Le protocole de couche application HTTP est à la base d'Internet. Il a commencé sa vie en 1991 sous le nom de HTTP / 0.9, et en 1999, il est devenu HTTP / 1.1, qui a été normalisé par l'Internet Engineering Council (IETF).
HTTP / 1.1 a satisfait tout le monde pendant longtemps, mais les besoins croissants du Web ont nécessité une mise à niveau - et en 2015 ont adopté HTTP / 2. L'histoire ne s'arrête pas là: tout récemment, l'IETF a annoncé une nouvelle version de HTTP / 3. Pour certains, cela a été une surprise et a semé la confusion. Si vous ne surveillez pas l'IETF, il peut sembler que HTTP / 3 est venu de nulle part. Néanmoins, nous pouvons retracer son origine en fonction de l'histoire des expériences et de l'évolution des protocoles web, notamment le protocole de transport QUIC.
Si vous n'êtes pas familier avec QUIC, mes collègues Cloudflare ont couvert divers aspects en détail: par exemple, consultez des articles sur les
failles réelles du HTTP moderne et des
détails sur le protocole de la couche de transport . Nous avons collecté ces documents et d'autres sur
cloudflare-quic.com . Et si vous êtes intéressé, assurez-vous de vérifier la
quiche : c'est notre propre implémentation de QUIC, écrite en Rust avec du code open source.
HTTP / 3 - traduction du protocole de transport QUIC pour la couche application. Le nom HTTP / 3 n'a été officiellement approuvé que récemment, dans la 17e version du projet (
draft-ietf-quic-http-17 ). Il a été proposé fin octobre 2018 et un consensus a été atteint lors de la réunion de l'IETF 103 à Bangkok en novembre.
Auparavant, HTTP / 3 était connu comme HTTP par QUIC, et avant cela - comme HTTP / 2 par gQUIC, et même plus tôt - SPDY par gQUIC. Mais l'essentiel est que HTTP / 3 n'est que la nouvelle syntaxe HTTP qui s'exécute sur le protocole IETF QUIC, un transport multiplexé et sécurisé basé sur UDP.
Dans cet article, nous allons examiner l'historique de certains des noms HTTP / 3 précédents et présenter la motivation du changement de nom. Revenons aux premiers jours de HTTP et à tout ce qui s'est passé pendant cette période. Si vous voulez obtenir l'image complète, vous pouvez immédiatement aller à la fin de l'article ou ouvrir
cette version très détaillée de SVG .
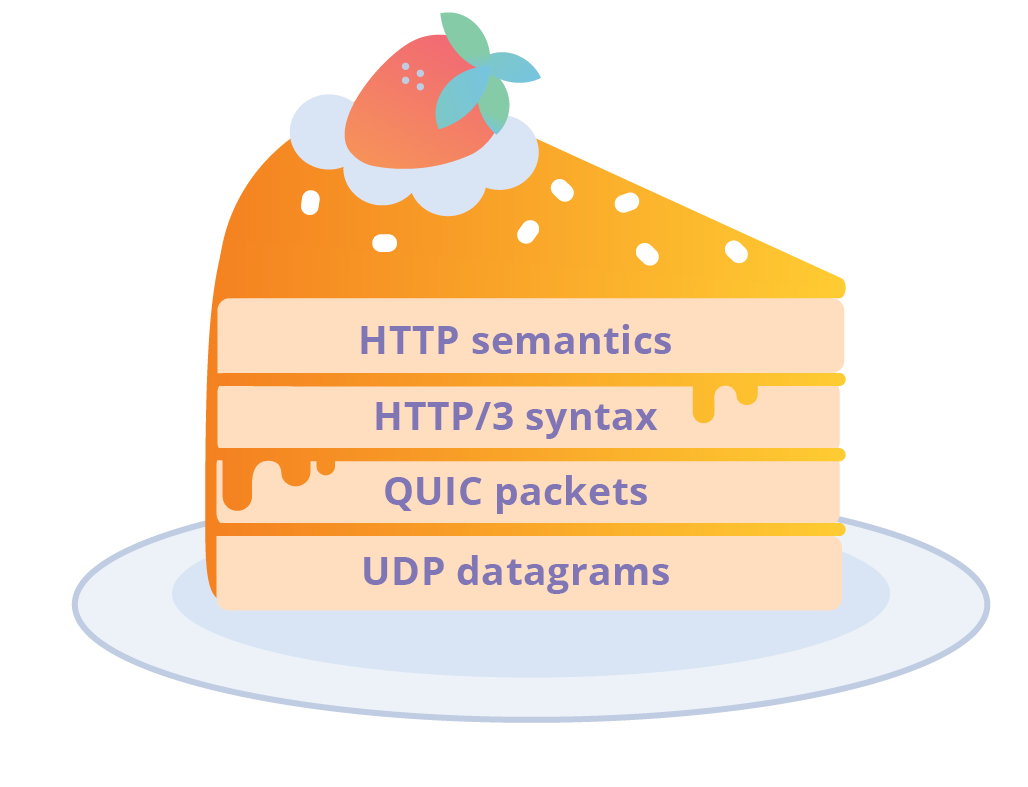 Gâteau HTTP / 3 couches
Gâteau HTTP / 3 couchesAmeublement
Juste avant de se concentrer sur HTTP, il convient de rappeler qu'il existe deux protocoles appelés QUIC. Comme nous l'avons déjà
expliqué , gQUIC est généralement utilisé comme abréviation de Google QUIC (protocole source) et QUIC comme version IETF qui diffère de gQUIC.
Depuis le début des années 90, les besoins d'Internet ont changé. Nous avons de nouvelles versions de HTTP et un nouveau niveau de sécurité sous la forme du protocole TLS (Transport Layer Security). Dans cet article, nous ne couvrirons que TLS, et dans d'
autres articles de notre blog, vous pourrez étudier le sujet plus en détail.
