.
Il est important d'écrire non seulement des services qui fonctionnent bien, mais aussi des services qui fonctionnent bien.
"Je suis très heureux de vous voir tous." Aujourd'hui, je vais parler de la dégradation gracieuse. Si vous le recherchez dans Yandex, vous apprendrez très probablement comment faire fonctionner votre site sans JS. Je vais vous parler un peu d'autre chose. À propos de la dégradation gracieuse par rapport au backend.

Commençons par la définition. À quoi ça ressemble en réalité?
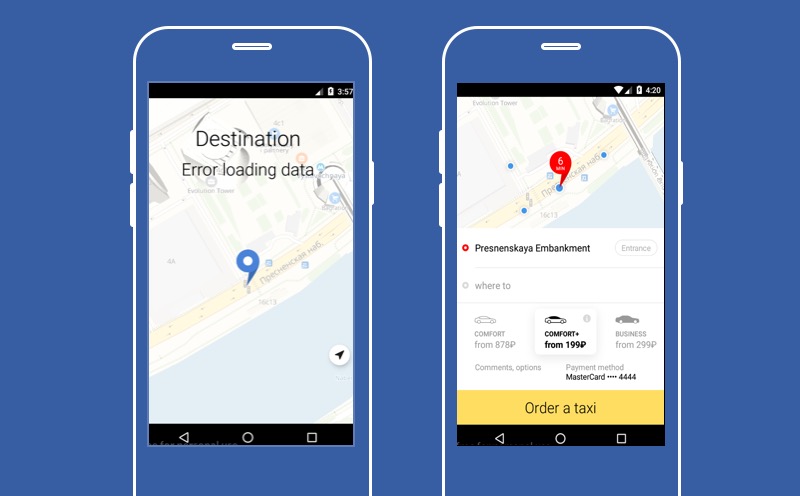
C'est là que notre application Yandex.Taxi est présentée au cas où l'un des services ne fonctionnerait pas - le service pour choisir la destination où le chauffeur devrait vous emmener. Comme vous pouvez le voir, sur cet écran il n'y a pas de gros bouton «Commander un taxi», ce qui signifie que l'utilisateur ne pourra pas utiliser le service. Mais vous pouvez essayer de dégrader et permettre à l'utilisateur de ne pas choisir le point B.
Ensuite, il ne pourra pas connaître le prix exact du voyage, nous ne pourrons pas construire un itinéraire, mais l'utilisateur aura un bouton «Commander un taxi» et il pourra utiliser notre service. La fonction principale de notre application sera disponible. C'est de cela que je veux parler aujourd'hui. À propos de la façon de se dégrader correctement et de ce qui peut être fait avec un service défectueux.
Plan de performance. Je vais vous dire comment dégrader quoi faire avec le service. Vous pouvez le désactiver et également utiliser un comportement différent. Ensuite, je vais vous dire comment comprendre quand il est temps de désactiver notre service. Et à la fin, je parlerai de quelques nuances auxquelles nous avons dû faire face lorsque nous avons créé un système de dégradation automatique pour Yandex.Taxi.
Que peut-on faire avec un service interrompu? Vous pouvez désactiver la fonctionnalité. Si le service de prévision de destinations individuelles ne fonctionne pas, vous désactivez ce service. Si le chat entre le conducteur et le passager ne fonctionne pas, vous désactivez le chat. Si vous ne pouvez pas commander une voiture, vous désactivez le bouton "Commander une voiture" - oh, non, cela ne fonctionne pas. Toutes les fonctionnalités ne peuvent pas être désactivées. Et si vous ne pouvez pas désactiver quelque chose, vous devez utiliser une approche différente. Par exemple, vous pouvez essayer de créer une mise en page ou une fonctionnalité simplifiée. Nous appelons un tel comportement simplifié dans Yandex une citrouille - nous disons que le service est devenu une citrouille.
Examinons ces solutions plus en détail.
