Récemment, ils parlent de plus en plus de l'analyse statique comme l'un des moyens importants d'assurer la qualité des produits logiciels en cours de développement, en particulier du point de vue de la sécurité. L'analyse statique vous permet de trouver des vulnérabilités et autres erreurs, elle peut être utilisée dans le processus de développement, s'intégrant dans des processus personnalisés. Cependant, en relation avec son application, de nombreuses questions se posent. Quelle est la différence entre les outils payants et gratuits? Pourquoi ne suffit-il pas d'utiliser le linter? En fin de compte, qu'est-ce que la statistique a à voir avec cela? Essayons de le comprendre.

Répondons tout de suite à la dernière question - les statistiques n'y sont pour rien, bien que l'analyse statique soit souvent appelée à tort statistique. L'analyse est statique, car l'application ne démarre pas pendant la numérisation.
Voyons d'abord ce que nous voulons rechercher dans le code du programme. L'analyse statique est le plus souvent utilisée pour rechercher des vulnérabilités - des sections de code, dont la présence peut entraîner une violation de la confidentialité, de l'intégrité ou de la disponibilité du système d'information. Cependant, les mêmes technologies peuvent être utilisées pour rechercher d'autres erreurs ou fonctionnalités de code.
Nous réservons qu'en général le problème de l'analyse statique est algorithmiquement insoluble (par exemple, par le théorème de Rice). Par conséquent, vous devez soit limiter les conditions de la tâche, soit autoriser l'inexactitude des résultats (ignorer les vulnérabilités, donner des faux positifs). Il s'avère que sur les vrais programmes, la deuxième option s'avère fonctionner.
Il existe de nombreux outils payants et gratuits qui revendiquent la recherche de vulnérabilité dans des applications écrites dans différents langages de programmation. Voyons comment l’analyseur statique est généralement organisé. De plus, nous nous concentrerons sur le noyau et les algorithmes de l'analyseur. Bien sûr, les outils peuvent différer par la convivialité de l'interface, par l'ensemble de fonctionnalités, par l'ensemble de plug-ins pour différents systèmes et par la facilité d'utilisation de l'API. C'est probablement un sujet pour un article séparé.
Présentation intermédiaire
On peut distinguer trois étapes de base dans le schéma de fonctionnement d'un analyseur statique.
- Construction d'une représentation intermédiaire (une représentation intermédiaire est également appelée représentation interne ou modèle de code).
- L'utilisation d'algorithmes d'analyse statique, à la suite de laquelle le modèle de code est complété par de nouvelles informations.
- Application de règles de recherche de vulnérabilités à un modèle de code augmenté.
Différents analyseurs statiques peuvent utiliser différents modèles de code, par exemple, le code source du programme, le flux de jetons, l'arbre d'analyse, le code à trois adresses, le graphique de flux de contrôle, le bytecode - standard ou natif - et ainsi de suite.

Comme les compilateurs, l'analyse lexicale et syntaxique est utilisée pour construire une représentation interne, le plus souvent un arbre d'analyse (AST, Abstract Syntax Tree). L'analyse lexicale décompose le texte du programme en éléments sémantiques minimaux, à la sortie recevant un flux de jetons. L'analyse vérifie que le flux de jetons correspond à la grammaire du langage de programmation, c'est-à-dire que le flux de jetons résultant est correct du point de vue du langage. À la suite de l'analyse, un arbre d'analyse est construit - une structure qui modélise le code source du programme. Ensuite, l'analyse sémantique est appliquée; elle vérifie le respect de conditions plus complexes, par exemple, la correspondance des types de données dans les instructions d'affectation.
L'arbre d'analyse peut être utilisé comme représentation interne. Vous pouvez également obtenir d'autres modèles à partir de l'arbre d'analyse. Par exemple, vous pouvez le traduire en un code à trois adresses, qui, à son tour, crée un graphique de flux de contrôle (CFG). En règle générale, CFG est le modèle principal pour les algorithmes d'analyse statique.

En analyse binaire (analyse statique de code binaire ou exécutable), un modèle est également construit, mais des pratiques de reverse engineering sont déjà utilisées ici: décompilation, désobfuscation, traduction inverse. Par conséquent, vous pouvez obtenir les mêmes modèles qu'à partir du code source, y compris le code source (en utilisant la décompilation complète). Parfois, le code binaire lui-même peut servir de représentation intermédiaire.
