La détection des attaques est une tâche importante dans la sécurité des informations depuis des décennies. Les premiers exemples connus de mise en œuvre d'IDS remontent au début des années 80.
Après plusieurs décennies, une industrie entière d'outils de détection d'attaque s'est formée. Actuellement, il existe différents types de produits, tels que IDS, IPS, WAF, pare-feu, dont la plupart offrent une détection d'attaque basée sur des règles. L'idée d'utiliser des techniques de détection d'anomalies pour détecter les attaques basées sur les statistiques de production ne semble pas aussi réaliste que par le passé. Ou tout de même? ..
Détection d'anomalies dans les applications Web
Les premiers pare-feu spécialement conçus pour détecter les attaques sur les applications Web ont commencé à apparaître sur le marché au début des années 1990. Depuis lors, les méthodes d'attaque et les mécanismes de défense ont considérablement changé et les attaquants peuvent avoir une longueur d'avance à tout moment.
Actuellement, la plupart des WAF tentent de détecter les attaques comme suit: il existe des mécanismes basés sur des règles qui sont intégrés au serveur proxy inverse. L'exemple le plus frappant est mod_security, le module WAF pour le serveur Web Apache, qui a été développé en 2002. L'identification des attaques à l'aide de règles présente plusieurs inconvénients; par exemple, les règles ne peuvent pas détecter les attaques zero-day, alors que les mêmes attaques peuvent être facilement détectées par un expert, et cela n'est pas surprenant, car le cerveau humain ne fonctionne pas comme un ensemble d'expressions régulières.
Du point de vue du WAF, les attaques peuvent être divisées en celles que nous pouvons détecter par la séquence de requêtes et celles où une requête HTTP (réponse) suffit à résoudre. Notre recherche se concentre sur la détection de ces derniers types d'attaques - injection SQL, Cross Site Scripting, injection d'entités externes XML, cheminement de chemin, commande de système d'exploitation, injection d'objet, etc.
Mais d'abord, testons-nous.
Que pensera l'expert quand il verra les requêtes suivantes?
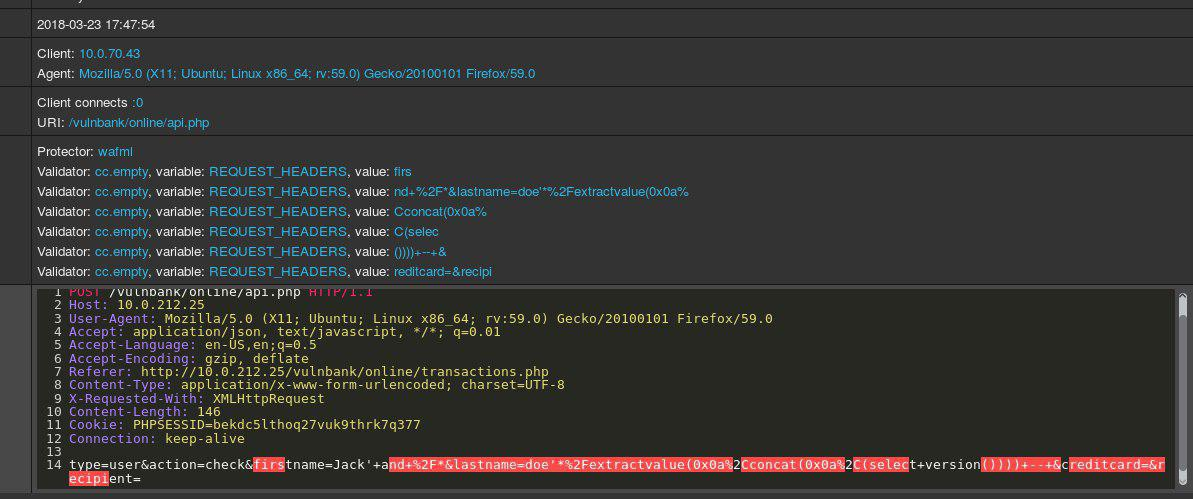
Jetez un œil à un exemple de requête HTTP aux applications:
Si vous avez été chargé de détecter des demandes malveillantes à une application, vous souhaitez probablement observer le comportement habituel de l'utilisateur pendant un certain temps. En examinant les requêtes pour plusieurs points de terminaison de l'application, vous pouvez avoir une idée générale de la structure et des fonctions des requêtes non dangereuses.