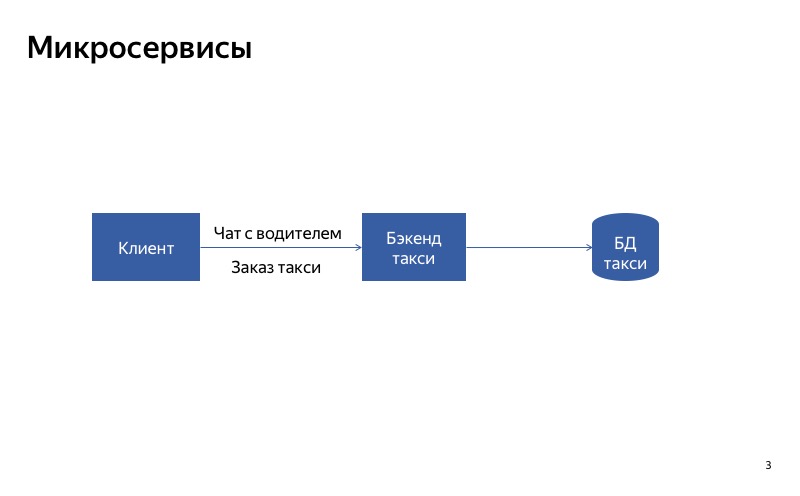
Comment désactiver les services? Vous pouvez probablement créer la bonne architecture. Supposons que nous ayons un service monolithique. Si l'une de ses parties tombe en panne, alors l'ensemble du service est interrompu. Mais si nous divisons le service en plusieurs parties afin que les clients utilisent différents services pour différentes demandes, cela deviendra beaucoup mieux.
Comment cela fonctionnera-t-il sur un exemple? Il existe un service Yandex.Taxi, dans lequel il existe deux fonctions principales: commander un taxi et discuter avec le chauffeur. Tant que nous avons un backend monolithique, si la conversation avec le conducteur échoue, la fonctionnalité de base de la commande d'un taxi sera affectée.
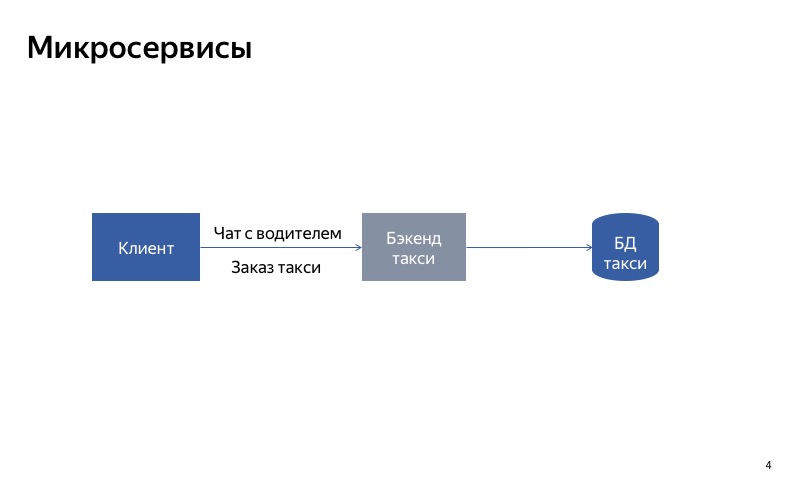
Que pouvez-vous essayer de faire? Divisez le service monolithique en deux parties. Une partie sera responsable de la commande d'un taxi, et l'autre - de la communication avec le chauffeur.
Maintenant, tout semble beaucoup mieux. Si la conversation avec le pilote est interrompue, tout le reste continue de fonctionner correctement.
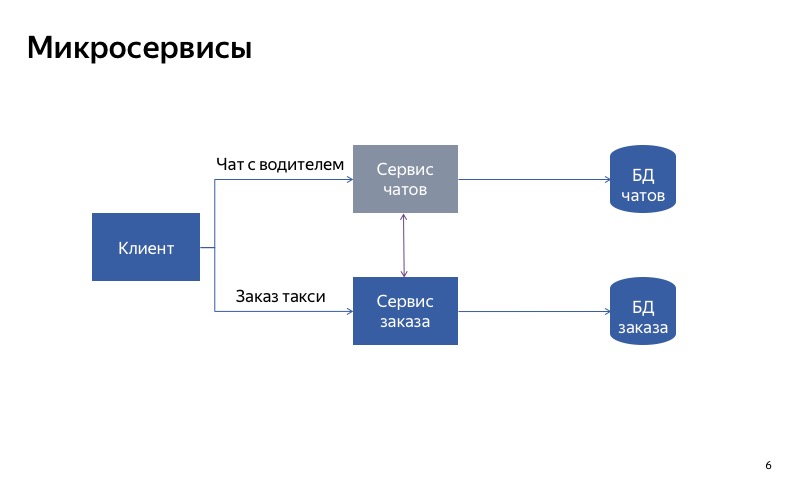
Comme vous pouvez le voir, le client utilise différentes API, différentes demandes pour passer une commande et communiquer avec le pilote.
