Après s'être rencontrés en 2019 et se reposer un peu du développement de nouvelles fonctionnalités pour Smart IDReader, nous nous sommes souvenus que nous n'avions rien écrit sur les processeurs nationaux depuis longtemps. Par conséquent, nous avons décidé de corriger d'urgence et de montrer un autre système de reconnaissance sur Elbrus.
En tant que système de reconnaissance, le système de reconnaissance des objets peints était considéré «dans des conditions incontrôlées par la méthode avec apprentissage selon un exemple» [1]. Ce système construit une description de l'image à partir de points singuliers et de leurs descripteurs, qu'il recherche dans une base de données indexée d'images. Nous avons analysé les performances de ce système et identifié la partie de bas niveau la plus longue de l'algorithme, qui a ensuite été optimisée à l'aide des outils de la plateforme Elbrus.
De quel type de système de reconnaissance parlons-nous?
Actuellement, la plupart des musées et galeries utilisent divers outils pour se familiariser indépendamment avec l'exposition. Avec les audioguides classiques, les applications mobiles utilisant des méthodes de traitement et d'analyse d'images se sont répandues. Certaines de ces applications reconnaissent des codes d'exposition graphiques (barre ou QR) [2], pour d'autres [3-4] les données d'entrée sont des cadres photo ou vidéo avec une exposition prise en gros plan (Smartify, Artbit). Bien entendu, les «guides mobiles» de cette dernière catégorie sont plus pratiques pour l'utilisateur [5] que les solutions avec saisie manuelle du numéro d'exposition ou reconnaissance QR: le numéro et le code sont assez petits, et leur recherche et saisie nécessite des actions supplémentaires qui ne sont pas liées à la revue d'exposition. C'est un tel système que nous considérerons.
La tâche de reconnaître les peintures dans les images a été formulée comme suit. Demander une image Q doit être assigné à l'une des classes C = \ {C_i \} _ {i \ in [0, N]}C = \ {C_i \} _ {i \ in [0, N]} où Ci - classe d'image i exposer à i in[1,N] , C0 - une classe d'autres images correspondant à la valeur "image inconnue". Pour chacun Ci ensemble d'images de référence Ti .
De plus, nous avons été guidés par les hypothèses suivantes:
- Demander une image Q obtenu à l'aide de la caméra d'un appareil mobile par un utilisateur non préparé lors d'une excursion, donc:
a) il peut contenir des défauts visuels - éblouissement, zones défocalisées, bruit;
b) l'angle, le cadrage, l'éclairage et l'équilibre des couleurs sont inconnus (Fig. 1a);
c) des objets étrangers, tels que des décors, des cadres, des visiteurs, peuvent être présents sur l'image (Fig. 1b). - Image de référence T Il s'agit d'une image haute résolution avec projection frontale d'une image ou de sa reproduction numérique. La norme ne contient pas d'objets étrangers ni de défauts visuels. Les normes peuvent être, par exemple, des pages numérisées qualitativement d'albums d'art (Fig. 2).
- L'image (à la fois sur la demande et sur la norme) peut s'appliquer à n'importe quel style - réalisme,
l'impressionnisme, l'abstractionnisme, le graphisme fractal, etc. - Nombre de cours N correspond à la taille de la collection et pour une galerie peut atteindre
des centaines de milliers d'expositions [6].

Figure 1 - Exemples de demandes d'images a) une photo est photographiée de loin en basse lumière, b) un visiteur est dans le cadre.

Figure 2 - Exemples d'images de référence pour les peintures a) Claude Monet "De Voorzaan en de Westerhem", b) Salvador Dali "La persistència de la memòria"
L'idée principale de notre solution à ce problème est basée sur la construction d'une description spéciale de l'image à partir de l'image d'entrée, qui est ensuite utilisée pour rechercher cette image dans la base de données de descriptions d'images de référence d'images haute résolution qui ne sont pas sujettes à des distorsions géométriques et autres défauts photographiques. Les coordonnées des points singuliers trouvés en utilisant l'algorithme YACIPE [7] et leurs descripteurs RFD agissent comme une telle description.
Pour chaque référence Ti construire une description, puis l'indexer - pour chaque point de la description, nous entrons un enregistrement du formulaire langlei,fi rangle dans un arbre de recherche de regroupement hiérarchique aléatoire [8], qui vous permet d'effectuer une recherche approximative des voisins les plus proches avec un gain de vitesse significatif par rapport à une recherche linéaire. La distance de Hamming est utilisée comme métrique, car nous utilisons un descripteur binaire.
