Cet article est une transcription du reportage vidéo d'Alexei Vakhov de Uchi.ru «Nuages dans les nuages»
Uchi.ru est une plateforme en ligne pour l'enseignement scolaire, plus de 2 millions d'élèves, des classes interactives décident régulièrement avec nous. Tous nos projets sont hébergés entièrement dans des clouds publics, 100% des applications fonctionnent dans des conteneurs, à partir du plus petit, pour un usage interne, et se terminant par de grandes productions à 1k + requêtes par seconde. Il se trouve que nous avons 15 clusters de dockers isolés (pas Kubernetes, sic!) Dans cinq fournisseurs de cloud. 1500 applications utilisateur, dont le nombre ne cesse de croître.
Je vais parler de choses très spécifiques: comment nous sommes passés aux conteneurs, comment nous gérons l'infrastructure, les problèmes que nous avons rencontrés, ce qui a fonctionné et ce qui n'a pas fonctionné.
Au cours du rapport, nous discuterons:
- Motivation pour la sélection de technologies et les fonctionnalités commerciales
- Outils: Ansible, Terraform, Docker, Github Flow, Consul, Nomad, Prometheus, Shaman - une interface Web pour Nomad.
- Utilisation de la fédération de clusters pour gérer l'infrastructure distribuée
- Déploiements NoOps, environnements de test, circuits d'application (les développeurs apportent leurs propres modifications pratiquement par eux-mêmes)
- Histoires divertissantes de la pratique
Peu importe, s'il vous plaît, sous le chat.
Je m'appelle Alexey Vakhov. Je travaille en tant que directeur technique chez Uchi.ru. Nous hébergeons dans des clouds publics. Nous utilisons activement Terraform, Ansible. Depuis lors, nous sommes complètement passés à Docker. Très satisfait. Comme nous sommes heureux, comme nous sommes heureux - je le dirai.

La société Uchi.ru est engagée dans la production de produits pour l'enseignement scolaire. Nous avons une plate-forme principale sur laquelle les enfants résolvent des problèmes interactifs dans divers sujets en Russie, au Brésil et aux États-Unis. Nous organisons des olympiades en ligne, des concours, des clubs, des camps. Chaque année, cette activité se développe.

D'un point de vue technique, la pile web classique (Ruby, Python, NodeJS, Nginx, Redis, ELK, PostgreSQL). La principale caractéristique est que de nombreuses applications. Les applications sont hébergées dans le monde entier. Chaque jour, il y a des déploiements en production.
La deuxième caractéristique est que nos régimes changent très souvent. Ils demandent de lancer une nouvelle application, d'arrêter l'ancienne, d'ajouter cron pour les jobs d'arrière-plan. Toutes les 2 semaines, il y a de nouveaux Jeux Olympiques - c'est une nouvelle application. Tout est nécessaire pour accompagner, surveiller, sauvegarder. Par conséquent, l'environnement est superdynamique. Le dynamisme est notre principale difficulté.
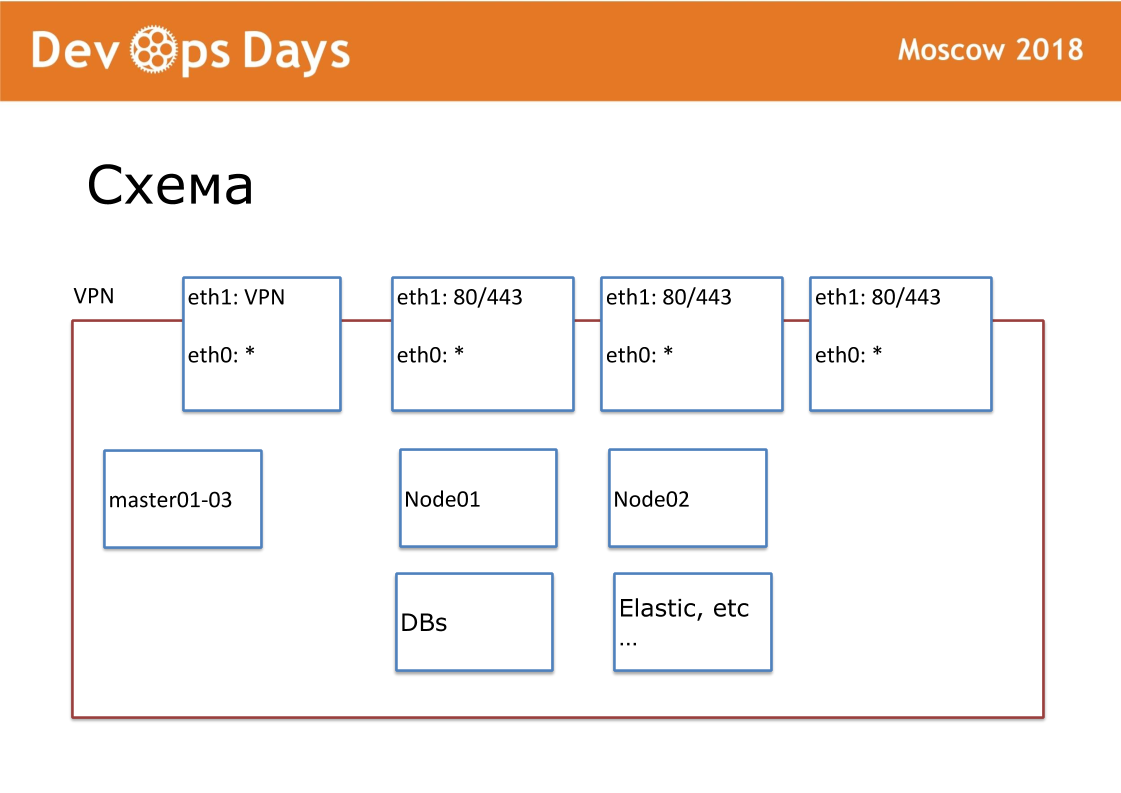
Notre unité de travail est le site. En termes de fournisseurs de cloud, c'est Project. Notre site est une entité complètement isolée avec une API et un sous-réseau privé. Lorsque nous entrons dans le pays, nous recherchons des fournisseurs de cloud locaux. Pas partout, il y a Google et Amazon. Il arrive parfois qu'il n'y ait pas d'API pour le fournisseur de cloud. Extérieurement, nous publions VPN et HTTP, HTTPS aux équilibreurs. Tous les autres services communiquent à l'intérieur du cloud.