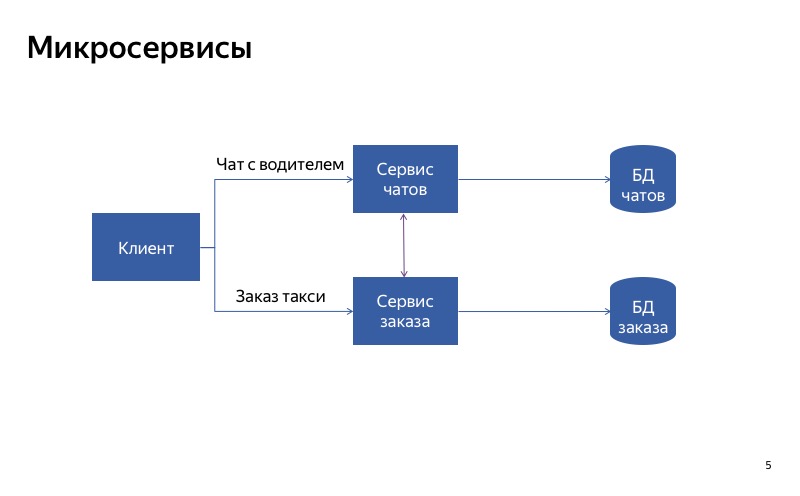
Mais en fait, il semble que maintenant tout ne soit pas si bon, car il existe une fausse connexion entre le service de chat et le service de commande. Et il peut s'avérer que le service de commande utilise un service de chat inactif. Dans ce cas, la fonctionnalité principale ne fonctionnera pas.
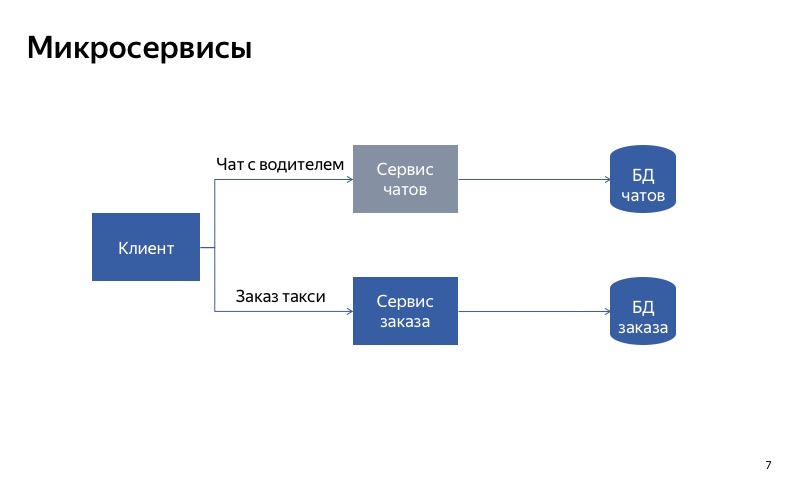
Et dans ce cas, tout va beaucoup mieux. Les communications parasites ont disparu et nos services sont désormais vraiment indépendants les uns des autres. Donc, si le service de chat tombe en panne, vous pouvez toujours prendre un taxi.
La conclusion de ceci est la suivante: si vous voulez dégrader en utilisant la séparation des services, il est très important de rendre les services indépendants les uns des autres. Cela signifie qu'ils doivent avoir différents points d'entrée, différents points de terminaison. Ils doivent avoir des durées d'exécution différentes. Et bien sûr, ils doivent utiliser différentes bases de données. Sinon, un service interrompu peut interrompre tous les autres services de la chaîne.
