Vous est-il arrivé de vous en tenir à une sorte de jeu simple, en pensant que l'intelligence artificielle pouvait tout à fait y faire face? J'avais l'habitude de le faire et j'ai décidé d'essayer de créer un tel joueur de bot. De plus, il existe désormais de nombreux outils de vision par ordinateur et d'apprentissage automatique qui vous permettent de créer des modèles sans une compréhension approfondie des détails de mise en œuvre. Les mortels ordinaires peuvent faire un prototype sans construire de réseaux de neurones pendant des mois.

Sous la coupe, vous trouverez le processus de création d'un bot de preuve de concept pour le jeu Clash Royale, dans lequel j'ai utilisé des bibliothèques Scala, Python et CV. En utilisant la vision par ordinateur et l'apprentissage automatique, j'ai essayé de créer un bot pour un jeu qui interagit comme un joueur en direct.
Je m'appelle Sergey Tolmachev, je suis développeur principal Scala sur la plate-forme Waves et enseigne
un cours Scala dans le quartier binaire, et pendant mon temps libre, j'étudie d'autres technologies, telles que l'IA. Et je voulais renforcer les compétences acquises avec une certaine expérience pratique. Contrairement aux compétitions d'IA, où votre bot joue contre les bots d'autres utilisateurs, Clash Royale peut jouer contre des gens, ce qui semble drôle. Votre bot peut apprendre à battre de vrais joueurs!
Mécanique du jeu dans Clash Royale
La mécanique du jeu est assez simple. Vous et votre adversaire avez trois bâtiments: une forteresse et deux tours. Les joueurs avant le jeu collectent des decks - 8 unités disponibles, qui sont ensuite utilisées au combat. Ils ont différents niveaux et peuvent être pompés, collectant plus de cartes de ces unités et achetant des mises à jour.
Après le début du jeu, vous pouvez placer les unités disponibles à une distance de sécurité des tours ennemies, tout en dépensant des unités de mana, qui sont lentement restaurées pendant le jeu. Les unités sont envoyées dans les bâtiments ennemis et distraites par les ennemis rencontrés en cours de route. Le joueur ne peut contrôler que la position initiale des unités - il ne peut affecter leur mouvement et leurs dégâts ultérieurs qu'en réglant d'autres unités.
Il y a encore des sorts qui peuvent être joués n'importe où sur le terrain, ils causent généralement des dégâts aux unités de différentes manières. Les sorts peuvent cloner, geler ou accélérer des unités dans une zone.
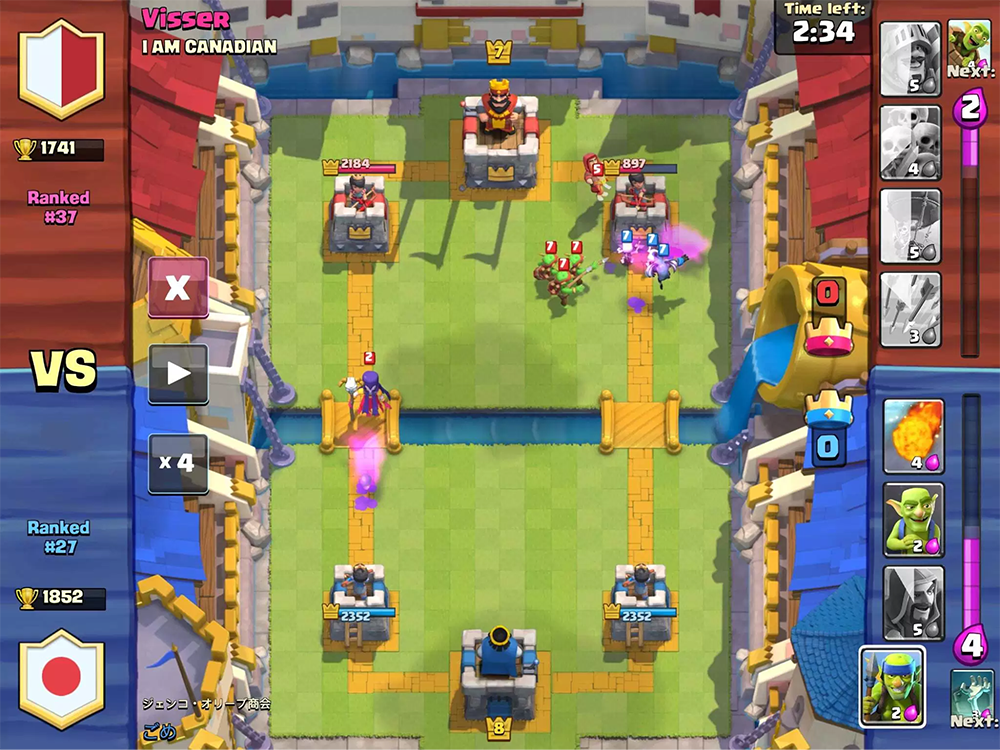
Le but du jeu est de détruire les bâtiments ennemis. Pour une victoire complète, vous devez détruire la forteresse ou après deux minutes de jeu détruire plus de bâtiments (les règles dépendent des modes de jeu, mais en général elles sonnent comme ça).
