pudge est une base de données clé / valeur
intégrable écrite dans la bibliothèque standard Go.
Je m'attarderai sur les différences fondamentales par rapport aux solutions existantes.
Apatridepudge.Set("../test/test", "Hello", "World")
Puj créera automatiquement la base de données de test, y compris les sous-répertoires, ou l'ouvrira. Il n'est pas nécessaire de stocker l'état de la table et vous pouvez stocker en toute sécurité des valeurs dans des applications multithreads. Pooj est thread-safe.
TypefreeDans puj, vous pouvez écrire des octets, des chaînes, des nombres ou des structures. Sans vous soucier de convertir les données en leur représentation binaire.
type Point struct { X int Y int } for i := 100; i >= 0; i-- { p := &Point{X: i, Y: i} db.Set(i, p) } var point Point db.Get(8, &point) log.Println(point)
Système de requêtePuj offre la possibilité d'extraire des clés dans un ordre spécifique, y compris la sélection avec une limite, l'indentation, le tri et la sélection par préfixe.
keys, _ := db.Keys(7, 2, 0, true)
Le code ci-dessus est similaire à la requête SQL:
select keys from db where key>7 order by keys asc limit 2 offset 0
Veuillez noter que le tri des clés est «paresseux». En revanche, les clés sont stockées en mémoire et cela fonctionne assez rapidement.
ParallélismePooj, comme la plupart des bases de données modernes, utilise un modèle de lecture non bloquant, mais l'écriture dans un fichier bloque toutes les opérations. Mais vous pouvez créer / ouvrir des fichiers à la volée, en minimisant le nombre de verrous. Il n'y a pas d'erreur "base de données déjà ouverte" dans puja. Exemple d'utilisation dans le routeur http:
func write(c *gin.Context) { var err error group := c.Param("group") counter := c.Param("counter") db, err := pudge.Open(group, cfg) if err != nil { renderError(c, err) return } _, err = db.Counter(counter, 1) if err != nil { renderError(c, err) return } c.String(http.StatusOK, "%s", "ok") }
Les moteursMalgré sa petite taille, le puj prend en charge deux modes de stockage de données. En mémoire et sur disque. Par défaut, puj stocke uniquement les données (valeurs) sur le disque. Mais si vous le souhaitez, vous pouvez activer le mode de stockage des données en mémoire. Dans ce cas, ils seront vidés sur le disque à la demande ou à la fermeture de la base de données.
StatutPooj est utilisé à la fois dans les projets domestiques et en production, sur le graphique ci-dessous - le nombre de demandes au serveur http basé sur puj, et le nombre de demandes est supérieur à 20 ms
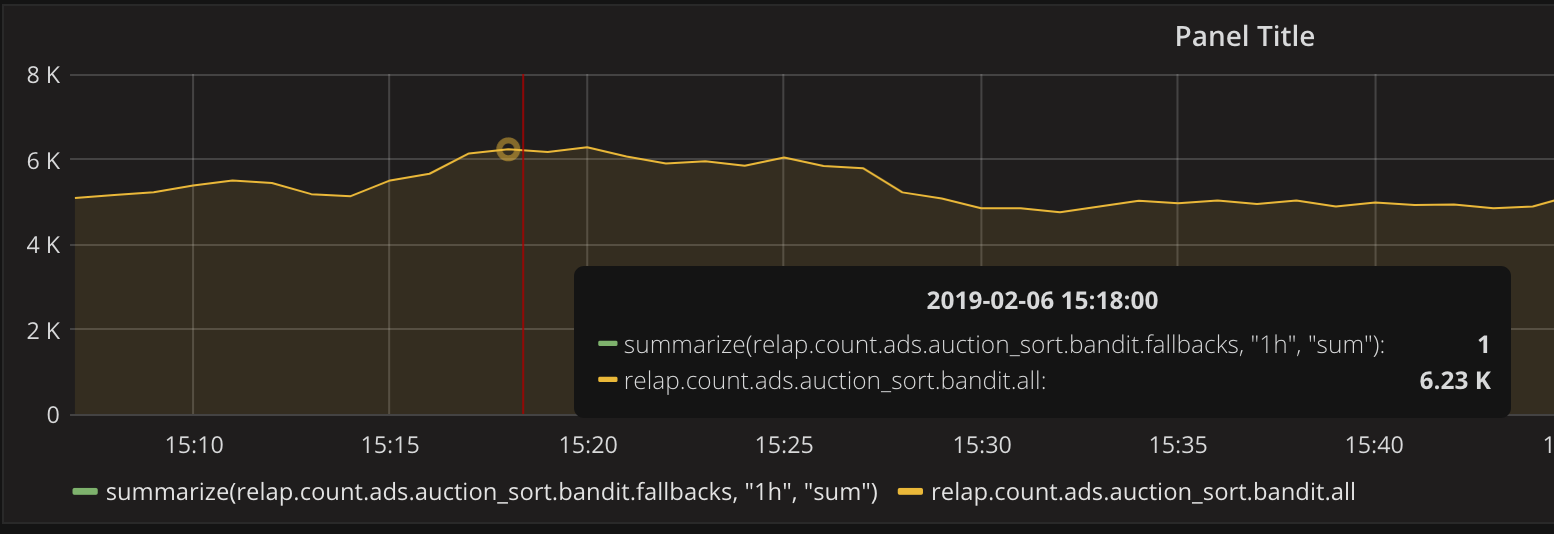
