Il y a quelque temps, sous la marque VTB, trois grandes banques ont fusionné: VTB, ex-VTB24 et ex-Bank of Moscow. Pour les observateurs externes, la banque VTB combinée fonctionne désormais dans son ensemble, mais de l'intérieur, tout semble beaucoup plus compliqué. Dans cet article, nous parlerons des plans pour créer un réseau unifié de la banque VTB intégrée, partager des astuces de vie sur l'organisation de l'interaction des pare-feu, connecter et combiner des segments de réseau sans interrompre les services.
Difficultés d'interaction d'infrastructures disparates
Les opérations de VTB sont actuellement soutenues par trois infrastructures existantes: l'ancienne banque de Moscou, l'ex-VTB24 et la VTB elle-même. Les infrastructures de chacun d'entre eux ont leur propre ensemble de périmètres de réseau, à la frontière duquel se trouvent des équipements de protection. L'une des conditions d'intégration des infrastructures au niveau du réseau est l'existence d'une structure d'adressage IP cohérente.
Immédiatement après la fusion, nous avons commencé à aligner les espaces d'adressage, et maintenant elle est presque terminée. Mais le processus prend du temps et est rapide, et les délais pour organiser les accès croisés entre les infrastructures étaient très serrés. Par conséquent, dans un premier temps, nous avons connecté les infrastructures de différentes banques entre elles sous la forme telle qu'elles sont - par le biais du pare-feu pour un certain nombre de zones de sécurité principales. Selon ce schéma, afin d'organiser l'accès d'un périmètre de réseau à un autre, il est nécessaire d'acheminer le trafic à travers de nombreux pare-feu et autres moyens de protection, diffusés aux adresses conjointes des ressources et des utilisateurs utilisant les technologies NAT et PAT. De plus, tous les pare-feu aux jonctions sont réservés à la fois localement et géographiquement, et cela doit toujours être pris en compte lors de l'organisation des interactions et de la construction des chaînes de services.
Un tel schéma est assez fonctionnel, mais vous ne pouvez certainement pas l'appeler optimal. Il y a à la fois des problèmes techniques et organisationnels. Il est nécessaire de coordonner et de documenter les interactions de nombreux systèmes dont les composants sont dispersés sur différentes infrastructures et zones de sécurité. Parallèlement, dans le processus de transformation des infrastructures, il est nécessaire de mettre à jour rapidement cette documentation pour chaque système. La conduite de ce processus charge considérablement notre ressource la plus précieuse - des spécialistes hautement qualifiés.
Les problèmes techniques se traduisent par la multiplication du trafic sur les liaisons, la forte charge d'outils de sécurité, la complexité d'organisation des interactions réseau, l'impossibilité de créer certaines interactions sans traduction d'adresse.
Le problème de la multiplication du trafic se pose principalement en raison des nombreuses zones de sécurité interagissant entre elles via des pare-feu sur différents sites. Quelle que soit la situation géographique des serveurs eux-mêmes, si le trafic dépasse le périmètre de la zone de sécurité, il passera par une chaîne de fonctions de sécurité pouvant se trouver dans d'autres emplacements. Par exemple, nous avons deux serveurs dans un centre de données, mais un dans le périmètre de VTB et l'autre dans le périmètre de l'ancien réseau VTB24. Le trafic entre eux ne passe pas directement, mais passe par 3-4 pare-feu qui peuvent être actifs dans d'autres centres de données, et le trafic sera acheminé vers le pare-feu et inversé plusieurs fois via le réseau de jonction.
Pour garantir une haute fiabilité, nous avons besoin de chaque pare-feu en 3 à 4 copies - deux sur un site sous la forme d'un cluster HA et un ou deux pare-feu sur un autre site, vers lesquels le trafic basculera si le cluster de pare-feu principal ou le site dans son ensemble est interrompu.
Nous résumons. Trois réseaux indépendants représentent un
tas de problèmes : une complexité excessive, la nécessité d'équipements supplémentaires coûteux, des goulots d'étranglement, des difficultés de redondance et, par conséquent, des coûts élevés d'exploitation de l'infrastructure.
