Le modèle Infrastructure as a Code (IaC), parfois appelé «infrastructure programmable», est un modèle par lequel le processus de configuration de l'infrastructure est similaire au processus de programmation logicielle. Essentiellement, cela a marqué le début de la suppression des frontières entre l'écriture d'applications et la création d'environnements pour ces applications. Les applications peuvent contenir des scripts qui créent et gèrent leurs propres machines virtuelles. C'est le fondement du cloud computing et une partie intégrante de DevOps.
L'infrastructure en tant que code vous permet de gérer des machines virtuelles au niveau logiciel. Cela élimine le besoin de configuration manuelle et de mises à jour pour les composants d'équipement individuels. L'infrastructure devient extrêmement «résiliente», c'est-à-dire reproductible et évolutive. Un opérateur peut déployer et gérer à la fois une et 1000 machines en utilisant le même ensemble de code. Parmi les avantages garantis de l'infrastructure comme le code, citons la rapidité, la rentabilité et la réduction des risques.
C'est exactement le sujet du décodage du rapport de Kirill Vetchinkin à DevOpsDays Moscou 2018. Le rapport: réutilisation des modules Ansible, stockage dans Git, révision, reconstruction, avantages financiers, mise à l'échelle horizontale en 1 clic.
Peu importe, s'il vous plaît, sous le chat.
Bonjour à tous. Comme je l'ai déjà dit, je suis Vetchinkin Kirill. Je travaille chez TYME et aujourd'hui nous parlerons de l'infrastructure en tant que code. Nous parlerons également de la façon dont nous avons appris à économiser sur cette pratique, car elle coûte assez cher. Écrire beaucoup de code coûte assez cher pour configurer l'infrastructure.
Je vais parler brièvement de l'entreprise. Je travaille chez TYME. Nous avons changé de marque. Maintenant, nous nous appelons PaySystem - comme son nom l'indique, nous sommes engagés dans des systèmes de paiement. Nous avons nos propres solutions - ce sont les traitements et le développement personnalisé. Le développement personnalisé est la banque électronique, la facturation, etc. Et comme vous le savez, s'il s'agit d'un développement personnalisé, il s'agit d'un grand nombre de projets chaque année. Le projet va après le projet. Plus il y a de projets, plus il faut augmenter l'infrastructure du même type. Les projets étant souvent lourdement chargés, nous utilisons une architecture de microservice. Par conséquent, dans un projet, il y a beaucoup, beaucoup de petits sous-projets.

Par conséquent, la gestion de tout ce zoo sans DevOps complet est très difficile. Par conséquent, notre entreprise a mis en œuvre diverses pratiques DevOps. Naturellement, nous travaillons sur le kanban, sur SCRUM, nous stockons tout dans git. Après validation, l'intégration est continue, les tests sont exécutés. Les testeurs écrivent des tests de bout en bout sur PyTest qui commencent tous les soirs. Le test unitaire démarre après chaque validation. Nous utilisons un processus de construction et de déploiement distinct: assemblé, puis déployé plusieurs fois dans divers environnements. Nous étions aux fenêtres. Sur les fenêtres que nous avons déployées en utilisant Octopus deploy, nous développons cette année sur DotNet Core. Par conséquent, nous pouvons désormais exécuter des logiciels sur des systèmes Linux. Nous avons quitté Octopus et sommes venus à Ansible. Aujourd'hui, nous allons parler de cette partie, qui est une nouvelle pratique que nous avons développée cette année, quelque chose que nous n'avions pas auparavant. Lorsque vous avez des tests, quand vous savez comment bien construire l'application, le déployer quelque part est très bien. Mais si vous avez deux environnements configurés différemment, alors vous tomberez et tomberez en production. Par conséquent, la gestion des configurations est une pratique très importante. C'est de cela que nous allons parler aujourd'hui.