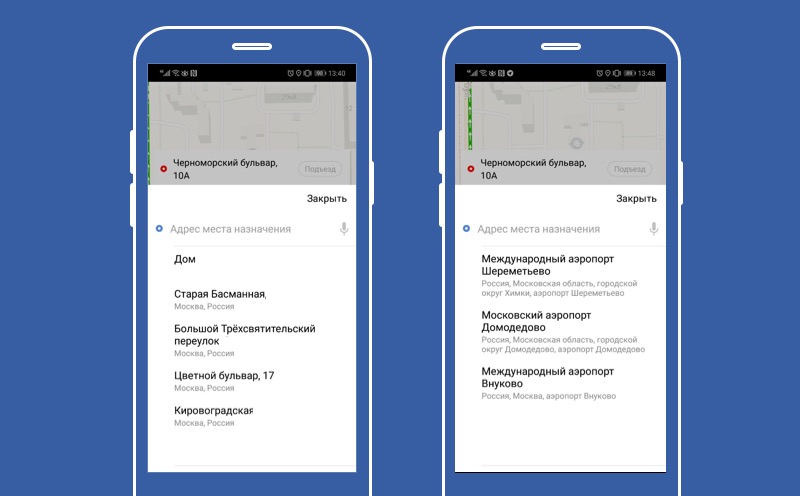
Eh bien, nous avons compris comment désactiver la fonctionnalité. Voyons maintenant comment faire la fonctionnalité par défaut, comment faire de la citrouille. Sur cet écran, notre service de prédiction de destination. Le service utilise l'IA intelligente pour prédire à l'utilisateur les meilleures destinations pour lui en ce moment. Et si l'IA est fatiguée, nous utilisons le comportement par défaut et proposons à l'utilisateur de quitter Moscou.
Voyons comment cela fonctionne dans la pratique.

Nous avons un client, il contacte le service de destination et obtient une erreur.
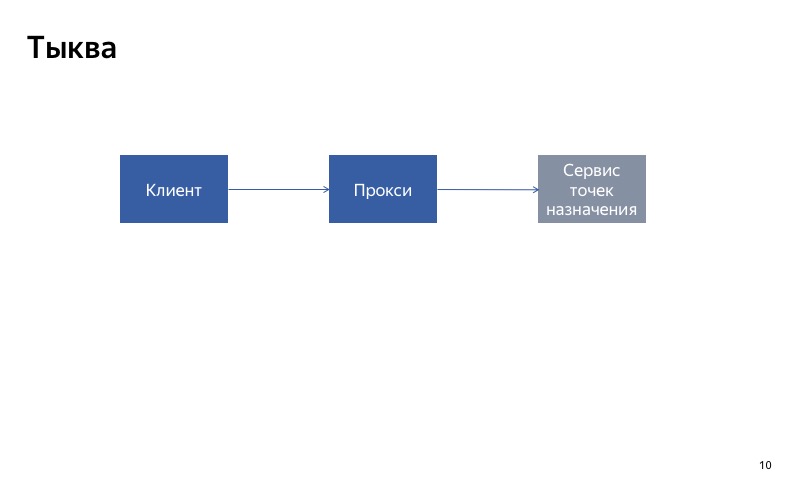
Maintenant, deux situations sont possibles. La première situation, si l'échec était unique, n'est qu'une seule demande ayant échoué. Dans ce cas, nous jetons simplement une erreur au client, il fera une nouvelle demande et obtiendra ses destinations préférées.
Mais si l'échec est massif, nous allumons la citrouille et l'utilisateur obtient le comportement par défaut.

Mais un tel comportement à la peau dure est beaucoup plus facile à mettre en œuvre, et cette citrouille est très fiable, elle nous permet donc de travailler même lorsque l'IA échoue. Si nous savons que les utilisateurs se rendent souvent dans les aéroports, nous ne remarquerons pas de détérioration significative de la vie des utilisateurs.