Théoriquement, plus le modèle est proche du code source, plus la qualité de l'analyse est mauvaise. Sur le code source lui-même, vous ne pouvez rechercher que des expressions régulières, ce qui ne vous permettra pas de trouver au moins une vulnérabilité compliquée.
Analyse du flux de données
L'un des principaux algorithmes d'analyse statique est l'analyse du flux de données. La tâche de cette analyse est de déterminer à chaque point du programme des informations sur les données sur lesquelles le code fonctionne. Les informations peuvent être différentes, par exemple, le type ou la valeur des données. Selon les informations à déterminer, la tâche d'analyse du flux de données peut être formulée.

Par exemple, s'il est nécessaire de déterminer si une expression est une constante, ainsi que la valeur de cette constante, le problème de propagation des constantes (propagation constante) est résolu. S'il est nécessaire de déterminer le type d'une variable, alors nous pouvons parler du problème de propagation de type. Si vous avez besoin de comprendre quelles variables peuvent pointer vers une zone de mémoire spécifique (stocker les mêmes données), alors nous parlons de la tâche de l'analyse des synonymes (analyse des alias). Il existe de nombreuses autres tâches d'analyse de flux de données qui peuvent être utilisées dans un analyseur statique. Comme les étapes de construction d'un modèle de code, ces tâches sont également utilisées dans les compilateurs.
Dans la théorie de la construction de compilateurs, des solutions au problème de l'analyse intra-procédurale d'un flux de données sont décrites (il est nécessaire de suivre les données dans une seule procédure / fonction / méthode). Les décisions sont basées sur la théorie des réseaux algébriques et d'autres éléments des théories mathématiques. Le problème de l'analyse du flux de données peut être résolu en temps polynomial, c'est-à-dire pendant un temps acceptable pour les ordinateurs, si les conditions du problème satisfont aux conditions du théorème de solvabilité, ce qui en pratique ne se produit pas toujours.
Nous vous en dirons plus sur la résolution du problème de l'analyse intra-procédurale du flux de données. Pour définir une tâche spécifique, en plus de déterminer les informations dont vous avez besoin, vous devez déterminer les règles de modification de ces informations lors de la transmission de données conformément aux instructions de CFG. Rappelons que les nœuds du CFG sont les blocs de base - des ensembles d'instructions dont l'exécution est toujours séquentielle, et les arcs indiquent le transfert de contrôle possible entre les blocs de base.
Pour chaque instruction
les ensembles sont définis:
- (informations générées par l'instruction ),
- (informations détruites par l'instruction ),
- (informations au point avant l'instruction ),
- (informations au point après l'instruction )
L'analyse de flux de données a pour objectif de définir des ensembles
et
pour chaque instruction
programmes. Le système de base d'équations avec lequel les tâches d'analyse du flux de données sont résolues est déterminé par la relation suivante (équations de flux de données):
La deuxième relation formule les règles selon lesquelles l'information est «combinée» aux points de confluence des arcs CFG (
- prédécesseurs
en CFG). L'opération d'union, d'intersection et quelques autres peut être utilisée.
L'information souhaitée (l'ensemble des valeurs des fonctions présentées ci-dessus) est formalisée comme un réseau algébrique. Les fonctions
et
sont considérés comme des mappages monotones sur des réseaux (fonctions d'écoulement). Pour les équations de flux de données, la solution est le point fixe de ces mappages.
Les algorithmes pour résoudre les problèmes d'analyse de flux de données recherchent des points fixes maximaux. Il existe plusieurs approches de la solution: algorithmes itératifs, analyse de composants fortement connectés, analyse T1-T2, analyse d'intervalle, analyse structurelle, etc. Il existe des théorèmes sur l'exactitude de ces algorithmes; ils déterminent la portée de leur applicabilité à des problèmes réels. Je le répète, les conditions des théorèmes peuvent ne pas être remplies, ce qui conduit à des algorithmes plus compliqués et à des résultats inexacts.
Analyse interprocédurale
En pratique, il est nécessaire de résoudre les problèmes d'analyse interprocédurale du flux de données, car rarement la vulnérabilité sera complètement localisée dans une seule fonction. Il existe plusieurs algorithmes courants.
