Introduction lyrique
Un soir, mettant les choses en ordre dans un placard, je suis tombé sur une grande boîte en carton. Elle a survécu à deux déménagements et n'a pas ouvert pendant tant d'années que j'ai complètement oublié ce qui y était stocké. Il s'est avéré qu'il y avait des photos - dans des albums, dans des enveloppes d'un magasin, et certaines étaient comme ça.
De nombreuses photographies ont été prises il y a plus de soixante-dix ans. L'un était un grand-père - dans ses années d'études, encore jeune et beau, dans des lunettes absolument
destructrices . «Wow, mon grand-père portait des vêtements hipster avant même qu'ils ne deviennent courants», ai-je pensé et j'ai involontairement souri. Je l'ai reconnu tout de suite, mais je suis ensuite allé voir les photos de personnes dont je ne me souviens de rien. Dans les traits du visage, vous pouvez vaguement deviner la relation - et c'est tout.

Quand j'avais quinze ans, ma grand-mère a montré à plusieurs reprises ces cartes et a parlé de ceux qui y sont représentés. Malheureusement, la valeur de telles histoires n'est comprise que lorsqu'il n'y a personne pour les raconter. À cette époque, pour la dixième fois, c'était absolument inintéressant pour moi d'écouter des contes moussus sur les années d'avant-guerre, je les ai fait signe et passé les oreilles. Maintenant, soudain, réalisant pleinement qu'une partie de mon histoire familiale était irrémédiablement perdue, j'ai eu l'idée de systématiser et de préserver ce qui restait.
La solution idéale pour stocker des données familiales me semblait être un hybride d'un moteur wiki et d'un album photo. Il n'y avait pas de solutions adaptées toutes faites, j'ai donc dû écrire la mienne. Il s'appelle
Bonsai et est open source sous la licence MIT. Ensuite, il y aura une histoire sur la façon dont il est organisé et comment l'utiliser, ainsi que l'histoire de son développement et un peu de
DRAMA .

Un autre vélo?
Aujourd'hui, il existe de nombreux outils qui vous permettent de faire des arbres généalogiques et de cataloguer les informations sur les proches. Ils sont conditionnellement divisés en deux grandes catégories - les services en ligne et les applications de bureau.
Dans le cas d'une application de bureau, la base de données est généralement stockée sous forme de fichier sur disque. Vous ouvrez l'application et la réapprovisionnez en mode mono-utilisateur. Si nécessaire, les données peuvent être exportées pour la sauvegarde ou le transfert vers un autre système (par exemple, au format
GEDCOM ). Parmi ceux que j'ai regardés, les plus agréables à utiliser semblaient
Gramps (gratuit) et l'
arbre de vie domestique (nécessite un achat unique).
Le côté opposé du spectre est les services Web. Ils stockent vos données sur des serveurs distants et facturent des frais d'utilisation périodiques. Puisqu'il s'agit d'un produit commercial avec une base centralisée et une bonne monétisation, les services de ce plan vous donnent la possibilité, par exemple, de rechercher des proches perdus par test ADN ou archives.
Les avantages et les inconvénients des deux options sont assez évidents. Dans le premier cas, vous stockez la base de données localement et contrôlez entièrement son accès et la création de sauvegardes. Si l'application est open source, si nécessaire, vous pouvez même y ajouter des fonctionnalités supplémentaires. Cependant, travailler avec une telle base de données ensemble ou afficher les données d'un autre appareil sera difficile. Dans le second, au contraire, l'accès se fait depuis n'importe quel appareil, mais vous donnez vos données à des tiers et espérez leur décence. Dans l'histoire de ma famille, il n'y a pas de secrets compromettants et terribles, cependant, je considère toujours ces informations comme purement personnelles et, en principe, je ne veux que personne d'autre les stocke ou les analyse.
Compte tenu des lacunes de ces deux approches, nous pouvons formuler une liste d'exigences pour le moteur "idéal":
- Application Web hébergée sur votre propre serveur
- Création d'articles sur les personnes, les animaux domestiques, les lieux, les événements, etc. comme un wiki
- Télécharger les médias
- Marques de personnes sur les photos et vidéos
- Construction automatique de l'arbre généalogique
- Calendrier avec toutes les dates importantes.