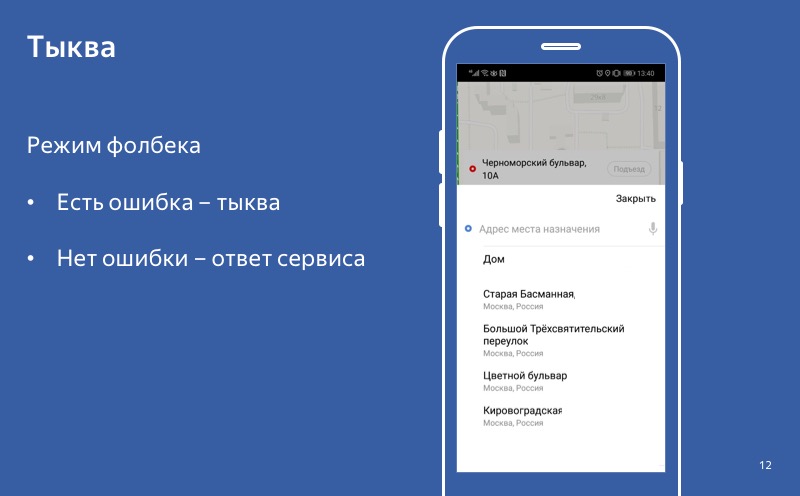
Même si le mode de dégradation est activé, la citrouille est activée, mais l'utilisateur contacte le service et reçoit une réponse réussie, alors nous utilisons cette réponse, pas la citrouille. Et ce comportement - lorsque dans le cas d'une réponse nous l'utilisons, et en cas d'erreur nous utilisons une citrouille - nous appelons le mode de repli.
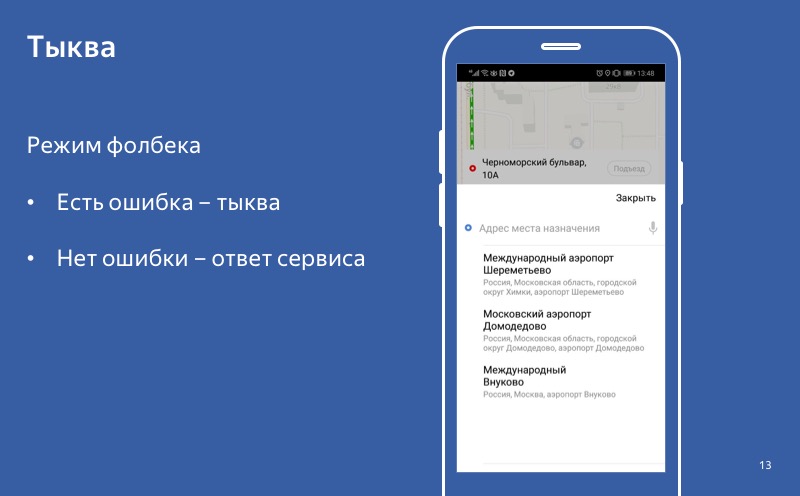
Aucune erreur - une réponse réussie. Il y a une erreur - une citrouille. Nous disons que le repli est activé.
J'ai trié ce qui peut être fait avec un service qui a échoué. Vous pouvez le désactiver ou activer la citrouille. Passons maintenant à la deuxième partie et voyons comment diagnostiquer.
Nous avons deux grandes questions auxquelles il faut répondre. Le premier est lorsque vous devez désactiver le service et allumer la citrouille. La seconde est lorsque vous devez désactiver la citrouille et réactiver le service. Avant de pouvoir répondre à ces questions, nous devons clarifier un point.
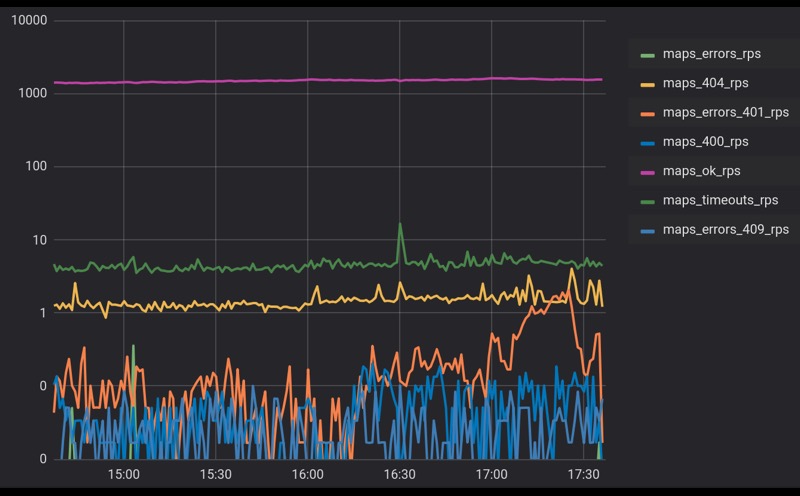
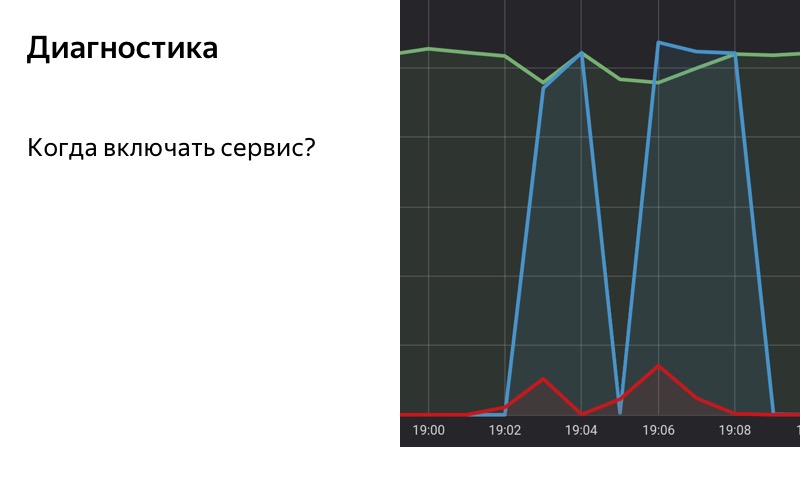
Dans tout système complexe qui interagit avec un grand nombre d'agents, il y a toujours des antécédents d'erreurs. Sur cette diapositive, nous voyons un véritable calendrier d'appels à l'un de nos services. Plusieurs milliers de RPS y viennent, nous obtenons un peu moins de 1% d'erreurs. Voici l'échelle logarithmique.
