L'année dernière, une vague d'articles sur les fêtes dans la Silicon Valley, avec une certaine atmosphère hollywoodienne, mais sans spécifier de noms spécifiques, de photographies et sans décrire les technologies de développement matériel et d'écriture de logiciels associées à ces noms, a passé une vague d'articles dans la presse russe et ukrainienne. Cet article est différent! Il aura également des milliardaires, des génies et des filles, mais avec des photos, des diapositives, des diagrammes et des fragments de code de programme. Donc:
L'autre jour, le maire de Campbell, avec le nom russe Paul Resnikoff, a coupé le ruban à l'ouverture du nouveau bureau de démarrage de Wave Computing, qui, avec Broadcom, développe une puce de 7 nanomètres pour accélérer le calcul des réseaux de neurones. Le bureau est situé dans le bâtiment de l'usine historique de conserves de fruits et de conserves de la fin du XIXe et du début du XXe siècles, lorsque la Silicon Valley était le plus grand verger du monde. Même alors, le bureau était engagé dans l'innovation, introduisit le premier dans l'industrie des moteurs électriques d'abricot-prune pour les convoyeurs, pour lequel environ 200 employés, principalement des femmes, travaillaient.
Lors de la fête qui a suivi la coupe du ruban, de nombreuses personnes célèbres de l'industrie ont été mises à l'honneur, y compris le camarade d'armes de Kernigan-Richie et l'auteur du compilateur C le plus populaire de la fin des années 70 - début des années 80, Stephen Johnson, l'un des auteurs de la norme à nombre à virgule flottante Jerome Kunen, inventeur concepts de bus locaux et le premier développeur de chipset PC AT Diosdado Banatao, anciens développeurs de processeurs Sun, DEC, Cyrix, Intel, AMD et Silicon Graphics, Qualcomm, Xilinx et Cypress chips, analystes industriels, une fille aux cheveux roux et d'autres habitants de Californie mpany de ce type.
À la fin de l'article, nous parlerons des livres à lire et des exercices à faire pour rejoindre cette communauté.
Commençons par Jerome Kunen, un innovateur en arithmétique à virgule flottante et gestionnaire Apple depuis le premier Macintosh.
Les dissertations de candidats ne sont pas si courantes qu'elles affectent le calcul sur des milliards d'appareils. C’est ce que Diser (à gauche) de Jerome Kunen, Contributions to a Proposed Standard for Binary Floating Point Arithmetic, dont les résultats ont été inclus dans les nombres à virgule flottante de la norme IEEE 754. Après avoir obtenu son diplôme de l'école supérieure de Berkeley en 1982, Jerome est allé travailler chez Apple, où il a introduit la bibliothèque à virgule flottante dans le premier Macintosh.
Après 10 ans de gestion chez Apple, Kunen a consulté Hewlett-Packard et Microsoft et, en 2000, a optimisé l'arithmétique 128 bits pour la nouvelle version x86 64 bits d'AMD. Jerome a récemment tourné son attention vers la recherche sur les normes à virgule flottante pour les réseaux de neurones, en particulier les différends concernant Unum et Posit. Unum est le nouveau standard proposé, promu par le scientifique de Caltech John Gustafson, l'auteur du livre désormais bruyant The End of Error, «The End of Error». Posit est une version d'Unum qui peut être implémentée plus efficacement (*) que Unum dans le matériel.
(*) Plus efficace en combinaison de paramètres: fréquence d'horloge, nombre de cycles par opération, débit du convoyeur, surface relative sur la puce et consommation d'énergie relative.

Images d'articles (pas de Jérôme)
Rendre les calculs à virgule flottante très efficaces pour le matériel AI et
Battre Floating Point à son propre jeu: Posit Arithmetic de John L. Gustafson et Isaac Yonemoto :