Pour chaque site, nous avons créé notre propre référentiel Ansible. Le référentiel contient hosts.yml, playbook, rôles et 3 dossiers secrets, dont je parlerai plus tard. C'est terraform, provision, routage. Nous sommes fans de standardisation. Notre référentiel doit toujours être appelé le "nom ansible du site". Nous normalisons chaque nom de fichier, structure interne. Ceci est très important pour une automatisation plus poussée.

Nous avons créé Terraform il y a un an et demi, nous l'utilisons donc. Terraform sans modules, sans structure de fichiers (une structure plate est utilisée). Structure du fichier Terraform: 1 serveur - 1 fichier, paramètres réseau et autres paramètres. À l'aide de terraform, nous décrivons des serveurs, des lecteurs, des domaines, des compartiments s3, des réseaux, etc. Terraform prépare sur place le fer à repasser.

Terraform crée le serveur, puis l'ensemble roule ces serveurs. Du fait que nous utilisons partout la même version du système d'exploitation, nous avons écrit tous les rôles à partir de zéro. Les rôles possibles sont généralement publiés sur Internet pour tous les systèmes d'exploitation qui ne fonctionnent nulle part. Nous avons tous pris des rôles Ansible et n'avons laissé que ce dont nous avions besoin. Rôles Ansible standardisés. Nous avons 6 playbooks de base. Une fois lancé, Ansible installe une liste standard de logiciels: OpenVPN, PostgreSQL, Nginx, Docker. Kubernetes que nous n'utilisons pas.

