
L'une des principales tâches de Yandex.Taxi est de s'assurer qu'une voiture arrive rapidement à l'utilisateur, et le temps du conducteur pour la «marche au ralenti» est réduit (c'est-à-dire le temps où il est sur la ligne sans passager). Il semblerait que tout soit simple: l'utilisateur sélectionne le tarif, indique des souhaits supplémentaires (siège enfant par exemple). Reste à filtrer les pilotes sur la ligne selon ces critères, sélectionner le plus proche et lui proposer une commande. Cependant, tout n'est si simple qu'à première vue.
Aujourd'hui, je vais dire à la communauté Habr comment nous choisissons le pilote le plus approprié et comment ce processus a évolué au fil du temps. Vous découvrirez deux approches pour résoudre le problème.
Architecture de recherche générale
Lorsque l'utilisateur clique sur le bouton «Appeler un taxi», un objet de commande est créé dans le backend et son traitement commence conformément à la machine d'état. Pour que la commande passe de l'état «En attente» à «Le conducteur est affecté», vous devez trouver le conducteur, lui proposer une commande et attendre la confirmation que la commande a été acceptée.
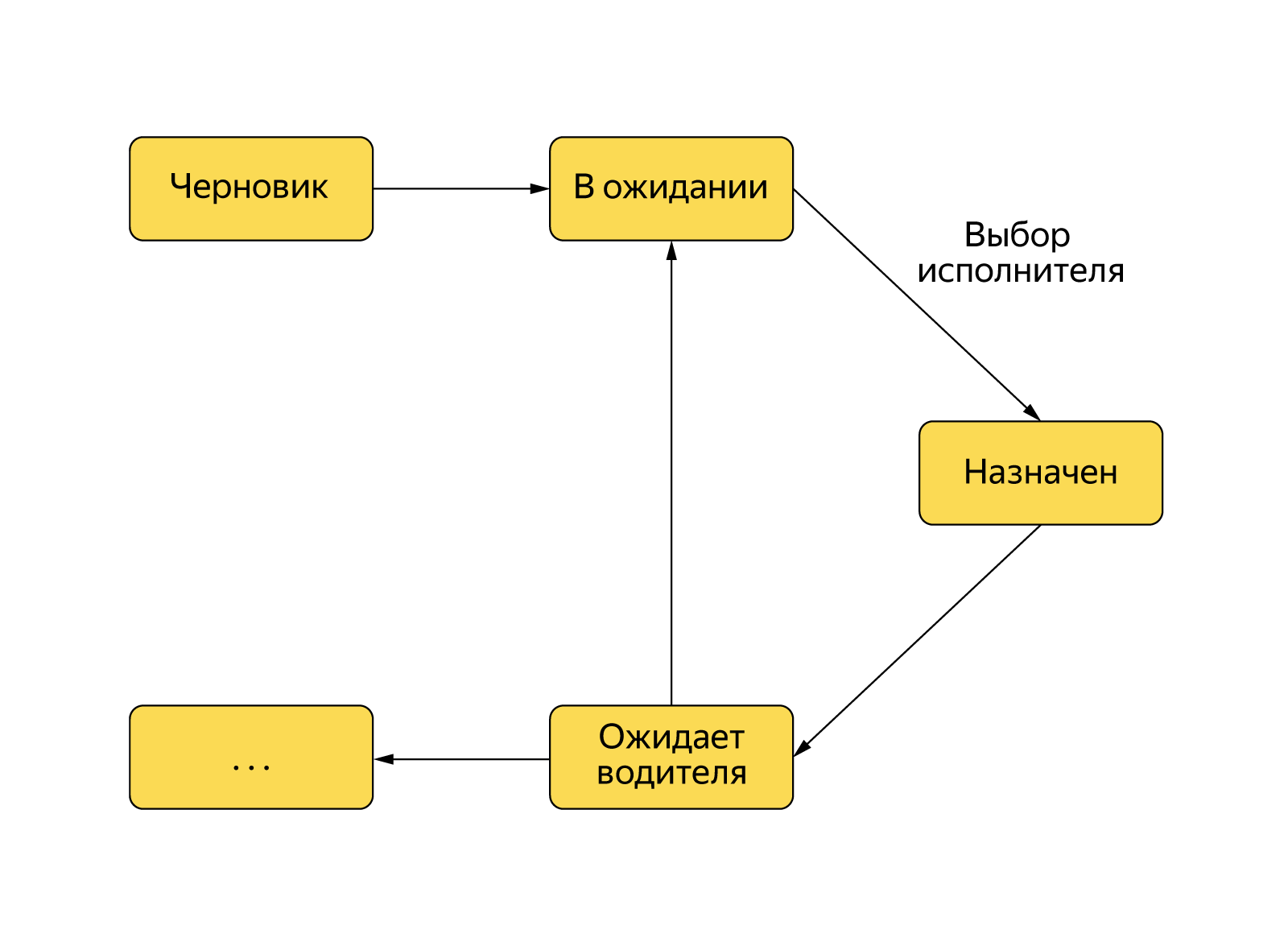
Approche gourmande
Pendant très longtemps, une approche
gourmande a fonctionné chez Yandex.Taxi. Avec cette approche, au stade de la recherche de l'entrepreneur, une demande est faite au microservice Tracker, qui est responsable des chauffeurs. Tracker sait tout sur les voitures: de la couleur et de la marque à son
emplacement actuel . Tracker dispose d'un géo-index local pour les pilotes et les connecteurs aux services de routage (routeurs) pour la création d'itinéraires du point A au point B (et même via les points B, D, D). Par conséquent, lorsqu'une demande est faite pour rechercher un conducteur, Tracker détermine d'abord les voitures les plus proches dans le géo-index local le long du rayon direct, en tenant compte des restrictions de commande «dures» (classe de voiture, exigences - siège