Le processus de reconnaissance est le suivant:
Dans l'image de la demande Q zone de peinture QL pré-localisé en utilisant l'hypothèse de la rectangularité du cadre. La recherche de zone est effectuée à l'aide de l'algorithme de recherche quadrangle rapide [9] avec la restriction sur le rapport d'aspect supprimée. Cela évite les problèmes suivants:
- description insuffisante de la zone d'image en raison d'objets étrangers dans le cadre, qui peuvent avoir des points spéciaux avec les meilleures notes;
- les coûts de calcul pour comparer les descripteurs des zones situées en dehors de l'image;
- un décalage important dans l'échelle et l'angle entre la norme dans la base de données et l'image de l'image, ce qui conduit à un résultat incorrect de correspondance des descripteurs.
L'image dans la zone trouvée est normalisée projectivement:
Q∗=H(QL),
où H - transformation projective.
Créez une description compacte w∗ :
a) l'image est réduite à une taille standard tout en conservant des proportions afin de rendre l'algorithme plus résistant à la mise à l'échelle;
b) le bruit haute fréquence est supprimé par un filtre gaussien;
c) des points singuliers sont calculés sur l'image résultante, leur nombre est artificiellement limité à M Le meilleur par évaluation interne de YACIPE;
d) les descripteurs RFD couleur des voisinages des points singuliers trouvés sont calculés, car dans notre tâche, il était important de sauvegarder des informations sur les caractéristiques de couleur des images d'entrée. Par exemple, les images de la Fig. Il serait extrêmement difficile de distinguer sans elle;
d) ainsi, la description de l'image I peut être représenté comme: w ^ * = \ {\ langle p_i, f_i) \ rangle \} _ {i \ in [1, M]}w ^ * = \ {\ langle p_i, f_i) \ rangle \} _ {i \ in [1, M]} où pi= langlexi,yi rangle Sont les coordonnées du i-ème point singulier, et fi Est la poignée du voisinage du i-ème point singulier.
Pour chaque entrée langlep,f rangle inw∗ l'index effectue une recherche approximative des voisins les plus proches du descripteur f . La procédure de vote est appliquée aux descripteurs trouvés - le descripteur fi ajoute une voix à la norme Ti . Ensuite, K candidats candidats avec le plus grand nombre de votes sont sélectionnés.
Pour chacun K les options sélectionnées à l'aide de l'algorithme RANSAC, une recherche de transformation projective est effectuée H translation, dans une erreur géométrique donnée delta points de requête Q∗ aux points de référence T . Paire de points langlep,p′ rangle avec des descripteurs proches est considérée comme une correspondance valide si:
gauche|H(p)−p′ droite|< delta,p inw∗,p′ inwT
Comme résultat final, la norme est sélectionnée Tb pour lequel le nombre de comparaisons correctes s'est avéré être le maximum. Si elle est inférieure à une certaine valeur seuil R , le résultat sera la réponse «image inconnue» afin d'éviter les faux positifs (par exemple, dans les images pour lesquelles il n'y a pas de description de la norme dans la base de données de recherche).


Figure 3 - Claude Monet. Cathédrale de Rouen, façade ouest, lumière du soleil (à gauche) et cathédrale de Rouen, portail et tour Saint-Romain au soleil (à droite).
L'une des principales parties du système est la recherche de descripteurs proches utilisant la distance de Hamming comme métrique. Puisqu'elle est calculée plusieurs fois, cette étape prend beaucoup de temps de calcul et prend 65% du temps du système. C'est pourquoi nous l'avons optimisé.
Une toute petite description de l'architecture d'Elbrus
L'architecture de processeur d'Elbrus utilise le principe d'un mot de commande large (Very Long Instruction Word, VLIW). Cela signifie que le processeur exécute les instructions en groupes, et au sein de chaque groupe, il n'y a pas de dépendances et ces instructions sont exécutées en parallèle. Chacun de ces groupes est appelé un mot de commande large. De larges mots de commande sont générés par un compilateur d'optimisation, qui permet une analyse plus détaillée du code source, conduisant à une parallélisation plus efficace [10].