Nous utilisons Consul + Nomad. Ce sont des programmes très simples. Exécutez 2 programmes écrits en Golang sur chaque serveur. Le consul est responsable de la découverte du service, de la vérification de l'intégrité et de la valeur-clé pour le stockage de la configuration. Nomad est responsable de la planification, du déploiement. Nomad lance des conteneurs, fournit des déploiements, y compris une mise à jour continue sur le bilan de santé, vous permet d'exécuter des sidecar-containers. Le cluster est facile à étendre ou vice versa à réduire. Nomad prend en charge le cron distribué.
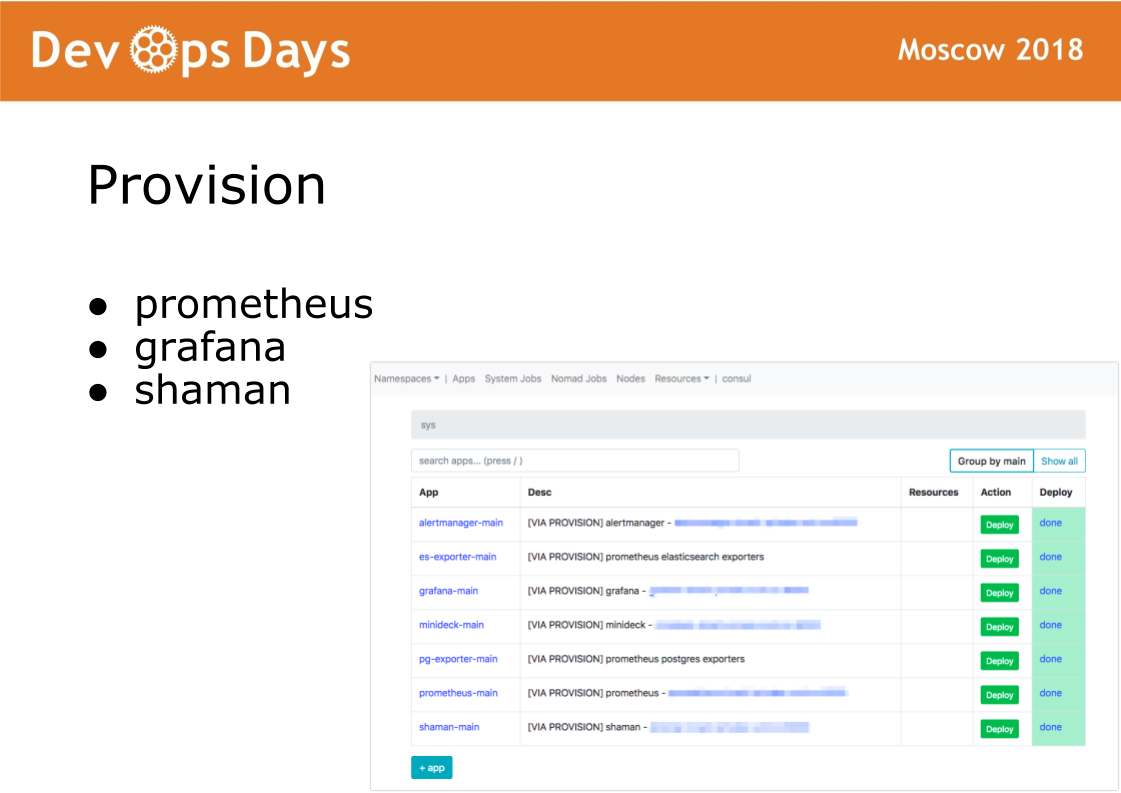
Une fois que nous sommes entrés sur le site, Ansible exécute le playbook situé dans le répertoire d'approvisionnement. Le playbook de ce répertoire est responsable de l'installation du logiciel dans le cluster de dockers utilisé par les administrateurs. Installez le logiciel prometheus, grafana et shaman secret.
Shaman est un tableau de bord Web pour les nomades. Nomad est de bas niveau et je ne veux pas vraiment laisser les développeurs y entrer. Dans chaman, nous voyons une liste d'applications, nous donnons aux développeurs un bouton de déploiement pour les applications. Les développeurs peuvent modifier les configurations: ajouter des conteneurs, des variables d'environnement, démarrer des services.
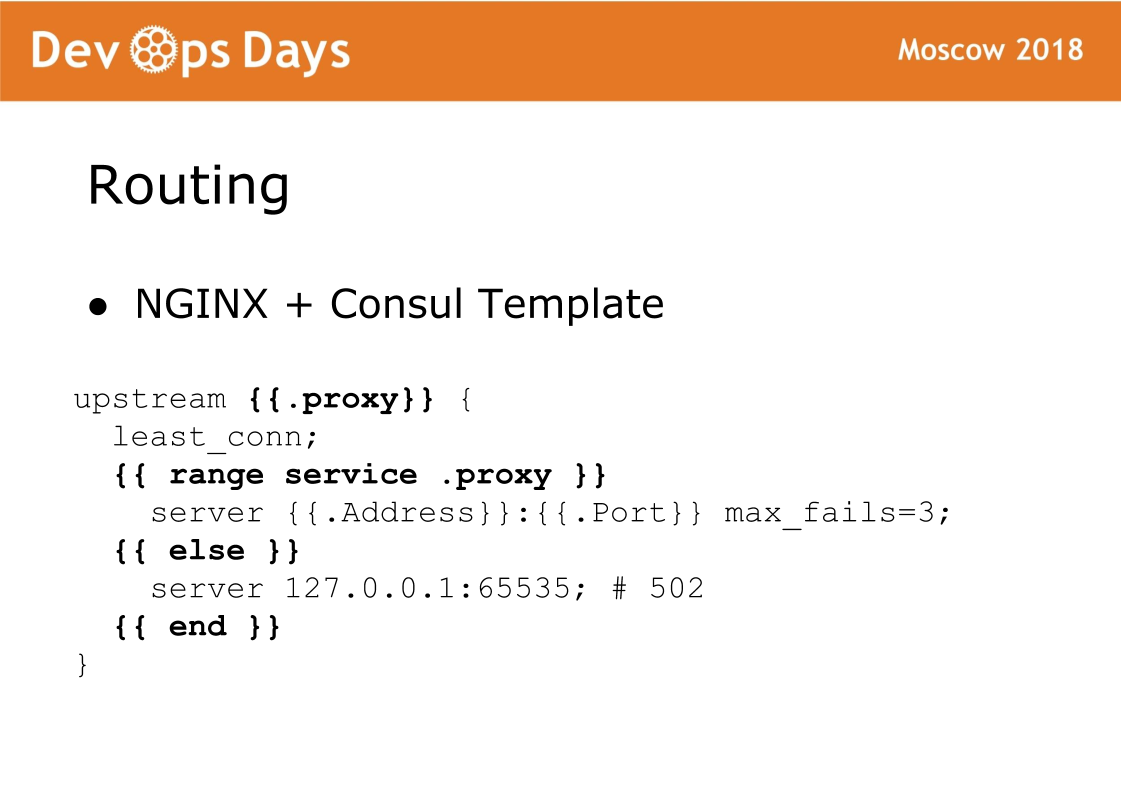
Et enfin, le dernier élément du site est le routage. Le routage est stocké dans le stockage K / V du consul, c'est-à-dire qu'il existe un lien entre l'amont, le service, l'url, etc. Sur chaque équilibreur, il existe un modèle Consul qui génère une configuration nginx et la fait recharger. Une chose très fiable, nous n'avons jamais eu de problème avec ça. La caractéristique de ce schéma est que le trafic accepte le nginx standard et vous pouvez toujours voir quelle configuration a été générée et fonctionner comme avec le nginx standard.