Je vais vous expliquer brièvement comment l'économie du travail du produit est construite: 60 % sont consacrés au développement , l' analyse prend environ 10 %, le contrôle qualité (tests) prend environ 20 % et tout le reste est alloué à la configuration. Lorsque les systèmes fonctionnent à plein régime, ils disposent de nombreux logiciels tiers, les systèmes d'exploitation eux-mêmes sont configurés presque de la même manière. Nous passons plus de temps à faire cela, essentiellement à faire la même chose. Il y avait une idée pour automatiser tout et réduire le coût de configuration de l'infrastructure. Des tâches similaires sont automatisées, bien déboguées et ne contiennent pas d'opérations manuelles.

Chaque application fonctionne dans une sorte d'environnement. Voyons de quoi il s'agit. Au minimum, nous devons avoir un système d'exploitation , il doit être configuré, il y a des applications tierces qui doivent également être configurées, l'application elle-même doit recevoir les configurations, mais pour que tout le produit fonctionne, l'application elle-même doit démarrer, qui fonctionne dans tout ce système. Il existe également un réseau qui doit également être configuré, mais nous ne parlerons pas du réseau aujourd'hui, car nous avons différents clients, différents périphériques réseau. Nous avons également essayé d'automatiser la configuration du réseau, mais comme les appareils sont différents, cela ne présentait aucun avantage particulier, nous avons consacré plus de ressources à cela. Mais nous avons automatisé les systèmes d'exploitation, les applications tierces et le transfert des paramètres de configuration aux applications elles-mêmes.

Il existe deux approches pour configurer les serveurs: avec vos mains - si vous les configurez avec vos mains, vous pouvez en conséquence obtenir une situation telle que votre production est configurée d'une manière, le test est différent, le test est vert, les tests sont verts. Vous déployez en production, et il n'y a pas de cadre là-bas - rien ne fonctionne pour vous. Autre exemple: trois serveurs d'applications sont configurés à la main. Un serveur d'applications a été configuré d'une manière, un autre serveur d'applications d'une manière différente. Les serveurs peuvent fonctionner de différentes manières. Autre exemple: il y a eu une situation où un serveur Stage a complètement cessé de fonctionner pour nous. Nous avons commencé à créer un nouveau serveur en utilisant et après 30 le serveur était prêt. Autre exemple: le serveur vient de cesser de fonctionner. Si vous le configurez avec vos mains, vous devez rechercher une personne qui sait comment le configurer, vous devez augmenter la documentation. Comme nous le savons, la documentation n'est guère pertinente. Ce sont de gros problèmes. Et, plus important encore, il s'agit d'un audit, c'est-à-dire qu'en gros, vous avez dix administrateurs, chacun d'eux configure quelque chose avec ses mains, il n'est pas très clair s'ils l'ont configuré correctement ou incorrectement, et comment comprendre si puis les paramètres, ils pourraient mettre quelque chose de superflu, ouvrir des ports inutiles.

Il existe une option alternative - c'est exactement ce dont nous parlons aujourd'hui - c'est la configuration à partir du code. Autrement dit, nous avons un référentiel git dans lequel toute l'infrastructure est stockée. Tous les scripts y sont stockés, à l'aide desquels nous allons le configurer. Comme tout est dans git, nous bénéficions de tous les avantages de la gestion de code, comme dans le développement, c'est-à-dire que nous pouvons faire des révisions, des audits, l'historique des modifications, qui l'a fait, pourquoi l'a fait, des commentaires, nous pouvons revenir en arrière. Pour travailler avec le code, vous devez utiliser le pipeline d'assemblage continu - le pipeline de déploiement. Pour qu'un système particulier apporte des modifications aux serveurs, c'est-à-dire que personne ne ferait quelque chose avec ses mains, mais le système le ferait exclusivement.