Approche générale d'intégration
Depuis que nous avons décidé d'entreprendre la transformation de l'architecture de réseau, nous allons commencer par les choses de base. Allons de haut en bas, nous allons commencer par analyser les besoins des entreprises, des candidats, des ingénieurs système et du personnel de sécurité.
- En fonction de leurs besoins, nous concevons la structure cible des zones de sécurité et les principes d'interconnexion entre ces zones.
- Nous imposons cette structure de zones à la géographie de nos principaux consommateurs - datacenters et grands bureaux.
- Ensuite, nous formons le réseau de transport MPLS.
- En dessous, nous apportons déjà le réseau principal qui fournit des services à la couche physique.
- Nous sélectionnons des emplacements pour le placement des modules de périphérie et des modules de pare-feu.
- Une fois l'image cible clarifiée, nous élaborons et approuvons la méthodologie de migration de l'infrastructure existante vers l'infrastructure cible afin que le processus soit transparent pour les systèmes en fonctionnement.
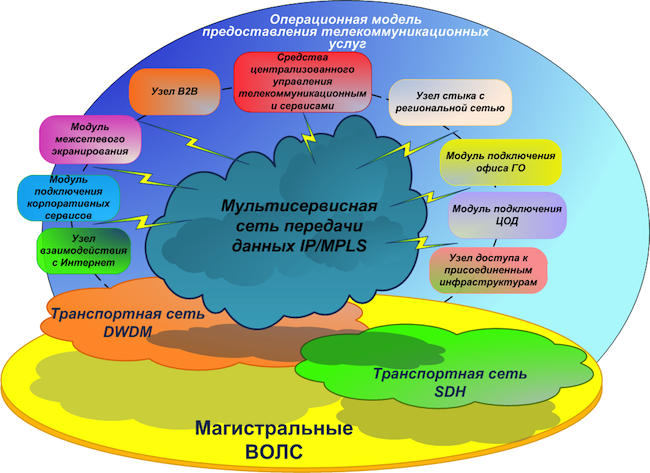
Concept de réseau cibleNous aurons un réseau principal de base - il s'agit d'une infrastructure de transport de télécommunications basée sur des lignes de communication à fibre optique (FOCL), des équipements passifs et actifs de formation de canaux. Il peut également utiliser le sous-système de densification des canaux optiques xWDM et, éventuellement, un réseau SDH.
Sur la base du réseau principal, nous construisons ce que l'on appelle
le réseau central . Il aura un seul plan d'adresses et un seul ensemble de protocoles de routage. Le réseau central comprend:
- MPLS - réseau multiservice;
- DCI - liens entre les centres de données;
- Modules EDGE - divers modules de connexion: pare-feu, organisations partenaires, canaux Internet, centres de données, LAN, réseaux régionaux.
Nous
créons un réseau multiservice
selon un principe hiérarchique avec l'allocation des nœuds de transit (P) et d'extrémité (PE) . Au cours d'une analyse préliminaire des équipements disponibles sur le marché aujourd'hui, il est devenu clair qu'il serait plus économiquement faisable de transférer le niveau des nœuds P vers des équipements séparés que de combiner la fonctionnalité P / PE dans un seul appareil.
Un réseau multiservice aura une haute disponibilité, une tolérance aux pannes, un temps de convergence minimum, une évolutivité, des performances et des fonctionnalités élevées, en particulier IPv6 et la prise en charge de la multidiffusion.
Pendant la construction du réseau fédérateur, nous avons l'intention d'
abandonner les technologies propriétaires (si possible sans compromettre la qualité), car nous nous efforçons de rendre la solution flexible et non liée à un fournisseur spécifique. Mais en même temps, nous ne voulons pas créer une «vinaigrette» à partir de l'équipement de divers fournisseurs. Notre principe de conception fondamental est de fournir le nombre maximum de services lors de l'utilisation d'équipements qui est minimalement suffisant pour ce nombre de fournisseurs. Cela permettra, entre autres, d'organiser la maintenance de l'infrastructure du réseau, en utilisant un nombre limité de personnel. Il est également important que le nouvel équipement soit compatible avec l'équipement existant afin d'assurer un processus de migration sans heurt.
