Récemment, Jupyter Notebook est devenu très populaire parmi les experts en science des données, devenant la norme de facto pour le prototypage rapide et l'analyse des données. Chez Netflix, nous essayons de repousser encore plus les limites de ses capacités en repensant ce que peut être Notebook, qui peut être utilisé et ce qu'ils peuvent en faire. Nous avons mis beaucoup d'efforts pour traduire notre vision en réalité.
Dans cet article, nous voulons vous expliquer pourquoi nous pensons que les ordinateurs portables Jupyter sont si attrayants et qui nous inspirent en cours de route. De plus, nous décrivons les composants de notre infrastructure et examinons de nouvelles façons d'utiliser Jupyter Notebook dans Netflix.

Note du traducteur: attention, beaucoup de texte et peu d'images
Si vous n'avez pas beaucoup de temps, nous vous suggérons de vous rendre immédiatement dans la section Cas d'utilisation .
Pourquoi tout ça?
Les données sont la puissance de Netflix. Ils imprègnent nos pensées, influencent nos décisions et remettent en cause nos hypothèses . Ils facturent des expériences et l' émergence d'une nouvelle à une échelle sans précédent . Les données nous permettent de découvrir des significations inattendues et de vivre une expérience personnalisée incroyable pour 130 millions de nos utilisateurs à travers le monde .
Faire de tout cela une réalité est une réalisation considérable, nécessitant un soutien technique et infrastructurel impressionnant. Chaque jour, plus d'un billion d'événements sont reçus dans un flux (pipeline d'ingestion de streaming) qui est traité et enregistré dans un stockage cloud de 100PB. Et chaque jour, nos utilisateurs effectuent plus de 150 000 tâches sur ces données, couvrant tout, des rapports à l'apprentissage automatique et aux algorithmes de recommandation.
Pour prendre en charge de tels scénarios d'utilisation à une telle échelle, nous avons construit l'un des meilleurs de l'industrie, une plate-forme de traitement des données flexible, puissante et, si nécessaire, complexe (Netflix Data Platform). Nous avons également développé des outils et services supplémentaires, tels que Genie (service d'exécution de tâches) et Metacat (méta-stockage). Ces outils réduisent la complexité et permettent ainsi de prendre en charge un plus large éventail d'utilisateurs dans toute l'entreprise.

La variété des utilisateurs est impressionnante, mais vous devez payer pour cela: la plate-forme de données Netflix et son écosystème d'outils et de services doivent évoluer pour prendre en charge des scénarios d'utilisation supplémentaires, des langues, des schémas d'accès, etc. Pour une meilleure compréhension du problème, nous considérons trois positions communes: un ingénieur analyste, un ingénieur de données et un scientifique des données.
 La différence dans la préférence des langues et des outils pour différentes positions
La différence dans la préférence des langues et des outils pour différentes positionsEn règle générale, chaque poste préfère utiliser son propre ensemble d'outils et de langues. Par exemple, un ingénieur de données peut créer un nouvel ensemble de données contenant des milliards de flux d'événements à l'aide de Scala dans IntelliJ. L'analyste peut les utiliser dans un nouveau rapport de qualité de streaming global à l'aide de SQL et Tableau. Ce rapport peut être envoyé à un Data Scientist qui construira un nouveau modèle de compression de streaming à l'aide de R et RStudio. À première vue, ces processus semblent fragmentés, bien que complémentaires, mais si vous regardez plus en profondeur, chacun de ces processus a plusieurs tâches qui se chevauchent:
exploration des données - a lieu à un stade précoce du projet; peut inclure un aperçu des données d'échantillonnage, des requêtes pour l'analyse statistique et la visualisation des données
préparation des données - une tâche répétitive, peut inclure le nettoyage, la standardisation, la transformation, la dénormalisation et l'agrégation des données; généralement la partie la plus longue du projet
validation des données - une tâche qui se produit régulièrement; peut comprendre une enquête sur les données échantillonnées, une analyse statistique, une analyse agrégée et une visualisation des données; se produit généralement dans le cadre de l'exploration des données, de la préparation des données, du développement, du pré-déploiement et du post-déploiement
productionnalisation - se produit à un stade avancé du projet; peut inclure le déploiement de code, des exemples d'ajouts, la formation de modèles, la validation des données et la planification des workflows
Pour étendre les capacités de nos utilisateurs, nous voulons rendre ces tâches aussi simples que possible.