Une caractéristique de l'architecture Elbrus est les méthodes de travail avec la mémoire. En plus d'avoir un cache qui optimise le temps d'accès à la mémoire, les processeurs Elbrus prennent en charge une méthode matérielle-logicielle pour la pré-pagination des données. Cette méthode permet de prédire les accès à la mémoire et de pomper les données dans le tampon de données préliminaire. Le matériel du processeur comprend un périphérique spécial pour accéder aux baies (Array Access Unit, AAU), mais le besoin de permutation est déterminé par le compilateur, qui génère des instructions spéciales pour AAU. L'utilisation d'un périphérique d'échange est plus efficace que le placement d'éléments de tableau dans le cache, car les éléments de tableau sont le plus souvent traités séquentiellement et rarement utilisés plus d'une fois [11]. Cependant, il convient de noter que l'utilisation d'un tampon de pré-pagination sur Elbrus n'est possible que lorsque vous travaillez avec des données alignées. Pour cette raison, la lecture / écriture des données alignées se produit beaucoup plus rapidement que les opérations correspondantes pour les données non alignées.
De plus, les processeurs Elbrus prennent en charge plusieurs types de parallélisme en plus du parallélisme au niveau des commandes: SIMD-parallélisme, parallélisme des flux de contrôle, parallélisme des tâches dans un complexe multi-machine. La concurrence SIMD nous intéresse particulièrement.
Caractéristiques de l'utilisation du processeur d'extension SIMD Elbrus
L'utilisation d'extensions SIMD peut être effectuée en deux modes: automatique et direct. Dans le premier cas, la parallélisation des opérations est entièrement effectuée par le compilateur sans la participation du développeur. Ce mode est limité, car le code optimisé doit répéter complètement le comportement du code source, y compris le comportement en cas de débordement, d'arrondi, etc. Dans ce cas, le comportement des instructions d'extension SIMD peut différer sous ces aspects des instructions du processeur. De plus, les algorithmes utilisés dans les compilateurs sont imparfaits et ne sont pas toujours capables d'effectuer une parallélisation efficace. Cependant, les développeurs peuvent également accéder directement aux commandes d'extension SIMD à l'aide d'intrinsèques. Les intrinsèques sont des fonctions dont les appels sont remplacés par le compilateur avec du code haute performance pour une plate-forme donnée, en particulier, avec des commandes d'extension SIMD. Les processeurs Elbrus-4C et Elbrus-8C prennent en charge un ensemble d'intrinsèques dont la taille de registre est de 64 bits. Il comprend les opérations de conversion de données, l'initialisation des éléments vectoriels, les opérations arithmétiques, les opérations logiques au niveau du bit, la permutation des éléments vectoriels, etc.
Lors de l'utilisation d'intrinsèques sur la plate-forme Elbrus, une attention particulière doit être accordée à l'accès à la mémoire, car les tâches pratiques, par exemple les tâches de traitement d'image, nécessitent souvent une lecture déséquilibrée des données dans un registre 64 bits. Une telle lecture en elle-même est inefficace, car elle nécessite une paire de commandes de lecture et une commande ultérieure pour former un bloc de données, mais, plus important encore, un tampon d'échange de tableau ne peut pas être utilisé pour augmenter la vitesse d'accès aux données. Cependant, il convient de noter que le problème de l'accès inefficace aux données non alignées est pertinent pour les processeurs Elbrus-4C et Elbrus-8C, tandis que pour le nouveau Elbrus-8CV avec la 5ème version du système de commande, il est partiellement résolu. Il est prévu que les processeurs Elbrus avec la 6ème version du système d'instruction seront complètement résolus.
Cependant, sur les processeurs Elbrus-4C et Elbrus-8C, le traitement des données de bas niveau est efficacement effectué en tenant compte de l'alignement. Par exemple, pour les tableaux numériques, il peut consister en plusieurs étapes: traitement de la partie initiale (jusqu'à la bordure d'alignement 64 bits de l'un des tableaux), traitement de la partie principale à l'aide d'un accès mémoire aligné et traitement des éléments restants du tableau. Étant donné que l'analyse des pointeurs pendant la compilation n'est pas une tâche triviale, vous pouvez utiliser l' –faligned compilateur –faligned , avec lequel toutes les opérations d'accès à la mémoire sont effectuées de manière alignée.