- Outils de coédition et de remplissage
Pour être honnête, j'ai réussi à trouver plusieurs projets avec une implémentation auto-hébergée, mais ils étaient dans un état déplorable: l'apparence s'est figée au niveau du milieu des années 2000, il n'y avait pas un ensemble complet des fonctionnalités nécessaires, mais je ne voulais pas creuser dans les scripts hérités en PHP. De plus, le précédent projet pour animaux de compagnie était terminé et il y avait un désir de prendre quelque chose de nouveau.
La règle d'or dit:
si vous voulez bien faire, faites-le vous-même!Les technologies utilisées ont été sélectionnées selon trois critères: mon expérience avec elles, leur popularité et leur ouverture. Voici le résultat:
- Rantime : .NET Core 2.1
- Backend : ASP.NET Core MVC
- Base de données : PostgreSQL
- Logique frontend : partiellement Vue, partiellement jQuery.
- Styles frontaux : Bootstrap + Sass
Les rôles de support incluent Elasticsearch pour la recherche en texte intégral et ffmpeg pour prendre des captures d'écran de la vidéo.
Schéma de données
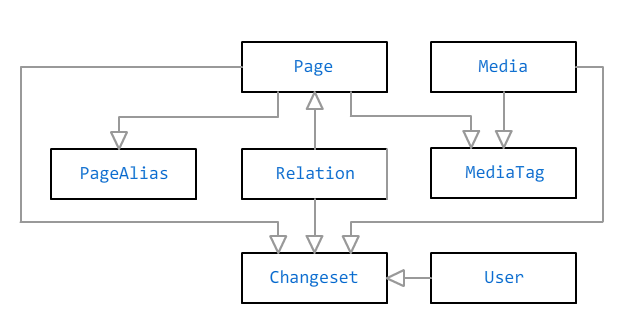
Les principaux objets de la base de données Bonsai sont une
page et un
fichier multimédia . Ils sont reliés par une relation plusieurs-à-plusieurs à travers des
marques . Un tag peut avoir un titre sans lien - par exemple, si vous avez besoin de taguer quelqu'un sur une photo, mais il n'y a pas d'informations sur une page complète à ce sujet.
En plus du texte libre, la page peut contenir des
faits entrés dans des champs spéciaux du panneau d'administration. Des faits supplémentaires sont calculés sur les faits: par exemple, si vous indiquez la date de naissance de la personne, elle sera indiquée sur le calendrier, et sa page affichera l'âge actuel (ou l'espérance de vie, si la date de décès est également indiquée), le sexe peut être utilisé pour déterminer le nom correct de la relation (`` père »Ou« mère »au lieu des« parents »courants), etc. Les faits sont stockés dans la base de données en tant que document JSON.
Vous avez le choix entre cinq types de pages: personne, animal, événement, lieu, etc. La liste des faits disponibles dépend du type de page: par exemple, «l'éducation» n'est pertinente que pour une personne, «la date de naissance» est pour une personne et un animal, et «l'adresse» est uniquement pour un lieu.
Les pages sont interconnectées par des
relations : «parent», «conjoint», «ami», «propriétaire», «résident» et bien d'autres. Certaines relations peuvent être limitées dans le temps (conjoint, propriétaire, résident), d'autres sont considérées comme permanentes.
Lorsque vous enregistrez une page ou une relation, la cohérence du modèle résultant est vérifiée. Par exemple,
les années de vie des conjoints doivent se chevaucher , une personne ne peut pas avoir plus d’un parent biologique de chaque sexe et vous ne pouvez pas non plus
devenir votre propre père . Les mariages homosexuels sont cependant autorisés.
La modification d'une page, d'un fichier multimédia ou d'une relation enregistre la
modification dans la base de données. Cela vous permet de sauvegarder l'historique des modifications et de les restaurer si nécessaire.
