
Dans l'article précédent, nous avons parlé d'un problème d'apprentissage automatique tel que les exemples contradictoires et certains types d'attaques qui permettent de les générer. Cet article se concentrera sur les algorithmes de protection contre ce type d'effet et les recommandations pour tester les modèles.
La protection
Tout d'abord, expliquons immédiatement un point - il est impossible de se défendre complètement contre un tel effet, et c'est tout à fait naturel. En effet, si nous résolvions complètement le problème des exemples contradictoires, nous résoudrions simultanément le problème de la construction d'un hyperplan idéal, ce qui, bien sûr, ne peut se faire sans un ensemble de données générales.
La défense d'un modèle d'apprentissage automatique se déroule en deux étapes:
Apprentissage - Nous enseignons à notre algorithme à répondre correctement aux exemples contradictoires.
Fonctionnement - nous essayons de détecter un exemple contradictoire pendant la phase de fonctionnement du modèle.
Il vaut la peine de dire tout de suite que vous pouvez utiliser les méthodes de protection présentées dans cet article à l'aide de IBM Adversarial Robustness Toolbox .
Formation contradictoire

Si vous demandez à une personne qui vient de se familiariser avec le problème contradictoire avec des exemples, la question: «Comment vous protéger de cet effet?», Alors certainement 9 personnes sur 10 diront: «Ajoutons les objets générés à l'ensemble de formation». Cette approche a été immédiatement proposée dans l'article Intriguing properties of neural networks en 2013. C'est dans cet article que ce problème a été décrit pour la première fois et l'attaque L-BFGS, qui permet de recevoir des exemples contradictoires.
Cette méthode est très simple. Nous générons des exemples contradictoires en utilisant différents types d'attaques et les ajoutons à l'ensemble de formation à chaque itération, augmentant ainsi la «résistance» du modèle contradictoire aux exemples.
L'inconvénient de cette méthode est assez évident: à chaque itération de la formation, pour chaque exemple, nous pouvons générer un très grand nombre d'exemples, respectivement, et le temps de modélisation de la formation augmente de nombreuses fois.
Vous pouvez appliquer cette méthode à l'aide de la bibliothèque ART-IBM comme suit.
from art.defences.adversarial_trainer import AdversarialTrainer trainer = AdversarialTrainer(model, attacks) trainer.fit(x_train, y_train)
Augmentation des données gaussiennes
La méthode suivante, décrite dans l'article Efficient Defenses Against Adversarial Attacks , utilise une logique similaire: elle suggère également d'ajouter des objets supplémentaires à l'ensemble d'entraînement, mais contrairement à Adversarial Training, ces objets ne sont pas des exemples contradictoires, mais des objets d'ensemble d'entraînement légèrement bruyants (le gaussien est utilisé comme bruit). bruit, d'où le nom de la méthode). Et, en effet, cela semble très logique, car le principal problème des modèles est précisément leur faible immunité au bruit.
Cette méthode montre des résultats similaires à la formation contradictoire, tout en passant beaucoup moins de temps à générer des objets pour la formation.
Vous pouvez appliquer cette méthode à l'aide de la classe GaussianAugmentation dans ART-IBM
from art.defences.gaussian_augmentation import GaussianAugmentation GDA = GaussianAugmentation() new_x = GDA(x_train)
Lissage des étiquettes
La méthode de lissage d'étiquette est très simple à mettre en œuvre, mais comporte néanmoins beaucoup de sens probabiliste. Nous n'entrerons pas dans les détails de l'interprétation probabiliste de cette méthode; vous pouvez la trouver dans l'article original Repenser l'architecture de démarrage pour la vision par ordinateur . Mais, pour le dire brièvement, le lissage d'étiquette est un type supplémentaire de régularisation du modèle dans le problème de classification, ce qui le rend plus résistant au bruit.
En fait, cette méthode lisse les étiquettes de classe. Les faire, disons, non pas 1, mais 0,9. Ainsi, les modèles de formation sont condamnés à une amende pour une "confiance" beaucoup plus grande dans l'étiquette d'un objet particulier.