La prochaine caractéristique de l'utilisation intrinsèque sur la plate-forme Elbrus est directement liée à son architecture VLIW. En raison de la présence de plusieurs dispositifs de logique arithmétique (ALU), qui fonctionnent en parallèle et sont chargés lors de la formation de mots de commande larges, plusieurs commandes peuvent être exécutées simultanément. Au total, les processeurs Elbrus-4C et Elbrus-8C disposent de six ALU qui peuvent être utilisées au sein d'une même équipe, mais chaque ALU prend en charge son propre ensemble d'intrinsèques. Des opérations simples, telles que l'ajout ou la multiplication d'éléments dans des registres 64 bits, prennent généralement en charge deux ALU. Cela signifie que le processeur Elbrus peut exécuter deux de ces instructions en un seul cycle d'horloge. Pour ce faire, exécuter le bouclage doit être utilisé dans le code exécutable. Le compilateur d'optimisation pour la plate-forme Elbrus prend en charge le pragma #pragma unroll(n) , qui permet le déploiement de n itérations de boucle.
Un exemple de l'implémentation de la fonction d'addition prenant en compte ces fonctionnalités se trouve dans notre article précédent.
Les expériences
Hourra, le texte est terminé et enfin nous allons lancer quelque chose sur Elbrus!
Tout d'abord, nous considérons séparément la distance de Hamming. Sans plus tarder, nous avons comparé deux vecteurs bit de données aléatoires. Les valeurs binaires étaient regroupées dans des tableaux d'entiers 8 bits, et pour simplifier, nous pensions que les longueurs des vecteurs d'origine étaient des multiples de 8. Comme d'habitude, le code est écrit en C ++, compilé par lcc 1.21.24 - un compilateur Elbrus optimisant.
Nous avons écrit plusieurs implémentations de la distance de Hamming, qui ont séquentiellement pris en compte les caractéristiques des processeurs Elbrus. Ils ressemblaient à ceci:
- Un XOR au niveau du bit entre des entiers de 8 bits et un tableau de valeurs précalculées sont utilisés. Il s'agit d'une implémentation de base sans intrisics et autres astuces.
- Il utilise XOR entre des entiers 32 bits et intrinsèques pour calculer le nombre d'unités dans un entier 32 bits - popcnt32. L'alignement des limites sur 32 bits n'a pas été effectué.
- Il utilise XOR entre des entiers 64 bits et intrinsèques pour calculer le nombre d'unités dans un entier 64 bits - popcnt64. L'alignement de bordure 64 bits n'a pas été effectué.
- Il utilise XOR entre des entiers 64 bits et intrinsèques pour calculer le nombre d'unités dans un entier 64 bits - popcnt64. L'accès à la mémoire s'effectue de manière alignée. Étant donné que les adresses de départ des tableaux peuvent avoir un alignement différent, lors de la lecture de l'un des tableaux, deux blocs 64 bits voisins sont lus et le bloc 64 bits nécessaire est formé à partir d'eux.
- Il utilise XOR entre des entiers 64 bits et intrinsèques pour calculer le nombre d'unités dans un entier 64 bits - popcnt64. L'accès à la mémoire s'effectue de manière alignée. Étant donné que les adresses de départ des tableaux peuvent avoir un alignement différent, lors de la lecture de l'un des tableaux, deux blocs 64 bits voisins sont lus et le bloc 64 bits nécessaire est formé à partir d'eux. En outre, l'
-faligned compilateur -faligned est -faligned . - Il utilise XOR entre des entiers 64 bits et intrinsèques pour calculer le nombre d'unités dans un entier 64 bits - popcnt64. L'accès à la mémoire s'effectue de manière alignée. Étant donné que les adresses de départ des tableaux peuvent avoir un alignement différent, lors de la lecture de l'un des tableaux, deux blocs 64 bits voisins sont lus et le bloc 64 bits nécessaire est formé à partir d'eux. De plus, l'
-faligned compilateur -faligned et les pragmas du compilateur #pragma unroll(2) unroll #pragma unroll(2) (pour utiliser les deux ALU disponibles pour calculer popcnt64) et #pragma loop count(1000) (pour activer des optimisations de #pragma loop count(1000) supplémentaires) ont été utilisés.
Les résultats des mesures de temps sont présentés dans le tableau 1.