La structure des zones de sécurité des réseaux VTB, ex-VTB24 et ex-Bank of Moscow dans le cadre du projet devrait être entièrement repensée dans le but de combiner des segments fonctionnellement dupliqués. Une structure unifiée des zones de sécurité avec des règles de routage communes et un concept unifié d'accès interréseaux est prévue. Nous prévoyons d'effectuer un pare-feu entre les zones de sécurité à l'aide de pare-feu matériels séparés, espacés sur deux emplacements principaux. Nous prévoyons également de mettre en œuvre tous les modules de périphérie indépendamment sur deux sites différents avec une redondance automatique entre eux sur la base de protocoles de routage dynamique normalisés.
Nous organisons la gestion des équipements du cœur de réseau via un réseau physique distinct (hors bande). L'accès administratif à tous les équipements du réseau sera assuré par un service unique d'authentification, d'autorisation et de comptabilité (AAA).
Pour trouver rapidement des problèmes dans le réseau, il est très important de pouvoir copier le trafic depuis n'importe quel point du réseau pour analyse et le transmettre à l'analyseur via un canal de communication indépendant. Pour ce faire, nous allons créer un réseau isolé pour le trafic SPAN, à l'aide duquel nous collecterons, filtrerons et transmettrons les flux de trafic aux serveurs d'analyse.
Afin de standardiser les services fournis par le réseau et la possibilité de répartir les coûts, nous allons introduire un catalogue unique avec des indicateurs SLA. Nous passons au modèle de service, dans lequel nous prenons en compte l'interconnexion de l'infrastructure réseau avec les tâches appliquées, l'interconnexion des éléments des applications de contrôle et leur impact sur les services. Et ce modèle de service est soutenu par un système de surveillance du réseau afin que nous puissions correctement répartir les coûts informatiques.
De la théorie à la pratique
Nous allons maintenant descendre d'un niveau et vous parler des solutions les plus intéressantes de notre nouvelle infrastructure qui pourraient vous être utiles.
Forêt de ressources: détails
Nous avons déjà
