Nous continuons l'histoire de la façon de reconnaître les plaques d'immatriculation pour ceux qui peuvent écrire l'application hello world en python! Dans cette partie, nous apprendrons à former des modèles qui recherchent une région d'un objet donné, et apprendrons également à écrire un réseau RNN simple qui supportera mieux la lecture des nombres que certains homologues commerciaux.
Dans cette partie, je vais vous dire comment former Nomeroff Net pour vos données, comment obtenir une reconnaissance de haute qualité, comment configurer la prise en charge du GPU et accélérer le tout d'un ordre de grandeur ...
Nous formons Mask RCNN pour trouver la zone avec le numéro
Bien sûr, vous pouvez trouver non seulement un numéro, mais tout autre objet que vous devez trouver. Par exemple, vous pouvez, par analogie, rechercher une carte de crédit et lire ses détails. En général, trouver le masque dans lequel l'objet est inscrit dans l'image s'appelle la tâche «Segmentation d'instance» (j'ai déjà écrit à ce sujet dans la première partie).
Nous allons maintenant découvrir comment former le réseau pour résoudre ce problème. En fait, il y a peu de programmation ici, tout se résume à un balisage de données monotone, fastidieux et uniforme. Oui, oui, après avoir marqué votre centaine, vous comprendrez ce que je veux dire :)
Ainsi, l'algorithme de préparation des données est le suivant:
- Nous prenons des images d'au moins 300 x 300, nous mettons tout dans un dossier
- Nous chargeons l'outil de balisage VGG Image Annotator (VIA) , vous pouvez le baliser directement en ligne , la sortie sera un répertoire avec une photo et le fichier json que vous avez créé avec le balisage. Il existe deux de ces dossiers, dans celui appelé train mettre la partie principale des exemples, dans la deuxième valeur environ 20-30% du nombre d'exemples du premier pack (Bien sûr, ces dossiers ne devraient pas avoir les mêmes photos). Vous pouvez voir un exemple de données balisées pour le projet Nomeroff Net . En quantité - plus c'est mieux. Certains experts recommandent 5 000 exemples, nous sommes paresseux, en tapant un peu plus de 1 000 car le résultat nous convenait très bien.

- Pour commencer la formation, vous devez télécharger le projet Nomeroff Net depuis Github, installer Mask RCNN avec toutes les dépendances et vous pouvez essayer d'exécuter le script de formation train / mrcnn.ipynb sur nos données
- Je vous préviens immédiatement, cela ne marche pas vite. Si vous n'avez pas de GPU, cela peut prendre des jours. Pour accélérer considérablement le processus d'apprentissage, il est conseillé d'installer tensorflow avec prise en charge GPU .
- Si la formation sur notre ensemble de données a réussi, vous pouvez désormais passer en toute sécurité à la vôtre.
Veuillez noter - nous ne formons pas tout à partir de zéro, nous formons le modèle formé sur les données de l' ensemble de données COCO , que Mask RCNN télécharge lors de la première exécution
- Vous pouvez entraîner non pas coco, mais notre modèle mask_rcnn_numberplate_0700.h5 , et spécifier le chemin vers ce modèle dans le paramètre de configuration WEIGHTS (par défaut, "WEIGHTS": "coco")
- Les paramètres qui peuvent être étendus sont: EPOCH, STEPS_PER_EPOCH
- Le résultat après chaque ère sera sauvegardé dans le dossier ./logs/numberplate<date de lancement> /
Pour tester le modèle formé en pratique, dans les
exemples de projet, remplacez
MASK_RCNN_MODEL_PATH par le chemin d'accès à votre modèle.
Améliorer le classificateur de plaque d'immatriculation selon vos besoins
Une fois les zones avec plaques d'immatriculation trouvées, vous devez essayer de déterminer quel état / type de numéro nous reconnaissons. Ici, l'universalisation va à l'encontre de la qualité de la reconnaissance. Par conséquent, idéalement, vous devez former un classificateur qui détermine non seulement le pays du numéro, mais également le type de conception de ce numéro (emplacement des caractères, options de symbole pour un type de numéro donné).
