
L'un des problèmes pressants à tout moment est celui de la préparation des rapports. Étant donné que Julia est une langue dont les utilisateurs sont directement liés aux tâches d'analyse des données, de préparation d'articles et de belles présentations avec les résultats des calculs et des rapports, ce sujet ne peut tout simplement pas être ignoré.
Initialement, cet article prévoyait un ensemble de recettes pour générer des rapports, mais à côté des rapports se trouve le sujet de la documentation, avec laquelle les générateurs de rapports ont de nombreuses intersections. Par conséquent, cela inclut des outils pour le critère de la possibilité d'incorporer du code exécutable Julia dans un modèle avec un balisage. Enfin, nous notons que la revue comprenait des générateurs de rapports, tous deux implémentés sur Julia elle-même, et des outils écrits dans d'autres langages de programmation. Eh bien, bien sûr, certains points clés de la langue Julia elle-même n'ont pas été ignorés, sans lesquels il n'est peut-être pas clair dans quels cas et quels moyens devraient être utilisés.
Carnet Jupyter
Cet outil devrait peut-être être attribué au plus populaire parmi ceux impliqués dans l'analyse des données. En raison de la possibilité de connecter différents cœurs de calcul, il est populaire auprès des chercheurs et des mathématiciens habitués à leurs langages de programmation spécifiques, dont Julia. Les modules correspondants pour le langage Julia sont entièrement implémentés pour le bloc-notes Jupyter. Et c'est pourquoi le Notebook est mentionné ici.
Le processus d'installation de Jupyter Notebook n'est pas compliqué. Pour la commande, voir https://github.com/JuliaLang/IJulia.jl Si Jupyter Notebook est déjà installé, il vous suffit d'installer le package Ijulia et d'enregistrer le noyau informatique correspondant.
Étant donné que le produit Jupyter Notebook est suffisamment connu pour ne pas l'écrire en détail, nous ne mentionnerons que quelques points. Bloc-notes (nous utiliserons la terminologie du bloc-notes) dans un bloc-notes Jupyter se compose de blocs, chacun pouvant contenir du code ou du balisage sous ses différentes formes (par exemple, Markdown). Le résultat du traitement est soit la visualisation du balisage (texte, formules, etc.), soit le résultat de la dernière opération. Si un point-virgule est placé à la fin de la ligne avec le code, le résultat ne sera pas affiché.
Exemples. Le bloc-notes avant exécution est illustré dans la figure suivante:

Le résultat de sa mise en œuvre est illustré dans la figure suivante.
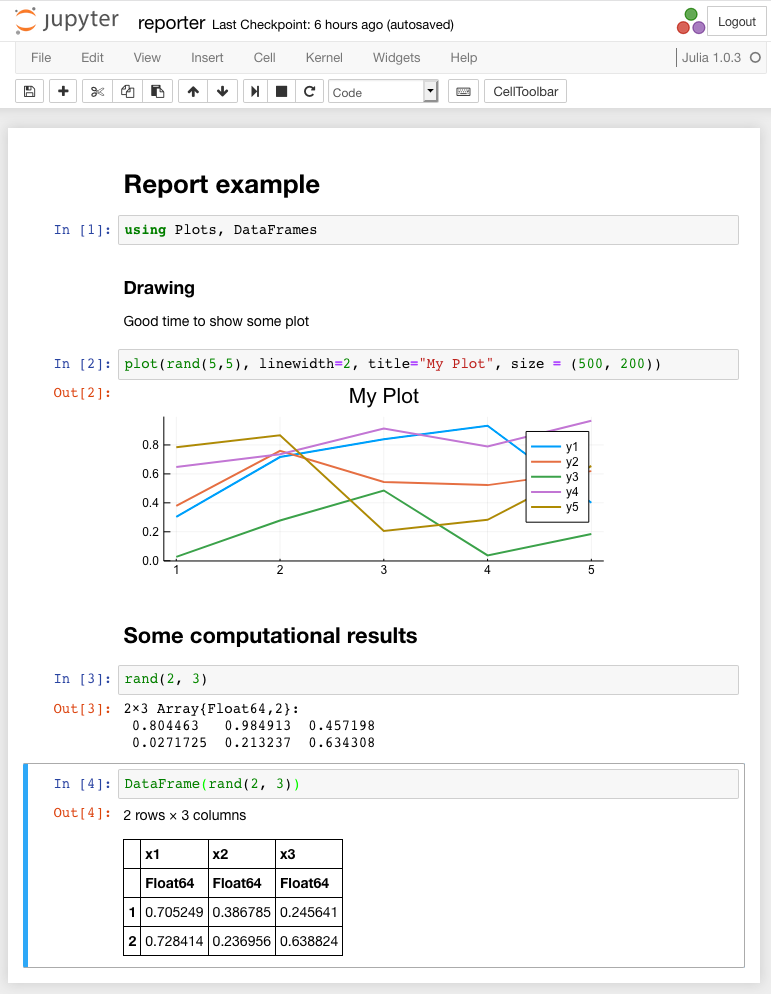
Le bloc-notes contient des graphiques et du texte. Notez que pour sortir la matrice, il est possible d'utiliser le type DataFrame , pour lequel le résultat est affiché sous la forme d'un tableau html avec des bordures explicites et un scroller, si nécessaire.