Pendant le jeu, vous devez prendre en compte le mouvement des unités, le nombre possible de mana et les cartes ennemies actuelles. Vous devez également considérer comment l'installation de l'unité affecte le terrain de jeu.
Construire une solution
Clash Royale est un jeu mobile, j'ai donc décidé de l'exécuter sur Android et d'interagir avec lui via ADB. Cela prendrait en charge le travail avec le simulateur ou avec un véritable appareil.
J'ai décidé que le bot, comme beaucoup d'autres IA de jeu, devrait travailler sur l'algorithme Perception-Analysis-Action. L'environnement entier du jeu est affiché à l'écran et l'interaction avec celui-ci se produit en cliquant sur l'écran. Par conséquent, le bot doit être un programme dont l'entrée décrit l'état actuel du jeu: l'emplacement et les caractéristiques des unités et des bâtiments, les cartes possibles actuelles et la quantité de mana. À la sortie, le bot doit donner un tableau de coordonnées où l'unité doit être enregistrée.
Mais avant de créer le bot lui-même, il était nécessaire de résoudre le problème d'extraction d'informations sur l'état actuel du jeu à partir de la capture d'écran. Dans l'ensemble, le contenu supplémentaire de l'article est consacré à cette tâche.
Pour résoudre ce problème, j'ai décidé d'utiliser la vision par ordinateur. Ce n'est peut-être pas la meilleure solution: un CV sans beaucoup d'expérience et de ressources a clairement des limites et ne peut pas tout reconnaître au niveau humain.
Il serait plus précis de prendre des données de la mémoire, mais je n'avais pas une telle expérience. La racine est requise et dans l'ensemble, cette solution semble plus compliquée. Il est également difficile de savoir si la vitesse en temps réel peut être atteinte ici si vous recherchez des objets avec une pile JVM à l'intérieur du périphérique. De plus, je voulais résoudre le problème du CV plus que cela.
En théorie, on pourrait créer un serveur proxy et en tirer des informations. Mais le protocole réseau du jeu change souvent, des proxys sur Internet se rencontrent, mais deviennent rapidement obsolètes et ne sont pas pris en charge.
Ressources de jeu disponibles
Pour commencer, j'ai décidé de me familiariser avec les matériaux disponibles du jeu. J'ai trouvé un
club d'artisans qui sortait des ressources de jeu emballées
[1] [2] . Tout d'abord, je me suis intéressé aux images d'unités, mais dans le jeu non emballé, elles sont présentées sous la forme d'une carte de tuiles (pièces dont une unité est constituée).
J'ai également trouvé des scripts collés (mais pas parfaits) de cadres d'animation d'unité - ils étaient utiles pour former le modèle de reconnaissance.

De plus, dans les ressources, vous pouvez trouver des csv avec diverses données de jeu - la quantité de HP, les dommages aux unités de différents niveaux, etc. Ceci est utile lors de la création de la logique du bot. Par exemple, à partir des données, il est devenu clair que le champ était divisé en 18 x 29 cellules et que des unités ne pouvaient être placées que sur elles. Il y avait aussi toutes les images des cartes des unités, qui nous seront utiles plus tard.