L'histoire de HTTP et TLS ne peut pas être exprimée avec une simple liste de dates, car certaines branches ont évolué en parallèle et se chevauchent dans le temps. Lorsque vous essayez de connecter tous les points en près de 30 ans d'histoire d'Internet, vous ne pouvez pas vous passer de visualisation. J'ai donc fait ce planning: Cloudflare Secure Web Timeline. (note: techniquement, il s'agit d'un
cladogramme , bien que les gens connaissent mieux le mot «graphique»).
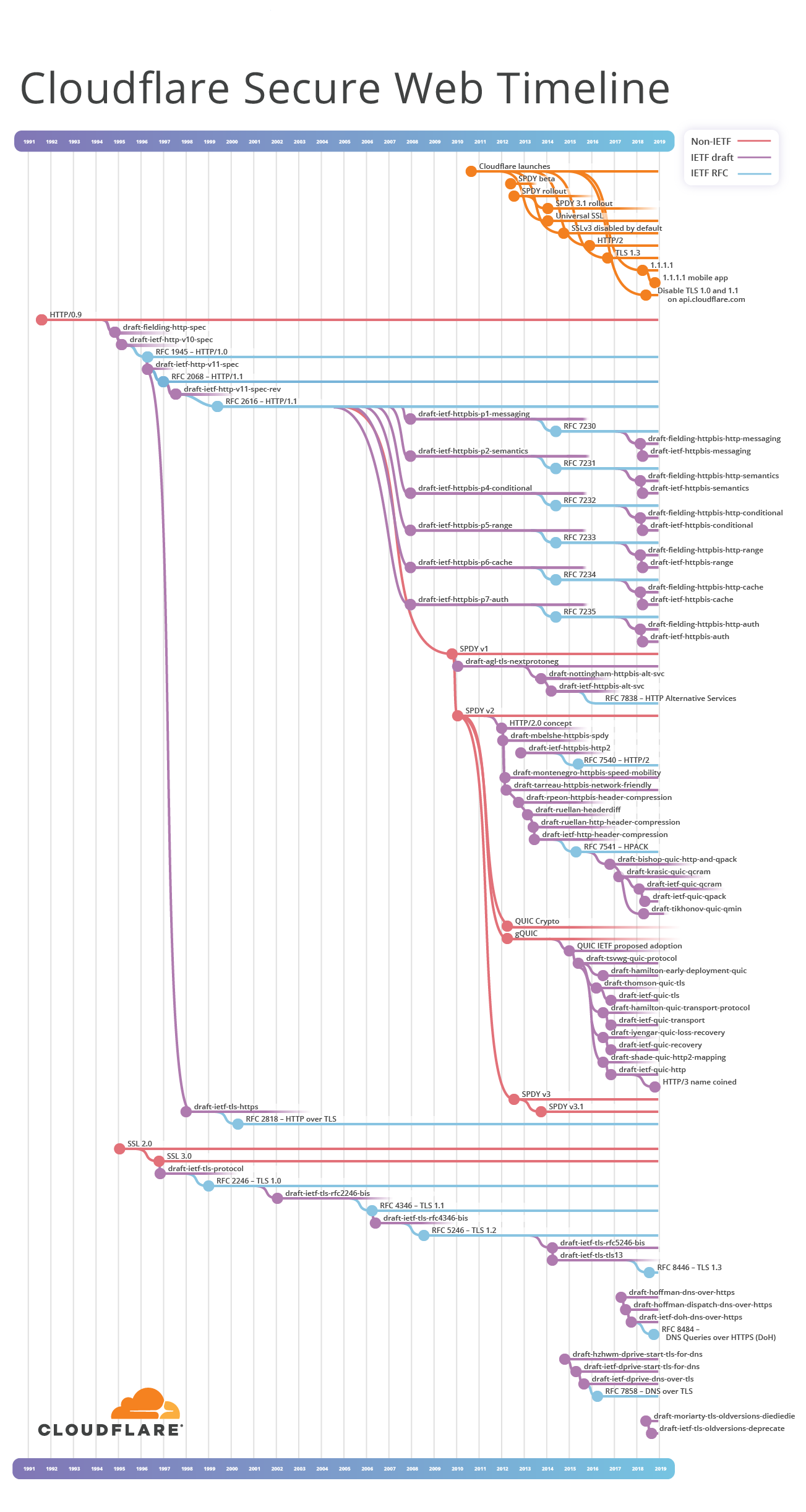
Par souci de beauté, j'ai laissé tomber certaines des informations, en me concentrant uniquement sur les succursales réussies dans l'espace IETF. Par exemple, les efforts du groupe de travail HTTP-NG du consortium W3, ainsi que certaines technologies exotiques, dont la prononciation tente toujours d'expliquer, ne sont pas présentées ici:
HMURR (prononcé "hummer") et
WAKA (prononcé "wah-kah").
Dans les sections suivantes, nous allons parcourir ce cladogramme et regarder quelques points de basculement dans l'histoire de HTTP. J'espère que cela aide à comprendre pourquoi la normalisation est bénéfique pour tout le monde et comment l'IETF aborde ce problème. Par conséquent, nous commençons par un très bref aperçu du sujet avant de revenir au calendrier lui-même. N'hésitez pas à sauter la section suivante si vous êtes déjà familier avec l'IETF.
Types de norme Internet
En règle générale, les normes définissent la compétence générale, la portée, les limites, l'applicabilité et d'autres considérations. Les normes existent sous de nombreuses formes et tailles. Ils peuvent être informels (norme de facto) ou formels (approuvés / publiés par une organisation de normalisation telle que l'IETF, l'ISO ou le MPEG). Les normes sont utilisées dans de nombreux domaines, il existe même une norme britannique officielle pour la fabrication du thé - BS 6008.