Dans notre projet, nous avons mis en œuvre un soutien pour reconnaître les numéros d'Ukraine, de la Fédération de Russie et des numéros européens en général. La qualité de reconnaissance des numéros européens est légèrement pire, car il existe des numéros avec des motifs différents et un nombre accru de caractères trouvés. Peut-être qu'au fil du temps, il y aura des modules de reconnaissance distincts pour "eu-ee", "eu-pl", "eu-nl", ...
Avant de classer une plaque d'immatriculation, vous devez la «découper» de l'image et la normaliser, en d'autres termes, supprimer toutes les distorsions au maximum et obtenir un rectangle net qui sera soumis à une analyse plus approfondie. Cette tâche s'est avérée assez banale, j'ai même dû rappeler les mathématiques de l'école et écrire une implémentation spécialisée de l'algorithme de clustering k-means :) :). Le module qui traite cela s'appelle RectDetector, c'est à quoi ressemblent les nombres normalisés, que nous classerons et reconnaîtrons davantage.

Pour automatiser en quelque sorte le processus de création d'un ensemble de données pour classer les nombres, nous avons développé un
petit panneau d'administration sur nodejs . En utilisant ce panneau d'administration, vous pouvez marquer l'inscription sur la plaque d'immatriculation et la classe à laquelle elle appartient.
Il peut y avoir plusieurs classificateurs. Dans notre cas, par type de numéro et par s'il est esquissé / peint sur la photo.
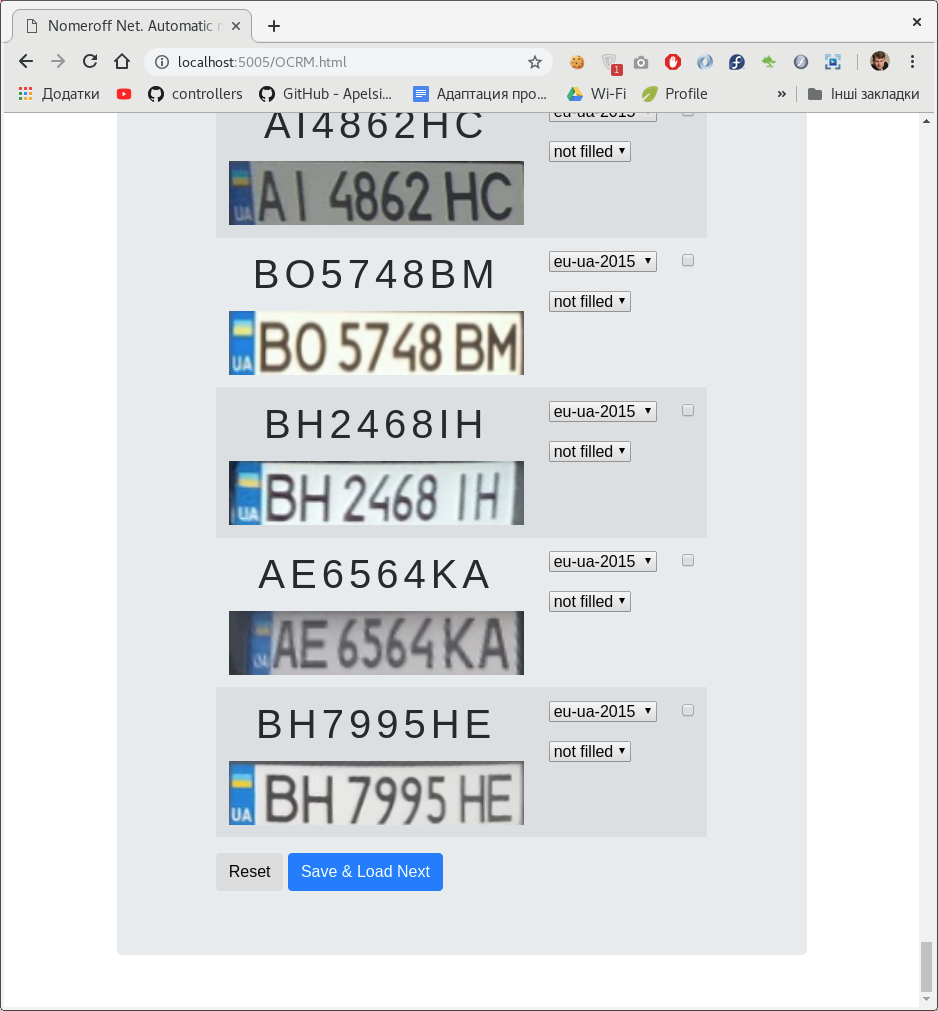
Après avoir marqué l'ensemble de données, nous le divisons en échantillons de formation, de validation et de test. À titre d'exemple, téléchargez notre
jeu de
données autoriaNumberplateOptions3Dataset-2019-05-20.zip pour voir comment tout
fonctionne là-bas.