Vision par ordinateur pour les paresseux
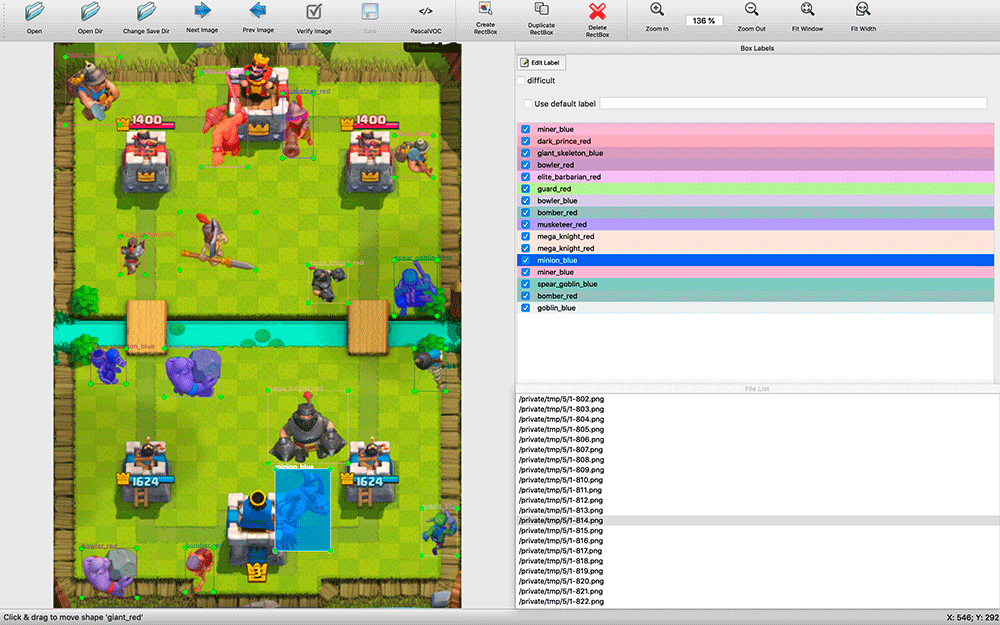
Après avoir recherché les solutions de CV disponibles, il est devenu clair que dans tous les cas, ils devraient être formés sur un ensemble de données étiqueté. J'ai pris des captures d'écran et j'étais déjà prêt à marquer un certain nombre de captures d'écran avec mes mains. Cela s'est avéré être une tâche intimidante.
Trouver les programmes de reconnaissance disponibles a pris du temps. Je me suis installé sur
labelImg . Toutes les applications d'annotation que j'ai trouvées étaient assez primitives: beaucoup ne prenaient pas en charge les raccourcis clavier, la sélection des objets et de leurs types était rendue beaucoup moins pratique que dans labelImg.
Lors du balisage, il s'est avéré utile d'avoir le code source de l'application. J'ai pris des captures d'écran toutes les deux secondes du match. Il y a beaucoup d'objets dans les captures d'écran (par exemple, une armée de squelettes), et j'ai fait une modification dans labelImg - par défaut, lors du marquage de l'image suivante, les étiquettes de la précédente ont été prises. Souvent, ils devaient simplement être déplacés vers une nouvelle position des unités, retirer les unités mortes et en ajouter quelques-unes apparues, et ne pas marquer à partir de zéro.

Le processus s'est avéré être gourmand en ressources - en deux jours en mode silencieux, j'ai posté environ 200 captures d'écran. L'échantillon semble très petit, mais j'ai décidé de commencer à expérimenter. Vous pouvez toujours ajouter plus d'exemples et améliorer la qualité du modèle.
Au moment du balisage, je ne savais pas quel outil de formation j'utiliserais, j'ai donc décidé d'enregistrer les résultats du balisage au format COV - l'un des plus conservateurs et apparemment universel.