L'application de cette méthode en Python peut être vue ci-dessous.
from art.defences.label_smoothing import LabelSmoothing LS = LabelSmoothing() new_x, new_y = LS(train_x, train_y)
Relu borné
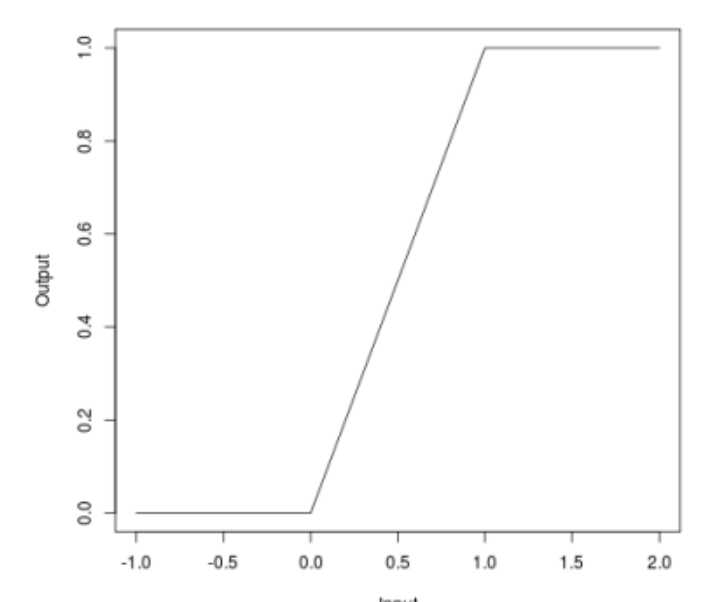
Lorsque nous avons parlé d'attaques, beaucoup ont pu remarquer que certaines attaques (JSMA, OnePixel) dépendent de la force du gradient à un moment ou à un autre de l'image d'entrée. La méthode simple et «bon marché» (en termes de coûts de calcul et de temps) de Bounded ReLU tente de résoudre ce problème.
L'essence de la méthode est la suivante. Remplaçons la fonction d'activation de ReLU dans un réseau de neurones par la même, qui est limitée non seulement par le bas, mais aussi par le haut, lissant ainsi les cartes de gradient, et à des points spécifiques, il ne sera pas possible d'obtenir un splash, ce qui ne vous permettra pas de tromper l'algorithme en changeant un pixel de l'image.
\ begin {équation *} f (x) =
\ begin {cases}
0, x <0
\\
x, 0 \ leq x \ leq t
\\
t, x> t
\ end {cases}
\ end {équation *}
Cette méthode a également été décrite dans l'article Efficient Defenses Against Adversarial Attacks
Building Model Ensembles
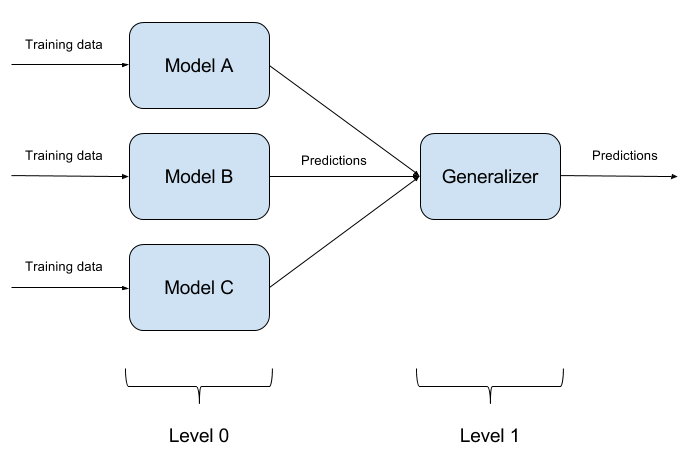
Il n'est pas difficile de tromper un modèle formé. Tromper deux modèles en même temps avec un même objet est encore plus difficile. Et s'il y a N de tels modèles? C'est sur cette base que repose la méthode d'ensemble des modèles. Nous construisons simplement N modèles différents et agrégons leur sortie en une seule réponse. Si les modèles sont également représentés par différents algorithmes, alors il est extrêmement difficile de tromper un tel système, mais c'est extrêmement difficile!