Vous obtenez maintenant la requête d'analyse suivante:

Il est immédiatement évident que quelque chose ne va pas ici. Il faudra un certain temps pour comprendre à quoi ressemble vraiment ici, et une fois que vous avez identifié la partie de la demande qui semble anormale, vous pouvez commencer à réfléchir au type d'attaque dont il s'agit. Essentiellement, notre objectif est de faire fonctionner notre «intelligence artificielle pour détecter les attaques» de la même manière - pour ressembler à la pensée humaine.
La chose évidente est qu'un trafic qui semble malveillant à première vue peut être normal pour un site Web particulier.
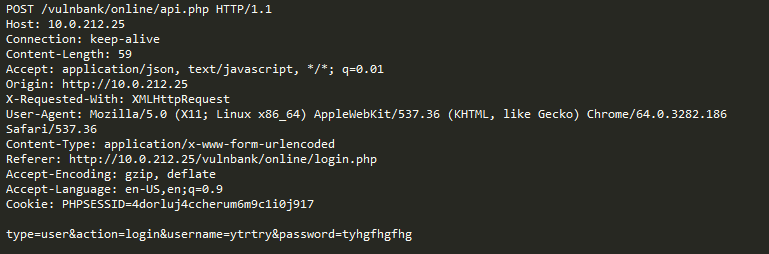
Par exemple, considérons les requêtes suivantes:
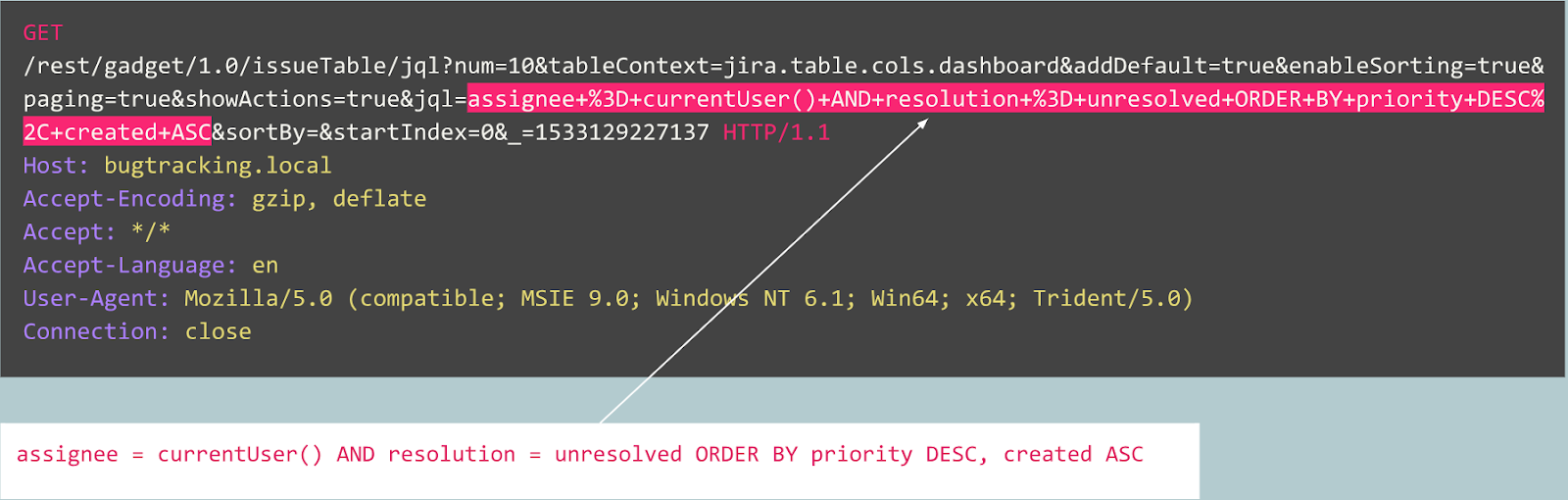
Cette requête est-elle anormale?