La question peut se poser: pourquoi ne pas simplement rechercher des images pixel par pixel des unités par pure coïncidence? Le problème est que pour cela, il faudrait rechercher un grand nombre d'images d'animation différentes d'unités différentes. Cela ne marcherait guère. Je voulais créer une solution universelle prenant en charge différentes autorisations. De plus, les unités peuvent avoir une couleur différente en fonction de l'effet qui leur est appliqué - gel, accélération.
Pourquoi ai-je choisi YOLO
J'ai commencé à explorer des solutions possibles de reconnaissance d'image. J'ai regardé l'application de différents algorithmes: OpenCV, TensorFlow, Torch. Je voulais rendre la reconnaissance aussi rapide que possible, même en sacrifiant la précision, et obtenir le POC dès que possible.
Après avoir lu les
articles , j'ai réalisé que ma tâche ne correspond pas aux classificateurs HOG / LBP / SVM / HAAR / .... Bien qu'ils soient rapides, ils devraient être appliqués plusieurs fois - selon le classificateur de chaque unité - puis un par un pour les appliquer à l'image à rechercher. De plus, leur principe de fonctionnement en théorie donnerait de mauvais résultats: les unités peuvent avoir une forme différente, par exemple, en se déplaçant vers la gauche et vers le haut.
Théoriquement, en utilisant un réseau neuronal, vous pouvez l'appliquer une fois à une image et obtenir toutes les unités de types différents avec leur position, alors j'ai commencé à creuser vers les réseaux neuronaux. TensorFlow a trouvé un support pour les réseaux de neurones convolutifs (CNN). Il s'est avéré qu'il n'est pas nécessaire de former les réseaux de neurones à partir de zéro - vous pouvez
recycler le puissant réseau existant .
Ensuite, j'ai trouvé un algorithme YOLO plus pratique qui promet moins de complexité et, par conséquent, a dû fournir un algorithme de recherche à haute vitesse sans sacrifier beaucoup de précision (et dans certains cas, surpasser les autres modèles).
Le site Web YOLO promet une énorme différence de vitesse en utilisant le petit modèle et un réseau optimisé plus petit. YOLO vous permet également de recycler le réseau de neurones fini pour votre tâche, et
darknet - un
framework open source pour utiliser divers neurones dont les créateurs ont développé YOLO - est une simple application C native, et tout le travail se fait via ses appels de paramètres.
TensorFlow, écrit en Python, est en fait une bibliothèque Python et est utilisé à l'aide de scripts auto-écrits dont vous avez besoin pour les comprendre ou les affiner en fonction de vos besoins. Pour certains, la flexibilité de TensorFlow est probablement un plus, mais sans entrer dans les détails, il n'est guère possible de le prendre rapidement et de l'utiliser. Par conséquent, dans mon projet, le choix s'est porté sur YOLO.
Construction de modèles
Pour travailler sur la formation des modèles, j'ai installé Ubuntu 18.10, livré des packages d'assemblage, le package OpenCL de NVIDIA et d'autres dépendances, et construit darknet.
Github a une
section avec des étapes simples pour recycler le modèle YOLO : vous devez télécharger le modèle et les configurations, les changer et commencer à recycler.
Je voulais d'abord essayer de recycler un modèle YOLO simple, puis Tiny et les comparer. Cependant, il s'est avéré que pour la formation de modèles simples, vous avez besoin de 4 Go de mémoire de carte vidéo et je n'avais qu'une carte graphique NVIDIA GeForce GTX 1060 de 3 Go achetée pour les jeux. Par conséquent, j'ai pu immédiatement former uniquement le modèle Tiny.
Le balisage des unités sur les images que j'avais était au format VOC, et YOLO a travaillé avec son propre format, j'ai donc utilisé l'utilitaire
convert2Yolo pour convertir les fichiers d'annotation.
Après une nuit d'entraînement sur mes 200 captures d'écran, j'ai obtenu les premiers résultats, et ils m'ont surpris - le modèle a vraiment pu reconnaître quelque chose correctement! J'ai réalisé que j'allais dans la bonne direction et j'ai décidé de faire plus d'exemples d'enseignement.