familiarisé les habitants de Khabrovsk avec la forêt ressource VTB. Essayez maintenant de donner une description technique plus détaillée.
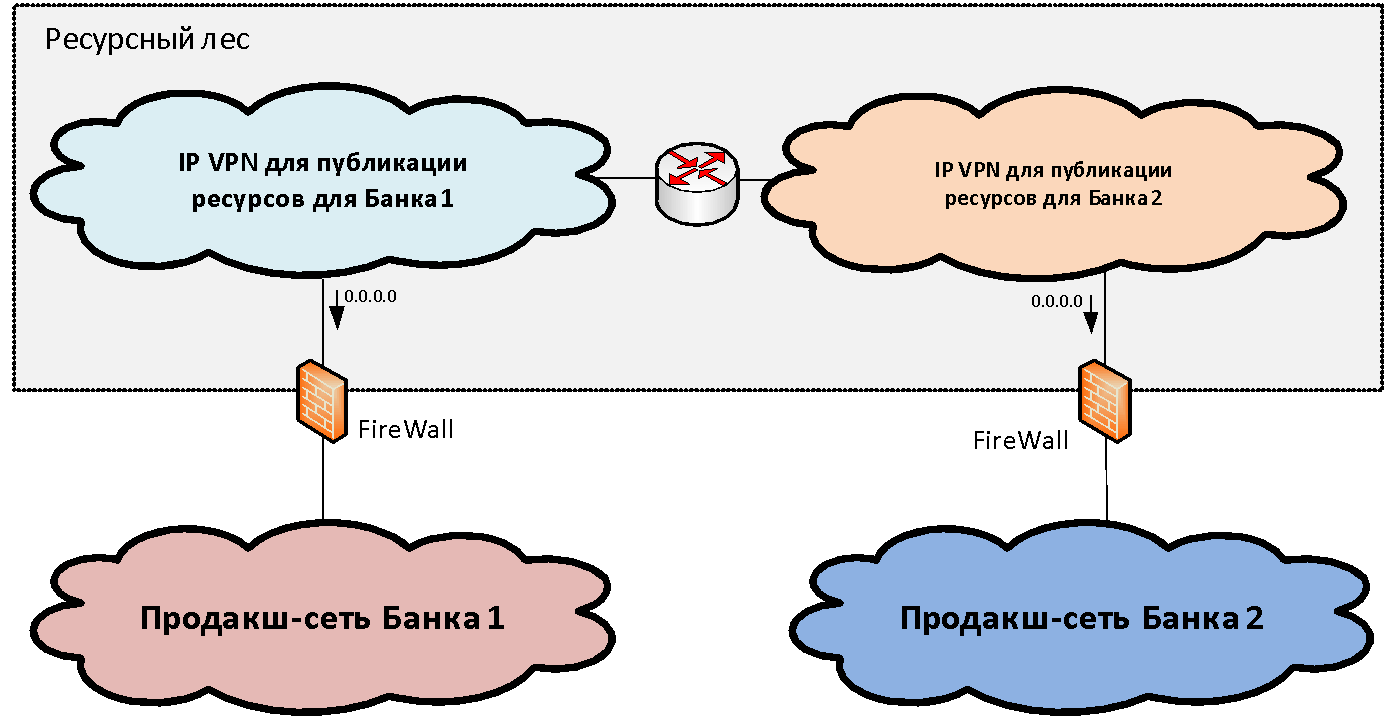
Supposons que nous ayons deux (pour plus de simplicité) des infrastructures de réseau d'organisations différentes qui doivent être combinées. Au sein de chaque infrastructure, en règle générale, parmi l'ensemble des segments de réseau fonctionnels (zones de sécurité), on peut distinguer le segment de réseau productif principal, où se trouvent les principaux systèmes industriels. Nous relions ces zones productives à une certaine structure de segments d'écluse, que nous appelons la
«forêt ressource» . Ces segments de passerelle publient les ressources partagées disponibles à partir des deux infrastructures.
Le concept d'une forêt de ressources, d'un point de vue réseau, est de créer une zone de sécurité de passerelle constituée de deux VPN IP (pour le cas de deux banques). Ces VPN IP sont librement routés entre eux et connectés via des pare-feu à des segments productifs. L'adressage IP pour ces segments est sélectionné dans une plage disjointe d'adresses IP. Ainsi, le routage vers la forêt ressource devient possible à partir des réseaux des deux organisations.
Mais avec le routage de la forêt de ressources vers les segments industriels, la situation est un peu pire, car l'adressage en eux se recoupe souvent et il est impossible de former une table unique. Pour résoudre ce problème, nous avons juste besoin de deux segments dans la forêt de ressources. Dans chacun des segments de la forêt ressource, un itinéraire par défaut est écrit vers le réseau industriel de "leur" organisation. Autrement dit, les utilisateurs peuvent accéder sans traduire les adresses à leur «propre» segment de la forêt de ressources et à un autre segment via PAT.
Ainsi, deux segments de la forêt de ressources représentent une zone de sécurité de passerelle unique, si vous tracez la frontière le long des pare-feu. Chacun d'eux a son propre routage: la passerelle par défaut regarde vers "sa" banque. Si nous plaçons une ressource dans un segment de la forêt de ressources, les utilisateurs de la banque correspondante peuvent interagir avec elle sans NAT.