Les premières définitions de protocoles HTTP et SSL ont été publiées en dehors de l'IETF: elles sont marquées de
lignes rouges dans le graphique. Mais leur utilisation généralisée en a fait de facto des normes.
À un moment donné, ils ont décidé d'officialiser ces protocoles (certaines raisons sont décrites ci-dessous). Les normes Internet sont généralement définies dans l'IETF, qui est guidé par le principe officieux de «consensus exemplaire et code actuel» basé sur des applications réelles sur Internet. C'est différent de l'approche de la salle blanche lorsque quelqu'un essaie de développer des protocoles idéaux dans le vide.
Les normes IETF sont communément appelées RFC. C’est difficile à expliquer brièvement, je recommande donc l’article
«Comment lire les RFC» du coprésident du groupe de travail QUIC, Mark Nottingham. Un groupe de travail ou groupe de travail n'est essentiellement qu'une liste de diffusion.
Chaque année, il y a trois réunions pour des réunions personnelles des membres de tous les groupes de travail, s'ils le souhaitent. L'ordre du jour de ces semaines peut être très chargé, il n'y a pas assez de temps pour une discussion approfondie des questions techniques. Par conséquent, certains préfèrent accueillir plus de réunions à mi-parcours entre les assemblées générales de l'IETF. Le groupe de travail QUIC a tenu plusieurs réunions intérimaires depuis 2017, la liste complète est disponible sur
la page des réunions .
Ces réunions ont l'occasion de rencontrer des experts d'autres organisations, telles que
l'Internet Architecture Council (IAB) ou l'
Internet Technology Research Group (IRTF). Ces dernières années, le week-end précédant l'IETF a traditionnellement organisé le
hackathon de l'
IETF . Le vrai code est développé ici et, surtout, passe les tests de compatibilité. Cela aide à trouver des problèmes dans les spécifications qui peuvent être discutés directement lors de la réunion.
Il est important de comprendre que les RFC ne proviennent pas de nulle part. Ils passent par tout un processus. Il commence généralement par un projet IETF Internet Draft (ID), qui est soumis pour examen. Dans le cas où la spécification a déjà été publiée, la préparation d'un ID deviendra un simple reformatage. La durée de vie de l'ID est de 6 mois à compter de la date de publication. Pour le garder actif, vous devez publier de nouvelles versions. En pratique, il est normal que l'ID expire. Cela arrive assez souvent. Les documents sont toujours stockés sur le site Web de l'IETF et sont ouverts à tous.
Sur le cladogramme, les ébauches sont présentées en
violet . Chacun a son
propre nom au format
draft- {author} - {groupe de travail} - {topic} - {version} . Le champ WG est facultatif, il peut pointer vers un futur groupe de travail de l'IETF et change parfois. Si l'ID est approuvé par l'IETF ou initié directement à l'intérieur de l'IETF, le brouillon est appelé
draft-ietf- {workgroup} - {topic} - {version} . Les ID peuvent se ramifier, fusionner ou s'estomper. La version commence à 00 et augmente d'un nouveau projet à chaque nouveau. Par exemple, le quatrième brouillon recevra le numéro de version 03. Chaque fois que le nom de l'ID est modifié, sa version est réinitialisée à 00.
Il est important de noter que n'importe qui peut soumettre son projet à l'IETF: ils ne peuvent pas être considérés comme des normes. Mais si le processus de normalisation atteint un consensus et que le document final réussit le test, nous obtiendrons un RFC. À ce stade, le nom change à nouveau. Chaque RFC reçoit un numéro unique, tel que
RFC 7230 . Les documents avec ce statut sont représentés par
des lignes bleues .
RFC est interdit de changer. Autrement dit, les modifications apportées à la RFC nécessitent l'adoption d'un document avec un nouveau numéro. Les modifications ne sont autorisées que pour la correction d'erreurs éditoriales ou techniques ou pour une simple optimisation de la mise en page. Les nouveaux RFC peuvent remplacer complètement les anciens ou les compléter.
Tous les documents de l'IETF sont accessibles au public à
http://tools.ietf.org . Personnellement, cela me semble un peu plus pratique que l'
IETF Datatracker , car le chemin du document de l'ID à la RFC y est affiché visuellement.
Ci-dessous est un exemple qui montre le développement de la norme
RFC 1945 , c'est-à-dire HTTP / 1.0.
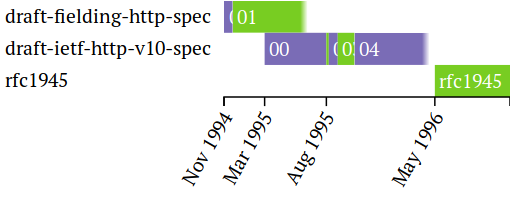 Histoire de RFC 1945 à l'interface IETF Datatracker
Histoire de RFC 1945 à l'interface IETF DatatrackerFait intéressant, au cours du travail, j'ai trouvé que la visualisation ci-dessus est incorrecte. Pour une raison quelconque,
draft-ietf-http-v10-spec-05 est manquant. Étant donné que la pièce d'identité a 6 mois, elle a probablement expiré avant l'adoption du RFC, bien qu'en réalité le projet ait été actif jusqu'en août 1996.
Étudier un cladogramme
Après une courte introduction théorique, nous pouvons commencer à étudier le cladogramme. Cette section présente quelques extraits avec les parties les plus importantes. Chaque point indique la date à laquelle le document ou la fonction a été fourni. Pour plus de clarté, les documents de l'IETF ont omis les numéros de projet, mais ils sont tous dans la
version complète .
HTTP est apparu en 1991 comme protocole HTTP / 0.9, et en 1994,
draft-fielding-http-spec-00 a été publié. Bientôt, il a été accepté par l'IETF, à la suite de quoi le nom a changé en
draft-ietf-http-v10-spec-00 . Après six éditions du projet, la norme
RFC 1945 , HTTP / 1.0, a été adoptée en 1996.
