Au cours de l'année écoulée, le sujet de la cyberintelligence ou de la menace d'intelligence a gagné en popularité dans la course aux cyberarmes entre attaquants et défenseurs. De toute évidence, l'obtention proactive d'informations sur les cybermenaces est une chose très utile, mais elle ne protégera pas l'infrastructure en elle-même. Il est nécessaire de construire un processus qui aidera à gérer correctement à la fois les informations sur la méthode d'une éventuelle attaque et le temps disponible pour s'y préparer. Et la condition clé pour la formation d'un tel processus est l'exhaustivité des informations sur les cybermenaces.

Les données primaires de Threat Intelligence peuvent être obtenues à partir d'une grande variété de sources. Il peut s'agir
d'abonnements gratuits , d'informations de partenaires, d'une équipe d'enquête technique de l'entreprise, etc.
Il existe trois étapes principales pour travailler avec des informations obtenues via le processus Threat Intelligence (bien que nous, en tant que centre de surveillance et de réponse aux cyberattaques, ayons une quatrième étape - informer les clients de la menace):
- Obtention d'informations, traitement primaire.
- Détection d'indicateurs de compromis (Indicateur de compromis, IOC).
- Vérification rétrospective.
Acquisition d'informations, traitement primaire
La première étape peut être qualifiée de la plus créative. Comprendre correctement la description d'une nouvelle menace, mettre en évidence les indicateurs pertinents, déterminer leur applicabilité à une organisation spécifique, filtrer les informations inutiles sur les attaques (par exemple, ciblées étroitement sur certaines régions) - tout cela est souvent une tâche difficile. En même temps, il existe des sources qui fournissent exclusivement des données vérifiées et pertinentes qui peuvent être ajoutées automatiquement à la base de données.
Pour une approche systématique du traitement de l'information, nous recommandons de diviser les indicateurs obtenus dans le cadre de Threat Intelligence en deux grands groupes - hôte et réseau. La détection des indicateurs de réseau ne signifie pas un compromis sans équivoque du système, mais la détection des indicateurs d'hôte, en règle générale, signale de manière fiable le succès d'une attaque.
Les indicateurs de réseau incluent les domaines, les URL, les adresses de messagerie, un ensemble d'adresses IP et de ports. Les indicateurs d'hôte exécutent des processus, des modifications des branches et des fichiers du registre, des quantités de hachage.
Les indicateurs reçus dans le cadre d'une alerte de menace unique, il est logique de les combiner en un seul groupe. Dans le cas de la détection d'indicateurs, cela facilite grandement la détermination du type d'attaque, et facilite également la vérification du système potentiellement compromis pour tous les indicateurs possibles d'un rapport de menace spécifique.
Cependant, il faut souvent faire face à des indicateurs dont la détection ne permet pas de parler sans équivoque d'un système compromis. Il peut s'agir d'adresses IP appartenant à de grandes sociétés et de réseaux d'hébergement, de domaines de messagerie de services de publipostage publicitaire, de noms et de sommes de hachage de fichiers exécutables légitimes. Les exemples les plus simples sont les adresses IP de Microsoft, Amazon, CloudFlare, qui sont souvent répertoriées, ou les processus légitimes qui apparaissent dans le système après l'installation des packages logiciels, par exemple, pageant.exe, un agent de stockage des clés. Afin d'éviter un grand nombre de faux positifs, il est préférable de filtrer ces indicateurs, mais, disons, ne les jetez pas - la plupart d'entre eux ne sont pas entièrement inutiles. En cas de suspicion d'un système compromis, une vérification complète est effectuée sur tous les indicateurs, et la détection d'un indicateur, même indirect, peut confirmer ces soupçons.
Étant donné que tous les indicateurs ne sont pas également utiles, Solar JSOC utilise le soi-disant poids d'indicateur. Par convention, la détection d'un lancement de fichier, dont la somme de hachage coïncide avec le hachage du fichier exécutable malveillant, a un poids seuil. La détection d'un tel indicateur conduit instantanément à la survenance d'un événement de sécurité de l'information. Un accès unique à l'adresse IP d'un hôte potentiellement dangereux sur un port non spécifique ne conduira pas à un événement IB, mais tombera dans un profil spécial qui accumule des statistiques, et la détection d'autres appels mènera également à une enquête.
En même temps, il existe des mécanismes qui nous semblaient raisonnables au moment de la création, mais qui ont finalement été reconnus comme inefficaces. Par exemple, il a été initialement prévu que certains types d'indicateurs auront une durée de vie limitée, après quoi ils seront désactivés. Cependant, comme la pratique l'a montré, lors de la connexion à une nouvelle infrastructure, on trouve parfois des hôtes infectés par divers types de logiciels malveillants depuis des années. Par exemple, une fois lors de la connexion d'un client, le virus Corkow a été détecté sur la machine du chef du service IS (les indicateurs avaient plus de cinq ans à l'époque), et une enquête plus approfondie a révélé une porte dérobée et un enregistreur de frappe exploités sur l'hôte.
Détection d'indicateurs de compromis
Nous travaillons avec de nombreuses installations de divers systèmes SIEM, cependant, la structure générale des enregistrements qui tombent dans la base de données des indicateurs est normalisée et ressemble à ceci:
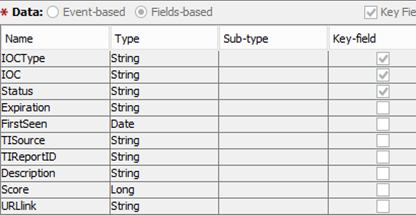
Par exemple, en triant les indicateurs par TIReportID, vous pouvez trouver tous les indicateurs qui sont apparus dans la description d'une menace spécifique, et en cliquant sur le lien URL, vous pouvez obtenir une description détaillée de celle-ci.
Lors de la construction du processus Threat Intelligence, il est très important d'analyser les systèmes d'information connectés au SIEM en termes d'utilité pour identifier des indicateurs de compromis.
Le fait est que la description de l'attaque comprend généralement différents types d'indicateurs de compromis - par exemple, la quantité de hachage du logiciel malveillant, l'adresse IP du serveur SS sur lequel il frappe, etc. Mais si les adresses IP accessibles par l'hôte sont surveillées par de nombreux moyens de protection, les informations sur les quantités de hachage sont beaucoup plus difficiles à obtenir. Par conséquent, nous considérons tous les systèmes qui peuvent servir de source de journaux du point de vue des indicateurs qu'ils peuvent suivre:
Type d'indicateur
| Type de source
|
Domaine
| Serveurs proxy, NGFW, serveurs DNS
|
URL
|
Prise
| Proxies, NGFW, FW
|
Mail
| Serveurs de messagerie, antispam, DLP
|
Processus
| Journaux de l'hôte, DB AVPO, Sysmon
|
Registre
| Journaux de l'hôte
|
Somme de hachage
| Journaux de l'hôte, DB AVPO, Sysmon, Sandbox CMDB
|
Schématiquement, le processus de détection des indicateurs de compromis peut être représenté comme suit:

J'ai déjà parlé des deux premiers points ci-dessus, maintenant un peu plus sur la vérification de la base de données du CIO. Pour un exemple, nous prendrons les événements contenant des informations sur les adresses IP. La règle de corrélation pour chaque événement effectue quatre vérifications possibles sur la base d'indicateurs:

La recherche est effectuée par des indicateurs pertinents du type Socket, tandis que la conception globale de l'adresse IP et du port correspondant est vérifiée pour la conformité avec l'indicateur. Parce que le port spécifique n'est pas toujours indiqué dans les informations sur les menaces, l'IP: toute construction vérifie si l'adresse de la base de données a un port non défini.
Une conception similaire est implémentée dans une règle qui détecte les indicateurs de compromis dans les événements de modification du registre. Dans les informations entrantes, il n'y a souvent pas de données sur une clé ou une valeur particulière.Par conséquent, lorsqu'un indicateur est entré dans la base de données, les données inconnues ou n'ayant pas de valeur exacte sont remplacées par `` toutes ''. Les dernières options de recherche sont les suivantes:

Après avoir trouvé l'indicateur de compromis dans les journaux, la règle de corrélation crée un événement de corrélation marqué avec la catégorie que la règle d'incident traite (nous en avons discuté en détail dans l'article «
Cuisine DROITE »).
En plus de la catégorie, l'événement de corrélation sera complété par des informations sur l'alerte ou le rapport dans lequel cet indicateur est apparu, son poids, les données de menace et un lien vers la source. Un traitement ultérieur des événements de détection d'indicateurs de tous types est effectué par la règle d'incident. Son travail peut être schématiquement présenté comme suit:

Mais, bien sûr, vous devez garder à l'esprit les exceptions: dans presque toutes les infrastructures, il existe des appareils dont les actions sont légitimes, malgré le fait qu'ils contiennent formellement des signes d'un système compromis. Ces appareils comprennent le plus souvent des bacs à sable, divers scanners, etc.
La nécessité de corréler les événements de détection d'indicateurs de différents types est également due au fait que les indicateurs hétérogènes sont le plus souvent présents dans les informations sur les menaces.
En conséquence, un regroupement des événements de détection d'indicateur peut vous permettre de voir l'intégralité de la chaîne d'attaque du moment de la pénétration à l'opération.
Nous proposons d'envisager la mise en œuvre de l'un des scénarios suivants comme un événement de sécurité de l'information:
- Détection d'un indicateur de compromis hautement pertinent.
- Détection de deux indicateurs différents d'un même rapport.
- Atteindre le seuil.
Avec les deux premières options, tout est clair et la troisième est nécessaire lorsque nous n'avons pas de données autres que l'activité réseau du système.
Vérification rétrospective des indicateurs de compromis
Après avoir reçu des informations sur la menace, identifié les indicateurs et organisé leur identification, il est nécessaire d'effectuer un contrôle rétrospectif qui vous permette de détecter un compromis qui a déjà eu lieu.
Si j'approfondis un peu la façon dont cela fonctionne au SOC, je peux dire que ce processus nécessite un temps et des ressources vraiment colossaux. La recherche d'indicateurs de compromis dans les journaux pendant six mois nous oblige à en conserver une quantité impressionnante pour les contrôles en ligne. De plus, le résultat du contrôle devrait être non seulement des informations sur la présence d'indicateurs, mais également des données générales sur le développement de l'attaque. Lors de la connexion de nouveaux systèmes d'information client, les données de ceux-ci doivent également être vérifiées pour les indicateurs. Pour cela, il est nécessaire d'affiner constamment le soi-disant «contenu» du SOC - règles de corrélation et indicateurs de compromis.
Pour le système ArcSight SIEM, même une telle recherche au cours des deux dernières semaines peut prendre beaucoup de temps. Par conséquent, il a été décidé de profiter des tendances.
"Une tendance est une ressource ESM qui définit comment et sur quelle période de temps les données seront agrégées et évaluées pour les tendances ou les courants dominants. Une tendance exécute une requête spécifiée selon un calendrier et une durée définis. »
ESM_101_Guide
Après plusieurs tests sur des systèmes chargés, l'algorithme suivant d'utilisation des tendances a été développé:

Les règles de profilage qui remplissent les feuilles actives correspondantes avec des données utiles vous permettent de répartir la charge totale sur le SIEM. Après réception des indicateurs, des demandes sont créées dans les fiches et tendances correspondantes, sur la base desquelles des rapports seront établis, qui à leur tour seront répartis dans toutes les installations. En fait, il ne reste plus qu'à exécuter des rapports et à traiter les résultats.
Il convient de noter que le processus de traitement peut être continuellement amélioré et automatisé. Par exemple, nous avons introduit une plate-forme de stockage et de traitement des indicateurs de compromis MISP, qui répond actuellement à nos exigences de flexibilité et de fonctionnalité. Ses analogues sont largement représentés sur le marché open source - YETI, étranger - Anomali ThreatStream, ThreatConnect, ThreatQuotinet, EclecticIQ, russe - TI.Platform, R-Vision Threat Intelligence Platform. Nous effectuons maintenant des tests finaux de déchargement automatisé d'événements directement à partir de la base de données SIEM. Cela accélérera considérablement la communication des indicateurs de compromis.
L'élément principal de la cyber-intelligence
Néanmoins, le dernier maillon du traitement des indicateurs eux-mêmes et des rapports est constitué d'ingénieurs et d'analystes, et les outils énumérés ci-dessus ne servent qu'à prendre des décisions. Dans notre pays, le groupe de réponse est responsable de l'ajout d'indicateurs et le groupe de suivi est responsable de l'exactitude des rapports.
Sans personnes, le système ne fonctionnera pas suffisamment, vous ne pouvez pas prévoir toutes les petites choses et les exceptions. Par exemple, nous notons les appels aux adresses IP des nœuds TOR, mais dans les rapports pour le client, nous partageons l'activité de l'hôte compromis et de l'hôte sur lequel TOR Browser a été simplement installé. Il est possible de l'automatiser, mais il est assez difficile de réfléchir à l'avance à tous ces points lors de la configuration des règles. Il s'avère donc que le groupe de réponse, selon divers critères, élimine les indicateurs qui créeront un grand nombre de faux positifs. Et vice versa - un indicateur spécifique peut être ajouté qui est très pertinent pour certains clients (par exemple, le secteur financier).
Le groupe de surveillance peut supprimer l'activité sandbox du rapport final, vérifier les administrateurs pour le blocage réussi d'une ressource malveillante, mais ajouter une activité sur l'analyse externe infructueuse, montrant au client que son infrastructure est vérifiée par des attaquants. La machine ne prendra pas de telles décisions.

Au lieu de la sortie
Pourquoi recommandons-nous cette méthode de travail avec Threat Intelligence? Tout d'abord, cela vous permet de vous éloigner du schéma, lorsque pour chaque nouvelle attaque, vous devez créer une règle de corrélation distincte. Cela prend un temps inacceptable et ne révèle que l'attaque en cours.
La méthode décrite tire le meilleur parti des capacités TI - il vous suffit d'ajouter des indicateurs, ce qui est au maximum 20 minutes à partir du moment où ils apparaissent, puis d'effectuer une vérification rétrospective complète des journaux. Vous réduirez ainsi le temps de réponse et obtiendrez des résultats de test plus complets.
Si vous avez des questions, n'hésitez pas à commenter.