En tant que système qui effectue les modifications, nous utilisons Ansible. Comme nous n'avons pas un grand nombre de serveurs, il nous convient parfaitement. Si vous avez 100 à 200 serveurs là-bas, vous aurez de petits problèmes, car il (c'est-à-dire Ansible) se connecte toujours à chacun et les configure à son tour - c'est un problème. Il vaut mieux utiliser d'autres moyens qui ne poussent pas, mais tirent. Mais pour notre histoire, lorsque nous avons de nombreux projets, mais pas plus de 20 serveurs, cela nous convient parfaitement. Ansible a un gros plus - c'est un seuil d'entrée bas. Autrement dit, n'importe quel spécialiste informatique en trois semaines peut parfaitement le maîtriser. Il a beaucoup de modules. Autrement dit, vous pouvez gérer les nuages, les réseaux, les fichiers, l'installation de programmes, déployer - absolument tout. S'il n'y a pas de modules, vous pouvez écrire les vôtres, vous pouvez enfin écrire quelque chose en utilisant le shell Ansible ou le module de commande.

En général, nous examinerons brièvement à quoi il ressemble généralement, cet outil. Ansible a des modules dont j'ai déjà parlé. Autrement dit, ils peuvent être livrés, écrits par eux-mêmes, qui font quelque chose. Il y a des inventaires - c'est là que nous effectuerons nos modifications, c'est-à-dire que ce sont les hôtes, leurs adresses IP, les variables spécifiques à ces hôtes. Et, en conséquence, le rôle. Les rôles sont ce que nous déploierons sur ces serveurs. Et nos hôtes sont également regroupés en groupes, c'est-à-dire que dans ce cas, nous voyons que nous avons deux groupes: le serveur de base de données et le serveur d'applications. Dans chaque groupe, nous avons trois voitures. Ils sont connectés via ssh. Ainsi, nous résolvons les problèmes dont nous avons parlé plus tôt, à savoir qu'en premier lieu nos serveurs sont configurés de manière identique, car le même rôle se déploie sur les serveurs. Et de la même manière, si nous exécutons ce rôle sur plusieurs machines, alors pour chacune, cela fonctionnera de la même manière.
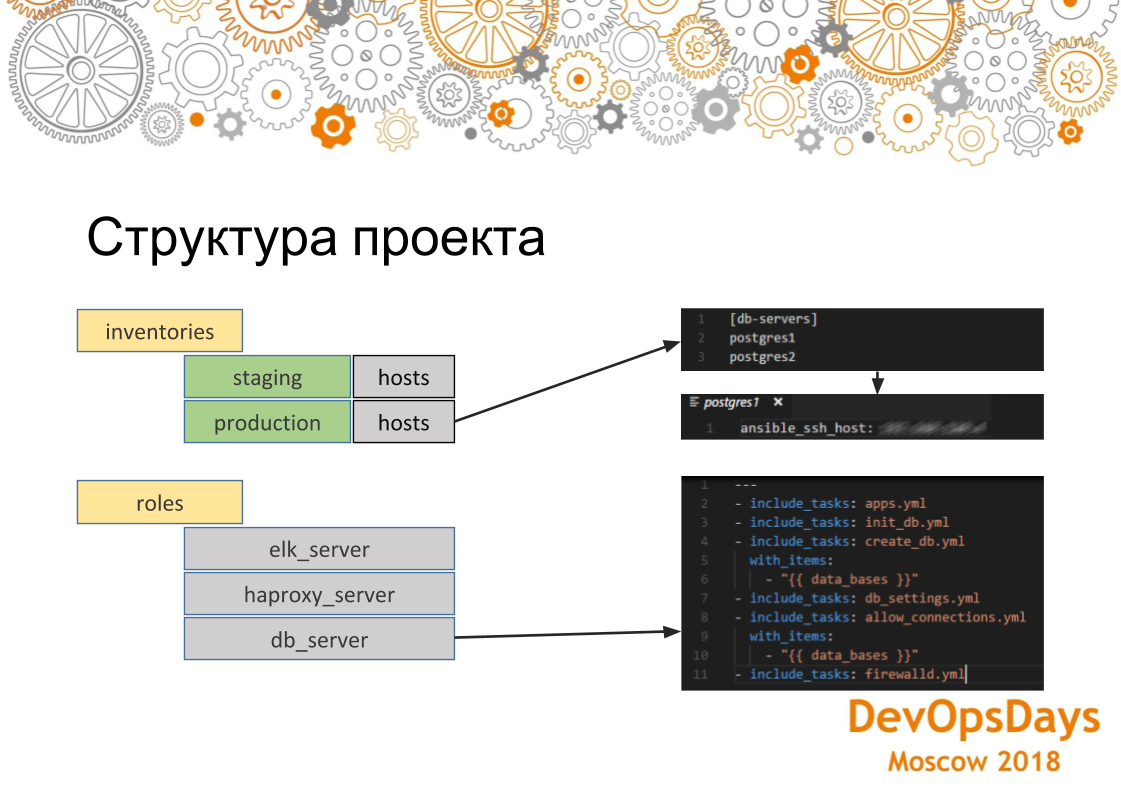
Si nous examinons de plus près la structure du projet Ansible, nous voyons ici que les hôtes sont acceptables pour les inventaires de production. Ce groupe est indiqué et contient deux serveurs. Si nous allons sur un serveur spécifique, nous voyons que l'adresse IP de cette machine est indiquée ici. D'autres paramètres peuvent également y être indiqués - variables spécifiques à cet environnement. Si nous regardons les rôles. Ce rôle contient plusieurs tâches qui seront exécutées. Dans ce cas, il s'agit du rôle d'installation de PostgreSQL. Autrement dit, nous installons l'application nécessaire, créons la base de données. Ici, nous utilisons une boucle. Ils (bases de données) seront un peu créés. Ensuite, nous établissons la connexion nécessaire - les adresses IP qui peuvent se connecter à cette base de données. Et, en conséquence, nous configurons à la toute fin du pare-feu. Les paramètres seront appliqués à tous les serveurs du groupe.