Relation
La parenté est l'un des concepts les plus anciens de la société. Déjà dans la
langue pré-indo-européenne, il y avait beaucoup de noms pour eux, qui, sous une forme légèrement modifiée, ont migré vers les langues modernes de divers groupes: le mot «mère» sera compris par le russe, l'anglais et le chinois.
Il existe de nombreuses options de parenté, mais les options de base sont trois:
parent ,
enfant et
conjoint . Ils vous permettent de construire un graphique dirigé à partir de la famille où ces relations sont des arêtes et les personnes sont des nœuds. Dans cette colonne, vous pouvez exprimer toute autre relation, en connaissant le chemin entre les participants et leur sexe: par exemple, pour identifier le grand-père de quelqu'un, vous devez d'abord trouver son parent (n'importe quel sexe), puis le parent de ce parent (homme), etc.
Dans le panneau d'administration Bonsai, vous pouvez saisir les relations de ces trois types de base. L'inverse sera automatiquement créé pour chaque relation - parent pour enfant, conjoint pour conjoint, propriétaire pour animal de compagnie. Toutes les relations supplémentaires sont calculées par le moteur et affichées dans la barre latérale de la page:
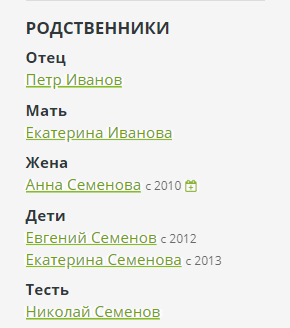
Pour calculer la relation, un parcours de graphe élémentaire est utilisé et les noms de relation sont définis sous la forme d'un DSL spécial:
public static RelationDefinition[] ParentRelations = { new RelationDefinition("Parent:m", ""), new RelationDefinition("Parent:f", ""), new RelationDefinition("Parent Child:m", "", ""), new RelationDefinition("Parent Child:f", "", ""), new RelationDefinition("Parent Parent:m", "", ""), new RelationDefinition("Parent Parent:f", "", "") };
Même une personne peut avoir de
nombreux parents directs. Bonsai divise les liens dans les groupes suivants:
- La relation de sang la plus proche est la famille dans laquelle la personne a grandi: mère et père, grands-parents, frères et sœurs. Si vous regardez le graphique, c'est le chemin 1-2 étapes vers le haut et 1 latéralement.
- Propre famille : un groupe pour chaque conjoint et ses enfants. Cela comprend également les proches du conjoint - belle-mère, beau-frère et autres.
- Autre : parents plus éloignés (petits-enfants, oncles, tantes) et liens de parenté (amis, collègues).
Parfois, une façon de déterminer l'appartenance à un groupe n'est pas suffisante. Les données peuvent être incomplètes, mais elles doivent encore être présentées de manière aussi adéquate que possible. Considérez le graphique frère suivant:
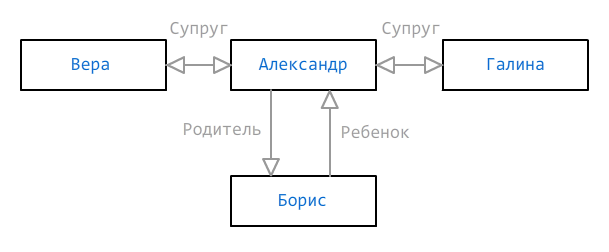
Comme nous le voyons, deux femmes (Vera et Galina) et un fils (Boris) sont indiqués pour Alexander, mais nous ne savons pas laquelle des femmes est la mère de l'enfant - c'est peut-être une sorte de troisième femme, mais elle n'a pas encore été ajoutée. Dans de tels cas, plusieurs chemins peuvent être indiqués qui devraient exister ou ne pas exister, et ils sont marqués respectivement par les signes
+ et
- :
new RelationDefinition("Spouse Child+Child", "||", "") new RelationDefinition("Spouse Child-Child:m", "") new RelationDefinition("Spouse Child-Child:f", "")
Arbre généalogique
Tout moteur de généalogie décent devrait pouvoir construire un arbre généalogique. C'est le moyen le plus visuel de montrer des informations générales sur les personnes et leurs relations familiales. Les données sont stockées dans la base de données sous la forme d'un graphique dirigé et, en théorie, elles devraient être faciles à visualiser. En pratique, c'est avec l'étalage de l'arbre que la plupart des difficultés sont apparues.