Fonctions en ligne . Au point d'appel de fonction, nous intégrons la fonction appelée, réduisant ainsi la tâche d'analyse interprocédurale à la tâche d'analyse intraprocédurale. Cette méthode est facilement implémentée, mais en pratique, lorsqu'elle est appliquée, une explosion combinatoire est rapidement réalisée.
Construction d'un graphique général du flux de contrôle de programme dans lequel les appels de fonction sont remplacés par des transitions vers l'adresse de début de la fonction appelée et les instructions de retour sont remplacées par des transitions vers toutes les instructions suivant toutes les instructions pour appeler cette fonction. Cette approche ajoute un grand nombre de chemins d'exécution irréalisables, ce qui réduit considérablement la précision de l'analyse.
Un algorithme similaire au précédent, mais lors du passage à une fonction,
le contexte est
enregistré - par exemple, un cadre de pile. Ainsi, le problème de la création de chemins irréalisables est résolu. Cependant, l'algorithme est applicable avec une profondeur d'appel limitée.
Informations sur la fonction de construction (résumé de la fonction). L'algorithme d'analyse interprocédurale le plus applicable. Il est basé sur la construction d'un résumé pour chaque fonction: les règles par lesquelles les informations sur les données sont converties lors de l'application de cette fonction, en fonction des différentes valeurs des arguments d'entrée. Des résumés prêts à l'emploi sont utilisés dans l'analyse procédurale interne des fonctions. Une difficulté distincte ici est la détermination de l'ordre de la traversée de fonction, car dans l'analyse au cas par cas, un résumé doit déjà être construit pour toutes les fonctions appelées. Habituellement, des algorithmes itératifs spéciaux pour traverser un graphe d'appel sont créés.
L'analyse interprocédurale des flux de données est une tâche exponentiellement difficile, c'est pourquoi l'analyseur doit effectuer un certain nombre d'optimisations et d'hypothèses (il est impossible de trouver la solution exacte en temps voulu pour la puissance de calcul). Habituellement, lors du développement d'un analyseur, il est nécessaire de trouver un compromis entre la quantité de ressources consommées, le temps d'analyse, le nombre de faux positifs et les vulnérabilités trouvées. Par conséquent, un analyseur statique peut fonctionner pendant une longue période, consommer beaucoup de ressources et donner des faux positifs. Cependant, sans cela, il est impossible de trouver les vulnérabilités les plus importantes.
C'est à ce stade que les analyseurs statiques sérieux diffèrent de nombreux outils ouverts, qui, en particulier, peuvent se positionner dans la recherche de vulnérabilités. Les vérifications rapides en temps linéaire sont bonnes lorsque vous devez obtenir le résultat rapidement, par exemple lors de la compilation. Cependant, cette approche ne peut pas trouver les vulnérabilités les plus critiques - par exemple, liées à la mise en œuvre des données.
Analyse des souillures
Nous devons également nous attarder sur l'une des tâches de l'analyse des flux de données - l'analyse des souillures. L'analyse des souillures vous permet de distribuer des drapeaux tout au long du programme. Cette tâche est essentielle à la sécurité de l'information, car c'est à l'aide de celle-ci que des vulnérabilités sont découvertes liées à la mise en œuvre des données (injections SQL, crossite scripting, redirections ouvertes, falsification du chemin du fichier, etc.), ainsi que des fuites de données confidentielles (saisie du mot de passe dans journaux d'événements, transfert de données non sécurisé).
Essayons de simuler une tâche. Supposons que nous voulons suivre n drapeaux -
. Beaucoup d'informations ici seront beaucoup de sous-ensembles
\ {f_1, ..., f_n \} , car pour chaque variable à chaque point du programme, nous voulons définir ses drapeaux.
Ensuite, nous devons définir les fonctions de flux. Dans ce cas, les fonctions de flux peuvent être déterminées par les considérations suivantes.
- De nombreuses règles sont données dans lesquelles sont définies les constructions qui conduisent à l'apparition ou au changement d'un ensemble de drapeaux.
- L'opération d'affectation fait basculer les drapeaux de droite à gauche.
