Il n'y a pas si longtemps, nous avons publié une nouvelle version mineure 8.3.75005 du logiciel de prévention des fuites de données DeviceLock DLP et, entre autres améliorations, nous avons inclus la fonction de consolidation des données des serveurs de stockage qui est très utile pour les grandes entreprises.

Je voudrais parler un peu plus de la consolidation ...
Tout d'abord, un peu sur l'organisation de la collecte et du stockage des données interceptées dans DeviceLock DLP. Étant une solution d'agent pour empêcher la fuite d'informations, DeviceLock DLP intercepte, analyse et active / désactive le transfert de données directement vers les ordinateurs des utilisateurs à l'aide d'agents. En plus d'intercepter, d'analyser et de décider d'autoriser / refuser le transfert, les agents peuvent également (si spécifié par la politique) accumuler des données d'audit et de cliché instantané (une copie des informations transmises par les utilisateurs).
Le serveur de stockage DeviceLock Enterprise Server (DLES) est utilisé pour le stockage centralisé et la post-analyse ultérieure des données accumulées par les agents (par exemple, rapports, recherche d'archives, etc.). Un nombre illimité de ces serveurs peut être installé dans l'organisation (nous ne limitons pas leur nombre à une licence), ce qui vous permet de répartir uniformément la charge sur les segments de réseau individuels et de minimiser le temps de collecte des données auprès des agents. Pour les agents, plusieurs serveurs DLES peuvent être définis et les règles de choix d'un serveur lors du transfert des données accumulées vers l'archive sont spécifiées. Chaque DeviceLock Enterprise Server se connecte à un serveur SQL et stocke ses données dans une base de données distincte. De plus, plusieurs serveurs de stockage peuvent être connectés à un serveur SQL.
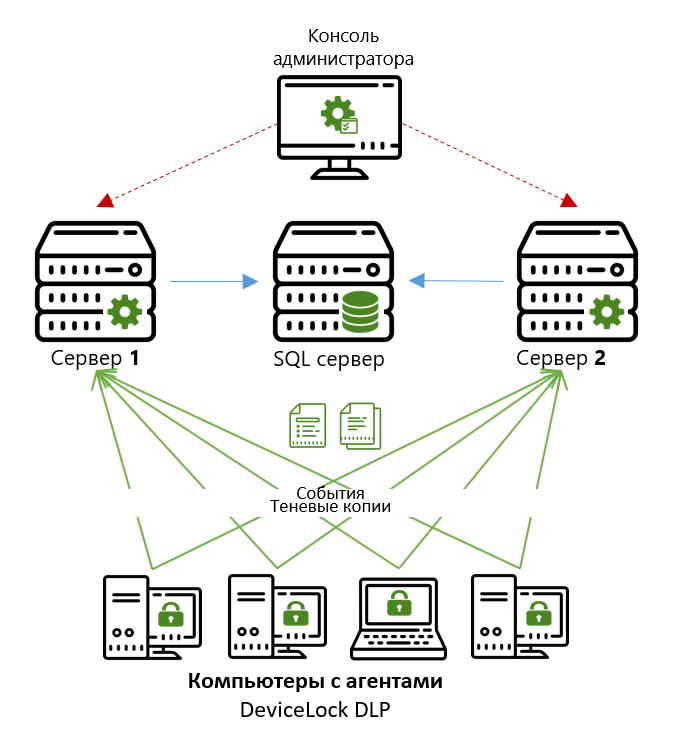
Si une organisation a plusieurs succursales, le schéma le plus souvent utilisé est lorsque chaque succursale a son propre serveur (ou plusieurs serveurs) pour le stockage, et que les données accumulées sont acheminées vers le bureau central selon un calendrier spécifié (une fois par jour, semaine, etc.).
Avant la publication de cette mise à jour, la réplication des données pouvait être effectuée à l'aide du serveur SQL, ce qui n'était pas très bon du point de vue de la commodité générale de la configuration du complexe. La non-trivialité de la réplication était particulièrement évidente dans une situation où plusieurs serveurs de stockage étaient connectés au même serveur SQL.
Nous proposons maintenant d'utiliser la fonction de consolidation, qui est beaucoup plus simple à configurer et à utiliser, dans laquelle la réplication planifiée des données est effectuée exclusivement par les outils DeviceLock Enterprise Server intégrés.