Il est tout à fait naturel que la mise en place d'ensembles de modèles soit une approche purement architecturale, posant beaucoup de questions (Quels modèles de base prendre? Comment agréger les sorties des modèles de base? Y a-t-il une relation entre les modèles? Et ainsi de suite). Pour cette raison, cette approche n'est pas implémentée dans ART-IBM
Fonctionnalité de compression
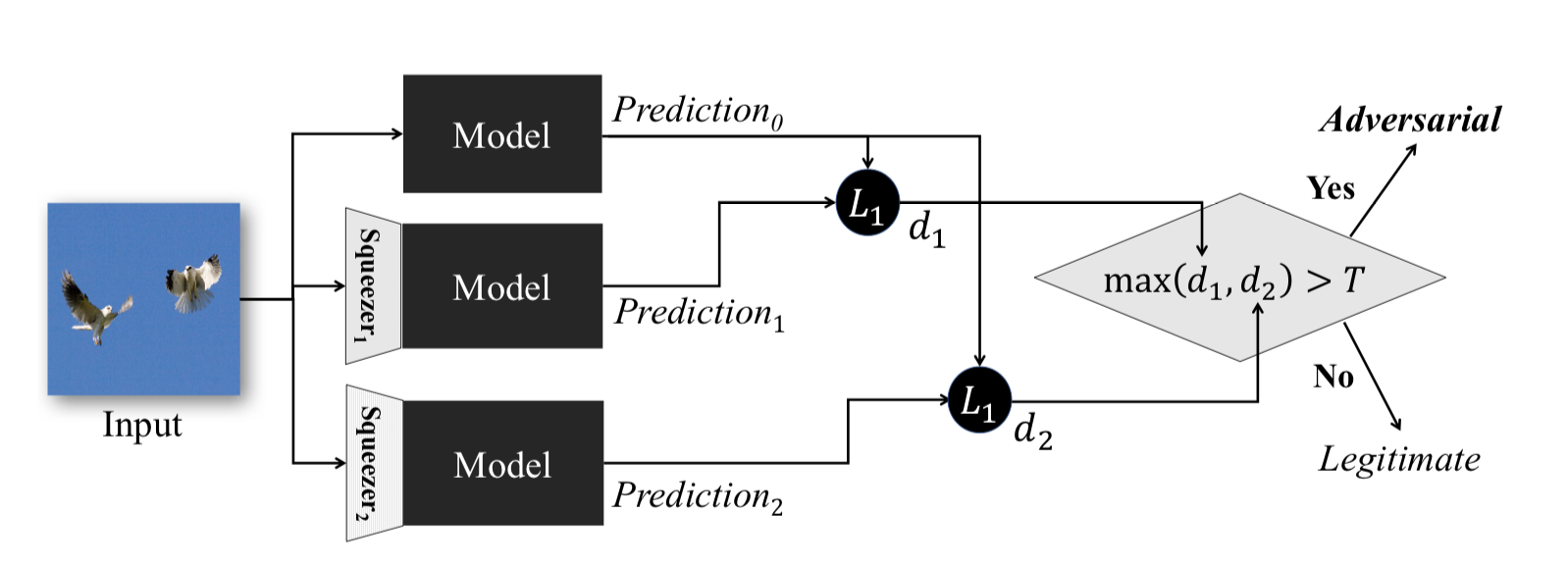
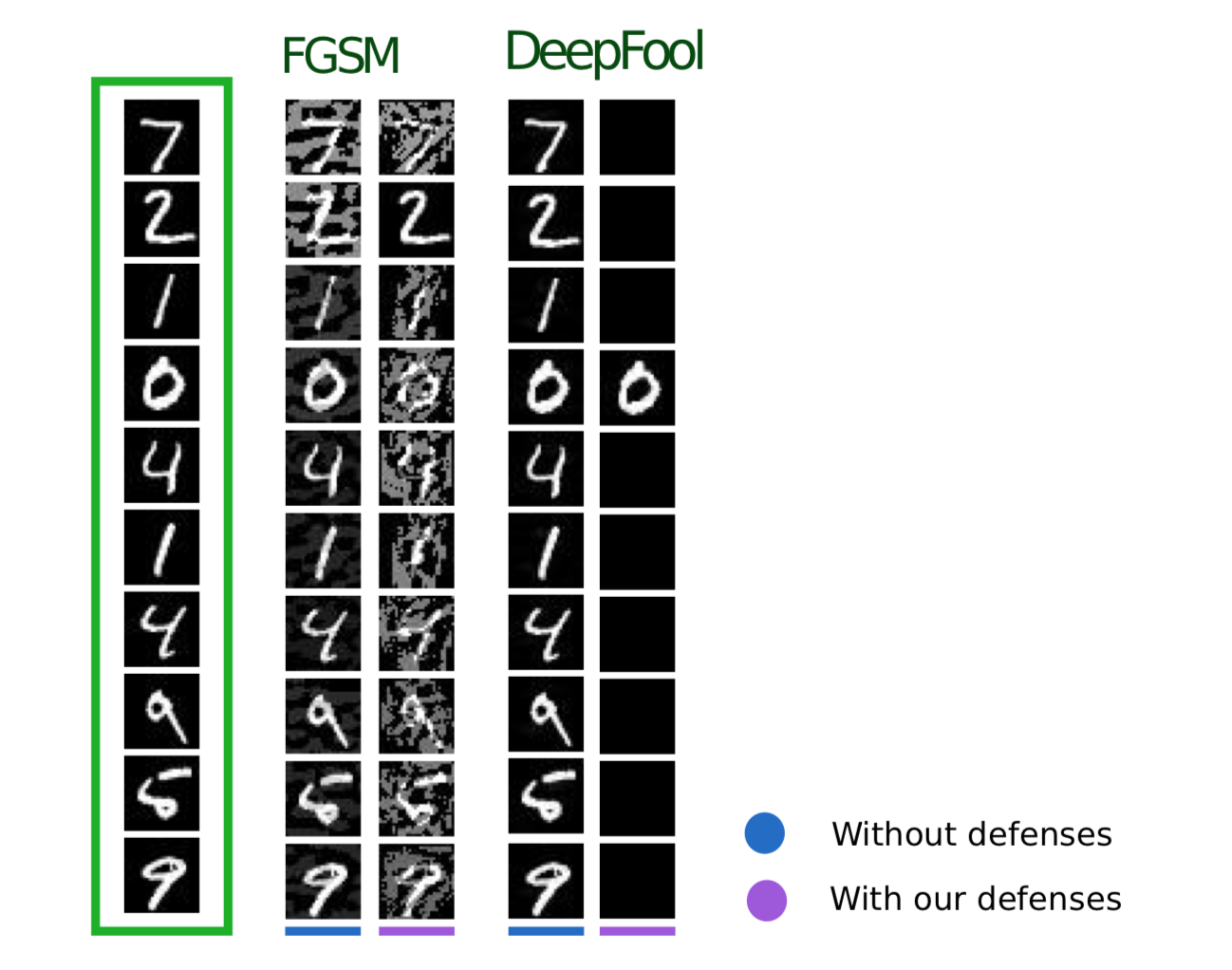
Cette méthode, décrite dans Feature Squeezing: Detecting Adversarial Exemples in Deep Neural Networks , fonctionne pendant la phase opérationnelle du modèle. Il vous permet de détecter des exemples contradictoires.
L'idée derrière cette méthode est la suivante: si vous entraînez n modèles sur les mêmes données, mais avec des taux de compression différents, les résultats de leur travail seront toujours similaires. Dans le même temps, l'exemple Adversarial, qui fonctionne sur le réseau source, échouera très probablement sur des réseaux supplémentaires. Ainsi, compte tenu de la différence par paire entre les sorties du réseau neuronal initial et celles supplémentaires, en choisissant le maximum parmi elles et en le comparant avec un seuil présélectionné, nous pouvons affirmer que l'objet d'entrée est soit contradictoire soit absolument valide.
Voici une méthode pour obtenir des objets compressés à l'aide de ART-IBM
from art.defences.feature_squeezing import FeatureSqueezing FS = FeatureSqueezing() new_x = FS(train_x)
Nous terminerons avec les méthodes de protection. Mais il serait faux de ne pas saisir un point important. Si un attaquant n'a pas accès aux entrées et sorties du modèle, il ne comprendra pas comment les données brutes sont traitées à l'intérieur de votre système avant d'entrer dans le modèle. Alors et seulement alors, toutes ses attaques seront réduites au tri aléatoire des valeurs d'entrée, ce qui est naturellement peu susceptible de conduire au résultat souhaité.