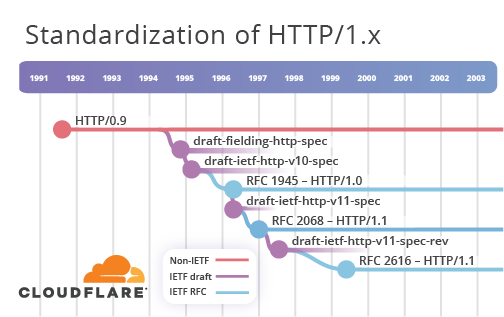
Cependant, avant même la fin des travaux sur HTTP / 1.0, un projet HTTP / 1.1 distinct a été lancé. Le projet de version de
draft-ietf-http-v11-spec-00 a été publié en novembre 1995 et officiellement adopté en tant que
RFC 2068 en 1997. L'œil averti remarquera que le cladogramme ne reflète pas tout à fait cette séquence d'événements - un problème infructueux de l'outil de visualisation. J'ai essayé de minimiser ces problèmes autant que possible.
Au milieu de 1997, une révision de HTTP / 1.1 a commencé sous la forme
draft-ietf-http-v11-spec-rev-00 . Il s'est terminé en 1999 avec la publication de la
RFC 2616 . Jusqu'en 2007, tout était calme dans le monde HTTP de l'IETF. Nous y reviendrons un peu plus tard.
Historique SSL et TLS
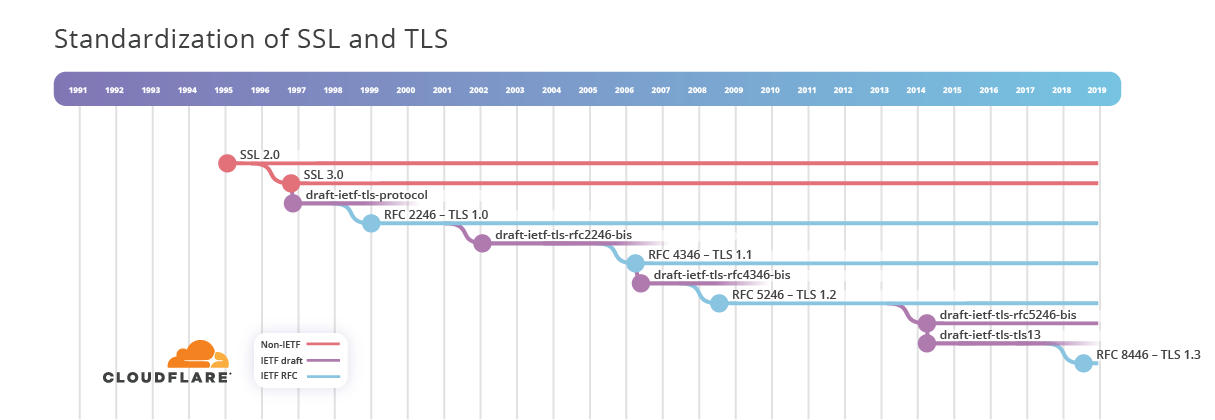
Nous tournons notre attention vers la trajectoire SSL. Nous voyons que la spécification SSL 2.0 a été publiée vers 1995, et SSL 3.0 a été publiée en novembre 1996. Fait intéressant, SSL 3.0 est approuvé dans la
RFC 6101 , qui n'est apparue qu'en août 2011. Il est situé dans la section
historique .
Selon l'IETF , il a été créé "pour documenter les idées qui ont été considérées et rejetées, ou les protocoles qui existaient déjà au moment où il a été décidé de les documenter." Dans ce cas, j'avais besoin d'un document IETF décrivant SSL 3.0 afin de l'utiliser partout comme lien canonique.
Nous sommes plus intéressés par la façon dont SSL a inspiré les ingénieurs pour développer TLS, qui a commencé avec un projet de
protocole-ietf-tls-00 00 en novembre 1996. Il a fait l'objet de 6 versions préliminaires et a été publié en tant que
RFC 2246 - TLS 1.0 au début de 1999.
En 1995-1999, SSL et TLS ont été utilisés pour protéger les connexions HTTP sur Internet. Cela fonctionnait très bien comme norme de facto. Ce n'est qu'en janvier 1998 que la normalisation officielle du HTTPS a commencé par la publication d'un projet de
draft-ietf-tls-https-00 . Travaux terminés en mai 2000 avec la publication de la
RFC 2616 - HTTP sur TLS.
TLS a continué d'évoluer de 2000 à 2007, avec l'adoption de TLS 1.1 et 1.2. Ensuite, il y a eu une pause de sept ans avant le début des travaux sur la prochaine version du protocole TLS, qui sera publiée sous forme de
draft-ietf-tls-tls13-00 en avril 2014, et après 28 projets, elle sera
approuvée en tant que
RFC 8446 - TLS 1.3 en août 2018.
Processus de normalisation d'Internet
Après une courte connaissance du cladogramme, j'espère qu'il est devenu préférable de comprendre le fonctionnement de l'IETF. Lors de la création de normes, les chercheurs ou les ingénieurs développent des protocoles expérimentaux pour des cas d'utilisation spécifiques. À différents niveaux, ils expérimentent des protocoles publics ou privés. Les informations reçues vous permettent d'identifier les problèmes ou d'améliorer le protocole. La publication de l'ouvrage permet d'expliquer l'expérience, l'avis de rencontre d'un cercle plus large de spécialistes ou de trouver l'aide d'autres interprètes. Si d'autres participants acceptent ce travail à un stade précoce, il deviendra la norme de facto et, finalement, il y aura suffisamment d'élan pour la normalisation officielle.