Ainsi, chaque site se compose de 5 couches. Avec terraform, nous personnalisons le matériel. Nous pouvons effectuer la configuration de base des serveurs, mettre le docker-cluster. Provision résume le logiciel système. Le routage dirige le trafic sur le site. Applications contient des applications utilisateur et des applications administrateur.
Nous avons débogué ces couches pendant longtemps afin qu'elles soient aussi identiques que possible. Provision, le routage correspond à 100% entre les sites. Par conséquent, pour les développeurs, chaque site est absolument identique.
Si les informaticiens passent d'un projet à l'autre, ils tombent dans un environnement tout à fait typique. En ansible, nous n'avons pas pu rendre les paramètres de pare-feu et VPN identiques pour différents fournisseurs de cloud. Avec un réseau, tous les fournisseurs de cloud fonctionnent différemment. Terraform est partout le sien, car il contient des conceptions spécifiques pour chaque fournisseur de cloud.
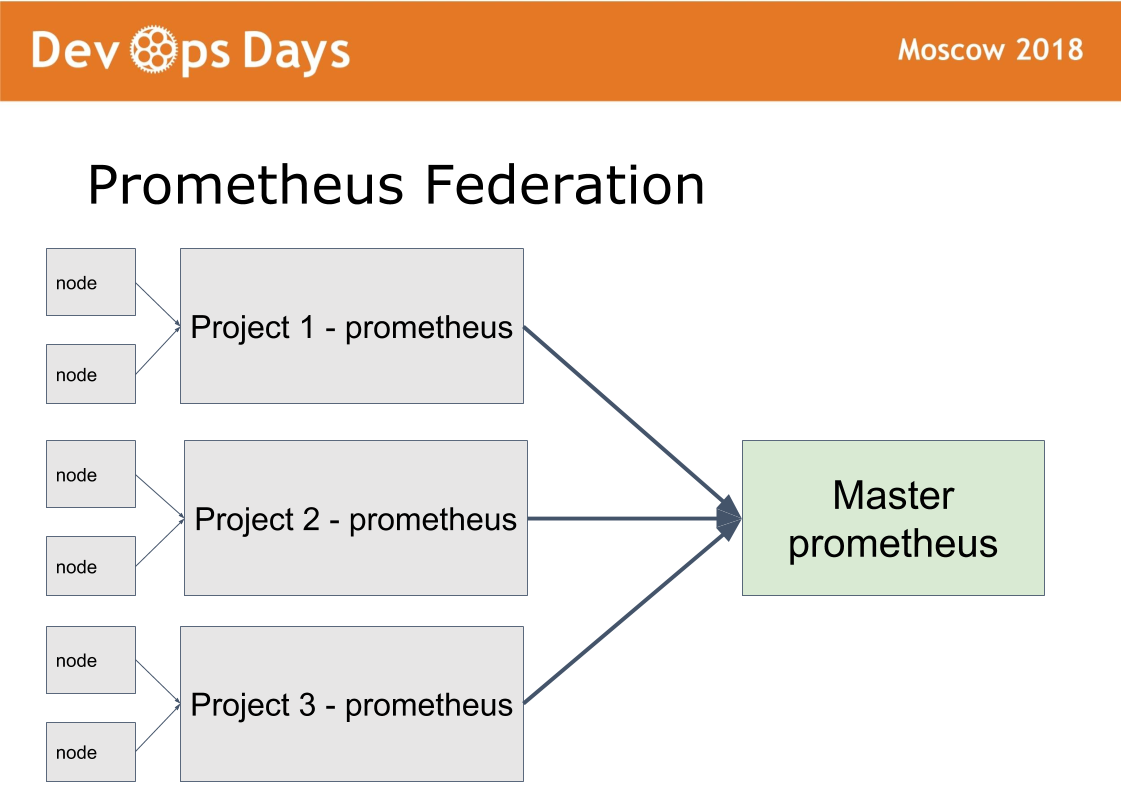
Nous avons 14 sites de production. La question se pose: comment les gérer? Nous avons fait le 15ème site maître, dans lequel nous n'autorisons que les administrateurs. Elle travaille sur un schéma de fédération.
L'idée a été prise de prometheus. Il y a un mode dans prometheus lorsque nous installons prometheus dans chaque site. Nous publions Prometheus via l'autorisation d'authentification de base HTTPS. Le maître Prometheus ne récupère que les métriques nécessaires du prometheus distant. Cela permet de comparer les métriques des applications dans différents clouds, de trouver les applications les plus téléchargées ou déchargées. La notification centralisée (alerte) passe par le maître Prometheus pour les administrateurs. Les développeurs reçoivent des alertes de prometheus local.

Le chaman est configuré de la même manière. Grâce au site principal, les administrateurs peuvent déployer, configurer sur n'importe quel site via une seule interface. Nous résolvons une classe de problèmes suffisamment importante sans quitter ce site maître.

Je vais vous dire comment nous sommes passés à Docker. Ce processus est très lent. Nous avons traversé environ 10 mois. À l'été 2017, nous avions 0 conteneurs de production. En avril 2018, nous avons ancré et déployé notre dernière application en production.