Test
Parlons maintenant des tests d'algorithmes pour contrer les exemples contradictoires. Ici, tout d'abord, il est nécessaire de comprendre comment nous allons tester notre modèle. Si nous supposons que l'attaquant peut accéder de manière complète à l'intégralité du modèle, il est nécessaire de tester notre modèle à l'aide des méthodes d'attaque WhiteBox.
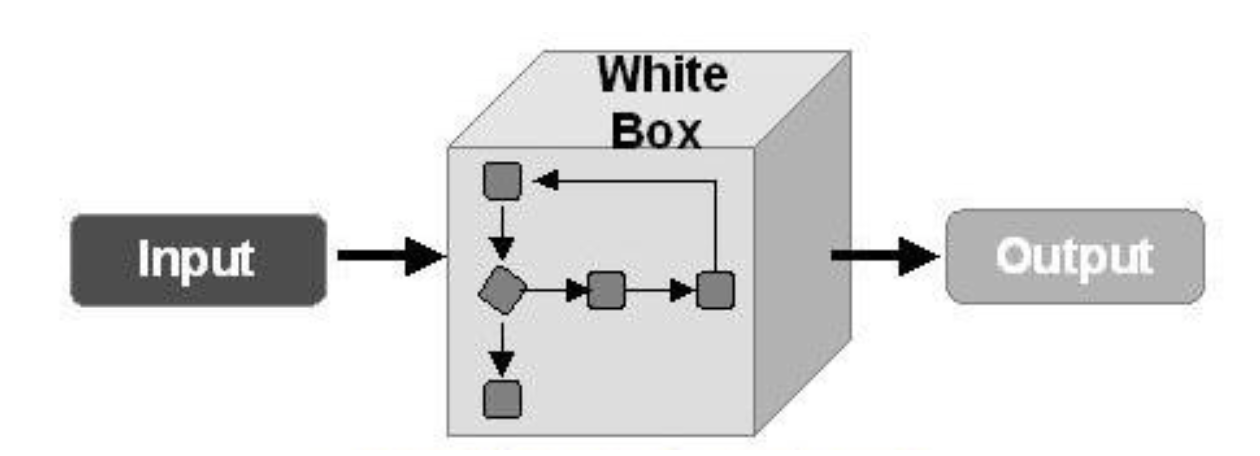
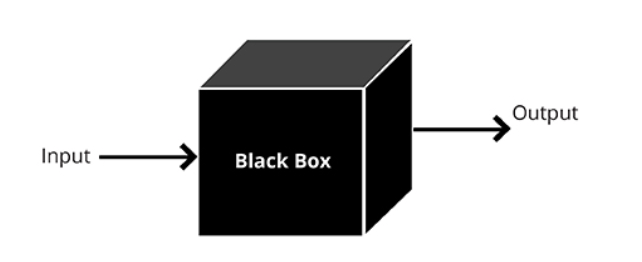
Dans un autre cas, nous supposons qu'un attaquant n'aura jamais accès aux "entrailles" de notre modèle, mais il pourra, quoique indirectement, influencer les données d'entrée et voir le résultat du modèle. Ensuite, vous devez appliquer les méthodes d'attaques BlackBox.