Dans ce cas, le puja est activé en mode de synchronisation complète et, au moment de la synchronisation, des retards importants (plus de 20 ms) se produisent. Mais heureusement, il n'y en a pas tant en pourcentage.
Sur la page du
projet, vous pouvez trouver plus de liens avec des exemples d'intégration de puja dans divers projets.
La vitesseDans le
référentiel avec benchmark'y, vous pouvez comparer puj avec d'autres bases de données:
Test 1
Number of keys: 1000000 Minimum key size: 16, maximum key size: 64 Minimum value size: 128, maximum value size: 512 Concurrency: 2
| pogreb
| goleveldb
| boulon
| badgerdb
| pudge
| slowpoke
| pudge (mem)
|
1M (Put + Get), secondes
| 187
| 38
| 126
| 34
| 23
| 23
| 2
|
1M Put, ops / sec
| 5336
| 34743
| 8054
| 33539
| 47298
| 46789
| 439581
|
1M Get, ops / sec
| 1782423
| 98406
| 499871
| 220597
| 499172
| 445783
| 1652069
|
FileSize Mb
| 568
| 357
| 552
| 487
| 358
| 358
| 358
|
Pooja est très bien équilibré dans le rapport entre la vitesse d'écriture et la vitesse de lecture. Qu'il ne s'agit pas d'une base de données hautement spécialisée optimisée pour la lecture ou l'écriture. À vitesse de lecture élevée - une vitesse d'écriture assez élevée est maintenue. Ce qui, cependant, peut être encore augmenté en parallélisant les enregistrements à différents fichiers (comme cela se fait dans les moteurs LSM Tree).
Liens vers les bases de données utilisées dans le test:
- pogreb Stockage de valeurs-clés intégré pour les charges de travail lourdes en lecture écrites en Go
- goleveldb Base de données de clés / valeurs LevelDB dans Go.
- bolt Une base de données clé / valeur intégrée pour Go.
- badgerdb DB clé-valeur rapide dans Go
- slowpoke Stockage de clé / valeur de bas niveau en pure Go (basé sur le pudge)
- pudge Stockage de clés / valeurs simple et rapide écrit à l'aide de la bibliothèque standard de Go
Ils m'ont demandé de comparer avec memcache et redis, mais comme la majeure partie du temps est consacrée aux interfaces réseau lors de l'interaction avec les données de base de données, ce n'est pas tout à fait juste. Bien que, d'un autre côté, le puja gagne en raison du multithreading, même s'il écrit des données sur le disque.
Développement ultérieur- Les transactions Il serait pratique de combiner les demandes d'écriture dans le pool, avec une restauration automatique en cas d'erreur.
- Possibilité de limiter la durée de vie des clés (comme TTL dans memcache / cassandra, etc.)
- L'absence d'un serveur. Il est pratique d'intégrer le puja dans les microservices existants, mais un serveur distinct apparaîtra probablement. Dans le cadre d'un projet distinct.
- Version mobile. Pour une utilisation sur Android, iOS et en tant que plugin pour Flutter.