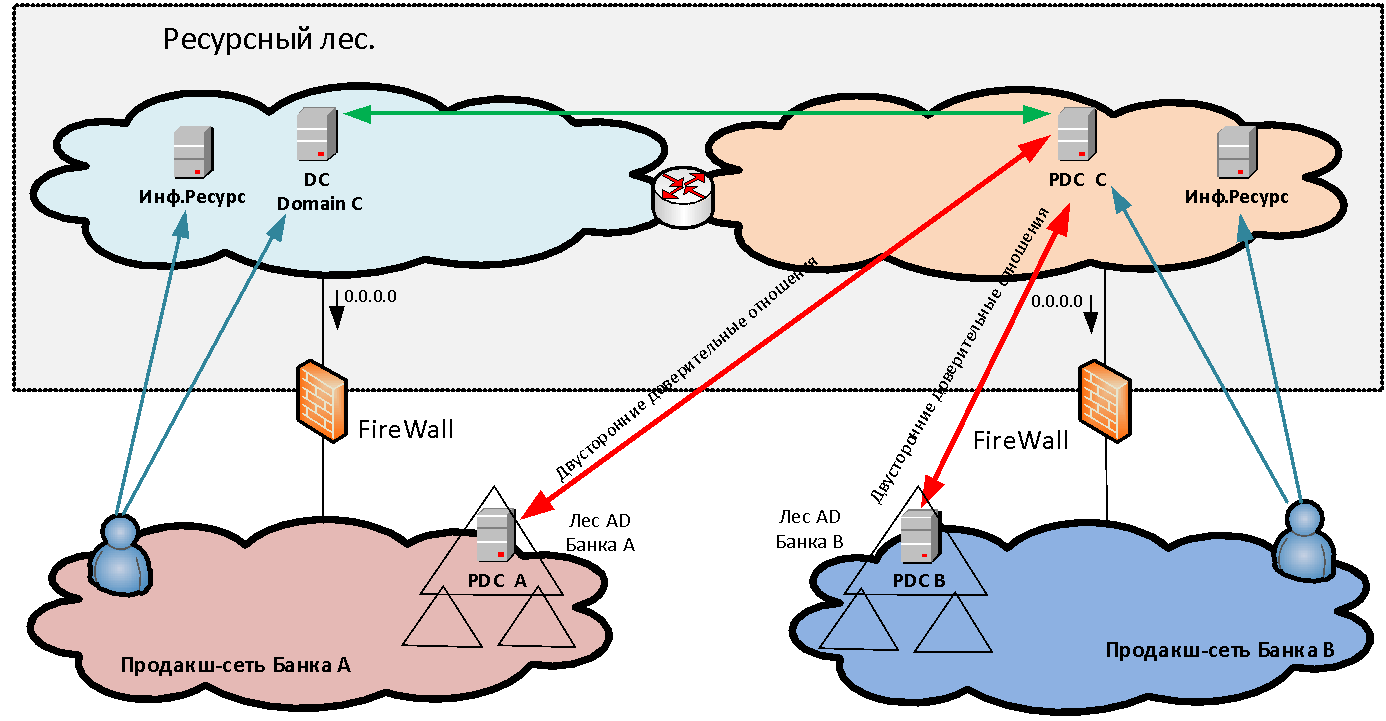
L'interaction sans NAT est très importante pour de nombreux systèmes et, tout d'abord, pour les interactions de domaine Microsoft - après tout, dans la forêt de ressources, nous avons des serveurs Active Directory pour le nouveau domaine commun, dont les approbations sont établies par les deux organisations. De plus, sans interaction NAT, des systèmes tels que Skype Entreprise, ABS «MBANK» et de nombreuses autres applications sont nécessaires, où le serveur retourne à l'adresse du client. Et si le client est derrière PAT, la connexion inverse ne sera plus établie.
Les serveurs que nous installons dans les segments de la forêt de ressources sont divisés en deux catégories: l'infrastructure (par exemple, les serveurs MS AD) et donnant accès à certains systèmes d'information. Le dernier type de serveur que nous appelons Data Marts. Les vitrines sont généralement des serveurs Web, dont le backend est déjà derrière le pare-feu dans le réseau de production de l'organisation qui a créé cette vitrine dans la forêt de ressources.
Et comment les
utilisateurs sont-ils
authentifiés lorsqu'ils accèdent aux ressources publiées? Si nous fournissons simplement l'accès à certaines applications à un ou deux utilisateurs dans un autre domaine, nous pouvons créer pour eux des comptes distincts pour l'authentification dans notre domaine. Mais lorsque nous parlons de la fusion en masse des infrastructures - disons, 50 000 utilisateurs - il est complètement irréaliste de créer et de gérer des comptes croisés séparés pour eux. Il n'est pas toujours possible de créer des approbations directes entre les forêts de différentes organisations, à la fois pour des raisons de sécurité et en raison de la nécessité de rendre les utilisateurs PAT dans les conditions d'intersection des espaces d'adressage. Par conséquent, pour résoudre le problème de l'authentification unifiée des utilisateurs, une nouvelle forêt MS AD constituée d'un domaine est créée dans le périmètre de la forêt de ressources. Dans ce nouveau domaine, les utilisateurs s'authentifient lorsqu'ils accèdent aux services. Pour rendre cela possible, des fiducies bilatérales au niveau des forêts sont établies entre la nouvelle forêt et les forêts de domaine de chaque organisation. Ainsi, l'utilisateur de n'importe laquelle des organisations peut s'authentifier sur n'importe quelle ressource publiée.