Pour étendre les capacités de notre plateforme, nous voulons minimiser le nombre d'outils qui doivent être pris en charge. Mais comment? Aucun outil ne peut couvrir toutes ces tâches. De plus, souvent une tâche nécessite l'utilisation de plusieurs outils. Cependant, si nous nous désengageons, un modèle commun apparaît pour tous les outils et langages: exécuter du code, examiner les données, présenter le résultat.
Il se trouve qu'un projet open source a été développé spécifiquement pour cela: le projet Jupyter .
Cahiers Jupyter

Le cahier Jupyter dans nteract affiche Vega et Altair
Le projet Jupyter a été lancé en 2014 dans le but de créer un ensemble cohérent d'outils open source pour la recherche, le workflow reproductible et l'analyse des données. Ces outils ont été très appréciés par l'industrie et aujourd'hui, Jupyter est devenu une partie intégrante de la boîte à outils de tout scientifique. Pour comprendre l'étendue de son influence, nous notons que Jupyter a reçu le prix ACM Software Systems Award 2017 - un prix prestigieux qu'il partage avec Java, Unix et the_Web.
Pour comprendre pourquoi le bloc-notes Jupyter est si attrayant pour nous, considérez ses principales caractéristiques:
- protocole de messagerie pour analyser et exécuter du code quelle que soit la langue
- format de fichier avec la possibilité de modifier, pour la description, l'affichage et l'exécution du code, la sortie et les notes de démarque
- interface Web pour l'écriture interactive, l'exécution de code et la visualisation des résultats
Le protocole Jupyter fournit une API de messagerie standardisée avec des noyaux qui agissent comme des modules de calcul et fournit une architecture composable, partageant ainsi où le code (UI) est stocké et où il est exécuté (le noyau). Ainsi, en séparant l'interface et le noyau, les ordinateurs portables peuvent fonctionner dans plusieurs langues tout en conservant la flexibilité de configurer le runtime. S'il existe une langue pour une langue qui peut échanger des messages à l'aide du protocole Jupyter, Notebook peut exécuter du code en envoyant et en recevant des messages vers ce noyau.
En plus de tout, tout cela est pris en charge par un format de fichier qui vous permet de stocker à la fois le code lui-même et les résultats de son exécution en un seul endroit. Cela signifie que vous pouvez afficher les résultats de l'exécution ultérieurement sans avoir à redémarrer le code lui-même. Les ordinateurs portables peuvent également stocker une description détaillée du contexte et de ce qui se passe exactement à l'intérieur. Cela en fait un format idéal pour transmettre un contexte commercial, fixer des hypothèses, commenter du code, décrire des conclusions, et bien plus encore.
Cas d'utilisation
Parmi les nombreux scénarios, les cas d'utilisation les plus courants sont: l'accès aux données, les modèles de bloc-notes et la planification des blocs-notes.
Accès aux données
Jupyter Notebook est apparu à l'origine sur Netflix pour prendre en charge les workflows de science des données. Au fur et à mesure que leur utilisation parmi les experts en science des données augmentait, nous avons vu le potentiel d'étendre les capacités de nos outils. Nous avons réalisé que nous pouvions utiliser la polyvalence et l'architecture du Jupyter Notebook et étendre ses capacités de partage de données. Au troisième trimestre de 2017, nous avons sérieusement commencé à faire de Notebook un outil pour un cercle restreint de spécialistes en un représentant de première classe de la plate-forme de données Netflix.
Du point de vue de nos utilisateurs, les ordinateurs portables offrent une interface pratique pour l'exécution interactive de commandes, la recherche de sortie et la visualisation des données - le tout dans un environnement de développement cloud. Nous prenons également en charge la bibliothèque Python, qui combine l'accès à l'API de la plateforme. Cela signifie que les utilisateurs ont un accès programmatique à la quasi-totalité de la plate-forme Netflix via Notebook. Grâce à cette combinaison de flexibilité, de puissance et de facilité d'utilisation, l'entreprise a connu une forte augmentation de son utilisation par tous les types d'utilisateurs de la plateforme.