Voici quelques exemples de ce à quoi pourraient ressembler les arbres généalogiques:

Arbre généalogique de Targaryenov. Très compact, car il est fait à la main. La génération d'un tel arbre à partir de données arbitraires sera extrêmement difficile automatiquement.
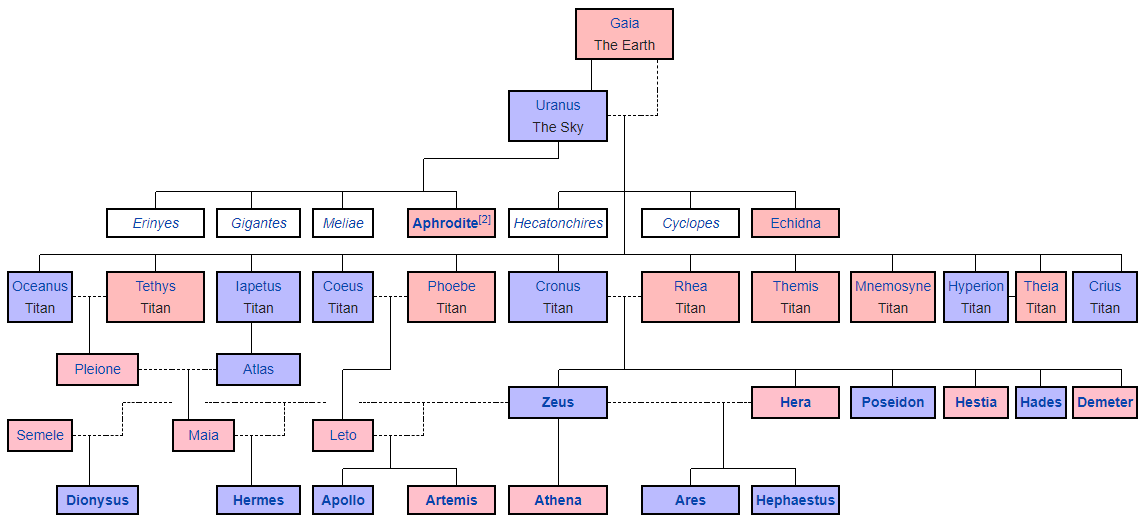
Dieux grecs. La représentation graphique est générée à partir d'une
syntaxe de démarque spéciale , dans laquelle vous devez toujours organiser manuellement tous les blocs et dessiner les liens entre eux. Un peu comme l'art ASCII.

Présentation d'un arbre sous forme de diagramme semi-circulaire. Généré facilement et automatiquement, mais ne prend en compte que les ancêtres directs.
J'ai examiné de nombreuses options. Le plus esthétique est sur le site MyHeritage:
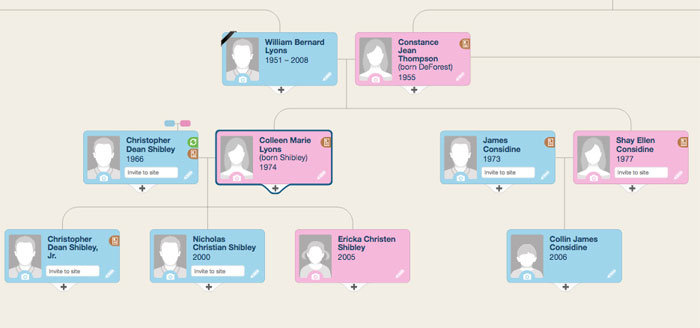
Le rendu d'un tel arbre peut être divisé en trois étapes conditionnelles: obtenir des données de la base de données, organiser des blocs / lignes de connexion et les afficher directement sur la page. Si tout était trivial avec les première et troisième étapes, alors dans la seconde j'ai trébuché.