Étant donné que la sélection a déjà été marquée (modérée), vous devez remplacer «isModerated»: 1 par «isModerated»: 0 dans des fichiers json aléatoires, puis démarrez le panneau d'administration .
Nous formons le classificateur:
Le script de formation
train / options.ipynb vous aidera à obtenir votre version du modèle. Notre exemple montre que pour la classification des régions / types de plaques d'immatriculation, nous avons obtenu une précision de
98,8% , pour la classification de "Le numéro est-il peint?"
99,4% sur notre jeu de données. D'accord, ça s'est bien passé.
Former votre OCR (reconnaissance de texte)
Eh bien, nous avons trouvé la zone avec le numéro et l'avons normalisée dans un rectangle qui contient l'inscription avec le numéro. Comment lisons-nous le texte? Le moyen le plus simple consiste à l'exécuter via FineReader ou Tesseract. La qualité sera «pas très», mais avec une bonne résolution de la zone avec le nombre, vous pouvez obtenir une précision de 80%. En fait, ce n'est pas une mauvaise précision, mais si je vous dis que vous pouvez obtenir
97% et en même temps dépenser beaucoup moins de ressources informatiques? Sonne bien - essayons. Une architecture légèrement inhabituelle convient à ces fins, dans laquelle des couches convolutives et récurrentes sont utilisées. L'architecture de ce réseau ressemble à ceci:
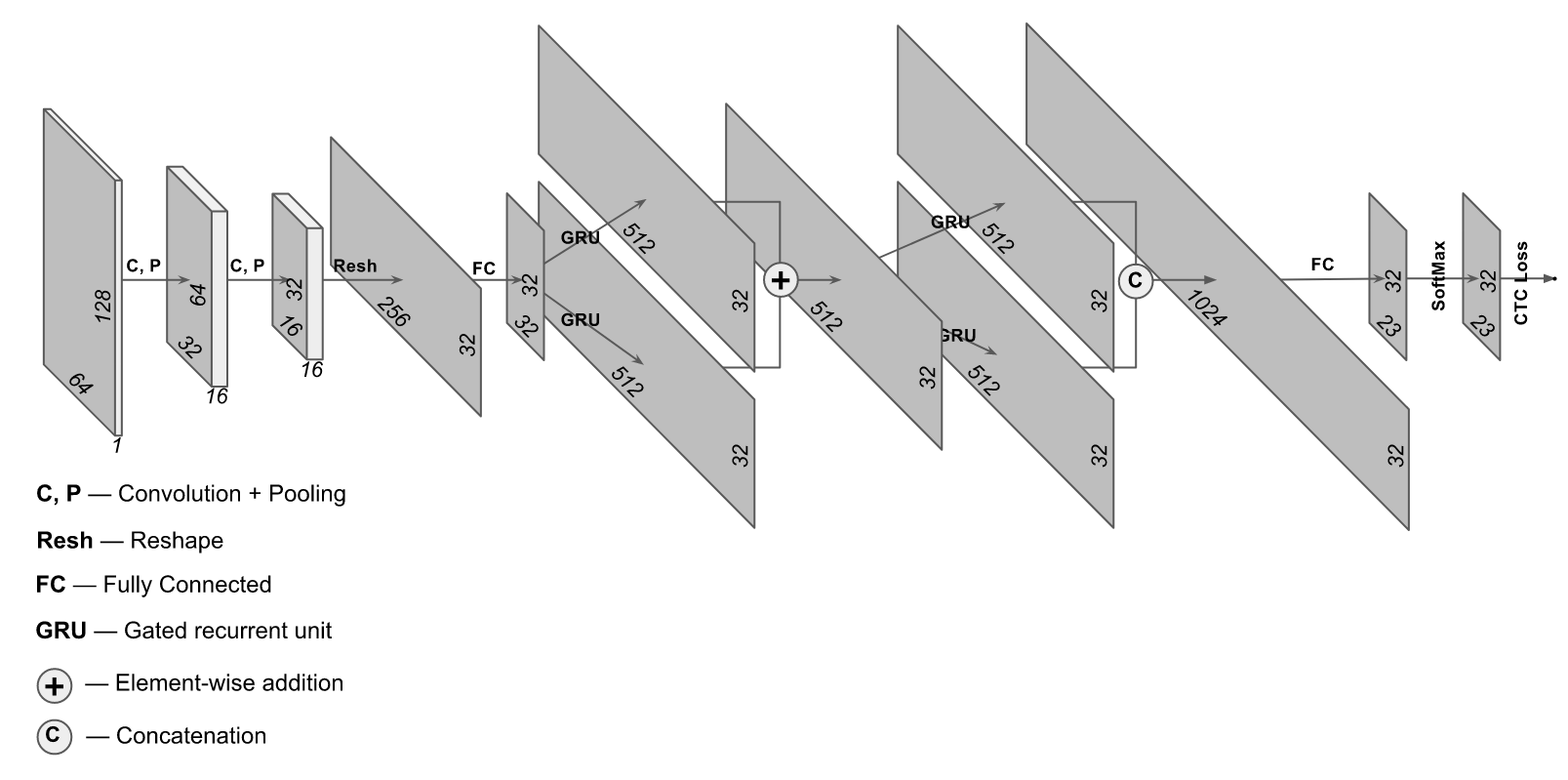
L'implémentation a été prise sur le site
https://supervise.ly/ , nous l'avons légèrement modifiée pour la formation sur de vraies photos (le site web supervised a une option pour un échantillonnage synthétique)
Maintenant, la partie amusante commence, marquez au moins 5 000 numéros :). Nous avons délimité environ
~ 100 000 ukrainiens ,
~ 50 000 ukrainiens avec le "vieux" design ,
~ 6 500 européens ,
~ 10 000 RF . Ce fut la partie la plus difficile du développement. Vous ne pouvez même pas imaginer combien de fois je me suis endormi sur une chaise d'ordinateur en train de modérer plusieurs heures par jour pour la prochaine portion de chiffres. Mais le vrai héros du balisage est
dimabendera - il a marqué 2/3 de tout le contenu, (donnez-lui un plus si vous comprenez à quel point c'était ennuyeux de faire tout ce travail :))
Vous pouvez essayer d'automatiser ce processus d'une manière ou d'une autre, par exemple, après avoir reconnu chaque image avec Tesseract, puis corriger les erreurs à l'aide de
notre panneau d'administration .
Veuillez noter: le même panneau d'administration est utilisé pour marquer le classificateur et l'OCR sur le numéro. Vous pouvez charger les mêmes données ici et là, à l'exception des nombres esquissés, bien sûr.