En fait, cette demande est une publication d'un bogue dans le tracker Jira et est typique de ce service, ce qui signifie que la demande est attendue et normale.
Considérons maintenant l'exemple suivant:

À première vue, la demande ressemble à une inscription d'utilisateur normale sur un site Web basé sur Joomla CMS. Cependant, l'opération demandée est user.register au lieu du registration.register habituel. La première option est obsolète et contient une vulnérabilité qui permet à quiconque de s'inscrire en tant qu'administrateur. Un exploit pour cette vulnérabilité est connu sous le nom de Joomla <3.6.4 Account Creation / Privilege Escalation (CVE-2016-8869, CVE-2016-8870).

Par où avons-nous commencé
Bien sûr, nous avons d'abord examiné les solutions existantes au problème. Diverses tentatives pour créer des algorithmes de détection d'attaque basés sur des statistiques ou l'apprentissage automatique ont été faites depuis des décennies. L'une des approches les plus populaires consiste à résoudre le problème de classification, lorsque les classes sont quelque chose comme «requêtes attendues», «injections SQL», XSS, CSRF, etc. De cette manière, vous pouvez obtenir une bonne précision pour l'ensemble de données en utilisant le classificateur , cependant, cette approche ne résout pas des problèmes très importants de notre point de vue:
- La sélection des classes est limitée et prédéterminée . Que se passe-t-il si votre modèle dans le processus d'apprentissage est représenté par trois classes, dites «requêtes normales», SQLi et XSS, et pendant le fonctionnement du système, il rencontre un CSRF ou une attaque zero-day?
- Le sens de ces classes . Supposons que vous deviez protéger dix clients, chacun exécutant des applications Web complètement différentes. Pour la plupart d'entre eux, vous n'avez aucune idée de l'apparence réelle de l'injection SQL pour leur application. Cela signifie que vous devez en quelque sorte créer artificiellement des jeux de données d'apprentissage. Cette approche n'est pas optimale, car en fin de compte, vous apprendrez des données dont la distribution diffère des données réelles.
- Interprétabilité des résultats du modèle . Eh bien, le modèle a produit le résultat de l'injection SQL, et maintenant quoi? Vous et, plus important encore, votre client, qui est le premier à voir un avertissement et qui n'est généralement pas un expert des attaques Web, devez deviner quelle partie de la demande votre modèle considère comme malveillante.
Gardant tous ces problèmes à l'esprit, nous avons décidé d'essayer de toute façon de former le modèle du classificateur.
Étant donné que le protocole HTTP est un protocole de texte, il était évident que nous devions examiner les classificateurs de texte modernes. Un exemple bien connu est l'analyse des sentiments dans un ensemble de données d'examen de films IMDB. Certaines solutions utilisent RNN pour classer les avis. Nous avons décidé d'essayer un modèle similaire avec une architecture RNN avec quelques légères différences. Par exemple, l'architecture RNN en langage naturel utilise une représentation vectorielle des mots, mais il n'est pas clair quels mots apparaissent dans un langage non naturel tel que HTTP. Par conséquent, nous avons décidé d'utiliser la représentation vectorielle des symboles pour notre tâche.
Les représentations prêtes à l'emploi ne résolvent pas notre problème, nous avons donc utilisé de simples correspondances de caractères dans des codes numériques avec plusieurs marqueurs internes, tels que
GO et
EOS .
Une fois le développement et les tests du modèle terminés, tous les problèmes précédemment prévus sont devenus apparents, mais au moins notre équipe est passée d'hypothèses inutiles à certains résultats.
Et ensuite?
Ensuite, nous avons décidé de faire quelques pas vers l'interprétabilité des résultats du modèle. À un moment donné, nous sommes tombés sur le mécanisme d'attention «Attention» et avons commencé à le mettre en œuvre dans notre modèle. Et cela a donné des résultats prometteurs. Maintenant, notre modèle a commencé à afficher non seulement des étiquettes de classe, mais aussi des facteurs d'attention pour chaque caractère que nous avons transmis au modèle.