L'algorithme de test général peut être décrit avec l'exemple suivant:
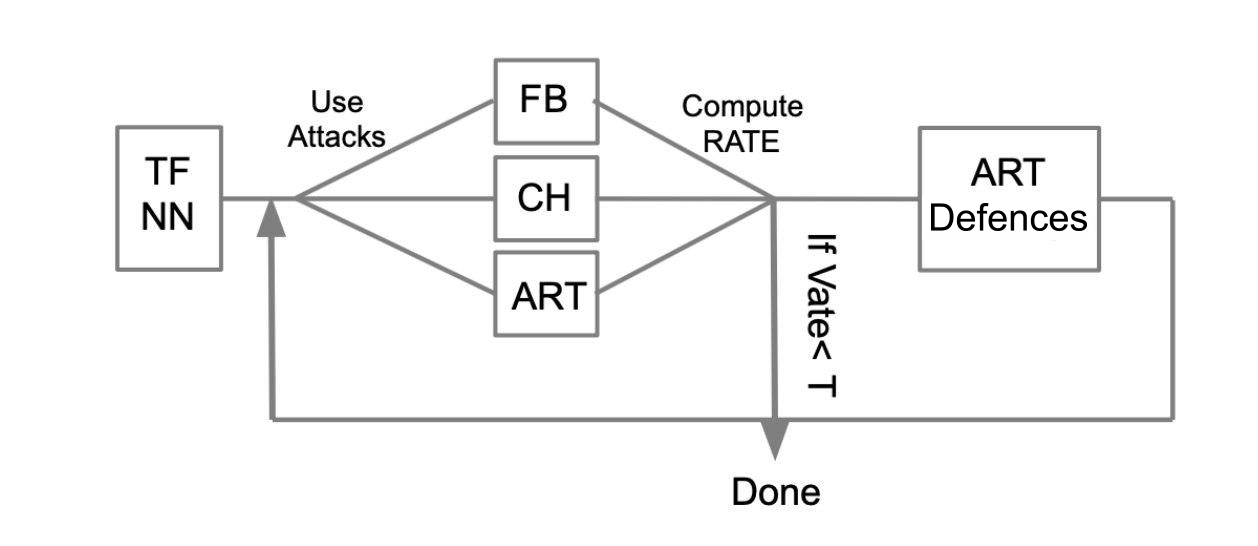
Soit un réseau neuronal formé écrit en TensorFlow (TF NN). Nous affirmons de manière experte que notre réseau peut tomber entre les mains d'un attaquant en pénétrant dans le système où se trouve le modèle. Dans ce cas, nous devons effectuer des attaques WhiteBox. Pour ce faire, nous définissons un pool d'attaques et des frameworks (FoolBox - FB, CleverHans - CH, Adversarial robustness toolbox - ART) qui permettent de mettre en œuvre ces attaques. Ensuite, en comptant le nombre d'attaques réussies, nous calculons le taux de réussite (SR). Si SR nous convient, nous terminons les tests, sinon nous utilisons l'une des méthodes de protection, par exemple, mises en œuvre dans ART-IBM. Ensuite, nous menons des attaques et considérons SR. Nous faisons cette opération de façon cyclique, jusqu'à ce que SR nous convienne.
Conclusions
Je voudrais terminer ici avec des informations générales sur les attaques, les défenses et les tests de modèles d'apprentissage automatique. En résumant les deux articles, nous pouvons conclure ce qui suit:
- Ne croyez pas au machine learning comme une sorte de miracle qui peut résoudre tous vos problèmes.
- Lorsque vous appliquez des algorithmes d'apprentissage automatique dans vos tâches, pensez à la résistance de cet algorithme à une telle menace que les exemples contradictoires.
- Vous pouvez protéger l'algorithme à la fois du côté de l'apprentissage automatique et du côté du système dans lequel ce modèle est utilisé.
- Testez vos modèles, en particulier dans les cas où le résultat du modèle affecte directement la décision
- Des bibliothèques telles que FoolBox, CleverHans, ART-IBM fournissent une interface pratique pour attaquer et défendre les modèles d'apprentissage automatique.
Dans cet article, je voudrais également résumer le travail avec les bibliothèques FoolBox, CleverHans et ART-IBM:
FoolBox est une bibliothèque simple et compréhensible pour attaquer les réseaux de neurones, prenant en charge de nombreux cadres différents.
CleverHans est une bibliothèque qui vous permet de mener des attaques en modifiant de nombreux paramètres de l'attaque, un peu plus compliqué que FoolBox, supporte moins de frameworks.
ART-IBM est la seule bibliothèque de ce qui précède qui vous permet de travailler avec des méthodes de sécurité, jusqu'à présent, elle ne prend en charge que TensorFlow et Keras, mais elle se développe plus rapidement que les autres.
Ici, il convient de dire qu'il existe une autre bibliothèque pour travailler avec des exemples contradictoires de Baidu, mais, malheureusement, elle ne convient qu'aux personnes qui parlent chinois.
Dans le prochain article sur ce sujet, nous analyserons une partie de la tâche qui devait être résolue lors de ZeroNights HackQuest 2018 en trompant un réseau neuronal typique à l'aide de la bibliothèque FoolBox.