Aujourd'hui, notebook est l'outil de données le plus populaire de Netflix.
Modèles de cahier
À mesure que la prise en charge de Jupyter Notebooks s'est développée au sein de la plate-forme, nous avons commencé à introduire de nouvelles fonctionnalités pour l'utiliser pour répondre à de nouveaux scénarios d'utilisation. De là sont venus des ordinateurs portables paramétrés. Les ordinateurs portables paramétrés représentent exactement ce que leur nom dit: un ordinateur portable qui vous permet de définir des paramètres dans le code et de recevoir des données au moment de l'exécution. Cela fournit un bon mécanisme pour que les utilisateurs définissent le bloc-notes comme des modèles réutilisables.
Nos utilisateurs ont trouvé de nombreuses façons d'utiliser de tels modèles. Nous énumérons quelques-uns des plus utilisés:
- Data Scientist : expérimentez avec différents coefficients et résumez les résultats
- Ingénieur de données : effectuer une collection d'audits de qualité des données dans le cadre du processus de déploiement.
- Data Analyst : partagez des requêtes et des visualisations préparées afin que les parties prenantes puissent explorer les données plus en profondeur que Tableau ne le permet
- Ingénieur logiciel : envoyer les résultats d'un script pour résoudre un crash
Planification des carnets (planificateur)
L'une des façons originales d'utiliser Notebook consiste à créer une couche de fusion pour planifier les workflows.
Étant donné que chaque ordinateur portable peut fonctionner sur un noyau arbitraire, nous pouvons prendre en charge n'importe quel environnement d'exécution défini par l'utilisateur. Et puisque les blocs-notes décrivent un flux d'exécution linéaire divisé en cellules, nous pouvons relier l'échec à une cellule spécifique. Cela permet aux utilisateurs de décrire l'exécution et les visualisations sous une forme plus narrative, qui peut être capturée avec précision au démarrage à un moment ultérieur.
Un tel paradigme vous permet d'utiliser un ordinateur portable pour un travail interactif et de passer en douceur à plusieurs exécutions et à l'utilisation du planificateur. Ce qui s'est avéré très pratique pour les utilisateurs. De nombreux utilisateurs créent des workflows entiers dans le bloc-notes uniquement pour les dupliquer ensuite dans des fichiers séparés et les exécuter au bon moment. En traitant le bloc-notes comme une description de processus séquentielle, nous pouvons facilement planifier leur exécution comme n'importe quel autre flux de travail.
Nous pouvons planifier l'exécution d'autres types de travaux via des cahiers. Lorsqu'un travail Spark ou Presto est exécuté à partir du planificateur, le code source est inséré dans le bloc-notes nouvellement créé et exécuté. Ce bloc-notes devient un référentiel d'historique contenant le code source, les paramètres, les configurations, les journaux d'exécution, les messages d'erreur, etc. Lors du dépannage, cela fournit un point de départ rapide pour l'enquête, car toutes les informations pertinentes se trouvent à l'intérieur et le bloc-notes peut être exécuté pour un débogage interactif.
Infrastructure pour ordinateur portable
La prise en charge des scénarios décrits ci-dessus à l'échelle de Netflix nécessite une infrastructure de prise en charge étendue. Présentez brièvement plusieurs projets qui seront discutés dans les sections suivantes:
nteract est la nouvelle génération d'interfaces utilisateur React pour les ordinateurs portables Jupyter. Il fournit une interface simple et intuitive et propose plusieurs améliorations pour l'interface utilisateur Jupyter classique, telles que des barres d'outils de cellules en ligne, des cellules glisser-déposer et un explorateur intégré.
Bibliothèque Papermill pour le paramétrage, l'exécution et l'analyse des cahiers Jupyter. À l'aide de laquelle vous pouvez propager plusieurs cahiers avec différents paramètres et les exécuter simultanément. Papermill vous permet également de collecter et de résumer des mesures pour une collection entière de cahiers.