Obtenir l'intégration réseau
Après avoir établi l'interaction des systèmes à travers l'infrastructure de la forêt ressource et ainsi éliminé les symptômes aigus, il était temps de reprendre l'intégration directe des réseaux.
Pour ce faire, dans un premier temps, nous avons connecté les segments de produits de trois banques à un seul pare-feu puissant (logiquement unifié, mais physiquement plusieurs fois réservé sur différents sites). Le pare-feu fournit une interaction directe entre les systèmes de différentes banques.
Avec l'ex-VTB24, avant d'organiser des interactions directes entre les systèmes, nous avons déjà réussi à aligner les espaces d'adressage. Après avoir formé les tables de routage sur le pare-feu et ouvert les accès appropriés, nous avons pu assurer l'interaction entre les systèmes dans deux infrastructures différentes.
Avec l'ex-Banque de Moscou, les espaces d'adressage au moment de l'organisation des interactions appliquées n'étaient pas alignés, et nous avons dû utiliser le NAT mutuel pour organiser l'interaction des systèmes. L'utilisation de NAT a créé un certain nombre de problèmes de résolution DNS qui ont été résolus par la maintenance de zones DNS en double. De plus, en raison du NAT, il y avait des difficultés avec le fonctionnement d'un certain nombre de systèmes d'application. Maintenant, nous avons presque éliminé les intersections des espaces d'adressage, mais nous sommes confrontés au fait que de nombreux systèmes VTB et ex-Bank of Moscow sont étroitement liés pour interagir aux adresses traduites. Nous devons maintenant migrer ces interactions vers de véritables adresses IP tout en maintenant la continuité des activités.
Suppression du NAT
Ici, notre objectif est d'assurer le fonctionnement des systèmes dans un espace d'adressage unique pour une intégration plus poussée des services d'infrastructure (MS AD, DNS) et des applications (Skype Entreprise, MBANK). Malheureusement, étant donné que certains des systèmes d'application sont déjà liés les uns aux autres aux adresses traduites, un travail individuel avec chaque système d'application est nécessaire pour éliminer le NAT pour des interactions spécifiques.
Parfois, vous pouvez
opter pour une telle astuce : définir le même serveur en même temps sous l'adresse traduite et sous la vraie. Ainsi, les administrateurs d'applications peuvent tester le travail à une adresse réelle avant la migration, essayer de basculer vers une interaction non NAT par eux-mêmes et revenir en arrière si nécessaire. Dans le même temps, nous surveillons le pare-feu à l'aide de la fonction de capture de paquets pour voir si quelqu'un communique avec le serveur via l'adresse traduite. Dès que cette communication s'arrête, nous, en accord avec le propriétaire de la ressource, arrêtons la diffusion: le serveur n'a qu'une adresse réelle.
Après avoir analysé NAT, malheureusement, pendant un certain temps, il sera nécessaire de maintenir le pare-feu entre des segments fonctionnellement identiques, car toutes les zones ne sont pas conformes aux mêmes normes de sécurité. Après la standardisation des segments, le pare-feu entre les segments est remplacé par le routage et les zones de sécurité fonctionnellement identiques fusionnent.
Pare-feu
Passons au problème du pare-feu interréseau. En principe, il est pertinent pour toute grande organisation dans laquelle il est nécessaire de fournir une tolérance aux pannes locale et globale des équipements de protection.