enfant, numéros jaunes). Ensuite, le temps et la longueur de l'itinéraire d'approvisionnement du véhicule sont spécifiés et, en tenant compte de ces informations, la meilleure option est sélectionnée.
Plus tard, cette logique a évolué: pour chaque pilote, ils ont commencé à compter sur son «scoring» sur commande - fonction de l'heure de livraison de la voiture. Et les pilotes étaient déjà classés en fonction de leur valeur. La fonction prend en compte non seulement le délai de livraison lui-même, mais aussi de nombreux autres facteurs: du niveau de la demande aux points A et B à «l'expérience» du conducteur. Ce rendez-vous gourmand s'appelle un bonus.
Approche tampon (faisceau)
Cependant, avec une approche gourmande, le chauffeur le plus proche recevra celui qui a d'abord commandé un taxi. Cependant, certains utilisateurs peuvent même se retrouver sans voiture.
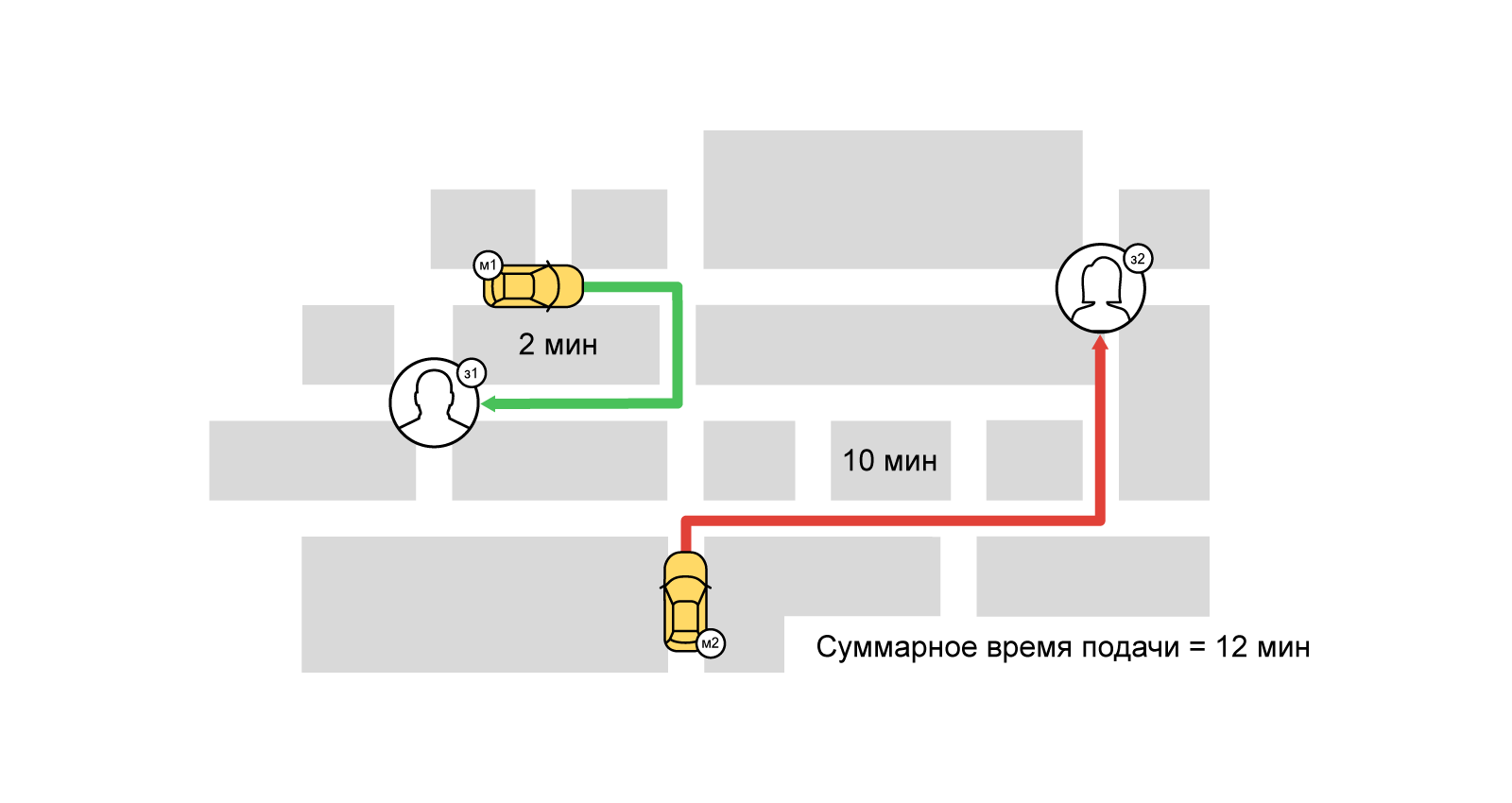
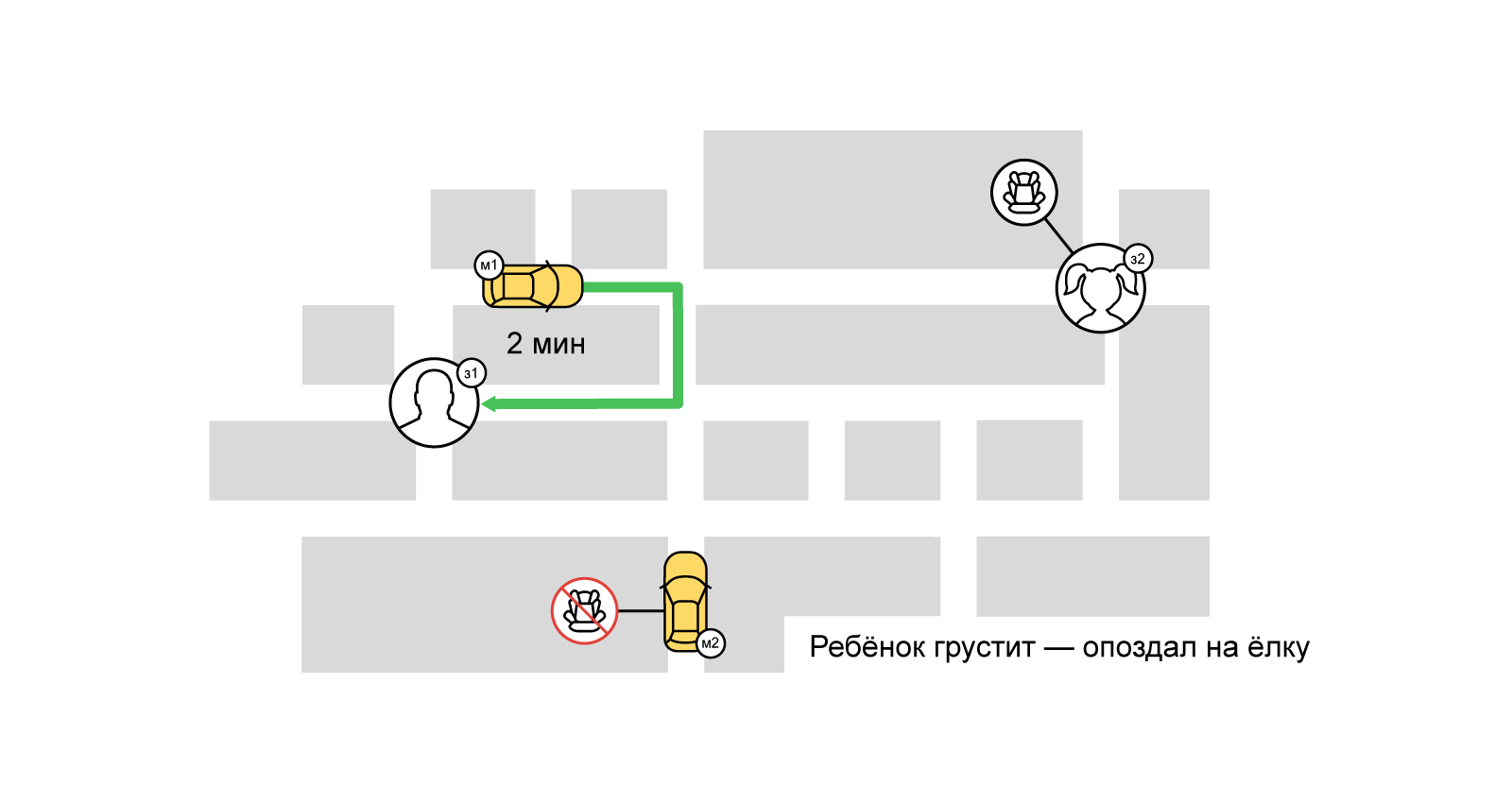