Nous pouvions maintenant visualiser et afficher dans l'interface Web l'endroit exact où l'attaque par injection SQL a été détectée. C'était un bon résultat, mais d'autres problèmes de la liste n'étaient toujours pas résolus.
Il était évident que nous devions continuer à tirer parti du mécanisme d'attention et à nous éloigner de la tâche de classification. Après avoir lu un grand nombre d'études connexes sur les modèles de séquence (sur les mécanismes d'attention [2], [3], [4], sur la représentation vectorielle, sur les architectures des encodeurs automatiques) et les expériences avec nos données, nous avons pu créer un modèle de détection d'anomalies qui, finalement, fonctionnerait plus ou moins comme un expert.
Encodeurs automatiques
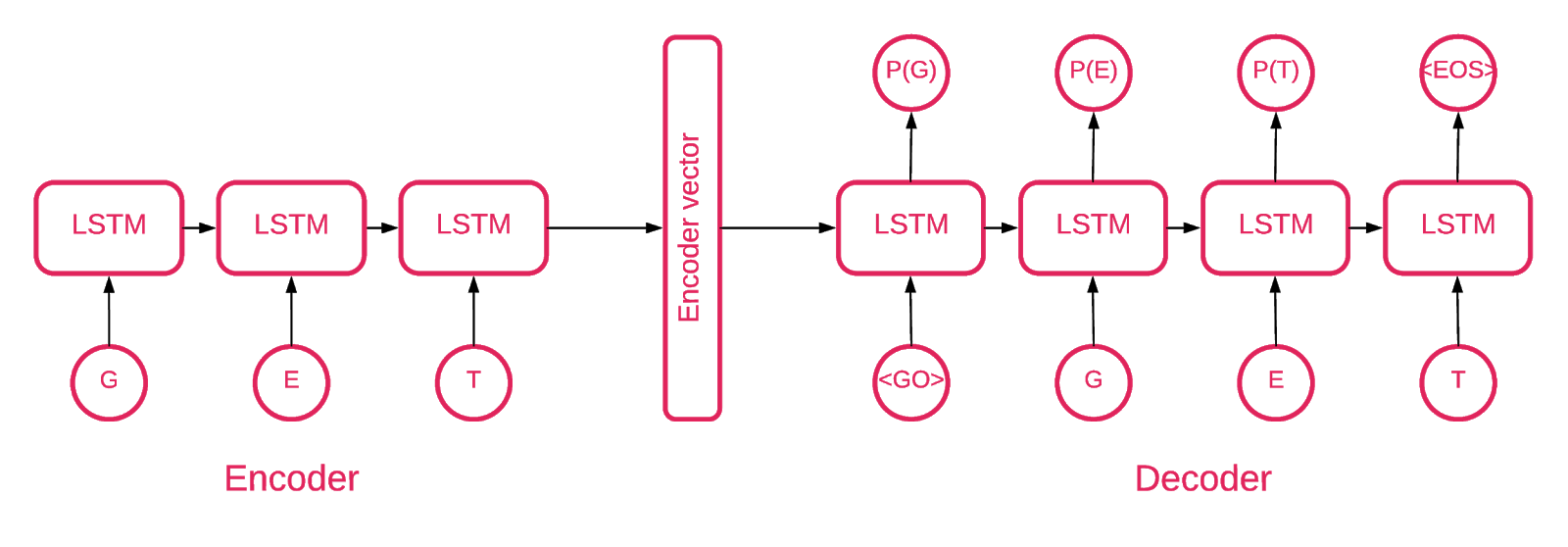
À un moment donné, il est devenu clair que l'architecture de Seq2Seq [5] est la plus appropriée pour notre tâche.
Le modèle Seq2Seq [7] se compose de deux LSTM multicouches - un codeur et un décodeur. L'encodeur mappe la séquence d'entrée sur un vecteur de longueur fixe. Le décodeur décode le vecteur cible à l'aide de la sortie du codeur. En formation, un encodeur automatique est un modèle dans lequel les valeurs cibles sont définies de la même manière que les valeurs d'entrée.
L'idée est d'apprendre au réseau à décoder les choses qu'il a vues ou, en d'autres termes, à rapprocher l'identité. Si un encodeur automatique formé reçoit un modèle anormal, il le recrée probablement avec un degré d'erreur élevé, simplement parce qu'il n'a jamais été vu.