Commuter est un service léger et évolutif verticalement pour visualiser et partager un ordinateur portable. Il fournit une version compatible Jupyter de l'API pour le contenu et facilite la lecture des blocs-notes stockés localement sur Amazon S3. Propose également un explorateur pour rechercher et partager des fichiers.
Titus est une plateforme de gestion de conteneurs qui fournit un lancement de conteneur évolutif et fiable et une intégration native dans le cloud avec Amazon AWS. Titus a été développé chez Netflix et est utilisé au combat pour prendre en charge les systèmes de streaming, de recommandation et de contenu Netflix.
Une description plus détaillée de l'architecture peut être trouvée dans l'article Scheduling Notebooks at Netflix . Aux fins de cet article, nous nous limitons aux trois composants fondamentaux du système: le stockage, l'exécution et l'interface.
 Infrastructure pour ordinateur portable sur Netflix
Infrastructure pour ordinateur portable sur NetflixStockage
La plate-forme de données Netflix utilise le stockage cloud Amazon S3 et EFS, que les ordinateurs portables traitent comme des systèmes de fichiers virtuels. Cela signifie que chaque utilisateur dispose d'un répertoire de base EFS contenant un espace de travail personnel pour les blocs-notes. Dans cet espace, nous stockons tout cahier créé ou chargé par l'utilisateur. C'est également l'endroit où la lecture et l'écriture se produisent lorsque l'utilisateur démarre de manière interactive l'ordinateur portable. Nous utilisons la combinaison [espace de travail + nom de fichier] pour l'espace de noms, c'est-à-dire /efs/users/kylek/notebooks/MySparkJob.ipynb pour la visualisation, le partage et dans le planificateur d'exécution. Un tel accord empêche les collisions et facilite l'identification de l'utilisateur et de l'emplacement du bloc-notes dans EFS.
Le chemin d'accès à l'espace de travail vous permet d'ignorer la complexité du stockage cloud pour l'utilisateur. Par exemple, seuls les noms des fichiers du carnet sont affichés dans le répertoire, c'est-à-dire MySparkJob.ipynb. Le même fichier est disponible via le terminal: ~ / notebooks / MySparkJob.ipynb.

Stockage pour ordinateur portable vs accès
Lorsque l'utilisateur définit la tâche de démarrage du bloc-notes, le planificateur copie le bloc-notes de l'utilisateur d'EFS dans le répertoire partagé sur S3. Le bloc-notes dans S3 devient la source de vérité pour le planificateur ou le bloc-notes source. Chaque fois que le planificateur (répartiteur) démarre le bloc-notes, il crée un nouveau bloc-notes à partir de la source. Ce nouveau bloc-notes est ce qui démarre réellement et devient un enregistrement invariable d'une exécution spécifique, contenant le code exécutable, la sortie et les journaux de chaque cellule. Nous l'appelons carnet de sortie (sortie).
La co-création est une caractéristique fondamentale de Netflix. Par conséquent, il n'était pas surprenant que les utilisateurs aient commencé à échanger des liens URL vers le bloc-notes. Avec la croissance de cette pratique, nous sommes confrontés au problème de la réécriture accidentelle causée par l'accès simultané de plusieurs utilisateurs au même bloc-notes. Nos utilisateurs voulaient un moyen de partager leur ordinateur portable actif en mode lecture seule. Cela a conduit à la création de Commuter . Sous le capot, Commuter affiche l'API Jupyter pour répertorier / files et / api / contents dans une liste de répertoires, pour afficher le contenu des fichiers et accéder aux métadonnées des fichiers. Cela signifie que les utilisateurs peuvent afficher les blocs-notes sans conséquences pour les tâches de combat ou les blocs-notes en direct.
Calculer
La gestion des ressources informatiques est l'une des parties les plus difficiles du travail avec les données. Cela est particulièrement vrai dans Netflix, où nous utilisons l'architecture de conteneur hautement évolutive dans AWS. Tous les travaux sur la plateforme de données sont exécutés dans des conteneurs, y compris les requêtes, les pipelines et le bloc-notes. Naturellement, nous avons voulu nous abstenir le plus possible de cette complexité.