Avec une demande accrue, lorsque la compétition pour les artistes commence, l'approche gourmande n'est pas bonne. Afin de satisfaire au maximum la demande même aux heures les plus chargées, nous utilisons de nombreuses approches et algorithmes. L'un d'eux est la désignation tampon (faisceau) des conducteurs sur les commandes. Il est basé sur la tâche bien connue du domaine de l'optimisation combinatoire -
le problème d'affectation . Bref, son essence: ayons N oeuvres et M interprètes, tout employé peut accomplir n'importe quelle tâche pendant le temps p (i, j) [0 <= i <N, 0 <= j <M]. Il est nécessaire d'affecter un tel entrepreneur à chaque tâche afin de réduire le temps d'exécution total de tous les travaux (dans ce cas, un entrepreneur ne peut occuper qu'un seul emploi).
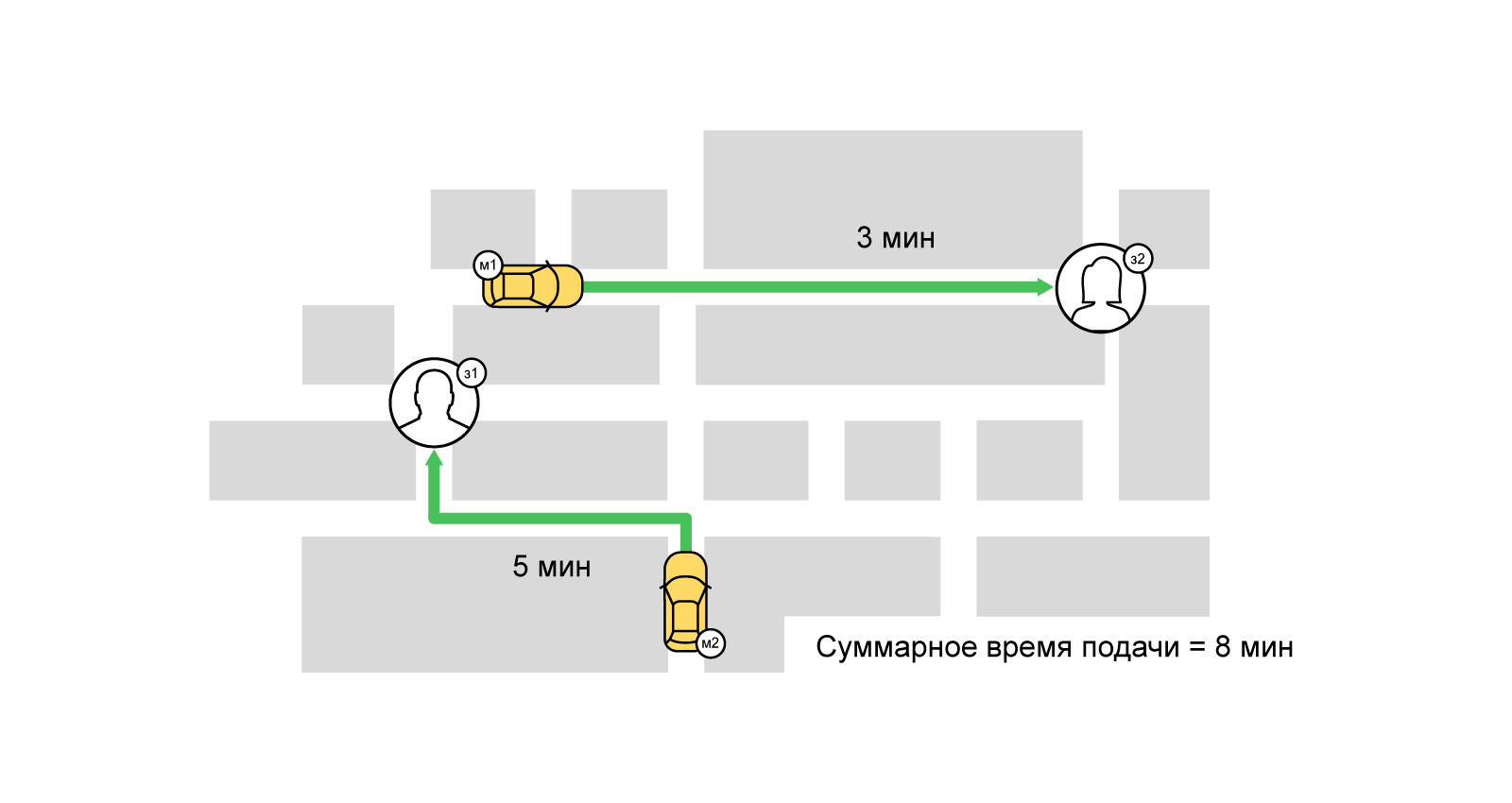
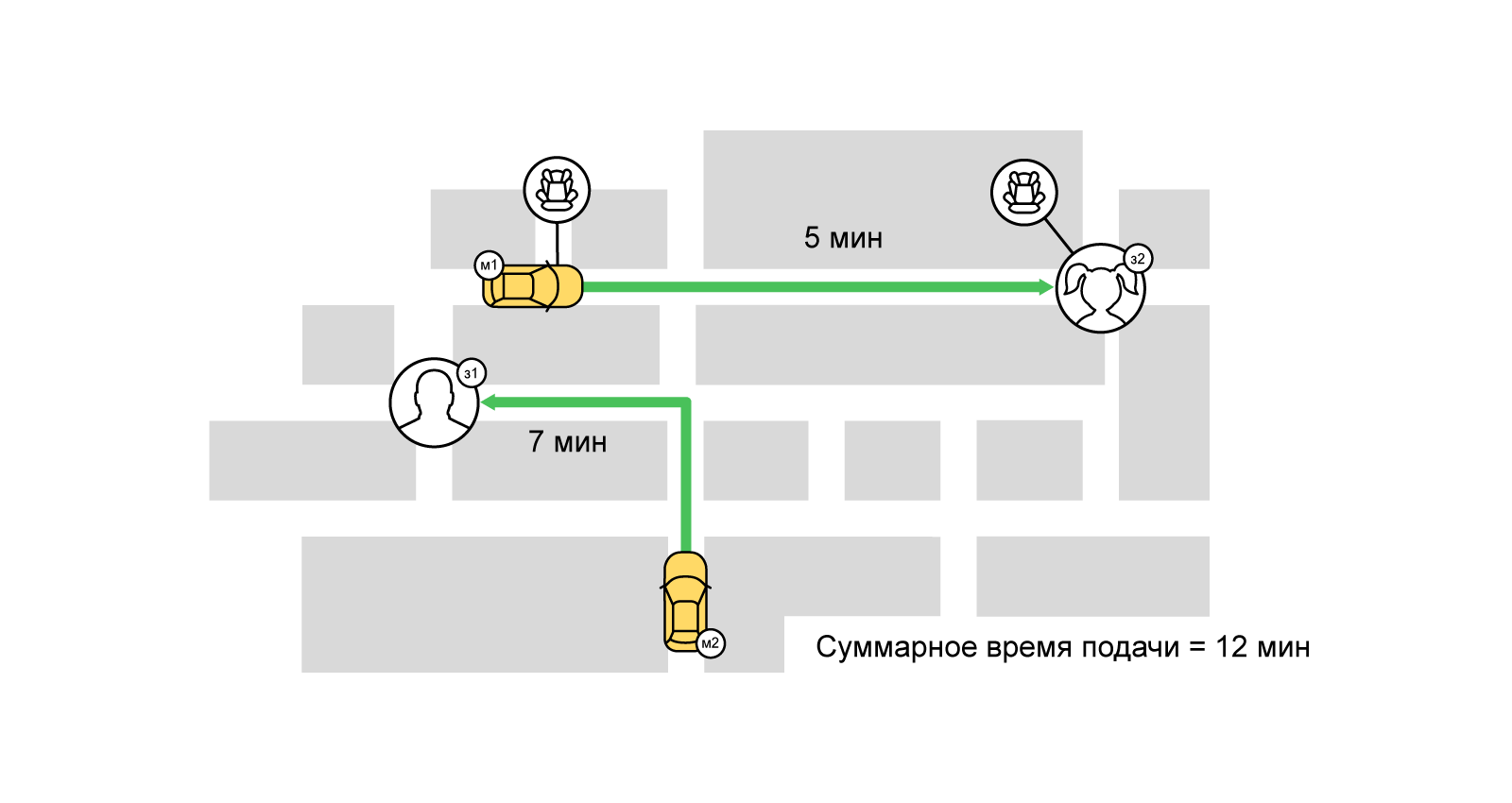
Lors de la résolution d'un tel problème d'affectation, notre «coût» d'exécution du travail (commande) par l'exécuteur testamentaire (parc de taxis et chauffeur) est la valeur de la