- Toute opération inconnue pour les ensembles de règles combine des indicateurs de tous les opérandes et l'ensemble final d'indicateurs est ajouté aux résultats de l'opération.
Enfin, vous devez définir les règles de fusion des informations aux points de jonction des arcs CFG. La fusion est déterminée par la règle d'union, c'est-à-dire que si différents ensembles d'indicateurs pour une seule variable provenaient de différents blocs de base, ils sont fusionnés lors de la fusion. Y compris les faux positifs viennent d'ici: l'algorithme ne garantit pas que le chemin vers le CFG sur lequel l'indicateur est apparu peut être exécuté.
Par exemple, vous devez détecter des vulnérabilités telles que l'injection SQL. Cette vulnérabilité se produit lorsque des données non vérifiées de l'utilisateur entrent dans les méthodes de travail avec la base de données. Il est nécessaire de déterminer que les données proviennent de l'utilisateur et d'ajouter l'indicateur de souillure à ces données. En règle générale, la base de règles de l'analyseur définit les règles de définition de l'indicateur de souillure. Par exemple, définissez un indicateur sur la valeur de retour de la méthode getParameter () de la classe Request.
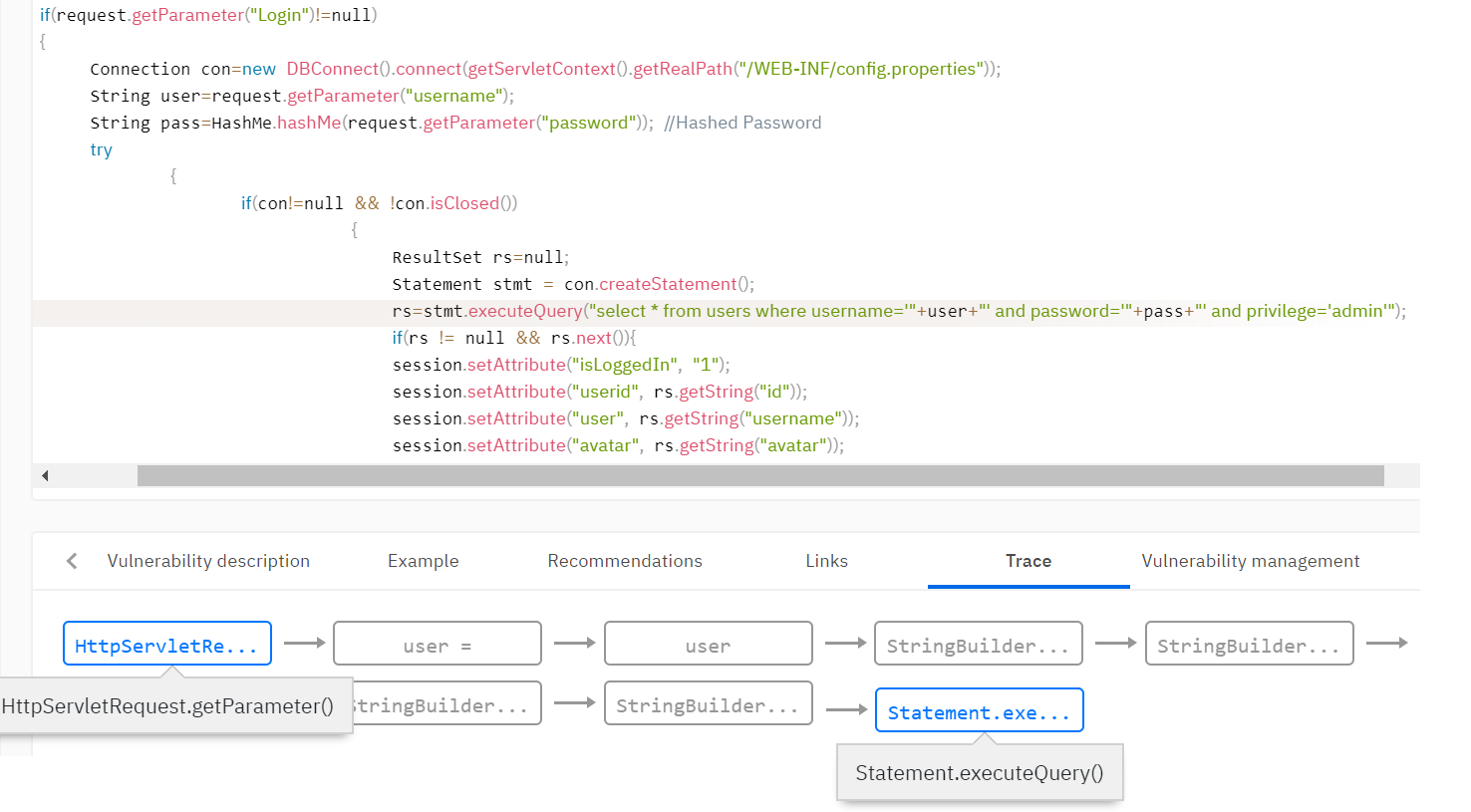
Ensuite, vous devez distribuer l'indicateur dans tout le programme analysé à l'aide de l'analyse des souillures, étant donné que les données peuvent être validées et l'indicateur peut disparaître sur l'un des chemins d'exécution. L'analyseur définit de nombreuses fonctions qui suppriment les indicateurs. Par exemple, la fonction de validation des données des balises html peut effacer l'indicateur des vulnérabilités de script intersite (XSS). Ou, la fonction pour lier une variable à une expression SQL supprime l'indicateur d'intégration dans SQL.