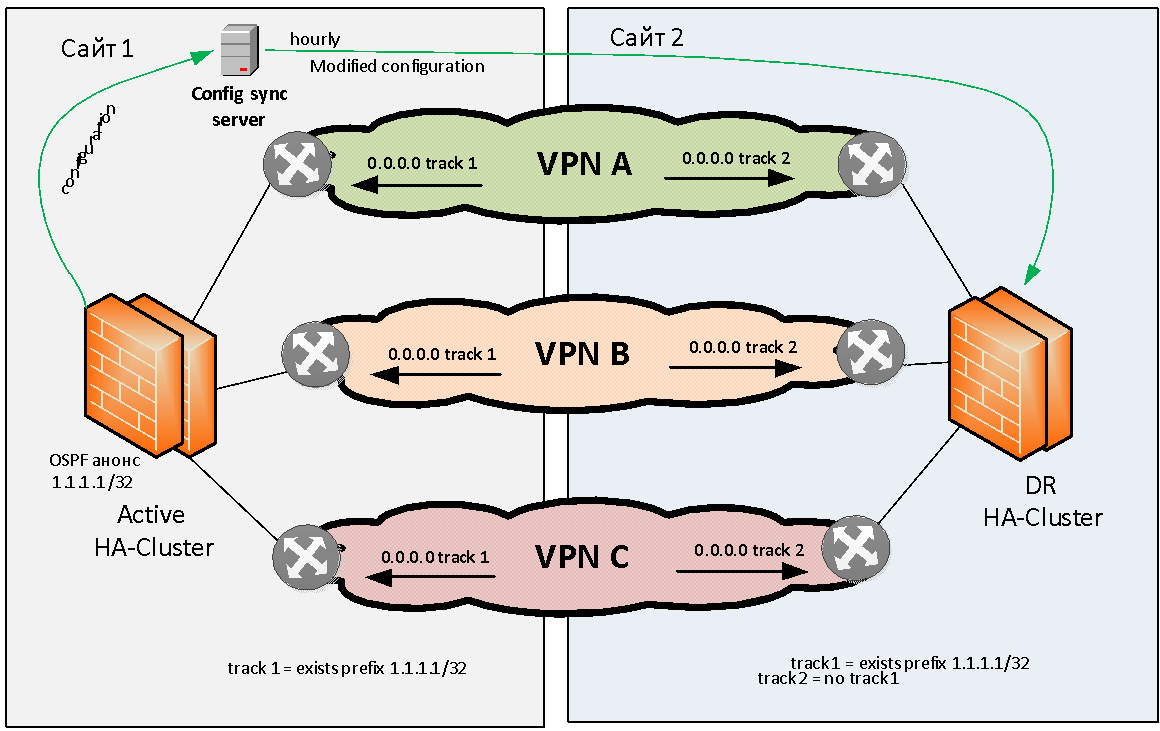
Essayons de formuler le problème de la réservation du pare-feu en général. Nous avons deux sites: le site 1 et le site 2. Il existe plusieurs (par exemple, trois) VPN IP MPLS qui communiquent entre eux via un pare-feu dynamique. Ce pare-feu doit être réservé localement et géographiquement.
Nous ne considérerons pas le problème de la sauvegarde locale des pare-feu; presque tous les fabricants offrent la possibilité d'assembler des pare-feu dans un cluster HA local. En ce qui concerne la réservation géographique des pare-feu, pratiquement aucun fournisseur n'a cette tâche prête à l'emploi.
Bien sûr, vous pouvez «étirer» un cluster de pare-feu sur plusieurs sites le long de L2, mais ce cluster représentera alors un point de défaillance unique et la fiabilité de notre solution ne sera pas très élevée. Parce que les clusters se bloquent parfois complètement en raison d'erreurs logicielles, ou tombent dans un état de cerveau divisé en raison d'une rupture de lien L2 entre les sites. Pour cette raison, nous avons immédiatement refusé d'étirer les clusters de pare-feu sur L2.
Nous devions trouver un schéma dans lequel si un module de pare-feu échouait sur un site, une transition automatique vers un autre site se produirait. Voici comment nous l'avons fait.
Il a été décidé de s'en tenir au modèle de géo-réservation Active / Standby lorsque le cluster actif est situé sur le même site. Sinon, nous rencontrons immédiatement des problèmes de routage asymétrique, ce qui est difficile à résoudre avec un grand nombre de VPN L3.
Le cluster de pare-feu actif doit en quelque sorte signaler son bon fonctionnement. Comme méthode de signalisation, nous avons choisi l'annonce OSPF du pare-feu au réseau de la route de test (drapeau) avec le masque / 32. L'équipement réseau sur le site 1 surveille la présence de cette route depuis le pare-feu et, si disponible, active le routage statique (par exemple, 0.0.0.0 / 0), vers le cluster de pare-feu donné. Cette route statique par défaut est ensuite placée (par redistribution) dans la table de protocole BGP MP et distribuée à travers le réseau de base. , OSPF , , IP VPN.