Mais à la fête, Stephen / Steve Johnson est la personne sur le compilateur à qui le langage de programmation C est devenu populaire. Le premier compilateur C a été écrit par Denis Ritchie, mais le compilateur de Richie était étroitement lié à l'architecture PDP-11. Steve Johnson, basé sur le travail d'Alan Snyder, a écrit au milieu des années 1970 le Portable C Compiler (PCC), qui était facile à refaire pour générer du code pour différentes architectures. Dans le même temps, le compilateur Johnson fonctionnait rapidement et optimisait. Comment y est-il parvenu?
À l'entrée du PCC, Steve Johnson a utilisé l'analyseur LALR (1) généré par YACC (Yet Another Compiler Compiler), également écrit par Steve Johnson. Après cela, la tâche de compilation a été réduite à la manipulation des arbres dans les fonctions récursives et à la génération de code à partir de la table de modèles. Certaines de ces fonctions récursives étaient indépendantes de la machine, l'autre partie a été écrite par des personnes qui ont transféré le PCC sur une autre machine. La table de modèle était constituée d'entrées de règle de type "si un registre de type A et deux registres de type B sont libres, reconstruisez l'arborescence en un nœud de type C et générez du code avec une chaîne D". La table dépendait de la machine.
En raison de la combinaison d'élégance, de flexibilité et d'efficacité, le compilateur PCC a été transféré à plus de 200 architectures - de PDP, VAX, IBM / 370, x86 au soviétique BESM-6 et Orbit 20-700 (un ordinateur de bord dans les premières versions du MiG-29). Selon Denis Ritchie, presque tous les compilateurs C du début des années 80 étaient basés sur PCC. Du monde BSD Unix, PCC a été supplanté en tant que compilateur GNU GCC standard en 1994.
Outre PCC et Yacc, Steve Johnson est également l'auteur du programme de vérification du programme Lint original (voir, par exemple, l'
article de 1978 ). Les noms des programmes Yacc et Lint sont depuis devenus des noms communs. Dans les années 2000, Steve a réécrit le front-end de MATLAB et a écrit MLint. Maintenant, Steve Johnson est occupé à paralléliser les algorithmes de calcul des réseaux de neurones sur des appareils tels que CGRA (Coarse-Grained Reconfigurable Architecture), avec des dizaines de milliers d'éléments de type processeur qui sont répartis par des tenseurs à travers un réseau de dizaines de milliers de commutateurs à l'intérieur d'une puce massive avec des milliards de transistors:

Mais avec un verre de vin, le milliardaire Diosdado Banatao, fondateur de Chips & Technologies, S3 Graphics et investisseur à Marvell. Si vous avez programmé un PC IBM en 1985-1988, quand ils sont apparus pour la première fois en URSS, alors vous savez peut-être qu'à l'intérieur de la plupart des AT-shek avec des graphiques EGA et VGA, il y avait des chipsets de Chips & Technologies, qui sont sortis simultanément avec ceux d'IBM. Les premiers chipsets C&T ont été conçus par Banatao, qui avait appris à devenir ingénieur en électronique à Stanford, et avant de travailler comme ingénieur chez Boeing. En 1987, Intel a acquis Chips & Technologies.


À gauche dans l'image ci-dessous, John Bourgoin, président de MIPS Technologies depuis son apogée dans les années 2000, lorsque des puces avec des noyaux MIPS étaient à l'intérieur de la plupart des lecteurs DVD, appareils photo numériques et téléviseurs, avec des chipsets de Zoran, Sigma Design, Realtek, Broadcom et d'autres sociétés. Avant cela, John était président de MIPS Silicon Graphics depuis 1996, lorsque les processeurs MIPS se trouvaient à l'intérieur des stations de travail Silicon Graphics qu'Hollywood utilisait pour tourner les premiers films réalistes 3D Jurassic Park. Avant Silicon Graphics, John était l'un des vice-présidents d'AMD depuis 1976.
Art Swift, à droite, était vice-président du marketing pour MIPS dans les années 2000, et avant cela dans les années 1980, il a travaillé comme ingénieur chez Fairchild Semiconductor (oui, celui-là), puis vice-président du marketing chez Sun, DEC, Cirrus Logic, et Président de Transmet. Récemment, Art a été vice-président du comité marketing de RISC-V et connaît bien Syntacore et CloudBear en Russie dans ce poste. Et maintenant, il est devenu le président de l'IP MIPS de Wave:

Les diapositives de la
présentation sur l'histoire du MIPS liées à la période où le MIPS était contrôlé par John Bourgoin, dans l'image ci-dessus à gauche:

La société Transmet, dont le président était Art Swift depuis un certain temps, dans l'image ci-dessus à droite, a sorti le processeur Crusoe à la fin des années 1990, qui pouvait suivre les instructions x86 et atteindre le marché des sous-ordinateurs portables Toshiba Libretto L, des ordinateurs portables NEC et Sharp , client léger de Compaq. Leur avantage concurrentiel sur Intel et AMD était réglé sur une faible consommation d'énergie contrôlée.
La mise en œuvre directe et la vérification de la suite x86 complète étant une entreprise très coûteuse, Transmeta a fait le contraire, ce qui ressemble au chemin de la société russe MTsST avec le processeur Elbrus (la ligne qui a commencé avec Elbrus 2000 et est maintenant présentée sous le nom d'Elbrus 8C). Transmeta et Elbrus étaient basés sur un processeur structurellement simple avec une microarchitecture VLIW, et le niveau d'émulation x86 fonctionnait en plus en utilisant la technologie que Transmeta appelait le morphing de code.
L'idée de VLIW (Very Long Instruction Word) est assez simple - plusieurs instructions de processeur sont explicitement déclarées comme une super instruction et sont exécutées en parallèle. Contrairement aux processeurs superscalaires, en particulier Intel à partir de PentiumPro (1996), dans lequel le processeur sélectionne plusieurs instructions dans la mémoire, puis décide quoi exécuter en parallèle et ce qui est séquentiel, sur la base d'une analyse automatique des dépendances entre les instructions.
Un processeur superscalaire est beaucoup plus compliqué que VLIW, car un superscalaire doit dépenser de la logique pour maintenir l'illusion d'un programmeur que toutes les instructions sélectionnées sont exécutées les unes après les autres, bien qu'en réalité il puisse y en avoir des dizaines à l'intérieur du processeur, à différents stades d'exécution. Dans le cas de VLIW, la charge de maintenir une telle illusion incombe au compilateur à partir d'un langage de haut niveau. En fin de compte, le circuit VLIW se brise lorsque le processeur doit travailler avec un cache à plusieurs niveaux, ce qui a des retards imprévisibles qui rendent difficile pour le compilateur de planifier les instructions d'horloge. Mais pour les calculs mathématiques (par exemple, mettre Elbrus sur le radar et calculer le mouvement de la cible), c'est la chose, surtout dans des conditions de pénurie de personnel technique qualifié (plus de gens doivent vérifier le superscalaire).
Illustration de l'idée VLIW, du processeur Crusoe et du sous-ordinateur portable Toshiba Libretto L1:

Et ici au centre sur la photo ci-dessous Derek Meyer, Derek Meyer, actuel PDG de Wave Computing. Avant Wave, Derek était PDG d'ARC, développeur de cœurs de processeur ARC utilisés dans les puces audio. Ces cœurs étaient
sous licence à l' époque
, notamment par la société russe NIIMA Progress , qui a ensuite autorisé les cœurs MIPS et
montré des puces basées sur eux lors d'une exposition à Kazan Innopolis . Derek Meyer a voyagé à plusieurs reprises en Russie, à Saint-Pétersbourg, où se trouvait l'équipe de développement de Virage Logic. En 2009, ARC a acquis Virage Logic, et en 2010, Synopsys, le leader mondial de la conception de puces, a acquis l'ARC.
A droite sur la photo -
Sergey Vakulenko , qui à l'aube de sa carrière était à l'origine de Runet, travaillait dans la coopérative Demos et à l'Institut Kurchatov, qui a amené Internet en URSS. Maintenant, Sergey écrit un modèle à cycle précis de l'élément de processeur Wave pour calculer les réseaux de neurones, et auparavant, il a écrit des modèles précis des cœurs MIPS qui ont été utilisés pour vérifier les cœurs de processeur MIPS I6400 Samurai, I7200 Shaolin et autres.