Je vais montrer sur un exemple «en direct» la configuration de base de la consolidation des données accumulées de quatre serveurs de stockage sur le serveur principal.
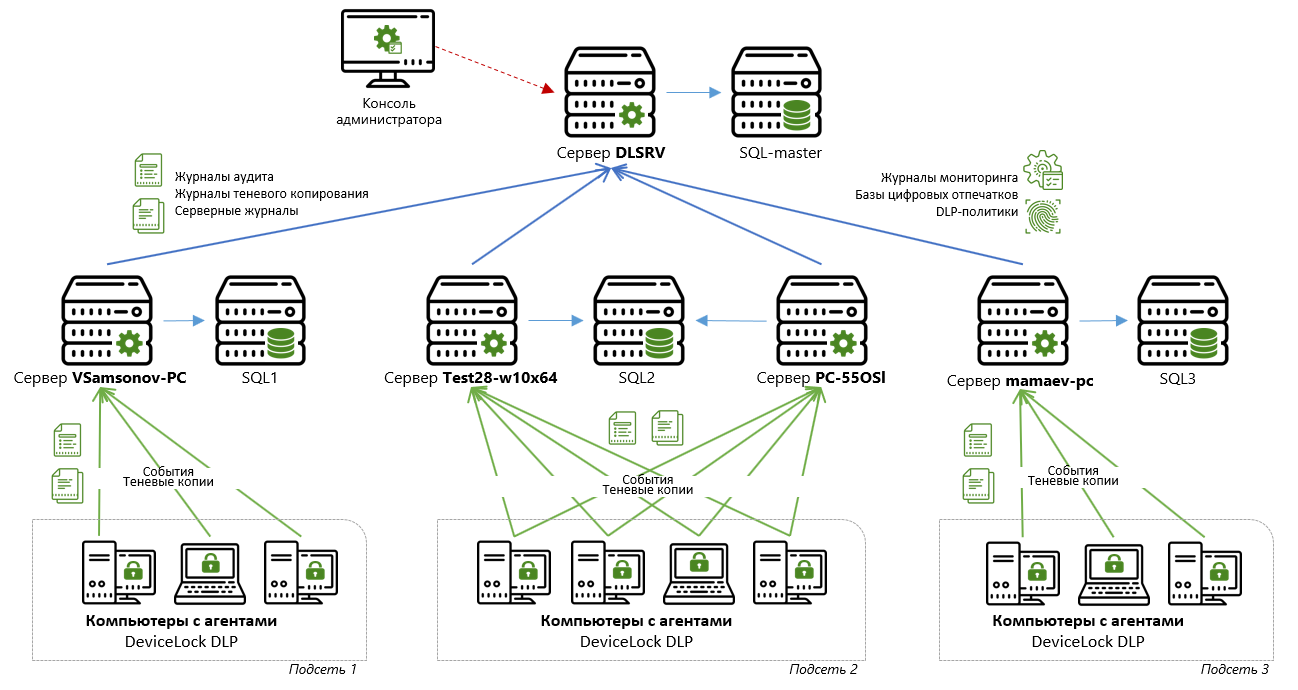
Le diagramme ci-dessus montre que deux serveurs (Test28-w10x64 et PC-55OSI) sont connectés au même serveur SQL (SQL2), tandis que les deux autres serveurs (VSamsonov-PC et mamaev-pc) sont chacun connectés à leur propre serveur SQL (SQL1 et SQL3, respectivement). La réplication des données sera effectuée sur le serveur maître DLSRV connecté au maître SQL.
Pour définir le calendrier et indiquer le serveur maître sur lequel les données doivent être répliquées, les paramètres de consolidation doivent être définis sur chacun des serveurs Test28-w10x64, PC-55OSI, VSamsonov-PC et mamaev-pc "en aval".