Le statut officiel du protocole est un facteur important pour les organisations qui envisagent de l'utiliser. Le processus formel de normalisation rend la norme de facto plus attrayante car elle assure généralement la stabilité. Une organisation réputée comme l'IETF, qui reflète les intérêts et l'expérience de nombreux participants, prend les devants et le leadership. Mais il convient de noter que toutes les normes formelles ne réussissent pas.
Le processus de création d'une norme est presque aussi important que la norme elle-même. Traiter l'idée initiale, une invitation à discuter de personnes ayant des connaissances, une expérience et des cas d'utilisation plus larges - tout cela contribue à créer quelque chose de plus utile pour un large public. Cependant, le processus de normalisation n'est pas toujours facile. Il y a des pièges et des obstacles. Parfois, un processus prend tellement de temps que le résultat n'est plus pertinent.
Chaque organisation qui définit des normes a généralement son propre processus, axé sur son domaine d'activité et ses participants. Expliquer tous les détails du fonctionnement de l'IETF dépasse de loin la portée de cet article. Si vous êtes intéressé, la page
«Comment nous travaillons» sur le site Web de l'IETF est un excellent point de départ. Comme d'habitude, la meilleure façon de le comprendre est de participer vous-même. Assez pour rejoindre la liste de diffusion ou la discussion dans le référentiel GitHub approprié.
Code de travail Cloudflare
Cloudflare est fier d'être l'un des premiers à introduire de nouveaux protocoles, comme ce fut le cas avec
HTTP / 2 et d'autres technologies. Nous testons également des fonctionnalités expérimentales et non encore approuvées, telles que
TLS 1.3 et
SPDY .
L'exécution de code réel vous aide à comprendre dans quelle mesure le protocole fonctionnera dans la pratique. Nous combinons des connaissances d'experts avec des informations expérimentales pour aider à améliorer le code et, lorsque cela est logique, signaler des problèmes ou des améliorations à un groupe de travail qui standardise le protocole.
Tester les innovations n'est pas la seule priorité. Un véritable innovateur sait toujours quand reporter l'innovation jusqu'à des temps meilleurs. Cela s'applique parfois aux protocoles axés sur la sécurité: par exemple, Cloudflare a
désactivé SSLv3 par défaut en raison de la vulnérabilité POODLE. Dans d'autres cas, les protocoles sont remplacés par des protocoles plus avancés technologiquement: par exemple, nous avons
remplacé SPDY par HTTP / 2 .
L'activation et la désactivation des protocoles sur Cloudflare sont représentées par
des lignes orange . Les repères verticaux aident à corréler les événements Cloudflare avec les documents IETF associés. Par exemple, Cloudflare a introduit la prise en charge TLS 1.3 en septembre 2016, et la
RFC 8446 finale a été publiée près de deux ans plus tard, en août 2018.

Refactoring: HTTPbis
HTTP / 1.1 est un protocole très réussi. Le graphique ne montre pas d'activité particulière de l'IETF après 1999. Mais en réalité, des années d'utilisation active du protocole ont donné de l'expérience et révélé des problèmes cachés de RFC 2616, y compris certains problèmes de compatibilité. De plus, le protocole a été étendu par d'autres RFC, comme 2817 et 2818. En conséquence, en 2007, il a été décidé de commencer des activités pour améliorer la spécification HTTP. Il s'appelle HTTPbis (où «bis» vient du mot latin «deux», «deux fois» ou «répéter»). La
charte initiale
du nouveau groupe de travail décrit bien les problèmes qu'il tentait de résoudre.
En général, HTTPbis a commencé à refactoriser
RFC 2616 . Il inclut des corrections de bogues et l'implémentation de certains aspects d'autres spécifications publiées en même temps. Il a été décidé de diviser le document en plusieurs parties. En conséquence, six projets ont été publiés en décembre 2007:
- draft-ietf-httpbis-p1-messagerie
- draft-ietf-httpbis-p2-semantics
- draft-ietf-httpbis-p4-conditionnel
- gamme draft-ietf-httpbis-p5
- draft-ietf-httpbis-p6-cache
- draft-ietf-httpbis-p7-auth
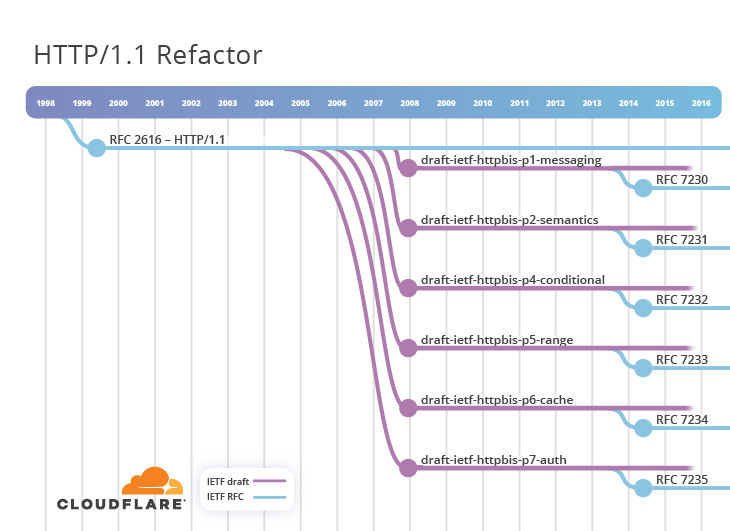
Le diagramme montre comment le travail a progressé au cours d'un long processus de développement de sept ans. Avant la normalisation finale, 27 projets ont été adoptés. En juin 2014, la soi-disant série RFC 723x (où x varie de 0 à 5) a été publiée. Le président du groupe de travail HTTPbis a noté cette réalisation avec la phrase
«RFC2616 est mort» . Si quelqu'un ne comprenait pas, les nouveaux documents ont été envoyés aux archives de l'ancien
RFC 2616 .
Qu'est-ce que cela a à voir avec HTTP / 3?