Un conteneur est fourni lorsque l'utilisateur démarre le serveur de bloc-notes. Nous fournissons des valeurs par défaut rationnelles pour les ressources de conteneur qui fonctionnent pour environ 87,3% des modèles d'exécution. Lorsque cela ne suffit pas, les utilisateurs peuvent demander plus de ressources à l'aide d'une interface simple.

Les utilisateurs peuvent sélectionner autant ou aussi peu de mémoire de calcul + que nécessaire
Nous fournissons également un runtime unifié avec une image de conteneur terminée. L'image a des bibliothèques partagées et un ensemble prédéfini de noyaux par défaut. Tout dans l'image n'est pas statique - nos noyaux utilisent les dernières versions de Spark et les dernières configurations de cluster pour notre plate-forme. Cela réduit l'encombrement et le temps de réglage pour les nouveaux ordinateurs portables et nous maintient généralement dans un environnement d'exécution unique.
Sous le capot, nous gérons l'orchestration et les environnements avec Titus , notre service de gestion de conteneurs Docker. Nous créons en outre un wrapper sur ce service, gérant des configurations et des images de serveur utilisateur spécifiques. L'image comprend également des groupes et des rôles de sécurité des utilisateurs, ainsi que des variables d'environnement communes pour l'identification dans les bibliothèques incluses. Cela signifie que nos utilisateurs peuvent consacrer moins de temps à l'infrastructure et plus de temps aux données.
Interface
Plus tôt, nous avons décrit notre vision selon laquelle les ordinateurs portables devraient être l'outil le plus efficace et optimal pour travailler avec des données. Mais cela présente un défi intéressant: comment une interface peut-elle prendre en charge tous les utilisateurs? Nous ne connaissons pas la réponse exacte, mais nous avons quelques idées.
Nous savons que la simplicité est nécessaire. Cela signifie une interface utilisateur intuitive avec un style minimaliste, et cela nécessite également une expérience utilisateur réfléchie qui rend les choses complexes faciles à faire. Cette philosophie cadre bien avec les objectifs de nteract , écrits sur le frontend React pour le cahier Jupyter. Il met l'accent sur la composabilité en tant que principes de conception fondamentaux, ce qui en fait un élément idéal de notre vision.