Nous venons du monde du rubis sur rails. Il y avait 99% des applications Ruby on Rails. Rails se déploie à travers Capistrano. Techniquement, Capistrano fonctionne comme suit: le développeur lance cap deploy, capistrano se rend sur tous les serveurs d'applications via ssh, récupère la dernière version du code, collecte les actifs, migre la base de données. Capistrano crée un lien symbolique vers la nouvelle version du code et envoie un signal USR2 à l'application Web. À ce signal, le serveur Web prend un nouveau code.
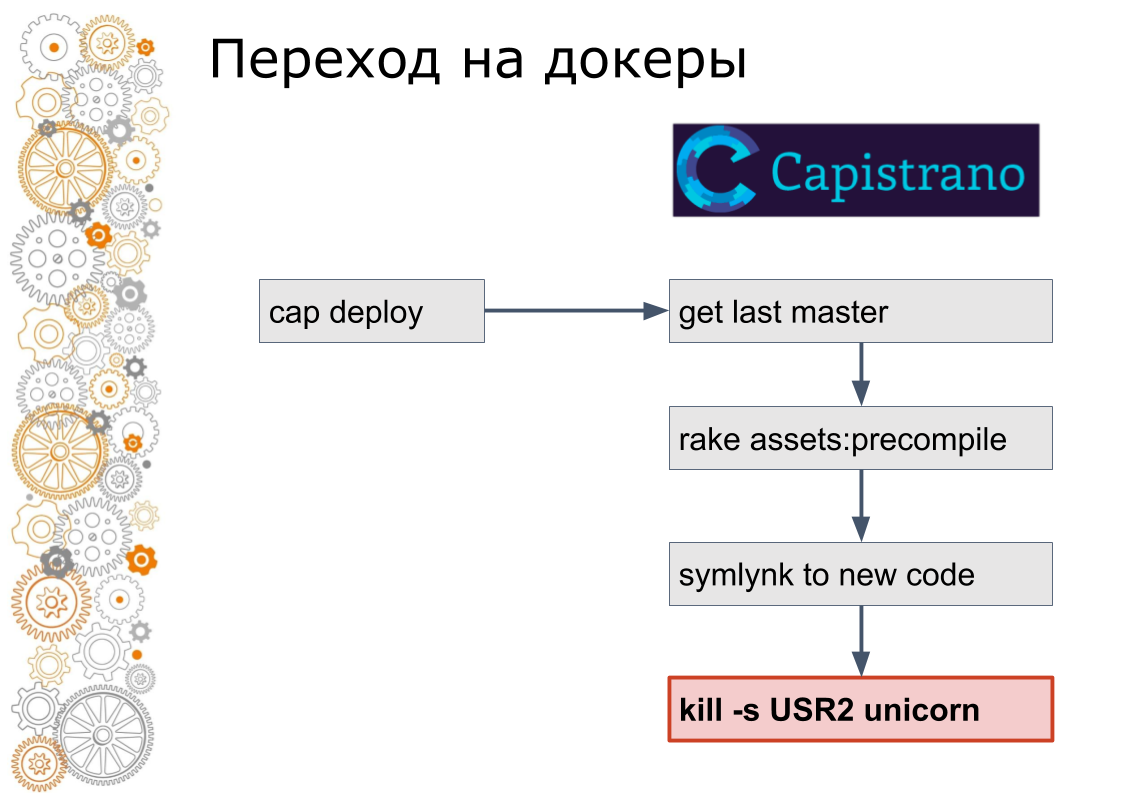
La dernière étape de docker ne se fait pas comme ça. Dans Docker, vous devez arrêter l'ancien conteneur, soulever le nouveau conteneur. Cela soulève la question: comment changer de trafic? Dans le monde du cloud, la découverte de services en est responsable.

Par conséquent, nous avons ajouté un consul à chaque site. Le consul a été ajouté car ils utilisaient Terraform. Nous avons enveloppé toutes les configurations nginx dans un modèle de consul. Formellement, la même chose, mais déjà nous étions prêts à gérer dynamiquement le trafic à l'intérieur des sites.

Ensuite, nous avons écrit un script ruby qui collectait une image sur l'un des serveurs, la poussait dans le registre, puis passait par ssh à chaque serveur, en récupérait de nouveaux et arrêtait les anciens conteneurs, les enregistrant en consul. Les développeurs ont également continué à exécuter cap deploy, mais les services étaient déjà en cours d'exécution dans docker.
Je me souviens qu'il y avait deux versions du script, la seconde s'est avérée assez avancée, il y a eu une mise à jour continue, lorsqu'un petit nombre de conteneurs s'est arrêté, de nouveaux ont augmenté, le consul Helfcheki a attendu et est parti.