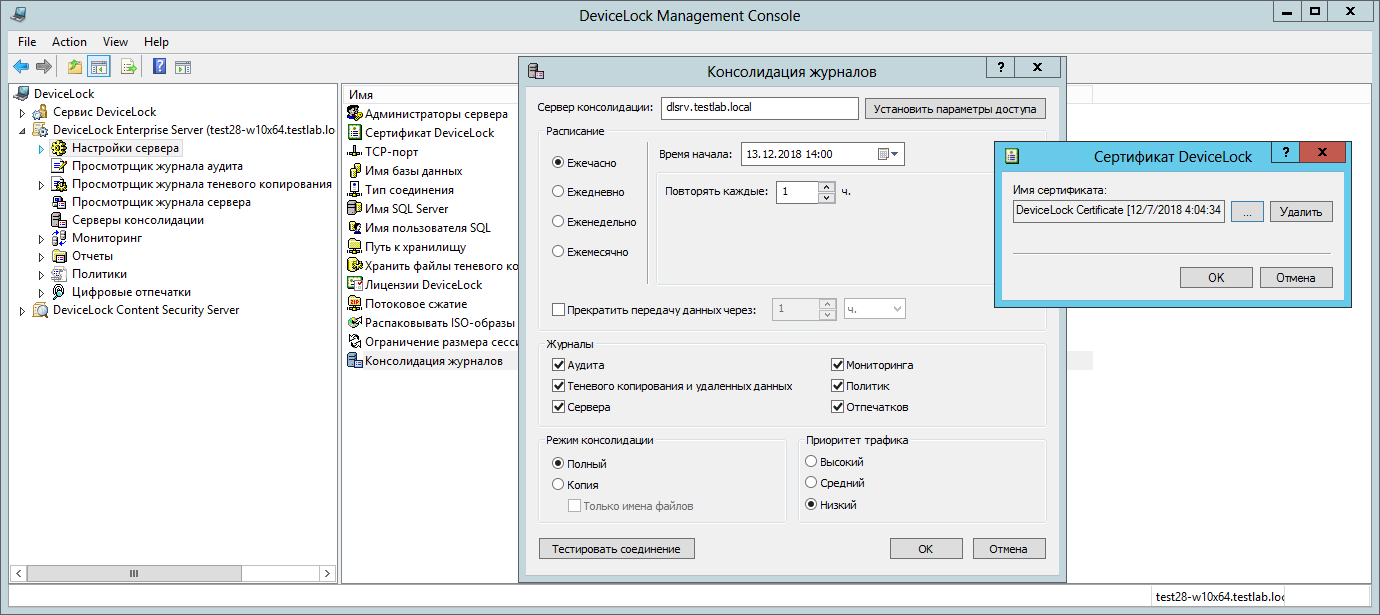
Entre autres choses, vous pouvez également indiquer ce qui doit être exactement répliqué (quels journaux), que ce soit pour copier des données ou les transférer, pour façonner un canal réseau ou pour les donner pour la consolidation dans son ensemble.
Après avoir réussi à établir une connexion entre "l'aval" et le serveur principal, des statistiques de consolidation apparaîtront dans l'interface de ce dernier.
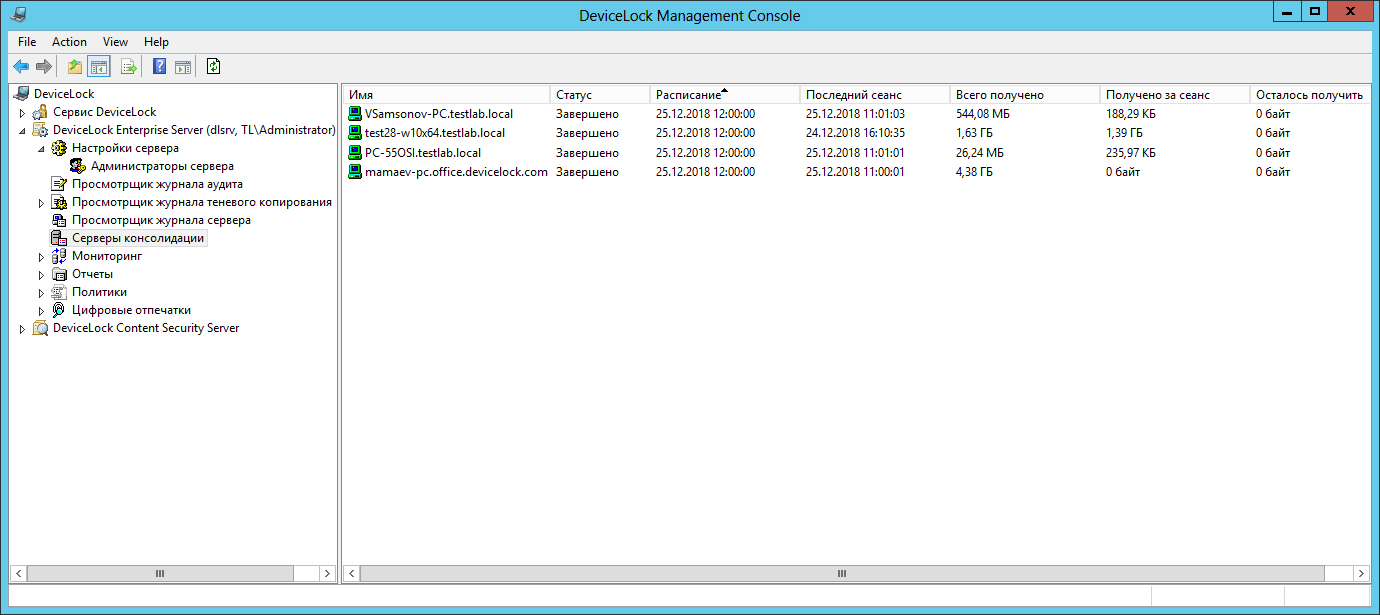