La plainte la plus courante de nos utilisateurs est le manque de visualisation native pour toutes les langues, en particulier pour les langues non Python. Data Explorer nteract — , .
Data Explorer MyBinder. ( )

Visualizing the World Happiness Report dataset with nteract's Data Explorer
, notebook, .
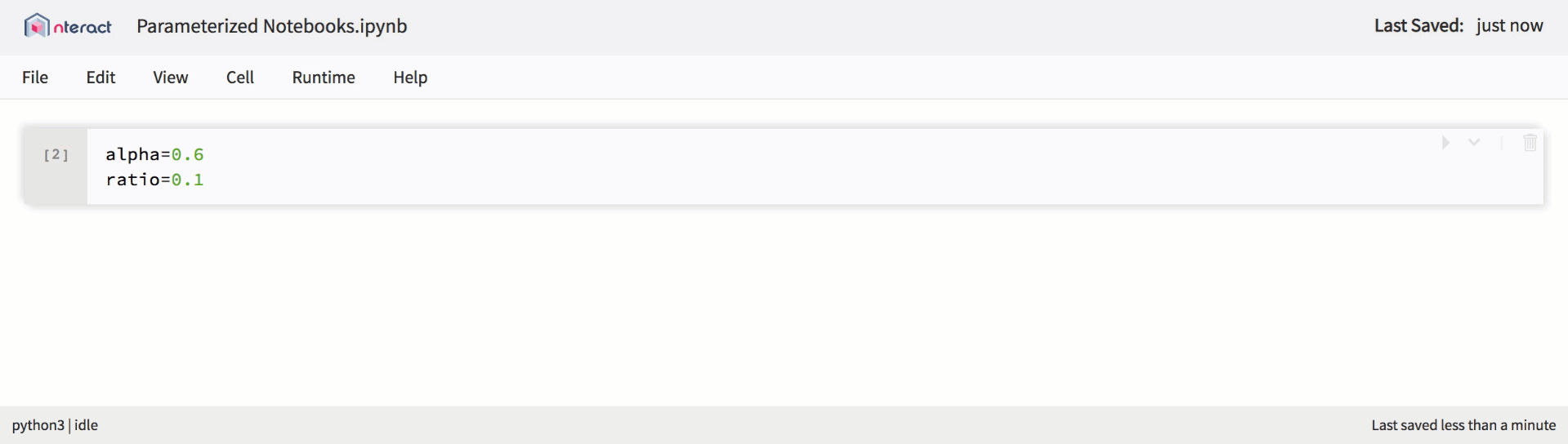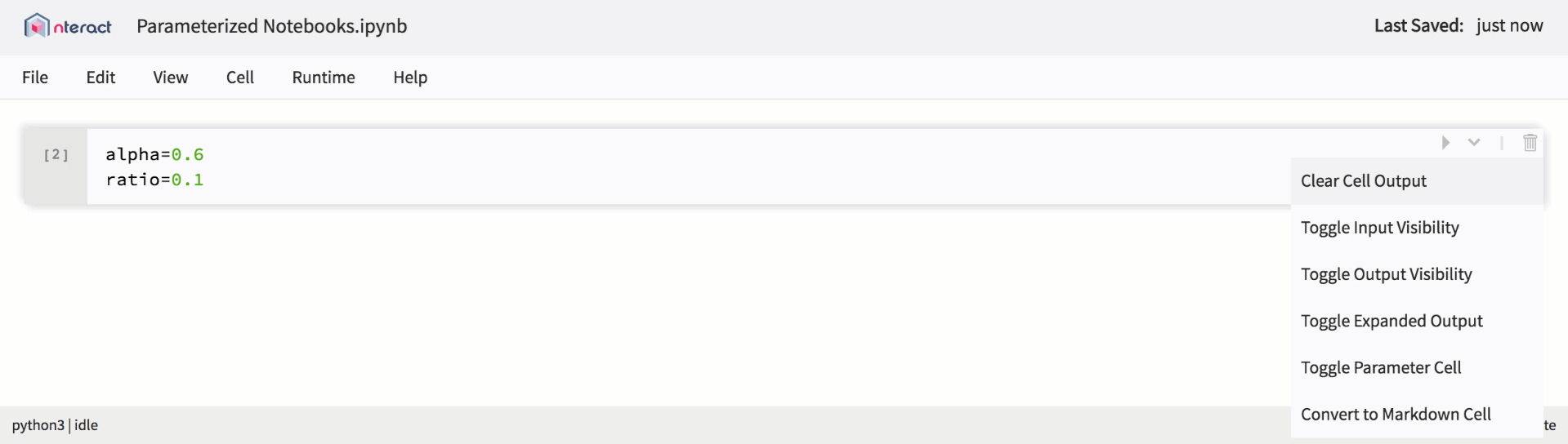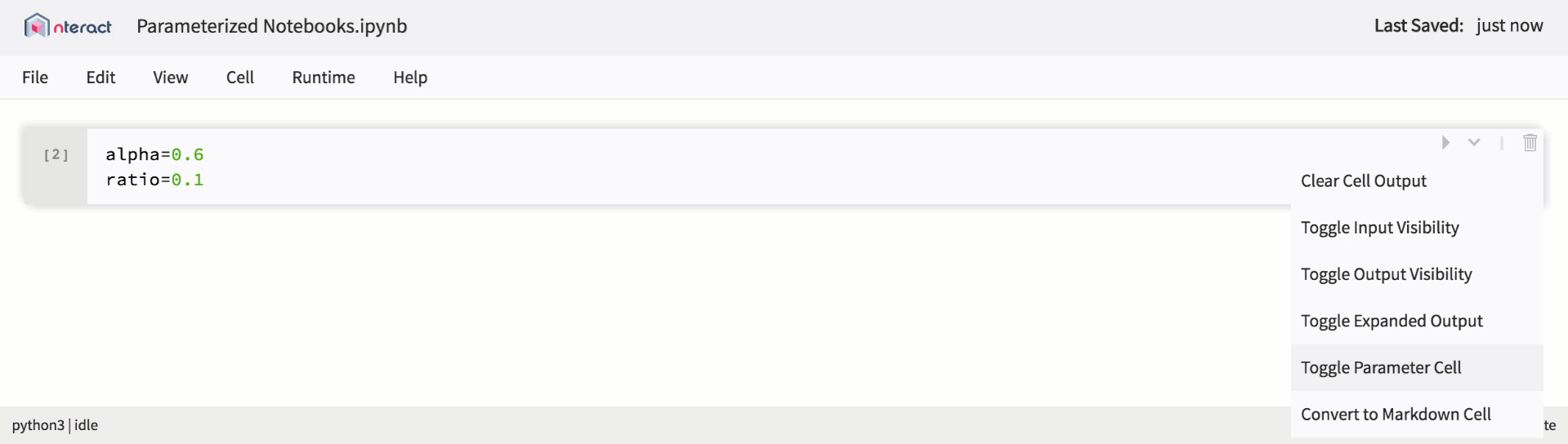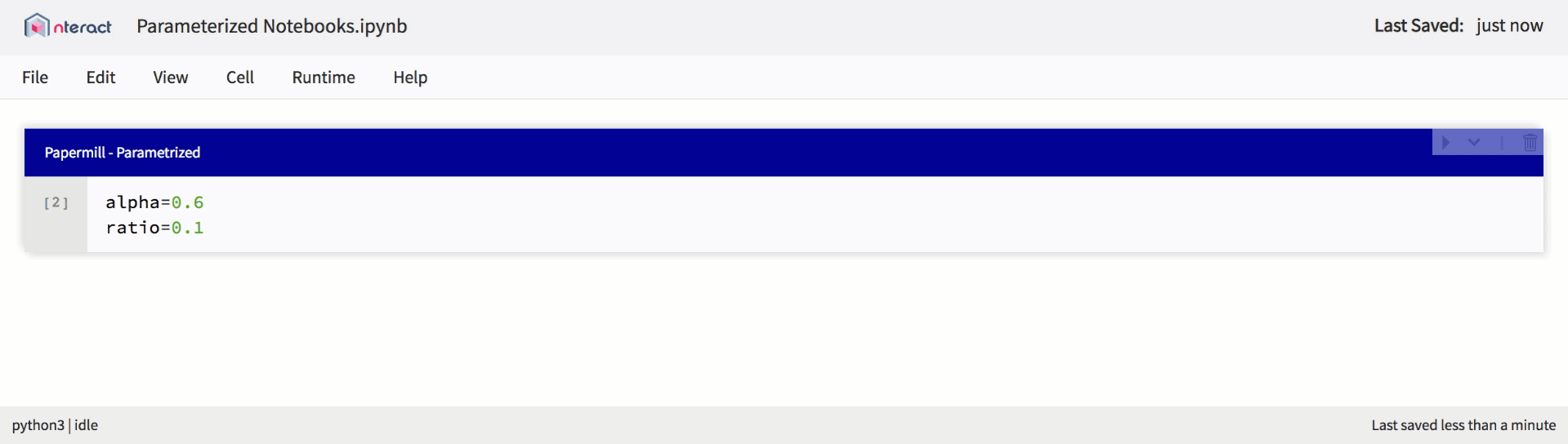
Native support for parameterized notebooks in nteract
Jupyter notebook , . , notebook. 12 , . , , , . , , Spark DataFrames, Scala. .
Open Source Projects
Netflix . , , . Netflix Data Platform Netflix OSS . “Not Invented Here”. Spark , Jupyter pandas .
, , Jupyter Project, . , nteract notebook UI Netflix. , . , Jupyter Notebook, , , . nteract.
, Netflix, . , , , , . , Papermill, .
What's Next ( )
, – (Netflixers) . Notebook Netflix. , . , .
! . , notebook. notebook Netflix, . :
I: Notebook Innovation ( )
II: Scheduling Notebooks
:
Scheduling workflows , — .