Les tentatives de lancer une solution faite à la hâte se sont soldées par un fiasco complet. Un arrangement compétent des éléments graphiques est un domaine si complexe que les
dissertations sont écrites dessus, et les
composants finis sont comme un appartement à Moscou. D'accord, vous ne pourrez pas vous écrire, mais il existe sûrement des solutions gratuites décentes?
La plupart de mes espoirs étaient dans la
bibliothèque D3.js. C'est peut-être la première chose qui vous vient à l'esprit si vous devez dessiner un graphique ou un graphique sur une page Web. Hélas, parmi plus de trois cents (!) Exemples sur le wiki, il n'y en avait pas un de plus ou moins similaire à un arbre avec MyHeritage.
L'étape suivante consistait à plonger dans des bibliothèques qui n'étaient pas impliquées dans le rendu, mais dans le calcul de la disposition optimale des éléments dans le graphique. La plupart d'entre eux proposent ce que l'on appelle
la mise en page Force . Il s'agit d'une approche très simple, basée sur des formules physiques: les nœuds du graphe sont représentés par des corps élastiques, et les lignes de connexion sont représentées par des ressorts. Il peut être facilement reconnu par son animation caractéristique - le graphique semble "se redresser" en cours de route, et ce n'est pas une caractéristique supplémentaire, mais une conséquence inévitable de la nature de simulation de l'algorithme. L'approche force-layout est bonne pour visualiser des données sans hiérarchie claire (par exemple, les connexions dans les réseaux sociaux), mais l'arbre généalogique sous cette forme semble défectueux.
Une autre option envisagée est la bibliothèque
Graphviz . Le résultat de son travail peut être facilement reconnu par les flèches caractéristiques. Un langage spécial
DOT est utilisé pour décrire le graphique. Les cas de test semblent encore plus ou moins, mais des problèmes surviennent avec des données réelles: les flèches se "cassent" et se connectent à des angles étranges, le graphique grimpe et vous ne pouvez pas l'ajuster et vous ne pourrez pas le contourner.
N'ayant pas trouvé de solution adaptée par moi-même, j'ai décidé de la commander en freelance, puis le
DRAMA a commencé.
La commande a été passée dans la matinée du 22 octobre et en moins d'une heure, elle a reçu plusieurs réponses. L'un des répondants s'appelait Vladislav; il a envoyé un exemple d'une solution similaire et a promis de terminer la tâche en
une journée . Cette vitesse me paraissait suspecte, mais j'espérais son expérience et à moi-même donné au gars une erreur d'une semaine. Les premiers jours, Vladislav a posé des questions supplémentaires, sans cesse me surprendre par une immersion profonde dans le projet et une attitude attentive aux détails, puis il a disparu. Il s'est réveillé le 1er novembre, s'est excusé pour la disparition forcée pour des raisons familiales et a envoyé un lien avec une version bêta qui ressemblait assez à ce qu'il voulait s'il n'y avait pas le nœud dans les lignes de connexion au centre:
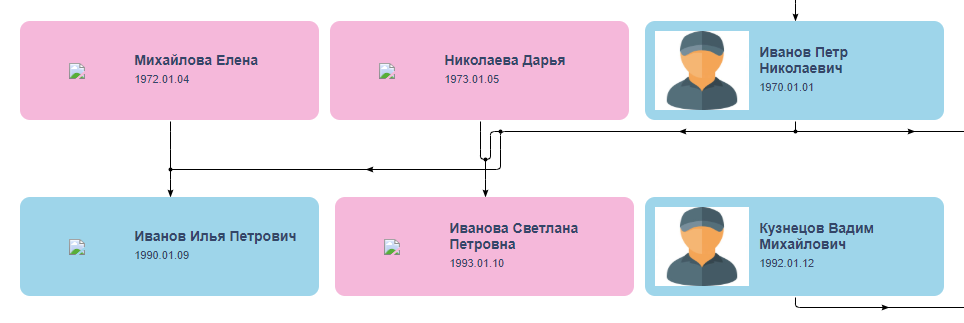
La disparition de l'interprète est toujours un réveil, mais on ne sait jamais, il se passe quelque chose, car il a fait quelque chose. Laissez-le continuer! J'ai envoyé un prépaiement et j'ai commencé à attendre des améliorations. Après quelques jours, Vladislav a écrit qu'il ne pouvait pas résoudre le problème, puis a de nouveau disparu - cette fois pendant trois semaines. Pendant ce temps, il n'a rien fait et a refusé de rembourser l'avance, car "la tâche a en fait été accomplie par un
stupide ex-ami qui l'a laissé tomber et n'a pas rendu son argent". Après quelques éclaircissements, le malheureux délégué a cessé d'essayer de s'excuser et s'est simplement tut. Alors maintenant, nous vivons - de temps en temps, je lui rappelle la dette, et en réponse, il envoie une capture d'écran de l'application bancaire - ils disent: "il n'y a pas d'argent, mais dès que - donc tout de suite". Je souhaite à Vladislav de réussir en affaires et de devenir riche plus rapidement!