fonction de notation à partir du moment où la voiture a été livrée à l'utilisateur. La tâche peut être décrite en termes de graphes bipartites: d'une part, les ordres, d'autre part, les interprètes. Entre les commandes et les interprètes, il y a des bords pondérés (notation). Ainsi, l'un de nos objectifs est de minimiser le délai total de livraison du véhicule en maximisant le nombre de commandes terminées (correspondance maximale). L'un des moyens les plus connus pour résoudre un tel problème est l'
algorithme hongrois .
Evidemment, avec un rendez-vous tampon, on ne peut pas donner de chauffeur sur demande, comme avec une approche gourmande. Vous devez d'abord mettre la commande dans la file d'attente, puis jouer, puis informer sur le pilote trouvé. Cela ne correspondait pas du tout à la machine d'état du traitement des commandes, et il fallait l'améliorer un peu. Afin de tester et de créer une nouvelle solution sans affecter nos collègues, nous avons immédiatement convenu que nous ferions tout dans un microservice DriverDispatcher distinct. Il prendra les commandes, fera la queue, trouvera les pilotes et enregistrera les résultats des rallyes.
Tout d'abord, nous avons dû préparer le Tracker pour un nouveau profil de charge. Si avec une approche gourmande, les demandes de pilotes tombaient simplement individuellement sur l'équilibreur de suivi et étaient redirigées vers ses instances avec équilibrage de charge, alors dans la destination du tampon toutes les demandes provenaient d'une seule machine: les demandes individuelles obstrueraient simplement le pool de connexions. Par conséquent, nous avons ajouté au tracker la possibilité de traiter des lots de demandes qui ont été traitées simultanément dans le tracker. En cours de route, nous avons également dû résoudre le problème d'un nombre raisonnable de demandes de traitement par lots. Du côté du client (DriverDispatcher), nous avons divisé le gros lot en plusieurs petits et l'avons envoyé à différentes instances de Tracker.