Abordez le problème lui-même: nous avons appris à configurer le serveur à l'aide d'Ansible et tout allait bien. Mais, comme je l'ai dit, nous avons de nombreux projets. Ils sont presque tous pareils. Certains de ces systèmes sont impliqués dans chaque projet (k8s, RabbitMQ, Vault, ELK, PostgreSQL, HAProxy). Pour chacun, nous avons écrit un rôle. Nous pouvons le faire rouler à partir du bouton.

Mais nous avons de nombreux projets, et dans chacun, ils se chevauchent essentiellement. C'est-à-dire, dans un tel ensemble, dans le second tel, dans le troisième tel. Nous obtenons des points d'intersection dans lesquels les mêmes rôles dans différents projets.

Nous avons un référentiel avec une application, nous avons un référentiel avec une infrastructure pour le projet. Le deuxième projet a exactement la même chose. Infrastructure continue. Et le troisième. Si nous implémentons la même chose, le copier-coller se révélera essentiellement. Nous jouerons le même rôle dans 10 endroits. Ensuite, s'il y a une erreur, nous régnerons en 10 endroits.

Ce que nous avons fait: nous avons pris chaque rôle commun à tous les projets et toutes ses configurations qui viennent de l'extérieur vers un référentiel séparé et les avons placés dans un git dans un dossier séparé - nous avons appelé TYME Infrastructure. Nous avons là un rôle pour PostgreSQL, pour ELK, pour le déploiement de clusters Kubernetes. Si nous avons besoin de mettre dans un projet, disons le même PostgreSQL, puis allumez-le simplement comme un sous-module, réécrivez les inventaires, c'est-à-dire, en gros, la configuration où rouler ce rôle. Nous ne réécrivons pas le rôle lui-même: il existe déjà. Et d'un simple clic, PostgreSQL apparaît dans tous les nouveaux projets. Si vous devez augmenter un cluster Kubernetes - la même chose.