Alors que l'IETF finalisait le RFC 723x, le monde ne s'est pas arrêté. Les gens ont continué d'étendre et de compléter HTTP. Parmi eux se trouvent des ingénieurs de Google, qui ont commencé à expérimenter leur propre protocole appelé SPDY (prononcé "speedy"). Ils ont dit que ce protocole accélère le chargement des pages Web, ce qui est une caractéristique essentielle de HTTP. Fin 2009, la première version a été annoncée et en 2010 SPDY v2 est rapidement apparu.
Je ne veux pas entrer dans les détails techniques de SPDY, mais il est important de comprendre que SPDY a pris les paradigmes HTTP de base et a légèrement changé le format d'échange pour l'optimisation. Avec le recul, nous voyons que HTTP a une distinction claire entre la sémantique et la syntaxe. La sémantique décrit le concept d'échange de demandes et de réponses, y compris les méthodes, les codes d'état, les champs d'en-tête (métadonnées) et les corps (données utiles). La syntaxe décrit comment mapper la sémantique en octets sur le réseau.
HTTP / 0.9, 1.0 et 1.1 ont beaucoup de sémantique commune. Ils utilisent également une syntaxe commune sous la forme de chaînes de caractères envoyées via des connexions TCP. SPDY a pris la sémantique de HTTP / 1.1 et a changé la syntaxe en binaire. C'est un sujet vraiment intéressant, mais aujourd'hui nous ne nous plongerons pas dans ce terrier de lapin.
Des expériences avec SPDY ont montré que la modification de la syntaxe HTTP donne vraiment effet. Dans le même temps, il est important de maintenir la sémantique existante. Par exemple, l'enregistrement du format URL pour l'utilisation de
https:// évité de nombreux problèmes susceptibles d'affecter la mise en œuvre de HTTPS.
Après avoir vu des résultats positifs, l'IETF a décidé qu'il était temps d'examiner les options pour HTTP / 2.0. Les
diapositives de la session HTTPbis lors de la réunion de l'IETF 83 en mars 2012 indiquent les exigences et les objectifs que les développeurs se sont fixés. Il indique clairement: «HTTP / 2.0 signifie uniquement que le protocole de transport (format filaire) n'est pas compatible avec HTTP / 1.x»
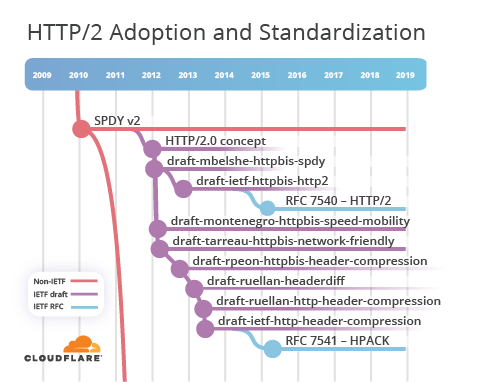
Lors de cette rencontre, la communauté a été invitée à exprimer ses idées. Les projets soumis incluaient
draft-mbelshe-httpbis-spdy-00 ,
draft-montenegro-httpbis-speed -Mobility- 00 et
draft-tarreau-httpbis-network-friendly-00 . Finalement, le projet de SPDY a été accepté et, en novembre 2012, les travaux ont commencé sur
draft-ietf-httpbis-http2-00 . Après 18 versions préliminaires, la
RFC 7540 - HTTP / 2 est apparue en un peu plus de deux ans. En 2015, la syntaxe HTTP / 2 était allée exactement assez pour rendre HTTP / 2 et SPDY incompatibles.
Ces années sont devenues une période très stressante pour les groupes de travail qui ont simultanément refactorisé HTTP / 1.1 et adopté HTTP / 2. Cela contraste fortement avec des années de calme au début des années 2000. N'oubliez pas de consulter le cladogramme complet pour vraiment apprécier la quantité de travail effectuée.
Malgré la standardisation de HTTP / 2, les expériences avec SPDY sont toujours utiles. Cloudflare a introduit le support SPDY en août 2012 et ne l'a supprimé qu'en février 2018, lorsque nos statistiques ont montré que moins de 4% des clients Web le demandaient. Pendant ce temps, peu de temps après la publication du RFC en décembre 2015, nous avons introduit le support HTTP / 2, lorsque l'analyse a montré un support significatif pour les clients Web.
Les protocoles SPDY et HTTP / 2 utilisent TLS par défaut. L'introduction du
SSL universel en septembre 2014 nous a permis de garantir que tous les utilisateurs de Cloudflare utiliseront les nouveaux protocoles dès leur introduction.
gQUIC
Google a continué d'expérimenter et jusqu'en 2015 a publié une autre version de SPDY v3 et v3.1. Ils ont également commencé à travailler sur le protocole gQUIC, dont la première version a été publiée début 2012.