Les erreurs peuvent être causées par diverses choses. C'est peut-être une sorte de processus interne, la mise à jour d'une sorte de base de données ou simplement des processus d'arrière-plan. Peut-être que les clients font de mauvaises demandes, mais le fait demeure: nous aurons toujours un arrière-plan d'erreurs. Prenons-le et continuons.
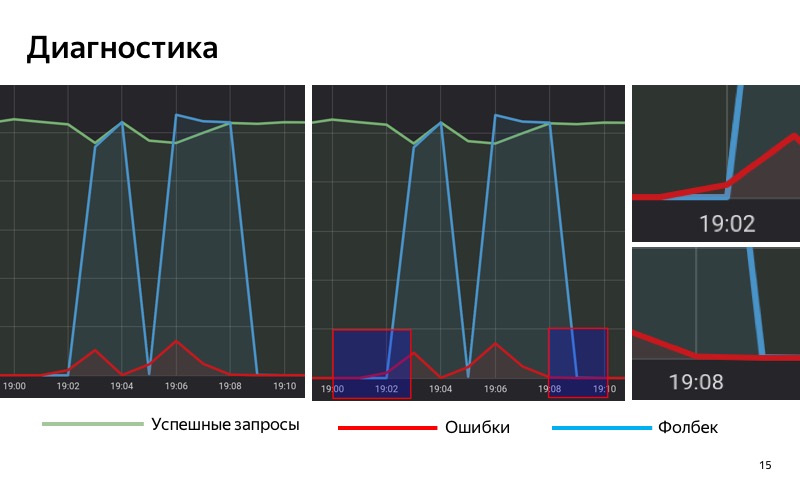
Nous utilisons donc la solution basée sur des statistiques. Nous avons une base de données spéciale dans laquelle nous enregistrons des statistiques, enregistrons le nombre de requêtes réussies, le nombre de requêtes avec des erreurs et des requêtes pour lesquelles le repli a été inclus. Nous prenons et accumulons des statistiques sur notre service sur une période de temps avec une fenêtre coulissante. Lorsque la proportion de demandes avec des erreurs dans cette fenêtre glissante dépasse un certain seuil, nous activons le repli. Et lorsque le nombre d'erreurs devient inférieur au seuil, nous le désactivons.
Faites attention aux zones sélectionnées. À 19 h 01, les premières erreurs ont commencé à apparaître, mais jusqu'à présent, leur part est assez faible, et jusqu'à 19 h 02, nous n'incluons pas le repli. A 19h02 le seuil est dépassé, nous avons activé le repli. A 19h08 le processus inverse: les erreurs ont pris fin, mais depuis un certain temps nous avons recours au repli, car le seuil est toujours dépassé dans notre fenêtre glissante. À 19 h 09, nous avons désactivé le repli.