Je ne voulais pas continuer à disposer de captures d'écran, et je me souvenais des images des animations d'unité. J'ai marqué toutes les petites images avec leurs classes et j'ai essayé de former le réseau sur cet ensemble. Le résultat a été très mauvais. Je suppose que le modèle n'a pas pu sélectionner les bons motifs à partir de petites images pour les utiliser dans de grandes images.
Après cela, j'ai décidé de les placer sur des arrière-plans prêts à l'emploi des arènes de combat et de créer par programme un fichier de marquage VOC. Il s'est avéré une telle capture d'écran synthétique avec une mise en page 100% précise et automatique.
J'ai écrit un script dans Scala qui divise la capture d'écran en 16 carrés 4x4 et définit les unités en leur centre afin qu'elles ne se croisent pas. Le script m'a également permis de personnaliser la création d'exemples de formation - lors de la prise de dégâts, les unités sont peintes dans la couleur de leur équipe (rouge / bleu), et lors de la classification, je reconnais séparément les unités de différentes couleurs. En plus de la coloration, les unités de différentes équipes qui ont subi des dommages présentent de légères différences de vêtements. De plus, j'ai augmenté et diminué un peu les unités au hasard, de sorte que le modèle a appris à ne pas dépendre beaucoup de la taille de l'unité. En conséquence, j'ai appris à créer des dizaines de milliers d'exemples de formation qui sont approximativement similaires à de vraies captures d'écran.
La génération n'était pas parfaite. Souvent, les unités étaient placées au-dessus des bâtiments, bien que dans le jeu elles soient derrière elles; il n'y avait aucun exemple de parties qui se chevauchent de l'unité, bien que ce ne soit pas une situation rare dans le jeu. Mais jusqu'à présent, j'ai décidé de le négliger.

Le modèle obtenu après plusieurs nuits de formation sur un mélange de 200 captures d'écran réelles et 5000 images générées qui ont été recréées au cours du processus de formation une fois par jour, lorsqu'il a été testé sur ces captures d'écran, a donné de mauvais résultats. Ce n'est pas surprenant, car les images générées ont beaucoup de différences avec les vraies.
Par conséquent, j'ai mis le modèle résultant à recycler sur un échantillon moyen, dans lequel il n'y avait que 200 de mes captures d'écran. Après cela, elle a commencé à travailler beaucoup mieux.
Quelle honteJe m'excuse d'avoir traité de telles mesures non scientifiques comme «beaucoup mieux», mais je ne sais pas comment valider rapidement les images, j'ai donc essayé plusieurs captures d'écran à partir d'un ensemble non destiné à la formation et j'ai cherché à voir si les résultats me satisfaisaient. C’est la chose la plus importante. Nous sommes paresseux et nous faisons un prototype, non?
Les étapes suivantes pour améliorer le modèle étaient compréhensibles - marquez avec vos mains plus de ces captures d'écran et entraînez-les sur le modèle, formé sur les captures d'écran générées.
Descendons au bot
J'ai décidé d'écrire un bot en Python - il a de nombreux outils disponibles pour ML. J'ai décidé d'utiliser mon modèle avec OpenCV, qui à partir de
3.5 a appris à utiliser des modèles de réseaux neuronaux , et j'ai même trouvé un
exemple simple . Après avoir essayé plusieurs bibliothèques pour travailler avec ADB, j'ai choisi
pure-python-adb - tout ce dont j'ai besoin y est simplement implémenté: la fonction de capture d'écran et l'opération sur le périphérique shell; Je tape en utilisant le «tap d'entrée».
Donc, après avoir reçu une capture d'écran du jeu, en reconnaissant les unités et en le poussant sur l'écran, j'ai continué à travailler sur la reconnaissance de l'état du jeu. En plus des unités, je devais reconnaître le niveau de mana actuel et les cartes disponibles pour le joueur.
Le niveau de mana dans le jeu est affiché sous forme de barre de progression et de chiffres. Sans réfléchir à deux fois, j'ai commencé à découper le nombre, à inverser et à reconnaître en utilisant
pytesseract .
Pour déterminer les cartes disponibles et leur position, j'ai utilisé le
détecteur de points KAZE d'OpenCV . Jusqu'à présent, je ne voulais pas recommencer à apprendre le réseau neuronal, et j'ai choisi une méthode plus rapide et plus facile, bien qu'au final, elle se soit avérée avoir la précision minimale suffisante dans le cas où vous devez rechercher de nombreux objets.