Les versions antérieures de gQUIC utilisaient la syntaxe HTTP SPDY v3. Ce choix était logique car HTTP / 2 n'a pas encore été approuvé. La syntaxe binaire SPDY est empaquetée dans des paquets QUIC qui sont envoyés dans des datagrammes UDP. Il s'agit d'une dérogation au transport TCP sur lequel HTTP s'est traditionnellement appuyé. L'ensemble du système d'assemblage ressemblait à ceci:
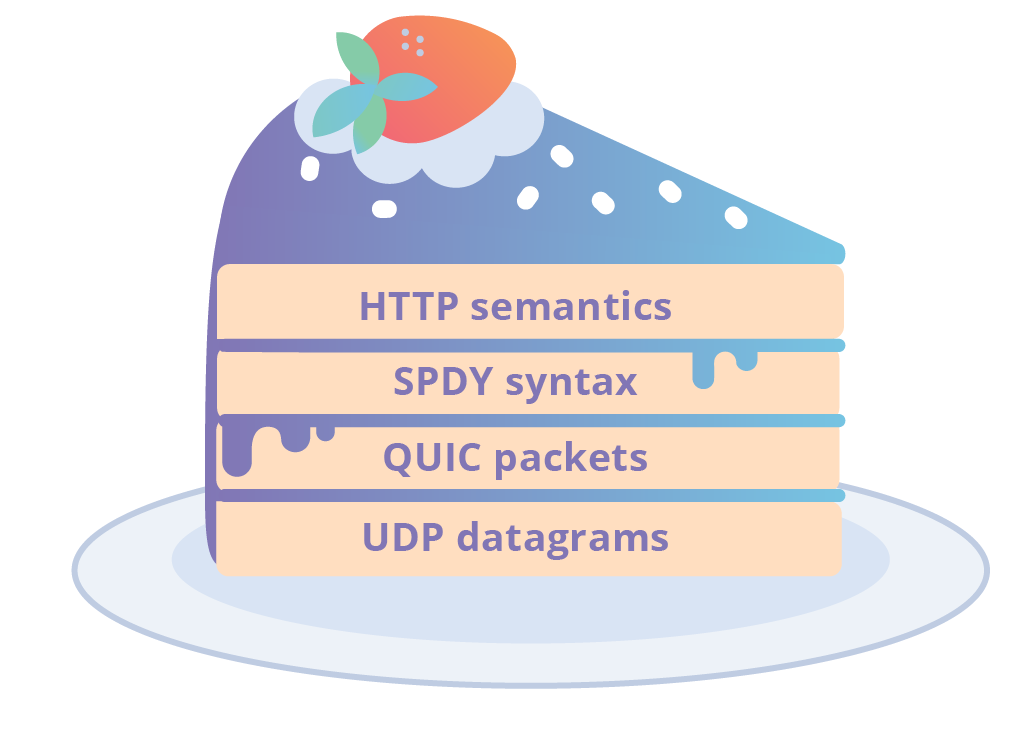 Tarte en couches SPDY par gQUIC
Tarte en couches SPDY par gQUICGQUIC a utilisé des astuces pour augmenter les performances. L'un d'eux est de brouiller la ligne claire entre l'application et le transport. En pratique, cela signifie que gQUIC ne prend en charge que HTTP. Cette connexion était si forte que gQUIC, qui s'appelait à l'époque QUIC, était considéré comme un candidat pour la prochaine version de HTTP. Bien que de nombreuses modifications aient été apportées à QUIC à l'avenir, à ce jour, de nombreuses personnes pensent qu'il ne prend en charge que HTTP. Malheureusement, cela conduit à une confusion constante lors de la discussion du protocole.
gQUIC a continué d'évoluer et est finalement passé à une syntaxe beaucoup plus proche de HTTP / 2. Si proche que la plupart des gens ont commencé à l'appeler "HTTP / 2 by QUIC". Mais en raison de limitations techniques, des différences très subtiles sont apparues. Un exemple est la sérialisation et l'échange d'en-têtes HTTP. Il s'agit d'une différence mineure, mais dans la pratique, cela signifie que gQUIC HTTP / 2 n'est pas compatible avec IETF HTTP / 2.
Enfin et surtout, vous devez toujours considérer les aspects de sécurité des protocoles Internet. Et les développeurs de gQUIC ont décidé d'abandonner TLS au profit d'une autre approche appelée QUIC Crypto. L'une des innovations intéressantes, il existe une nouvelle méthode d'accélération des poignées de main. Après avoir établi une session sécurisée avec le serveur, le client peut réutiliser les informations et fixer l'heure «zéro» de la prise de contact, c'est-à-dire 0-RTT. Cette astuce a ensuite été incluse dans le protocole TLS 1.3.
Puis-je enfin découvrir ce qu'est HTTP / 3?
Presque.
Nous comprenons maintenant comment fonctionne la normalisation. Ainsi, la considération gQUIC s'est déroulée selon le même scénario. En juin 2015, le premier
projet de projet-tsvwg-quic-protocol-00 , intitulé «QUIC: Transport UDP sécurisé et fiable pour HTTP / 2», a été introduit. Mais n'oubliez pas qu'au final la syntaxe du protocole est quasiment mise en compatibilité avec HTTP / 2.
Google a
annoncé que "BoF se tiendra lors de la réunion de l'IETF 93 à Prague". Si vous êtes intéressé par ce qu'est BoF, veuillez vous référer à la
RFC 6771 . En bref, BoF (
Birds of a Feather ) est une réunion informelle lors d'une conférence.
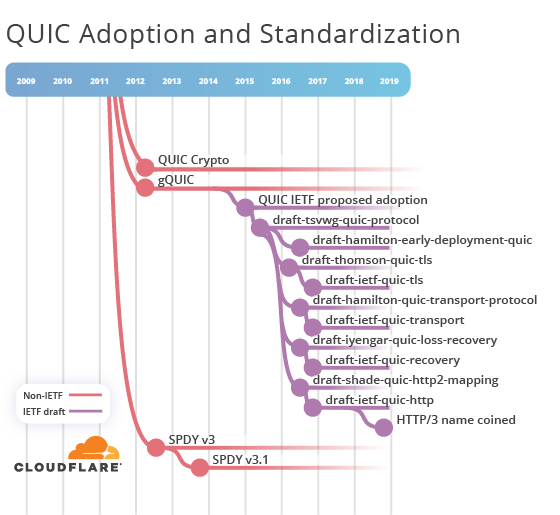
À la suite de la discussion avec l'IETF, il a été décidé que QUIC présente de nombreux avantages au niveau du transport, vous devez séparer ce protocole de HTTP et réintroduire une séparation claire entre les couches. De plus, pour ce protocole, ils ont décidé de retourner la poignée de main basée sur TLS (ce qui n'est pas si mal, car à ce moment-là TLS 1.3 avec le schéma 0-RTT avait déjà été développé).