Ils ont ensuite réalisé qu'il s'agissait d'une méthode sans issue. Le script est passé à 600 lignes. La prochaine étape du délestage manuel, nous avons remplacé Nomad. Masquer les détails du travail au développeur. Autrement dit, ils appelaient toujours cap deploy, mais à l'intérieur il y avait déjà une technologie complètement différente.
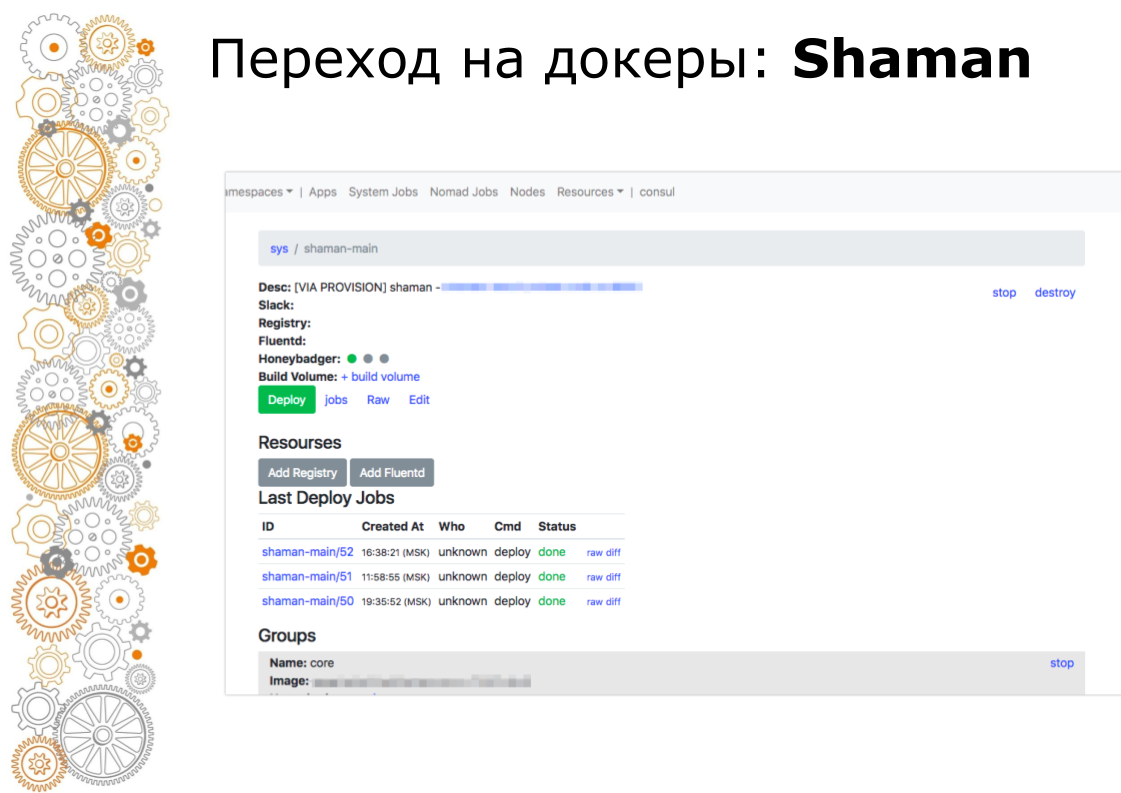
Et à la fin, nous avons déplacé le déploiement vers l'interface utilisateur et retiré l'accès au serveur, laissant le bouton de déploiement vert et l'interface de contrôle.
En principe, une telle transition s'est avérée bien sûr longue, mais nous avons évité le problème que j'ai rencontré à plusieurs reprises.
Il existe une sorte de pile, de système ou quelque chose comme ça. Khachennaya déjà juste en volets. Le développement d'une nouvelle version commence. Après quelques mois ou quelques années, selon la taille de l'entreprise, moins de la moitié des fonctionnalités nécessaires sont implémentées dans la nouvelle version, et l'ancienne version s'est toujours échappée. Et cette nouvelle est également devenue très héritée. Et il est temps de commencer une nouvelle troisième version à partir de zéro. En général, c'est un processus sans fin.
Par conséquent, nous déplaçons toujours la pile entière dans son ensemble. À petits pas, de travers, avec des béquilles, mais entièrement. Nous ne pouvons pas mettre à niveau par exemple le moteur Docker sur un seul site. Il faut mettre à jour partout, s'il y a un désir.