Tableau 1. Temps de calcul de la distance de Hamming entre deux tableaux de nombres binaires compressés de longueur 10 ^ 5 sur une machine avec un processeur Elbrus-4C. Le temps moyen sur 10 ^ 5 commence.
| Non. | Une expérience | Temps, ms |
|---|
| 1 | tableau des valeurs calculées | 141.18 |
| 2 | popcnt32, pas d'alignement | 125,54 |
| 3 | popcnt64, pas d'alignement | 58,00 |
| 4 | alignement popcnt64 | 17,36 |
| 5 | alignement -faligned , -faligned | 17h15 |
| 6 | popcnt64, alignement, -faligned, pragma unroll | 12,23 |
On peut voir que toutes les optimisations considérées ont conduit à une diminution de 11,5 fois du temps d'exécution. Il est à noter que l'utilisation des intrinsèques pour un accès déséquilibré à la mémoire n'a montré une accélération que 1,13 fois (pour popcnt32) et 2,4 fois (pour popcnt64), tandis que la prise en compte de l'alignement des données a conduit à l'utilisation du tampon d'échange de tableau APB à l'aide duquel il a été possible d'accélérer encore 3,4 fois (58 ms contre 17,15 ms). Malgré le fait que l'utilisation de l'indicateur -faligned n'ait pas montré de gain de performances significatif dans l'exemple ci-dessus, dans des algorithmes plus complexes, il peut y avoir une situation où le compilateur ne peut pas analyser le code source suffisamment profondément pour générer des commandes pour APB. La prise en compte du nombre réel d'ALU spécialisés nous a permis d'accélérer les calculs de 1,4 fois.
Pas si mal! Comme nous avons comparé jusqu'à 6 options d'implémentation, nous donnons le pseudo-code du final, le plus rapide:
: 8- A B, T, T[i] i : res, A B offset ← A 64- effective_len ← , 64- for i from 1 to offset: res ← res + T[xor(A[i] , B[i])] v_a ← 64- , A[offset+1] v_b1 ← 64- , B[offset] v_b2 ← 64- , v_b1 // 64- for i from offset to effective_len: v_b ← align(v_b1, v_b2) // 64- , v_a res ← res + popcnt64(xor(v_a, v_b)) v_a ← 64- v_b1 ← v_b2 v_b2 ← 64- //
Il serait formidable d'accélérer une fois pour toutes le calcul de la distance de Hamming de 11,5 fois, mais dans la vie tout est un peu plus compliqué: une telle implémentation n'aura un avantage qu'avec des longueurs de tableaux suffisamment importantes. Dans la Fig. La figure 4 présente une comparaison du temps de calcul à l'aide du tableau des valeurs pré-calculées et de notre implémentation finale. Vous pouvez voir que lorsque notre version commence à gagner uniquement à partir de longueurs supérieures à 400 octets, et cela doit également être pris en compte lors de l'optimisation sur Elbrus.
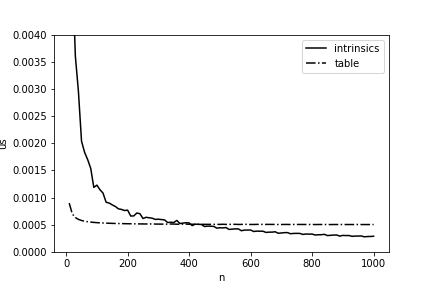
Figure 4 - Temps moyen (par 1 octet) pour calculer la distance de Hamming entre deux matrices en fonction de leur longueur à Elbrus-4C.
C'est tout, maintenant nous sommes prêts à mesurer le temps de fonctionnement de l'ensemble du système. Nous avons mesuré le temps de traitement moyen des demandes (hors chargement des images) pour 933 demandes. Lors de la compilation d'une description compacte de l'image, un descripteur binaire de type RFD couleur de 5328 bits a été utilisé. Il était composé de 3 descripteurs RFD gris concaténés de 1776 bits calculés pour chaque canal de la section d'image d'entrée. D'une part, de tels descripteurs longs ne plaisent pas à une vitesse de calcul et de comparaison élevée; d'autre part, ils fournissent une qualité de travail suffisamment élevée. Cependant, il y a de bonnes nouvelles - nous pouvons utiliser l'implémentation rapide de la distance de Hamming pour les comparer! Les longueurs des tableaux comparés sont de 666 octets, ce qui est supérieur à la valeur seuil de 400 octets pour Elbrus-4C.
Les résultats des mesures sont présentés dans le tableau 2. On peut voir qu'une seule implémentation rapide de la distance de Hamming donne un traitement de requête 1,5 fois plus rapide. Il convient également de noter que cette optimisation ne modifie pas les résultats des calculs, et donc la qualité de la reconnaissance.