Ainsi, il s'est avéré réduire le coût d'écriture des rôles. Autrement dit, ils ont écrit une fois - ils l'ont utilisé 10 fois. Lorsque le projet va après le projet - c'est très pratique. Mais comme nous travaillons maintenant avec l'infrastructure en tant que code, nous avons naturellement besoin des pipelines dont nous avons parlé. Les gens s'engagent dans git, ils peuvent commettre une sorte d'inexactitude - nous devons suivre tout cela. Par conséquent, nous avons construit un tel pipeline. Autrement dit, le développeur valide les scripts Ansible dans git. Teamity les suit et les transfère à Ansible. Teamcity n'est nécessaire ici que pour une raison: premièrement, il a une interface visuelle (il existe une version gratuite d'Ansible Tower - AWX, qui résout le même problème - environ)., Contrairement à Ansible, gratuit et, en principe, nous avons Teamcity comme un seul Ci. Donc, en principe, Ansible a un module qui peut lui-même suivre git. Mais dans ce cas, ils l'ont fait à l'image et à la ressemblance. Et dès qu'il l'a suivi, il transfère tout le code à Ansible et Ansible, respectivement, les lance sur le serveur d'intégration et modifie la configuration. Si ce processus est violé, nous analysons ce qui ne va pas, pourquoi les scripts ont été mal écrits.

Le deuxième point est qu'il existe une infrastructure spécifique, ici nous avons l'infrastructure déployée séparément, l'application est déployée séparément. Mais il existe une infrastructure spécifique pour chaque application, c'est-à-dire qui doit être déployée avant de la lancer. Ici, en conséquence, il est impossible de le transférer vers un autre pipeline. Vous devez le déployer dans le même conteneur que l'application elle-même. Autrement dit, les frameworks sont très appréciés lorsque vous devez installer un framework pour une nouvelle application et en mettre un autre pour une autre. Voici comment avec cette situation. Ou vous devez nettoyer les caches. Par exemple, Ansible peut également grimper, nettoyer le cache.

Mais ici, nous utilisons docker en combinaison avec Ansible. Autrement dit, l'infrastructure spécifique de nous est dans le docker, non spécifique dans Ansible. Et donc, nous partageons en quelque sorte ce petit delta dans Docker, tout le reste, fondamental - dans Ansible.

Un point très important - si vous faites rouler l'infrastructure à travers une sorte de scripts, via le code, alors si vous avez encore des manipulations manuelles du serveur, alors c'est une vulnérabilité potentielle. Parce que disons que vous mettez Java sur le serveur de test, que vous avez écrit le rôle ELK, que vous l'avez lancé. Le déploiement dans le test a réussi. Déployer en production, mais il n'y a pas de java. Et vous n'avez pas spécifié java dans le script - le déploiement en production est tombé. Par conséquent, vous devez retirer les droits de tous les serveurs aux administrateurs afin qu'ils n'y rampent pas de vos mains et n'effectuent pas toutes les modifications via git. Tout ce convoyeur que nous avons traversé nous-mêmes. Il y a une chose mais - ne serrez pas trop les écrous. Autrement dit, il est nécessaire d'introduire un tel processus progressivement. Parce qu'il n'est toujours pas recadré. Dans notre cas, nous avons laissé l'accès à tous les systèmes à la tête de l'administrateur principal en cas d'incidents imprévus. L'accès est accordé à condition de ne rien configurer à la main.

Comment fonctionne le développement? Déploiement dans la mise en scène, la production doit être sans erreur. Quelque chose pourrait se casser ici. Si le déploiement dans l'environnement d'intégration tombe constamment sur des erreurs, ce sera mauvais. Ceci est similaire au débogage d'applications sur une machine distante. Lorsqu'un développeur développe d'abord tout sur une machine, le compile. Si tout se compile, l'envoie au référentiel. Il utilise la même approche. Les développeurs utilisent Visual Studio Code avec les plugins Ansible, Vagrant, Docker, etc. Les développeurs testent leur code d'infrastructure sur un vagabond local. Il s'élève un système d'exploitation propre. Les scripts eux-mêmes pour élever cette machine se trouvent également dans ce référentiel avec l'infrastructure dont nous avons parlé. Le développeur commence à y installer un serveur FTP. Si quelque chose s'est mal passé, il le supprime simplement, le recharge et essaie à nouveau d'installer le logiciel nécessaire dessus à l'aide de scripts de déploiement. Après avoir débogué les scripts de déploiement, il envoie une demande de fusion à la branche principale. Après avoir fusionné la demande de fusion, le CI restaure ces modifications sur le serveur d'intégration.