Jeté l'enfant - moins dans le karma!Perdre de l'argent n'était pas si ennuyeux, mais un mois s'est écoulé, et la tâche n'a pas décollé, et maintenant il n'y avait nulle part où attendre de l'aide. Tout d'abord, j'étais en colère contre moi-même: j'ai pris le chemin de la moindre résistance, violé la
règle d'or - et voici le résultat. Rempli de colère juste, je me suis de nouveau assis pour étudier les bibliothèques pour dessiner des graphiques et - voilà! - soudainement trouvé exactement ce dont vous avez besoin.
La bibliothèque s'appelait
Eclipse Layout Kernel , en abrégé ELK. Comme vous pouvez le deviner, il est utilisé pour afficher des diagrammes dans l'IDE Eclipse, mais il peut également être utilisé de manière autonome. En général, il est écrit en Java, mais il existe une version diffusée en JS. Oui, son code est un
cauchemar et pèse un an et demi mégaoctets, mais ces lacunes peuvent être pardonnées pour le fait que cela
fonctionne et fait exactement la bonne chose. L'interface est élémentaire: les nœuds, les bords et les paramètres sont transmis à l'entrée, et à la sortie, nous obtenons les coordonnées. Vous pouvez dessiner un arbre en les utilisant de n'importe quelle manière pratique: j'ai choisi SVG pour relier les lignes et les divisions avec un positionnement absolu pour les blocs.
L'intégration de la bibliothèque et la sélection des paramètres optimaux ont pris deux nuits sur la force. Bien sûr, ce n'est pas «un jour», comme l'a promis mon pigiste malchanceux et arrogant, mais assez proche. En conséquence, Bonsai a pu afficher l'arbre sous cette forme approximative:
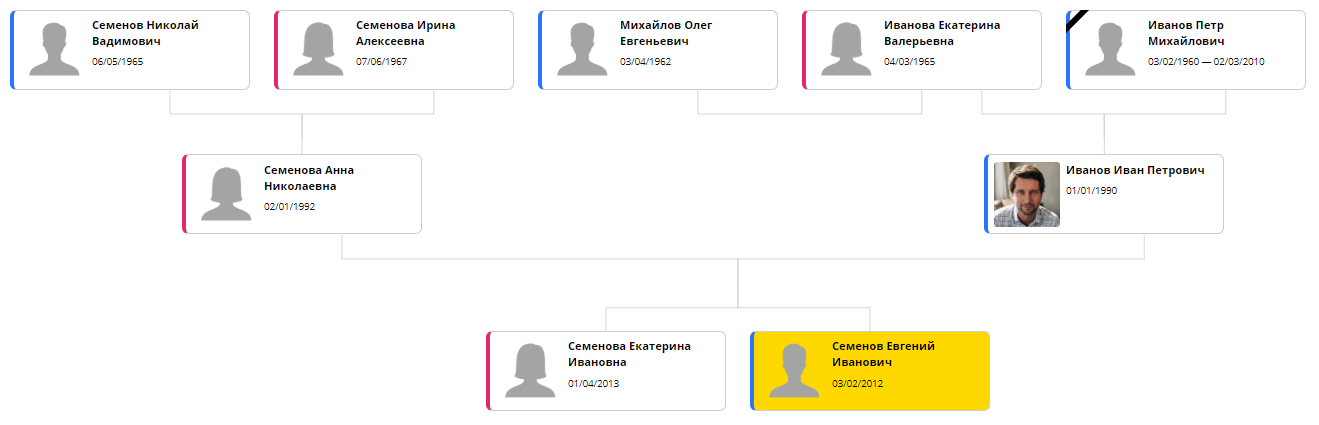
Maintenant, le seul problème qui reste est le temps de traitement. ELK utilise un algorithme itératif: vous pouvez vous rapprocher d'un placement optimal en passant du temps supplémentaire. Sur un arbre de 20-30 éléments, un bon résultat nécessite environ 5 secondes. Pour cette raison, une page avec un arbre s'ouvre à chaque fois pendant longtemps, et elle commence rapidement à ennuyer. Par la prochaine version, le calcul sera transféré au backend afin qu'il puisse être fait une fois lors du changement de page et de la mise en cache.
Recherche plein texte
Un système de stockage d'informations textuelles serait inutile sans une recherche en texte intégral pratique. Bonsai utilise la base de données PostgreSQL, donc la première chose que j'ai décidé a été de vérifier ce qu'il pouvait offrir dès le départ. Autre déception:
tsvector les mots ordinaires, mais refuse de rechercher la chose la plus importante - les noms et prénoms:
SELECT to_tsvector('') @@ to_tsquery(''),