Déploiements. Toutes les instructions de docker déploient 10 conteneurs nginx ou 10 conteneurs redis dans docker. Ceci est un mauvais exemple, car les images sont déjà assemblées, les images sont claires. Nous avons emballé nos applications de rails dans Docker. La taille des images de docker était de 2 à 3 gigaoctets. Ils sortiront pas si vite.
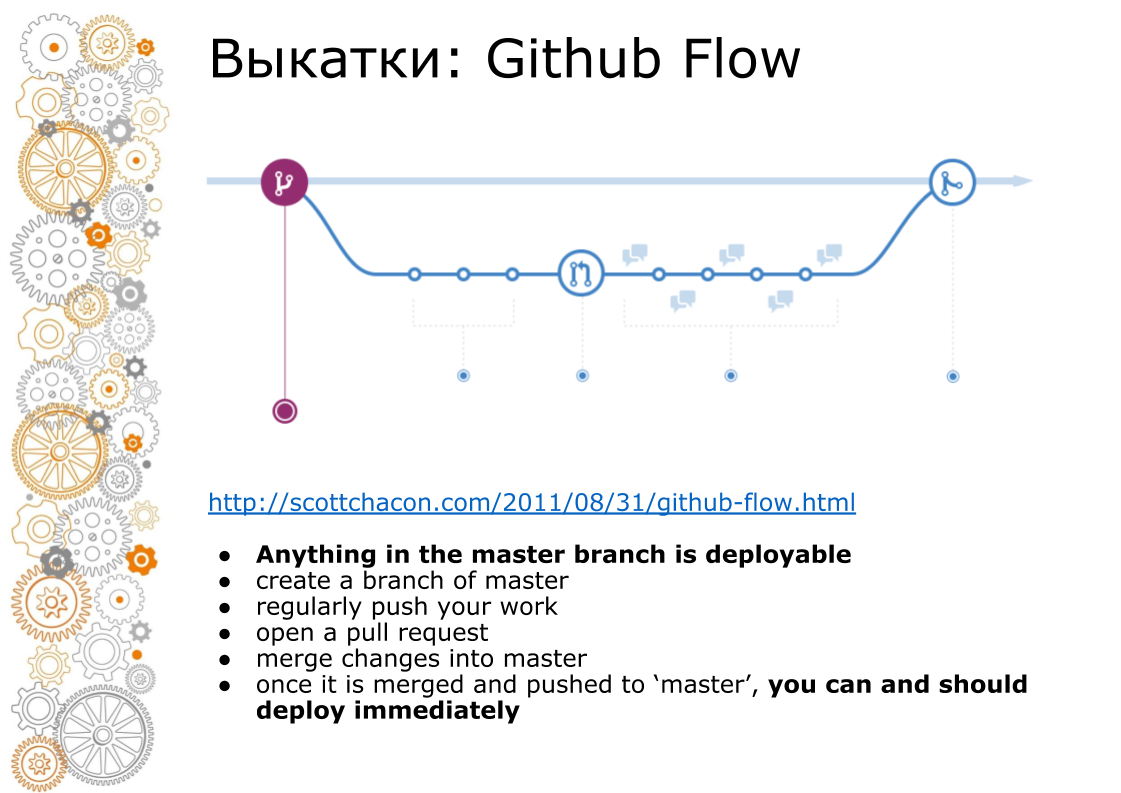
Le deuxième problème est venu du web hipster. Un site Web hipster est toujours Github Flow. En 2011, il y avait un poste de création d'époque que Github Flow dirige, de sorte que la toile entière roule. À quoi ça ressemble? La branche maître est toujours la production. Lors de l'ajout de nouvelles fonctionnalités, nous créons une branche. Lors de la fusion, nous procédons à la révision du code, exécutons des tests, augmentons l'environnement de transfert. Environnement de mise en scène à la recherche d'affaires. Au moment X, si tout réussit, nous fusionnons la branche en master et passons en production.
Sur capistrano, cela a bien fonctionné, car il a été créé pour cela. Docker nous vend toujours un pipeline. Assemblé le conteneur. Le conteneur peut être transféré au développeur, testeur, transféré à la production. Mais au moment de la fusion en master, le code est déjà différent. Toutes les images de docker qui ont été collectées à partir de la branche de fonctionnalité, elles n'ont pas été collectées à partir du maître.

Comment l'avons-nous fait? Nous collectons l'image, la mettons dans le registre docker local. Et après cela, nous faisons le reste des opérations: migration, déploiement en production.

Pour assembler rapidement cette image, nous utilisons Docker-in-Docker. Sur Internet, tout le monde écrit que c'est un anti-pattern, ça plante. Nous n'avions rien de tel. Combien travaillaient déjà avec lui n'a jamais eu de problème. Nous transmettons le répertoire / var / lib / docker au serveur principal en utilisant le volume persistant. Toutes les images intermédiaires se trouvent sur le serveur principal. L'assemblage d'une nouvelle image tient en quelques minutes.

Pour chaque application, nous créons un registre docker interne local et notre volume de build. Parce que docker enregistre toutes les couches sur le disque et est difficile à nettoyer. Nous connaissons maintenant l'utilisation du disque de chaque registre Docker local. Nous savons combien de disque cela nécessite. Vous pouvez recevoir des alertes via Grafana centralisé et nettoyer. Pendant que nous nettoyons leurs mains. Mais nous allons l'automatiser.

Un autre point. Image Docker collectée. Maintenant, cette image doit être décomposée en serveurs. Lors de la copie d'une grande image Docker, le réseau ne résiste pas. Dans le cloud, nous avons 1 Gbit / s. Il y a un arrêt global dans le cloud. Nous déployons maintenant une image Docker sur 4 serveurs de production lourds. Sur le graphique, vous pouvez voir le disque travaillé sur 1 pack de serveurs. Ensuite, le deuxième pack de serveurs est déployé. Ci-dessous, vous pouvez voir l'utilisation du canal. Environ 1 Gbit / s, nous tirons presque. Il n'y a plus beaucoup d'accélération.

Ma production préférée est l'Afrique du Sud. Il y a du fer très cher et lent. Quatre fois plus cher qu'en Russie. Il y a une très mauvaise connexion Internet. Internet au niveau du modem, mais pas buggy. Là, nous déployons des applications en 40 minutes, en prenant en compte le réglage des caches, les paramètres de timeout.