Tableau 2. Temps de traitement moyen d'une demande à un système de reconnaissance d'objets de peinture dans des conditions non contrôlées.
| Une expérience | Temps de demande, s | Le calcul de la distance de Hamming a pris | Temps d'accélération |
|---|
| Implémentation de base | 2,81 | 63% | - |
| Implémentation rapide | 1,87 | 40% | 1,5 |
Conclusion
Dans cet article, nous avons parlé un peu de la structure du système de reconnaissance pour peindre des objets dans des conditions non contrôlées et montré une fois de plus comment les manipulations de bas niveau peuvent augmenter considérablement sa vitesse sur la plate-forme Elbrus. Ainsi, l'implémentation proposée de la distance de Hamming fonctionne un ordre de grandeur (!) Plus rapide que l'implémentation utilisant un tableau de valeurs pré-calculées avec une longueur suffisamment grande des vecteurs d'entrée, et l'ensemble du système a été accéléré une fois et demie! Pour atteindre ce résultat, des extensions SIMD ont été utilisées et les fonctionnalités d'architecture et d'accès à la mémoire des processeurs Elbrus-4C et Elbrus-8C ont été prises en compte. Ces résultats montrent que les processeurs Elbrus contiennent des ressources importantes pour un fonctionnement efficace, qui ne sont pas pleinement utilisées en l'absence d'une optimisation spécialement effectuée. Cependant, les méthodes d'accès à la mémoire devraient être améliorées sur les nouveaux processeurs Elbrus, ce qui permettra à certaines de ces optimisations d'être effectuées automatiquement et facilitera grandement la vie des développeurs.
Littérature
[1] N.S. Skoryukina, A.N. Milovzorov, D.V. Field, V.V. Arlazarov. La méthode de reconnaissance des objets de peinture dans des conditions incontrôlées avec une formation selon un exemple // Transactions d'ISA RAS. - Numéro spécial, 2018 - p. 5-15.
[2] Pérez-Sanagustín M. et al. Utiliser des codes QR pour augmenter l'engagement des utilisateurs dans des espaces de type musée // Computers in Human Behavior. - 2016. - T. 60. - S. 73-85. doi: 10.1016 / j.chb.2016.02.02.012
[3] Antoshchuk S. G., Godovichenko N. A. Analyse des caractéristiques ponctuelles de l'image dans le système Mobile Virtual Guide // Pratsi. - 2013. - Non. 1 (40). - S. 67-72.
[4] Andreatta C., Leonardi F. Reconnaissance des peintures basées sur l'apparence pour un guide de musée mobile // Conférence internationale sur la théorie et les applications de la vision par ordinateur, VISAPP. - 2006.
[5] Leonard Wein. 2014. Reconnaissance visuelle dans les applications de guides de musée: les visiteurs en veulent-ils? .. Dans les actes de la conférence SIGCHI sur les facteurs humains dans les systèmes informatiques (CHI '14). ACM, New York, NY, USA, 635-638.
doi: 10.1145 / 2556288.2557270
[6] Galerie Tretyakov, https://www.tretyakovgallery.ru/collection/
[7] Lukoyanov A. S., Nikolaev D. P., Konovalenko I. A. Modification de l'algorithme YAPE pour les images avec un large éventail de contraste local // Technologies de l'information et nanotechnologies. - 2018 .-- S. 1193-1204.
[8] Muja M., Lowe DG Correspondance rapide des fonctionnalités binaires // Computer and Robot Vision (CRV), 2012 Ninth Conference on. - IEEE, 2012 .-- S. 404-410.
doi: 10.1109 / CRV.2012.60
[9] Skoryukina, N., Nikolaev, DP, Sheshkus, A., Polevoy, D. (2015, février). Détection rectangulaire en temps réel de documents sur des appareils mobiles. Dans la septième conférence internationale sur la vision industrielle (ICMV 2014) (vol. 9445, p. 94452A). Société internationale d'optique et de photonique.
doi: 10.1117 / 12.2181377
[10] Kim A.K., Bychkov I.N. et d'autres technologies russes «Elbrus» pour les ordinateurs personnels, les serveurs et les superordinateurs // Technologies de l'information modernes et éducation informatique, M.: Foundation for the Development of Internet Media, IT Education, Human Potential «League of Internet Media», 2014, N ° 10, p. 39-50.
[11] Kim A.K., Perekatov V.I., Ermakov S.G. Microprocesseurs et systèmes informatiques
la famille Elbrus. - Saint-Pétersbourg: Peter, 2013 .-- 272 S.