Les trigrammes ne donnent rien de bon non plus. Au final, j'ai opté pour une option plutôt attendue: ElasticSearch +
Russian Morphology . Il s'est avéré très gênant de travailler avec .NET, cependant, il fait face à la recherche d'un cinq solide avec son nom complet.
Imperfection consciente
Lorsque l'on travaille sur un projet, des situations se produisent régulièrement lorsqu'un
perfectionniste interne est furieux de la solution choisie. Le sujet est plutôt atypique et les «bonnes manières» généralement acceptées ne fonctionnent pas toujours.
Par exemple, que se passe-t-il lorsque nous ouvrons une page?
- Le texte de la page est compilé de Markdown en HTML. Si le texte contient des liens vers d'autres pages et fichiers multimédias, vous devrez vous rendre dans la base de données pour plus d'informations.
- Les faits sont désérialisés du JSON dans lequel ils sont stockés dans la base de données, dans le modèle de vue.
- Les relations sont déterminées. Pour ce faire, à partir de la base de données qui souffre depuis longtemps, il est nécessaire d'obtenir l' intégralité du graphique de connexion et d'y trouver des nœuds selon une liste de chemins précédemment connue.
À première vue, cela semble être une opération terriblement difficile, mais en fait ce n'est pas à cause de la quantité relativement faible de données. De combien de parents vous souvenez-vous et voulez-vous écrire? Essayez de les raconter par intérêt et trouvez qu'il sera très difficile de composer au moins une centaine. Et combien de personnes veulent donner accès? Même un nombre astronomiquement élevé pour une famille, c'est mille personnes! - Selon les standards des bases de données modernes, cela reste ridicule.
Bien sûr, le modèle de vue de page compilé est toujours mis en cache la première fois qu'il est ouvert et réutilisé sur les modèles suivants, principalement parce qu'il était très facile à implémenter. La règle d'invalidation du cache pour les modifications dans le panneau d'administration est également prise aussi simple que possible: si nous ne modifions que le texte et certains faits
locaux (liste des langues, type de sang, couleur des cheveux, etc.), il suffit de réinitialiser cette page spécifique. Avec tout autre changement - nom de la page, date de naissance ou sexe, ajout ou modification d'une connexion - le cache est
complètement réinitialisé. Oui, ce n'est pas le moyen le plus intelligent de nettoyer. Oui, bien sûr, vous pourriez écrire un algorithme complexe qui ne réinitialiserait que ce dont vous avez besoin - mais pour ce projet, cela ne justifierait pas les coûts.