Le dernier problème qui m'inquiétait avant que Docker ne contacte était la charge. En fait, la charge est la même que sans docker avec un fer identique. La seule nuance que nous avons rencontrée en un seul point. Si vous collectez des journaux du moteur Docker via le pilote fluentd intégré, puis à une charge d'environ 1000 rps, le tampon fluentd interne commence à être jonché et les demandes commencent à ralentir. Nous avons enlevé l'exploitation forestière dans des conteneurs de side-car. En nomade, cela s'appelle l'expéditeur de grumes. Un petit conteneur est suspendu à côté d'un grand conteneur d'application. La seule tâche consiste à le récupérer et à l'envoyer vers un référentiel centralisé.

Quels étaient les problèmes / solutions / défis. J'ai essayé d'analyser quelle était la tâche. Les caractéristiques de nos problèmes sont:
- de nombreuses applications indépendantes
- changements continus dans l'infrastructure
- Flux Github et grandes images de docker

Nos solutions
- Fédération des clusters de dockers. Du point de vue de la manipulation, c'est difficile. Mais Docker est bon pour déployer des fonctionnalités commerciales en production. Nous travaillons avec des données personnelles et nous avons une certification dans chaque pays. Dans un site isolé, une telle certification est facile à passer. Pendant la certification, toutes les questions se posent: où hébergez-vous, comment avez-vous un fournisseur de cloud, où stockez-vous les données personnelles, où sauvegardez-vous, qui a accès aux données. Lorsque tout est isolé, il est beaucoup plus facile de décrire le cercle des suspects et de surveiller tout cela beaucoup plus facilement.
- Orchestration. Il est clair que les kubernetes. Il est partout. Mais je tiens à dire que Consul + Nomad est une solution complètement de production.
- Assemblage d'images. Vous pouvez rapidement créer des images dans Docker-in-Docker.
- Lors de l'utilisation de Docker, le maintien d'une charge de 1000 rps est également possible.
Vecteur de direction de développement
Maintenant, l'un des gros problèmes est la désynchronisation des versions logicielles sur les sites. Auparavant, nous configurions le serveur à la main. Puis nous sommes devenus des ingénieurs devops. Configurez maintenant le serveur en utilisant ansible. Nous avons maintenant l'unification totale, la normalisation. Nous introduisons la pensée ordinaire dans la tête. Nous ne pouvons pas réparer PostgreSQL avec nos mains sur le serveur. Si vous avez besoin d'une sorte de réglage fin sur un seul serveur, nous pensons comment répartir ce paramètre partout. Si vous ne standardisez pas, il y aura un zoo de paramètres.
Je suis ravi et très heureux que nous sortions de la boîte gratuitement une infrastructure de travail vraiment, vraiment sympa.

Vous pouvez m'ajouter sur facebook. Si nous faisons quelque chose de bien, j'écrirai à ce sujet.
Questions:
Quel est l'avantage du modèle Consul par rapport au modèle Ansible, par exemple, pour configurer des règles de pare-feu et plus encore?
Réponse: Nous avons maintenant du trafic provenant d'équilibreurs externes qui va directement aux conteneurs. Il n'y a personne entre les deux. Une configuration y est formée qui transmet les adresses IP et les ports du cluster. De plus, nous avons tous les paramètres d'équilibre en K / V dans Consul. Nous avons une idée de donner des paramètres de routage aux développeurs via une interface sécurisée afin qu'ils ne cassent rien.
Question: Concernant l'homogénéité de tous les sites. N'y a-t-il vraiment aucune demande des entreprises ou des développeurs dont vous avez besoin pour déployer quelque chose de non standard sur ce site? Par exemple, tarantool avec cassandra.
Réponse: Cela arrive, mais c'est très rare. Ceci nous établissons un artefact séparé interne. Il y a un tel problème, mais il est rare.
Question: La solution au problème de livraison est d'utiliser un registre de docker privé dans chaque site et à partir de là, il est déjà rapide d'obtenir des images de docker.
Réponse: Quoi qu'il en soit, le déploiement se déroulera sur le réseau, car nous déployons simultanément l'image docker sur 15 serveurs. Nous nous reposons contre le réseau. À l'intérieur du réseau, 1 Gbit / s.
Question: De nombreux conteneurs Docker sont basés à peu près sur la même pile technologique?
Réponse: Ruby, Python, NodeJS.
Question: À quelle fréquence testez-vous ou vérifiez-vous les images de votre docker pour les mises à jour? Comment résolvez-vous les problèmes de mise à jour, par exemple, lorsque glibc, openssl doivent être corrigés dans tous les dockers?
Réponse: Si vous trouvez une telle erreur, vulnérabilité, alors nous nous asseyons pendant une semaine et la réparons. Si vous avez besoin de déployer, nous pouvons déployer le cloud entier (toutes les applications) de zéro à travers la fédération. On peut cliquer sur tous les boutons verts pour le déploiement d'applications et laisser boire du thé.
Question: Allez-vous libérer votre chaman en open source?
Réponse: Ici Andrei (montre la personne du public) nous promet de mettre en place un chaman à l'automne. Mais là, vous devez ajouter un support pour kubernetes. OpenSource devrait toujours être meilleur.