Lors du démarrage du bot, j'ai compté les points clés pour toutes les images de la carte (il y en a plusieurs dizaines au total), et pendant le jeu, j'ai cherché des correspondances de toutes les cartes avec la zone de carte du joueur pour réduire le nombre d'erreurs et augmenter la vitesse. Ils ont été triés par précision et par la coordonnée
x pour obtenir l'ordre des cartes - des informations sur leur localisation à l'écran.
Ayant un peu joué avec les paramètres, en pratique j'ai eu beaucoup d'erreurs, bien que certaines images complexes de cartes, qui ont parfois été confondues avec d'autres par l'algorithme, aient été reconnues avec une grande précision. J'ai dû ajouter un tampon de trois éléments: si trois reconnaissances consécutives nous obtenons les mêmes valeurs, alors nous croyons conditionnellement que nous pouvons leur faire confiance.

Après avoir reçu toutes les informations nécessaires (unités et leur position approximative, mana et cartes disponibles), vous pouvez prendre certaines décisions.
Pour commencer, j'ai décidé de prendre quelque chose de simple: par exemple, s'il y a suffisamment de mana sur une carte accessible, jouez-la sur le terrain. Mais le bot ne sait toujours pas comment "jouer" les cartes - il sait quelles cartes nous avons, où est le champ, vous devez cliquer sur la carte souhaitée, puis sur la cellule souhaitée dans le champ.
Connaissant la résolution de la capture d'écran, vous pouvez comprendre les coordonnées de la carte et la cellule de champ souhaitée. Maintenant, je suis lié à la résolution d'écran exacte, mais si nécessaire, je peux ignorer cela. La fonction de décision renverra un tableau de prises qui doivent être effectuées dans un proche avenir. En général, notre bot sera une boucle infinie (simplifiée):
: = : ( ) : = () = () = () += (, , , )
Jusqu'à présent, le bot ne peut mettre des unités qu'à un moment donné, mais dispose déjà de suffisamment d'informations pour construire une stratégie plus complexe.
Premiers problèmes
En réalité, j'ai rencontré un problème inattendu et très désagréable. La création d'une capture d'écran via ADB prend environ 100 ms, ce qui introduit un retard important - je m'attendais à un tel retard maximum, en tenant compte de tous les calculs et du choix d'action, mais pas à une étape de la création d'une capture d'écran. Une solution simple et rapide n'a pas pu être trouvée. En théorie, en utilisant l'émulateur Android, vous pouvez prendre des captures d'écran directement depuis la fenêtre de l'application, ou vous pouvez créer un utilitaire pour diffuser des images à partir d'un téléphone avec compression via UDP et y connecter le bot, mais je n'ai pas non plus trouvé de solutions rapides ici.
Alors
Ayant évalué sobrement l'état de mon projet, j'ai décidé de m'attarder sur ce modèle pour l'instant. J'ai passé plusieurs semaines de mon temps libre à le faire, et la reconnaissance des unités n'est qu'une partie du gameplay.
J'ai décidé de développer progressivement les parties du bot - pour faire la logique de base de la perception, puis la logique simple du jeu et l'interaction avec le jeu, et ensuite il sera possible d'améliorer les parties individuelles du bot. Lorsque le niveau du modèle de reconnaissance d'unité devient suffisant, l'ajout d'informations sur HP et le niveau d'unités peut amener le développement du bot de jeu à une toute nouvelle étape. Ce sera peut-être le prochain objectif, mais pour l'instant, cela ne vaut vraiment pas la peine de se concentrer sur cette tâche.
Dépôt de projets GithubJ'ai passé beaucoup de temps sur le projet et, franchement, j'en ai marre, mais je ne le regrette pas un peu - j'ai acquis une nouvelle expérience en ML / CV.
Peut-être que je reviendrai vers lui plus tard - je serai heureux si quelqu'un me rejoint. Si vous êtes intéressé, rejoignez le groupe sur
Telegram , et venez également à mon
cours Scala .