Voici Vadim Antonov et Sergey Vakulenko en 1990, avec le premier ordinateur de l'URSS connecté à Internet:

Et voici Larry Hudepohl à droite (Hüdepol est orthographié en russe?). Larry a commencé sa carrière chez Digital Equipment Corporation (DEC) en tant que concepteur de processeurs pour MicroVAX. Ensuite, Larry a travaillé pour une petite entreprise Cyrix, qui à la fin des années 1980 a mis au défi Intel et a fabriqué un coprocesseur FPU compatible avec Intel 80387 et 50% plus rapide. Larry a ensuite conçu les puces MIPS chez Silicon Graphics. Lorsque MIPS Technologies s'est séparé de Silicon Graphics, Larry et Ryan Quinter ont lancé ensemble le premier produit MIPS indépendant, MIPS 4K, qui est devenu l'épine dorsale de la gamme qui a dominé l'électronique domestique des années 2000 (lecteurs DVD, appareils photo, téléviseurs numériques). Ensuite, le MIPS 5K a volé dans l'espace - il a été utilisé par l'agence spatiale japonaise JAXA. Ensuite, Larry, en tant que VP Hardware Engineering, a dirigé le développement des lignes suivantes, et maintenant il travaille sur de nouvelles architectures d'accélérateurs Wave.

Le vaisseau spatial japonais, fièrement nommé Hayabusa-2 (Sapsan-2), qui a
atterri à la surface de l'astéroïde Ryugu l'an dernier , est contrôlé par le processeur HR5000 basé sur le cœur du processeur MIPS 5Kf, qui est sous licence depuis longtemps par MIPS Technologies.
Voici un pipeline série simple du cœur du processeur MIPS 5Kf 64 bits de sa
fiche technique :

Droit sur la photo - Darren Jones, Darren Jones. Il était directeur de l'ingénierie matérielle chez MIPS, qui a dirigé le développement de cœurs complexes, avec du multithreading matériel et des superscalaires avec une extraordinaire exécution d'instructions. Puis Darren est allé à Xilinx, où il a été impliqué dans les puces Xilinx Zynq, sur lesquelles se trouve une combinaison de FPGA et de processeurs ARM. Darren est maintenant vice-président de l'ingénierie chez Wave.
Au MIPS, Darren était le chef d'un groupe dont les membres sont ensuite allés travailler pour Apple et Samsung. Le concepteur Monica, qui est allé chez Samsung, m'a dit une fois une phrase dont je me souvenais bien: "Conception RTL: quelques principes simples et le reste triche" (conception matérielle au niveau du registre: quelques principes simples, tout le reste est muhlezh ") Un exemple canonique d'un muhlezh est un cache (le programme a écrit des données et les a lues, mais elles ne seront mémorisées que plus tard), mais ce n'est qu'un cas très spécial de ce que Monica a pu faire.