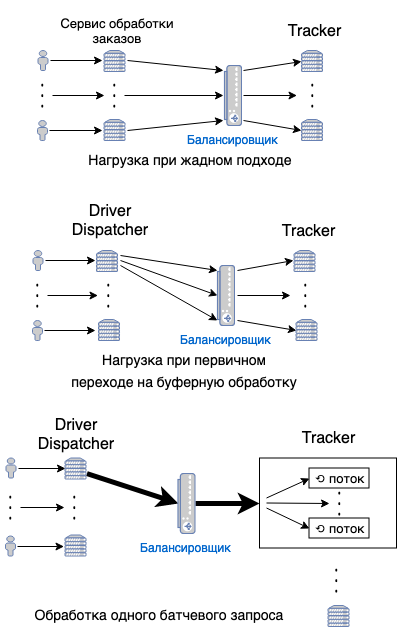
Ainsi, le tracker est préparé, le scoring est considéré à la fois dans Tracker (rendez-vous gourmand) et dans le nouveau service (DriverDispatcher'e), l'algorithme de résolution du problème d'affectation est débogué et fonctionne correctement. La question s'est posée de savoir comment intégrer tout cela dans la machine d'état du traitement des commandes. Nous avons ajouté l'envoi et la suppression des méta-informations de commande dans DriverDispatcher lorsque la commande est transférée d'un état à l'autre. Et cela a presque fonctionné. Presque - parce que les itérations de recherche d'un entrepreneur à commander n'étaient pas contrôlées en externe. Nous pourrions simplement remplacer le voyage vers le tracker par le chauffeur par un voyage à notre service et donner au chauffeur quand il est trouvé, et avant cela juste donner 404. Mais c'est mauvais, car vous devez offrir une commande au chauffeur dès que nous trouvons une commande, et même plusieurs les secondes de retard jouent ici un rôle: le conducteur peut simplement tourner dans la mauvaise direction, et la commande ne sera plus pertinente. Pour ce faire, nous avons permis d'appeler le processus de recherche d'un artiste sans affecter les tâches prévues. Nous avons donc enregistré la logique de recherche (avec de nouvelles demandes) et ajouté la possibilité de l'appeler en dehors du planificateur.
Ainsi, nous avons pu combiner la machine à états principale pour le traitement des commandes avec la machine à états dans la répartition du tampon sans affecter la logique de travail et sans courir entre les états. Vous pouvez exécuter les premières expériences sur des utilisateurs en direct.
Tout cela est très cool, mais qu'en est-il du temps pour rechercher un artiste, demandez-vous. Si la recherche n'a pas lieu immédiatement après la réception de la commande, alors le temps de recherche augmente et est par conséquent compensé par un flux plus rapide? Ce n'est pas tout à fait vrai: à l'aide de diverses techniques (dont l'utilisation du machine learning), nous avons pu isoler des cas où l'attente a du sens, dans d'autres cas le temps d'attente ne change pas.
Tirage au sort
Une autre façon de trouver un artiste plus rapidement est de commencer à le rechercher AVANT de créer une commande. Lorsqu'une nouvelle
épingle apparaît (c'est-à-dire que l'utilisateur saisit uniquement les données de commande dans l'application), les
algorithmes d' apprentissage automatique évaluent la probabilité qu'une commande suive et décident de la prendre en compte lors de la mise en mémoire tampon des pilotes. Nous pouvons trouver la voiture à l'avance et, lorsque l'utilisateur clique sur le bouton de commande, faire immédiatement une offre à un conducteur approprié.
Conclusion
Faire correspondre les commandes et les chauffeurs n'est pas une tâche facile; cela nécessite de prendre en compte de nombreux facteurs. L'un d'eux est le contexte des mouvements de conducteurs lors du choix des candidats à l'ordre. Nous en parlerons dans les articles suivants.
Autres postes de technologie de taxi