Le projet ne prend pas en charge la localisation et le changement d'apparence, l'autorisation fonctionne sur OAuth sur Facebook \ Google, et le panneau d'administration est fait sur les formulaires habituels, et pas sur un cadre SPA basé sur la dernière mode. Tout cela
pourrait être réalisé ou amélioré, mais cela n'aurait résolu aucun problème, et donc du temps aurait été perdu.
Un regard vers l'avenir
Une autre raison pour laquelle cela n'a aucun sens d'investir dans la complexité du dispositif moteur est la nature éphémère de la mise en œuvre par rapport aux données qu'il stocke. Réfléchissez un instant: le Web dans sa forme actuelle existe depuis près de vingt ans, et l'histoire de la famille existe depuis
des siècles . Personne n'a encore résolu ce problème simplement parce que l'industrie des technologies de l'information elle-même existe beaucoup moins. Que peut-on faire?
Le moteur devra être réécrit régulièrement à partir de zéro - tout comme pendant des milliers d'années, les moines ont été durs pour copier des textes de livres délabrés vers de nouveaux. La seule différence est que le livre peut mentir cent ans avec une bonne manipulation et l'application - sur la force de 15-20 ans. J'espère que dans vingt ans, je pourrai encore le faire moi-même, mais dans vingt ans, mes enfants ou petits-enfants devront le faire. Je voudrais leur laisser une source simple, compréhensible et documentée.
Aux toutes premières étapes de la conception, j'ai voulu intégrer un certain langage de type SQL dans le moteur, à l'aide duquel j'ai pu obtenir des réponses à des questions spécifiques: «quel est le pourcentage de mes ancêtres aux yeux bleus», «quand Ivan a acheté la première voiture» et ainsi de suite. Cette idée a dû être abandonnée car il faudrait au lieu du texte brut entrer toutes les informations sous une forme formalisée, et seule une description de ce type prendrait des années. D'un autre côté, la compréhension du langage naturel prend de l'ampleur. Je ne serai pas surpris si dans dix ou deux ans il sera possible de demander à Siri de lire le texte pour vous, de suivre les liens et, par conséquent, de présenter un extrait des faits. Les gars, poussez!
Comment essayer?
Malheureusement, je ne peux pas fournir de lien vers la démo terminée: aucun serveur ne peut résister à l’effet habra. Mais il y a quelques captures d'écran visuelles (les images sont cliquables).
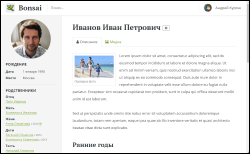

Si Bonsai vous a semblé utile et que vous souhaitez l'exécuter vous-même, le code source peut être téléchargé depuis Github:
https://github.com/impworks/bonsaiDes instructions d'installation détaillées sont fournies dans le fichier Lisez-moi. Vous en aurez besoin:
- .NET Core 2.1+
- PostgreSQL 10+
- ElasticSearch 5.x et le plugin russe de morphologie
- Application Facebook ou Google pour l'autorisation oAuth
Après le premier lancement, plusieurs pages de test et photos sont créées dans la base de données. Pour la production, ce comportement n'est pas nécessaire et est désactivé par l'indicateur dans les paramètres.
Il y a tout juste un mois, j'ai lancé ma propre instance et j'ai commencé à l'exécuter, obtenant des données réelles. Une certaine rugosité est rencontrée, mais sinon je suis complètement satisfait du résultat. Maintenant, le projet sera progressivement développé et finalisé. Les tâches principales consistent à accélérer l'affichage de l'arborescence, à permettre le téléchargement de documents sous forme de PDF et à affiner les droits d'accès. Ce serait bien d'améliorer la convivialité du panneau d'administration à certains endroits ou de reconnaître automatiquement les visages sur la photo -
mais ce n'est pas exact .