, , , .
1 - , , 1 , 2 — . , , VPN' . , , , .
, active/standby. active-. , . , (, IP- ). . . .
L3 , . .
. , , — , , . L3-, .
, IP-. MPLS VPN. MPLS VPN «IN» VPN «OUT». VPN HUB-and-spoke VPN. Spoke HUB' VPN, .
«IN»
- Spoke VPN' VPN. «OUT»
Spoke VPN' .
MPLS VPN «IN». VPN . VPN HUB-VPN «IN» . . , Policy Based Routing. VPN «OUT», VPN «OUT» Spoke-VPN.
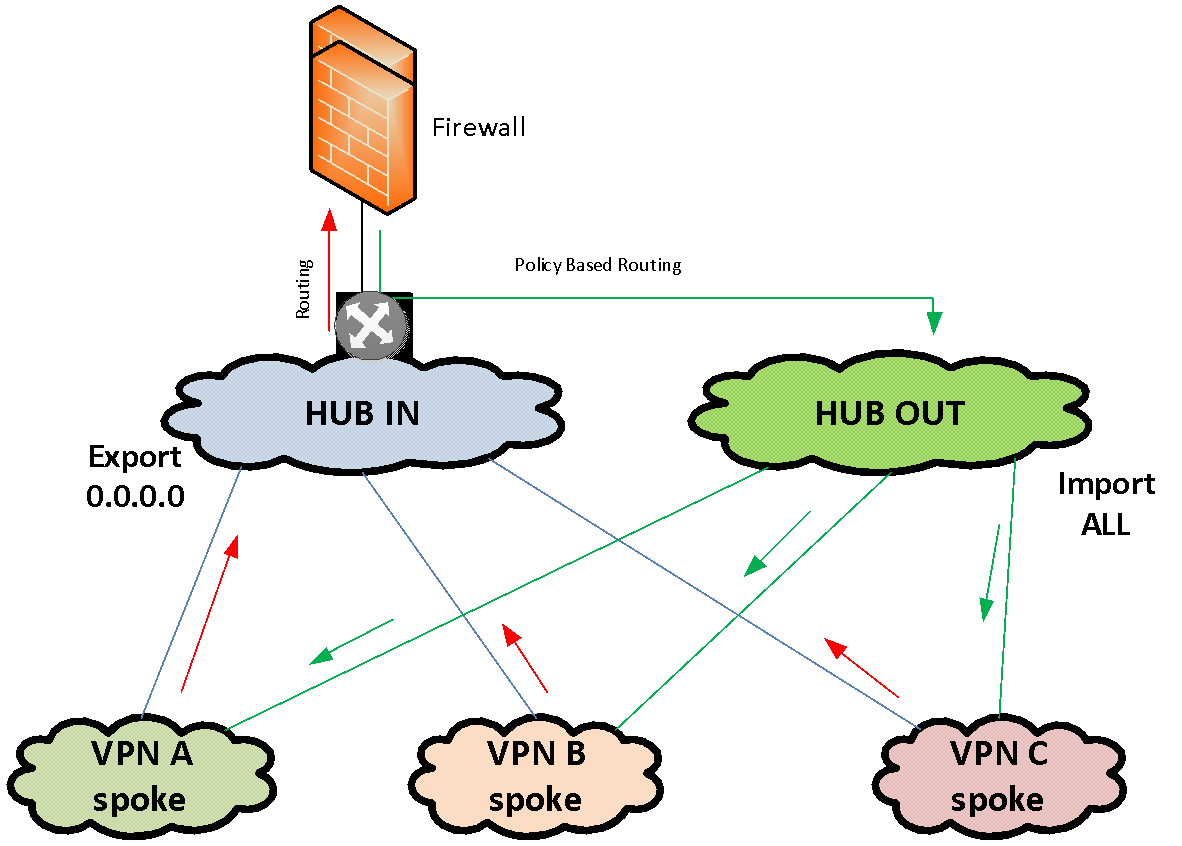
VPN, . MPLS import / export HUB VPN.
VPN , — , VLAN, ..
Conclusion
, , . , , , . .