Si vous marquez au moins 5000 numéros et pouvez former votre OCR - n'hésitez pas à organiser un prix pour vous-même avec vos supérieurs, je suis sûr que ce test n'est pas pour les mauviettes!
Commencer la formation
Le
script train / ocr-ru.ipynb forme le modèle pour les nombres russes, il existe des exemples pour l'
Ukraine et l'
Europe .
Veuillez noter que dans les paramètres d'entraînement, il n'y a qu'une seule ère (un passage).
Une caractéristique de la formation d'un tel ensemble de données sera un résultat très différent pour chaque tentative, avant chaque session de formation, les données sont mélangées dans un ordre aléatoire, parfois elles sont plus efficaces pour la formation, parfois pas très. Je vous recommande d'essayer au moins 5 fois, tout en contrôlant la précision des données de test. Avec différentes tentatives de lancement, notre précision pourrait «sauter» de
87% à 97% .
Quelques recommandations :
- Pas besoin de tout initialiser d'une nouvelle manière, redémarrez simplement la ligne model = ocrTextDetector.train (mode = MODE) jusqu'à ce que nous obtenions le résultat attendu
- L'une des raisons d'une mauvaise précision est l'insuffisance des données. Si vous ne l'aimez pas, nous le marquons encore et encore, à un moment donné la qualité cesse de croître, pour chaque ensemble de données il est différent, vous pouvez vous concentrer sur le nombre de 10 000 exemples étiquetés
- La formation sera plus rapide si le pilote NVIDIA CuDNN est installé, modifiez la valeur MODE = "gpu" dans le script de formation et CuDNNGRU sera connecté à la place de la couche GRU, ce qui entraînera une accélération triple.
Un peu sur la configuration de tensorflow pour les GPU NVIDIA
Si vous êtes un heureux propriétaire d'un GPU de NVIDIA, vous pouvez parfois accélérer les choses: à la fois la formation des modèles et les nombres d'inférence (mode de reconnaissance). Le problème est d'installer et de compiler tout correctement.
Nous utilisons Fedora Linux sur nos serveurs ML (cela s'est produit historiquement).
La séquence approximative d'actions pour ceux qui utilisent ce système d'exploitation est la suivante:
- Nous mettons le pilote GPU pour votre version de système d'exploitation, ici pour Fedora
- Nous connectons le référentiel NVIDIA et installons le package CUDA à partir de là, ici pour CentOS / Fedora
- Nous mettons le bazel, et nous collectons le tensorflow des sources sur ce quai
- Il est également conseillé d'installer l'ancienne version du compilateur gcc, appelée cuda-gcc, tout allait bien pour moi sur cuda-gcc 6.4. Lors de la configuration de l'assembly, spécifiez le chemin d'accès à cuda-gcc
Si vous ne pouvez pas créer tensorflow avec le support gpu, vous pouvez tout démarrer via docker, et en plus de docker, vous devez installer le package nvidia-docker2. À l'intérieur du conteneur Docker, vous pouvez exécuter le bloc-notes jupyter, puis tout y exécuter.
jupyter notebook --ip=0.0.0.0 --port=8888 --allow-root
Liens utiles
Je tiens également à remercier les 2expres,
habilleurs de glassofkvass pour avoir fourni les photos avec des chiffres et
dimabendera pour avoir écrit la plupart du code et balisé la plupart des données du projet Nomeroff Net.
UPD1: Puisque I et Dmitri sont envoyés aux questions standard de PM sur la reconnaissance des nombres, une combinaison de tensorflow avec gpu, etc. et Dmitry et je donne les mêmes réponses, je veux en quelque sorte optimiser ce processus.
Nous suggérons de structurer la correspondance dans les commentaires, divisée par sujet. Il existe des fonctionnalités pratiques sur GitHub pour cela. À l'avenir, veuillez ne pas poser de questions dans les commentaires, mais dans le
numéro thématique sur github Nomeroff NetUPD2: Au fil du temps, des ensembles de données sont également apparus:
nombres kazakhs, nombres géorgiens