Le multithreading matériel et une superscalaire extraordinaire sont deux approches différentes pour améliorer les performances du processeur. Le multithreading matériel vous permet d'augmenter le débit sans grande consommation d'énergie, mais avec une programmation non triviale. Le superscalaire vous permet d'exécuter des programmes à un seul thread environ deux fois plus vite, mais dépense également deux fois plus de watts. Mais sans astuces de programmation.
Enfin, le multithreading matériel était bien expliqué dans Wikipedia russe, voici son
multithreading temporaire (il est implémenté dans MIPS interAptiv et MIPS I7200 Shaolin), mais le
multithreading simultané (il a été réalisé dans les processeurs DEC Alpha dans les années 1990, puis dans SPARC, puis dans MIPS I6400 Samurai / I6500 Daimyo).
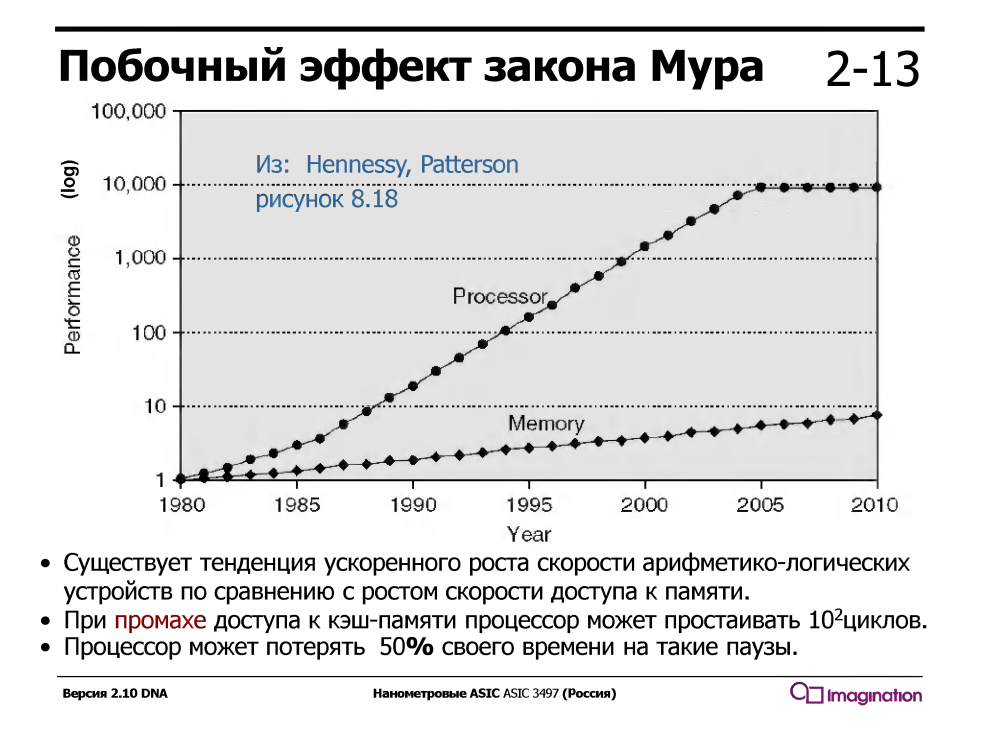
Le multithreading temporaire exploite le fait qu'un processeur avec un pipeline série conventionnel est inactif / attend la moitié du temps d'exécution. Qu'attend-il? Les données qui passent par les caches de la mémoire. Et cela attend longtemps - en attendant un échec de cache, le processeur pourrait exécuter des dizaines, voire cent ou deux instructions arithmétiques simples telles que l'addition.
Ce n'était pas toujours le cas - dans les années 1960, les dispositifs arithmétiques étaient beaucoup plus lents que la mémoire. Mais depuis environ 1980, la vitesse des cœurs de processeur a augmenté beaucoup plus rapidement que la vitesse de la mémoire, et même l'apparition de caches à plusieurs niveaux dans les processeurs n'a résolu le problème que partiellement.
Les processeurs avec multithreading temporaire prennent en charge plusieurs ensembles de registres, un pour chaque thread, et lorsque le thread actuel attend des données de la mémoire lors d'un échec de cache, le processeur bascule vers un autre thread. Cela se produit instantanément, dans un cycle, sans interruptions et des milliers de cycles du gestionnaire d'interruption, qui est activé lors du multithreading logiciel (et non matériel).
Voici l'idée du multi-threading
sur les diapositives des ateliers de Charles Danchek , professeur à l'Université de Californie à Santa Cruz, Silicon Valley Extension. Pourquoi en russe? Parce que Charles Danchek a donné des conférences au MISiS de Moscou, puis à l'ITMO de Saint-Pétersbourg et au KPI de Kiev:


Fait intéressant, le matériel multi-thread peut être programmé simplement en C. Voici à quoi ça ressemble:
#include "mips/m32c0.h" #include "mips/mt.h" #include "mips/mips34k.h"
Ici, du côté de la fête, se trouve l'appareil Wave pour les centres de données. Cela ne fonctionne pas encore complètement, bien que les puces soient disponibles pour certains clients dans le cadre du programme bêta:

Que fait cet appareil? Savez-vous comment programmer en Python? Ici en Python, vous pouvez construire en utilisant la bibliothèque TensorFlow appelle le soi-disant Data Flow Graph (DFG). Les réseaux de neurones sont essentiellement de tels graphes spécialisés avec des opérations sur des matrices. Dans le groupe de logiciels Wave, dont une partie est dirigée par Steve Johnson, il y a un compilateur avec un sous-ensemble de la représentation Google TensorFlow dans les fichiers de configuration pour les puces de cet appareil. Après configuration, il peut faire le calcul de tels graphes très rapidement. L'appareil est conçu pour les centres de données, mais le même principe peut être appliqué aux petites puces, même à l'intérieur des appareils mobiles, par exemple pour la reconnaissance faciale:

Chijioke Anyanwu (à gauche) - Pendant de nombreuses années, il a été le gardien de l'ensemble du système de test du cœur du processeur MIPS. Baldwyn Chieh (au centre) est le concepteur de la nouvelle génération d'éléments de type processeur dans Wave. Baldwin était un designer senior chez Qualcomm. Voici les
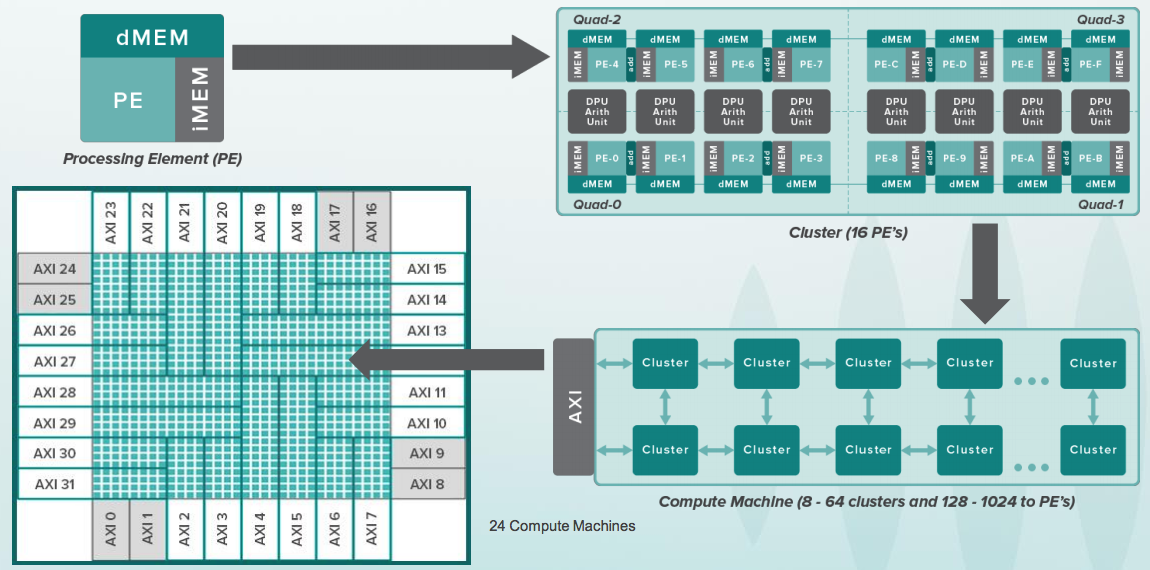
diapositives sur l'appareil Wave de la conférence HotChips :


Chaque IA de l'innovation numérique nanométrique de chaque entreprise de la Silicon Valley doit avoir sa propre fille aux cheveux brillants. Voici une telle fille dans Wave. Son nom est Athena, elle est sociologue de formation et est engagée dans le bureau:

Et voici à quoi ressemble le bureau de l'extérieur, et son histoire plus que centenaire de l'époque où il était une conserverie innovante:


Et maintenant, la question est: comment comprendre l'architecture, la microarchitecture, les circuits numériques, les principes de conception des puces AI et participer à de telles fêtes? Le moyen le plus simple est d'étudier le manuel «Circuit numérique et architecture informatique» de David Harris et Sarah Harris, et d'aller à Wave Computing pour le stagiaire d'été (il est prévu d'embaucher 15 stagiaires pour l'été). J'espère que cela pourra également se faire dans des sociétés russes de microélectronique engagées dans des développements similaires - ELVIS, Milander, Baikal Electronics, IVA Technologies et plusieurs autres. A Kiev, cela peut théoriquement se faire dans la société Melexis, qui coopère avec le KPI.
L'autre jour, une nouvelle version enfin corrigée du manuel Harris & Harris a été publiée, qui devrait être gratuite ici
www.mips.com/downloads/digital-design-and-computer-architecture-russian-edition-second-edition-ver3 , mais ce lien ne fonctionne pas pour moi, et quand il fonctionnera, j'écrirai un article séparé à ce sujet. Avec des questions posées lors d'entretiens à Apple, Intel, AMD, et sur quelles pages de ce manuel (et d'autres sources) vous pouvez voir les réponses.