Environ un an plus tard, en 2016, un nouvel ensemble de projets a été publié:
C'est là que la confusion est revenue:
draft-shadow-quic-http2-mapping-00 est appelé "HTTP / 2 Semantics Using the QUIC Transport Protocol" et décrit "HTTP / 2 Semantic Mapping over QUIC". Cependant, ce n'est pas le bon nom. L'essence de HTTP / 2 est de changer la syntaxe tout en conservant la sémantique. De plus, «HTTP / 2 by gQUIC» n'a jamais été une description précise de la syntaxe, pour les raisons que j'ai décrites précédemment. Gardez cela à l'esprit lorsque vous vous familiariserez avec les événements futurs.
Cette version de QUIC de l'IETF devrait devenir un tout nouveau protocole de transport. C'est une entreprise sérieuse, donc l'IETF a essayé d'évaluer l'intérêt de ses membres pour le projet. Pour ce faire, lors de la réunion de l'IETF 96 à Berlin en 2016, une session BoF (
slides ) a été organisée. J'ai eu la chance d'assister personnellement à la réunion, qui a attiré des centaines de participants, comme en témoigne la
photographie d'Adam Roach . En conséquence, un consensus a été atteint: QUIC sera adopté et normalisé par l'IETF.
Le premier projet IETF QUIC
draft-ietf-quic-http-00 pour traduire HTTP en transport QUIC a logiquement simplifié le nom du protocole en «HTTP sur QUIC» (HTTP sur QUIC). Malheureusement, le travail n'était pas terminé, donc différents termes HTTP / 2 ont été utilisés dans toute l'organisation. Mike Bishop, le nouvel éditeur de référentiel standard, a vu le problème et a commencé à corriger les références HTTP / 2 incorrectes. Dans la prochaine version du protocole, la description est devenue «mappage de la sémantique HTTP sur QUIC».
Progressivement, au fil du temps et des versions plus récentes, le terme «HTTP / 2» a commencé à être utilisé moins fréquemment, si nécessaire, en pointant simplement vers la
RFC 7540 . Deux ans plus tard, en octobre 2018, la dix-septième version du projet (numéro 16) a été publiée. Bien que le protocole HTTP sur QUIC ressemble à HTTP / 2, il s'agit essentiellement d'une syntaxe HTTP indépendante et incompatible. Cependant, pour les personnes qui ne surveillent pas de près le travail de l'IETF (qui est un très grand pourcentage de la population mondiale), le titre du document ne reflète pas cette différence. L'une des tâches principales de la normalisation est la promotion de la communication et de l'interopérabilité. Et une chose aussi simple que nommer est devenue la principale cause de confusion dans la communauté.
Rappelez-vous ce qui a été dit en 2012: «HTTP / 2.0 signifie seulement que le format n'est pas compatible avec HTTP / 1.x pour le transport.» L'IETF a suivi ce précédent. Après de nombreuses discussions avant et pendant la conférence IETF 103, un consensus était encore atteint sur le changement de nom de «HTTP sur QUIC» en HTTP / 3.
Le monde s'est amélioré et nous pouvons passer à des discussions plus importantes.
Mais les RFC 7230 et 7231 ne sont pas d'accord avec votre définition de la sémantique et de la syntaxe!
Parfois, les noms des documents peuvent prêter à confusion. Voici les documents HTTP qui décrivent la syntaxe et la sémantique:
- RFC 7230 - Protocole de transfert hypertexte (HTTP / 1.1): syntaxe et routage des messages
- RFC 7231 - Hypertext Transfer Protocol (HTTP / 1.1): sémantique et contenu
Par de tels noms, on peut supposer que la sémantique fondamentale de HTTP est spécifique à une version spécifique de HTTP, c'est-à-dire HTTP / 1.1. Mais il s'agit d'un effet secondaire aléatoire de l'arbre généalogique HTTP. La bonne nouvelle est que le groupe de travail HTTPbis essaie de résoudre le problème. Certains courageux membres du GT ont entamé une nouvelle série de révisions du document. Ce travail est en cours en ce moment et est connu comme le travail HTTP Core (vous avez peut-être entendu parler de ce groupe de travail sous les noms HTTPtre ou HTTPter: tout est ambigu ici aussi) Leurs efforts vous permettront de compresser six brouillons en trois:
- Sémantique HTTP (draft-ietf-httpbis-semantics)
- Mise en cache HTTP (draft-ietf-httpbis-caching)
- Syntaxe et routage des messages HTTP / 1.1 (draft-ietf-httpbis-messaging)
Dans le cadre de ce nouveau cadre, il devient plus évident que HTTP / 2 et HTTP / 3 sont des définitions syntaxiques pour la sémantique générale de HTTP. Cela ne signifie pas qu'ils n'ont pas leurs propres fonctions en dehors de la syntaxe, mais cela devrait aider dans la suite de la discussion.
Tout mettre ensemble
Cet article a décrit superficiellement le processus de normalisation HTTP dans l'IETF au cours des trois dernières décennies. Sans toucher particulièrement aux détails techniques, j'ai essayé d'expliquer comment nous en sommes arrivés à HTTP / 3. Si vous avez manqué le milieu et cherché l'essence dans une phrase, alors voici:
HTTP / 3 est juste une nouvelle syntaxe HTTP qui fonctionne sur IETF QUIC, un transport multiplexé et sécurisé basé sur UDP . Il existe de nombreuses nuances techniques intéressantes, mais vous devez les reporter pour une autre fois.
Nous avons examiné les étapes importantes du développement de HTTP et TLS, mais séparément les unes des autres. Maintenant, à la fin de l'article, nous publions à nouveau le cladogramme complet. Vous pouvez l'étudier calmement et soigneusement dans un cadre confortable. Et pour les supersisteners: voici
une version absolument complète, y compris les brouillons .