Nous avons compris quand désactiver le service. Il est nécessaire de répondre à la deuxième question: quand l'allumer. C'est simple: nous utilisons la même solution basée sur des statistiques.
Il est important de ne pas supprimer la charge du service, même si nous activons le mode de dégradation. C'est ce qui nous permet de continuer à recevoir des statistiques même si nous montrons à l'utilisateur une citrouille. Ainsi, nous pouvons déterminer que les erreurs sont terminées, le service est réparé. Vous pouvez donc le réactiver complètement.
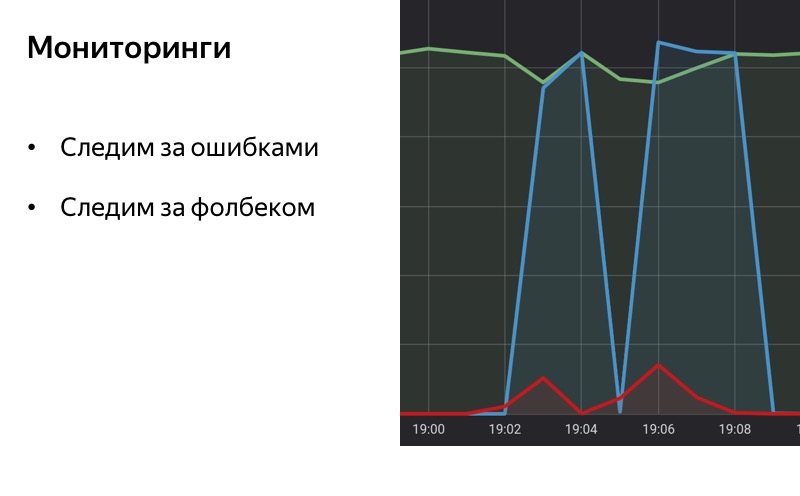
Quand on parle de dégradation, on ne peut pas dire de surveillance. Une bonne surveillance est la moitié du succès, la moitié du chemin vers l'arrêt automatique ou la dégradation automatique. Il est important pour nous de comprendre le type de problèmes qui surviennent avec notre service, la nature des erreurs et leur fréquence. Et peut-être qu'à la première étape, nous n'avons même pas besoin d'un disjoncteur. Simplement, si le voyant de surveillance s'allume, nous pouvons activer et désactiver le service manuellement. Lorsque la lampe de surveillance s'éteint, nous activons le service.
Si nous faisons une dégradation automatique, un commutateur automatique, alors il est important de faire une surveillance sur le repli lui-même. Si le système de dégradation fonctionne assez bien, les utilisateurs ne remarqueront peut-être pas du tout que quelque chose s'est cassé en nous. Nous-mêmes pouvons, s'il n'y a pas de surveillance, ne pas le remarquer. Il est important de surveiller le repli, il est important de comprendre quand il est allumé, quand il est éteint, afin que les statistiques soient disponibles et nous pouvons comprendre combien de temps la fonctionnalité ne fonctionne pas, si notre backend empire ou s'améliore au fil du temps, selon combien de temps nous pensons repli .
Tout est avec l'essentiel.
En fin de compte, je voudrais vous dire quelques nuances auxquelles nous avons dû faire face lorsque nous développions un système de dégradation automatique dans Yandex.Taxi.
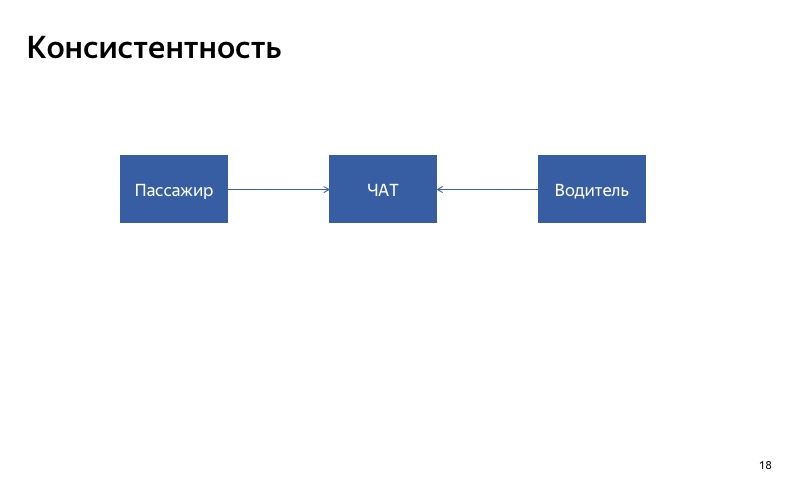
La première chose à laquelle vous devez faire attention est la cohérence. Si vous effectuez une dégradation automatique pour un certain service, il est important que le service réponde de manière cohérente à tous ses clients. Si vous avez deux clients qui utilisent le service, il est important que les réponses de ces deux clients en cas de dégradation soient cohérentes. Et si vous avez un service qui est impliqué dans un long processus, vous devez comprendre: peut-être qu'au début et à la fin du processus, le service fonctionnera correctement, et quelque part au milieu de secours sera activé.