Vous pouvez voir les données collectées, comme d'habitude, dans la visionneuse standard du journal correspondant. Par exemple, pour un journal de cliché instantané, il ressemblerait à ceci:
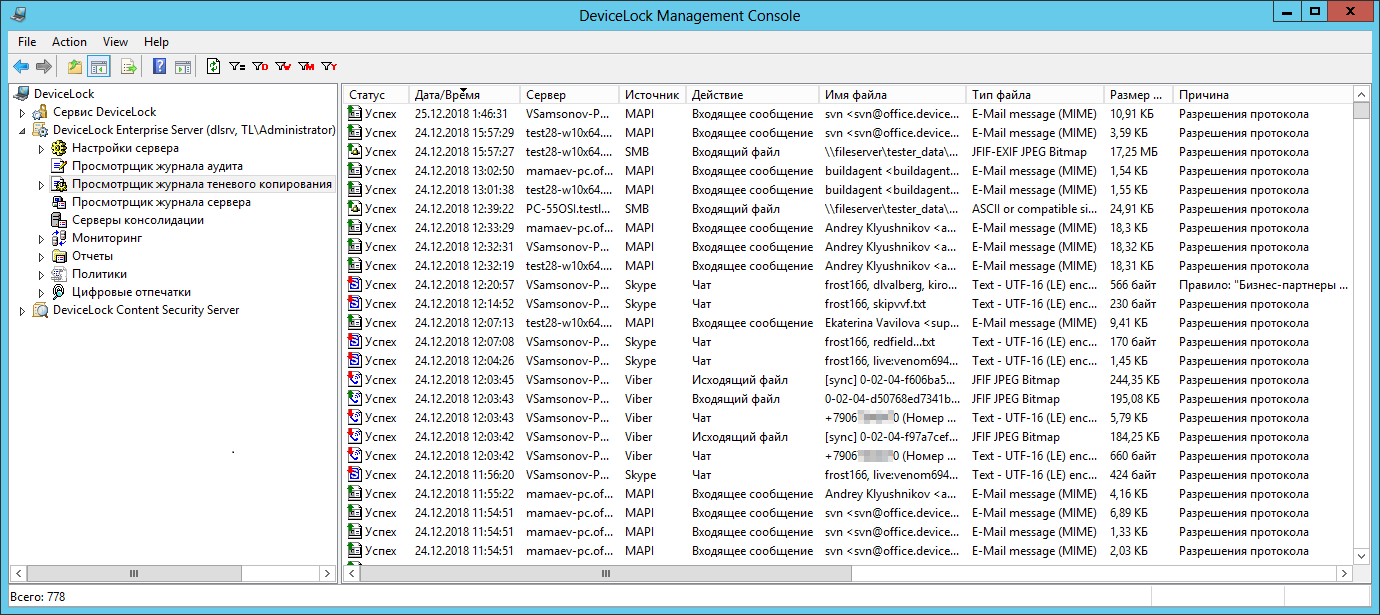
Le serveur d'origine qui a collecté les données des agents est affiché dans la colonne Serveur ici.
Par ailleurs, je tiens à noter que le "niveau d'imbrication" de la consolidation n'est pas limité. S'il sera nécessaire de répliquer les données du DLSRV ailleurs «vers le haut», alors simplement dans les paramètres de consolidation du DLSRV, vous devrez enregistrer son «serveur en amont». Et donc presque à l'infini;)