Solution
Notre solution se compose de plusieurs parties: initialisation du modèle, formation, prévision et vérification. Nous espérons que la plupart du code situé dans le référentiel ne nécessite aucune explication, nous nous concentrerons donc uniquement sur les parties importantes.
Le modèle est créé en tant qu'instance de la classe Seq2Seq, qui a les arguments de constructeur suivants:
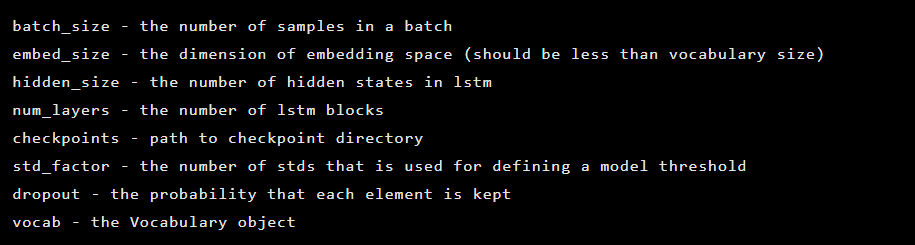
Ensuite, les couches d'auto-encodeur sont initialisées. Premier encodeur:
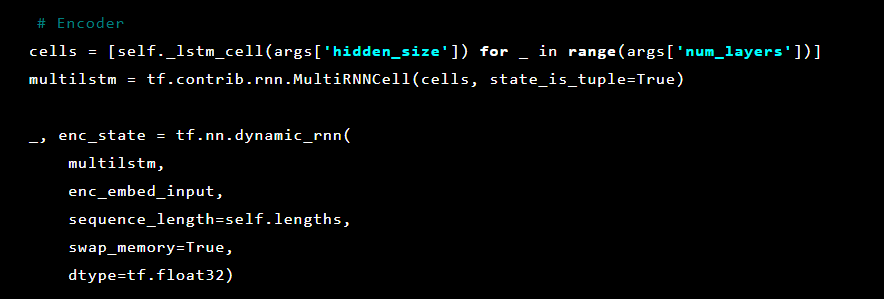
Ensuite, le décodeur:
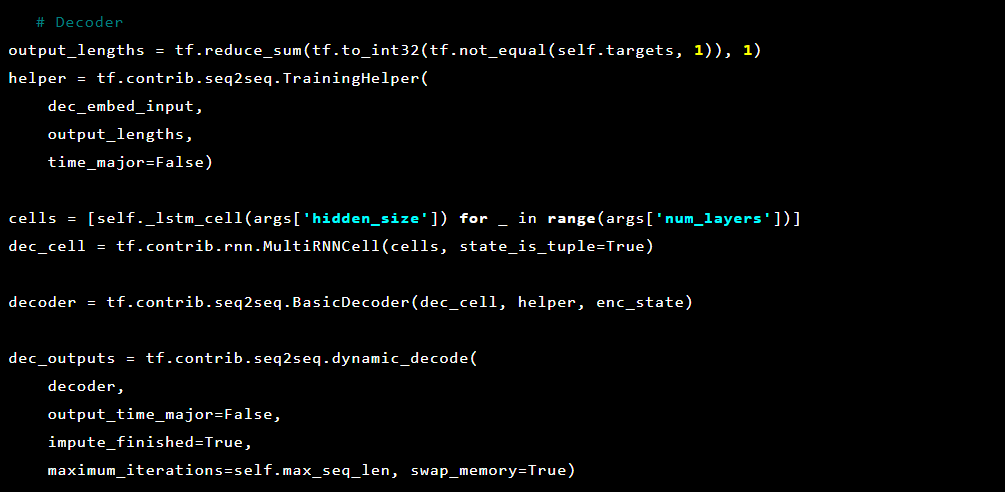
Puisque le problème que nous résolvons est de détecter des anomalies, les valeurs cibles et les entrées sont les mêmes. Donc, notre feed_dict ressemble à ceci:
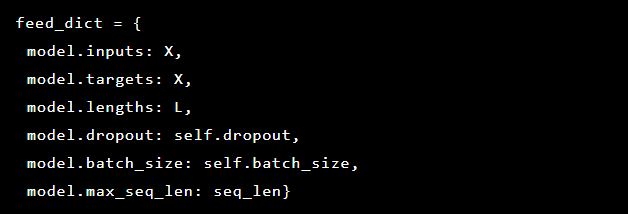
Après chaque ère, le meilleur modèle est enregistré comme point de référence, qui peut ensuite être téléchargé. À des fins de test, une application Web a été créée que nous avons défendue avec un modèle pour vérifier si les attaques réelles ont réussi.