Cela semble compliqué, mais essayons d'expliquer avec un exemple. Cela deviendra peut-être plus clair.
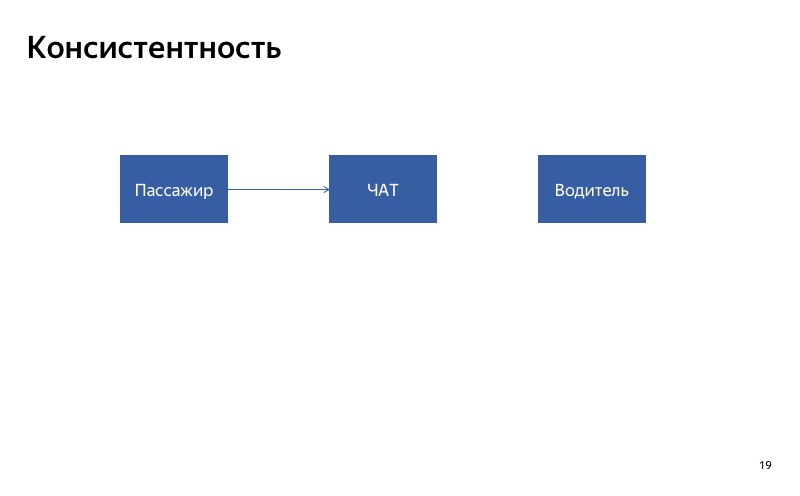
Voici notre conversation entre chauffeur et passager. Le moyen le plus simple de le dégrader est de le désactiver. Imaginons que le chat du pilote soit rompu. Que va-t-il arriver? Le client écrira sur le chat, mais le pilote ne verra pas les messages. Ils seront probablement très mécontents, jureront à notre candidature lorsqu'ils se rencontreront. Dans ce cas, il est important que le chat soit activé en même temps ou désactivé en même temps pour tous les participants au chat. C'est ce que j'appelle la cohérence.

La deuxième nuance concerne le fait que notre application Yandex.Taxi est géo-distribuée: les taxis peuvent être commandés à Moscou, Krasnoyarsk ou Helsinki. Ceci doit être pris en compte même lors du développement de systèmes de dégradation. Imaginez que nous avons beaucoup de demandes réussies et très peu de demandes avec des erreurs. Il semblerait que ce soit une situation normale, le fond des erreurs est toujours présent. Mais vous pouvez regarder la même image différemment.
Vous pouvez voir que le service ne fonctionne pas dans Mytishchi et vous devez activer le repli pour ces utilisateurs. La conclusion est: vous devez construire les bonnes statistiques. Pour nous, en tant que service géo-distribué, cela signifie également que nous devons construire des statistiques par ville. Si nous faisons les statistiques correctement, nous verrons immédiatement que la plupart des demandes de Mytishchi se cassent et activent le repli spécifiquement pour les utilisateurs de Mytishchi. Et pour tous les autres utilisateurs, nous continuerons à travailler en mode normal, car pour eux le service fonctionne correctement.

Peut-être que pour d'autres services, il y aura des conditions différentes et d'autres nuances.
Nos services deviennent de plus en plus complexes. Ils dépendent souvent du monde extérieur, ce que nous ne pouvons pas prévoir. Par conséquent, il est important d'écrire non seulement des services qui fonctionnent bien, mais aussi des services qui fonctionnent bien. Si vous apprenez quelque chose de nouveau, dites-le à vos collègues, partagez-le. Aimez, partagez, republiez. Dégrader correctement.