Puisque tous les scripts sont du code, nous pouvons écrire des tests. Disons que nous avons installé PostgreSQL. Nous voulons vérifier si cela fonctionne ou non. Pour ce faire, utilisez le module d'assertion Ansible. Comparez la version installée de PostgreSQL avec la version des scripts. Ainsi, nous comprenons qu'il est installé, qu'il fonctionne généralement, c'est la version même que nous attendions.

On voit que le test a réussi. Notre playbook a donc fonctionné correctement. Vous pouvez écrire autant de tests que vous le souhaitez. Ils sont idempotents. Idempotency (une opération qui, si elle est appliquée à une valeur plusieurs fois, entraîne toujours la même valeur qu'avec une seule application). Si vous écrivez des scripts gratuits pour l'installation et la configuration, assurez-vous que vos scripts obtiennent toujours la même valeur si vous les exécutez plusieurs fois.

Il existe un autre type de test qui n'est pas directement lié aux tests d'infrastructure. Mais ils semblent l'affecter indirectement. Ce sont des tests de bout en bout. Nous avons l'infrastructure et les applications elles-mêmes sont installées sur le même serveur, que les testeurs testent. Si nous avons déployé une sorte d'infrastructure incorrecte, alors nous ne réussirons que des tests complexes. Autrement dit, notre application ne fonctionnera pas correctement. Dans cet exemple, nous avons installé une nouvelle version en production - l'application fonctionne. Ensuite, une validation a été faite dans les tests git et end-to-end, qui ont lieu la nuit, suivi qu'ici nous n'avons pas de fichier sur ftp. Nous démontons ce cas et voyons que le problème est dans les paramètres ftp. Nous corrigeons les scripts dans le code, déployons à nouveau et tout devient vert. Même histoire avec le code. Le code d'infrastructure et l'infrastructure sont indirectement testés d'une manière ou d'une autre. Nous pouvons ensuite le déployer en production.

Lorsque nous avons introduit cette approche, CI (Teamcity), qui a déployé des modifications sur le serveur d'intégration, est tombé 8 fois sur 10. Personne n'y a fait attention car il n'y a pas eu de retour. Pour les développeurs, ces processus sont implémentés depuis longtemps, mais les messages n'ont pas atteint les OPS (administrateurs système). Par conséquent, nous avons ajouté un tableau de bord avec les assemblages de ce projet à un grand écran dans un endroit bien en vue du bureau. Sur celui-ci, divers projets sont surlignés en vert - cela signifie que tout est en ordre avec lui. Si surligné en rouge signifie que tout va mal avec lui. On voit que certains tests ont échoué. Lors de la présentation, sur le côté gauche du second, du haut, nous voyons le résultat des déploiements de déploiement . , , , . : - . . Slack , - - - .

Ok, , , - , . trunk based . Master — . Master CI (Teamcity) integration . CI , integration . release candidate. . . , end-to-end , staging . production. , staging .

. ? , PostgreSQL. 5 . , . 1-2 . . , PostgreSQL . PostgreSQL , staging, production 4 . , , . , . - .

git submodule Ansible . , . git submodule Ansible . inventories , . 30 . git submodule .

: , . , , , staging , . , , , , , , staging. — , , - .

6 . — 10 . . . , . - git submodule, . . , , , . , , .

.
-, , : , Ansible git , : “ , - ”. ? git . , . 100% . . .
, . . , RabbitMQ, ELK, . , ELK . , , ELK. ELK, , ELK .
, , , , . , , , , . , . .
. , , , , , , . git. , — git, , : , - . .
, , , code review. , , . , . , , , , , . , : . . . , - - .
, .
: , git submodule, . - , latest . inventories. — , . , , .. . — . .
: - Ansible ( A B, B C A, )? , ?
: . . , - IP , , , , . . , , , , , . , - , , , RabbitMQ RabbitMQ, . - , .
PS github . github . github — Pull request .