Inspirés par le mécanisme d'attention, nous avons essayé de l'appliquer au modèle d'auto-encodeur pour marquer les parties anormales de cette requête, mais nous avons remarqué que les probabilités dérivées de la dernière couche fonctionnent mieux.

Au stade des tests sur notre échantillon retardé, nous avons obtenu de très bons résultats: la précision et le rappel sont proches de 0,99. Et la courbe ROC tend à 1. Elle a l'air incroyable, n'est-ce pas?
Résultats
Le modèle proposé de l'auto-encodeur Seq2Seq a pu détecter des anomalies dans les requêtes HTTP avec une très grande précision.
Ce modèle agit comme une personne: il étudie uniquement les demandes des utilisateurs «normaux» pour une application web. Et lorsqu'il détecte des anomalies dans les demandes, il sélectionne l'emplacement exact de la demande, qu'il considère comme anormal.
Nous avons testé ce modèle sur certaines attaques sur une application de test et les résultats étaient prometteurs. Par exemple, l'image ci-dessus montre comment notre modèle a détecté une injection SQL divisée en deux paramètres dans un formulaire Web. De telles injections SQL sont appelées fragmentées: des parties de la charge utile d'attaque sont livrées dans plusieurs paramètres HTTP, ce qui rend difficile la détection des WAF basés sur des règles, car ils testent généralement chaque paramètre individuellement.
Le code du modèle et les données de formation et de test sont publiés sur un ordinateur portable Jupyter afin que chacun puisse reproduire nos résultats et suggérer des améliorations.
En conclusion
Nous pensons que notre tâche n'a pas été triviale. Nous voudrions, avec un minimum d'efforts (tout d'abord, éviter les erreurs dues à la complication de la solution), trouver un moyen de détecter les attaques qui, comme par magie, ont appris à décider ce qui est bon et ce qui est mauvais. Deuxièmement, je voulais éviter les problèmes avec le facteur humain, quand exactement un expert décide ce qui est un signe d'une attaque et ce qui ne l'est pas. En résumé, je voudrais noter que l'auto-encodeur avec l'architecture Seq2Seq pour le problème de recherche d'anomalies, à notre avis et pour notre problème, a fait un excellent travail.
Nous voulions également résoudre le problème d'interprétabilité des données. L'utilisation d'architectures de réseaux neuronaux complexes est généralement très difficile. Dans une série de transformations, il est déjà difficile de dire à la fin quelle partie exacte des données a le plus influencé la décision. Cependant, après avoir repensé l'approche de l'interprétation des données par le modèle, il s'est avéré suffisant pour nous d'obtenir les probabilités pour chaque symbole de la dernière couche.
Il convient de noter qu'il ne s'agit pas d'une version de production. Nous ne pouvons pas divulguer les détails de la mise en œuvre de cette approche dans un produit réel, et nous voulons avertir que le simple fait de prendre et d'intégrer cette solution dans certains produits ne fonctionnera pas.
Référentiel GitHub:
goo.gl/aNwq9UAuteurs : Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sakharov (
GitHub ), Arseniy Reutov (
Raz0r )
Références:
- Comprendre les réseaux LSTM
- Réseaux de neurones récurrents augmentés et attention
- L'attention est tout ce dont vous avez besoin
- L'attention est tout ce dont vous avez besoin (annoté)
- Tutoriel de traduction automatique de neurones (seq2seq)
- Codeurs automatiques
- Apprentissage de séquence en séquence avec les réseaux de neurones
- Construire des encodeurs automatiques à Keras