Règles de recherche de vulnérabilité
Du fait de l'application des algorithmes ci-dessus, la représentation intermédiaire est complétée par les informations nécessaires à la recherche de vulnérabilités. Par exemple, dans le modèle de code, des informations apparaissent sur les variables qui appartiennent à certains indicateurs, quelles données sont constantes. Les règles de recherche de vulnérabilité sont formulées en termes de modèle de code. Les règles décrivent les fonctionnalités de la vue intermédiaire finale qui peuvent indiquer une vulnérabilité.
Par exemple, vous pouvez appliquer une règle de recherche de vulnérabilité qui définit un appel de méthode avec un paramètre qui a l'indicateur taint. Revenant à l'exemple de l'injection SQL, nous vérifions que les variables avec le drapeau taint ne tombent pas dans la fonction de requête de base de données.
Il s'avère qu'une partie importante de l'analyseur statique, en plus de la qualité des algorithmes, est la configuration et la base de règles: une description des constructions dans le code génère des indicateurs ou d'autres informations, des constructions qui valident de telles données et pour quelles constructions l'utilisation de ces données est critique.
D'autres approches
En plus de l'analyse du flux de données, il existe d'autres approches. L'une des plus célèbres est l'exécution symbolique ou l'interprétation abstraite. Dans ces approches, le programme s'exécute sur des domaines abstraits, le calcul et la distribution des restrictions de données dans le programme. En utilisant cette approche, on peut non seulement trouver la vulnérabilité, mais aussi calculer les conditions sur les données d'entrée dans lesquelles la vulnérabilité est exploitable. Cependant, cette approche présente de sérieux inconvénients - avec des solutions standard sur des programmes réels, les algorithmes explosent de façon exponentielle et les optimisations entraînent de graves pertes de qualité de l'analyse.
Conclusions
En fin de compte, je pense qu'il vaut la peine de résumer, en parlant des avantages et des inconvénients de l'analyse statique. Il est logique de comparer avec l'analyse dynamique, dans laquelle la recherche de vulnérabilité se produit lors de l'exécution du programme.

L'avantage incontestable de l'analyse statique est la couverture complète du code analysé. De plus, les avantages de l'analyse statique incluent le fait que pour l'exécuter, il n'est pas nécessaire d'exécuter l'application dans un environnement de combat. L'analyse statique peut être mise en œuvre aux tout premiers stades de développement, minimisant ainsi le coût des vulnérabilités trouvées.
Les inconvénients de l'analyse statique sont la présence inévitable de faux positifs, la consommation de ressources et un long temps d'analyse sur de grandes quantités de code. Cependant, ces inconvénients sont inévitables, en fonction des spécificités des algorithmes. Comme nous l'avons vu, un analyseur rapide ne trouvera jamais une véritable vulnérabilité telle que l'injection SQL et similaires.
Nous avons écrit dans
un autre article sur les difficultés restantes de l'utilisation d'outils d'analyse statique, qui, en fin de compte, peuvent être assez bien surmontées.