Le bloc-notes Jupyter peut exporter le bloc-notes actuel vers un fichier html. S'il y a des outils de conversion installés, il peut convertir en pdf.
Pour créer des rapports conformément à certaines réglementations, vous pouvez utiliser le module nbconvert et la commande suivante, qui est appelée en arrière-plan selon le calendrier:
jupyter nbconvert --to html --execute julia_filename.ipynb
Lors de longs calculs, il est conseillé d'ajouter une option indiquant le délai d'attente - --ExecutePreprocessor.timeout=180
Un rapport html généré à partir de ce fichier apparaîtra dans le répertoire courant. L'option --execute signifie ici forcer le recomptage à démarrer.
Pour un ensemble complet d' nbconvert module nbconvert consultez
https://nbconvert.readthedocs.io/en/latest/usage.html
Le résultat de la conversion en html est presque complètement cohérent avec la figure précédente, sauf qu'il n'a pas de barre de menu ou de boutons.
Jupytext
Un utilitaire assez intéressant qui vous permet de convertir des notes ipynb précédemment créées en texte Markdown ou en code Julia.
Nous pouvons transformer l'exemple précédemment considéré en utilisant la commande
jupytext --to julia julia_filename.ipynb
En conséquence, nous obtenons le fichier julia_filename.jl avec le code Julia et un balisage spécial sous forme de commentaires.
# --- # jupyter: # jupytext: # text_representation: # extension: .jl # format_name: light # format_version: '1.3' # jupytext_version: 0.8.6 # kernelspec: # display_name: Julia 1.0.3 # language: julia # name: julia-1.0 # --- # # Report example using Plots, DataFrames # ### Drawing # Good time to show some plot plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) # ## Some computational results rand(2, 3) DataFrame(rand(2, 3))
Notez que les séparateurs de blocs ne sont que des sauts de ligne doubles.
On peut faire la transformation inverse en utilisant la commande:
jupytext --to notebook julia_filename.jl
En conséquence, un fichier ipynb sera généré, qui, à son tour, peut être traité et converti en pdf ou html.
Voir les détails https://github.com/mwouts/jupytext
L'inconvénient général de jupytext et jupyter notebook est que la «beauté» du rapport est limitée par les capacités de ces outils.
HTML auto-généré
Si, pour une raison quelconque, nous pensons que le bloc-notes Jupyter est un produit trop lourd, nécessitant l'installation de nombreux packages tiers qui ne sont pas nécessaires au fonctionnement de Julia, ou pas suffisamment flexibles pour créer le formulaire de rapport dont nous avons besoin, alors une autre méthode consiste à générer une page html manuellement. Cependant, ici, vous devez vous plonger un peu dans les fonctionnalités de l'imagerie.
Pour Julia, une façon typique de sortir quelque chose dans le flux de sortie est d'utiliser la fonction Base.write et pour la décoration, Base.show(io, mime, x) . De plus, pour les différentes méthodes de sortie MIME demandées, il peut y avoir différentes options d'affichage. Par exemple, un DataFrame lorsqu'il est affiché sous forme de texte est affiché par un tableau pseudo-graphique.
julia> show(stdout, MIME"text/plain"(), DataFrame(rand(3, 2))) 3×2 DataFrame │ Row │ x1 │ x2 │ │ │ Float64 │ Float64 │ ├─────┼──────────┼───────────┤ │ 1 │ 0.321698 │ 0.939474 │ │ 2 │ 0.933878 │ 0.0745969 │ │ 3 │ 0.497315 │ 0.0167594 │
Si mime est spécifié en tant que text/html , le résultat est un balisage HTML.
julia> show(stdout, MIME"text/html"(), DataFrame(rand(3, 2))) <table class="data-frame"> <thead> <tr><th></th><th>x1</th><th>x2</th></tr> <tr><th></th><th>Float64</th><th>Float64</th></tr> </thead> <tbody><p>3 rows × 2 columns</p> <tr><th>1</th><td>0.640151</td><td>0.219299</td></tr> <tr><th>2</th><td>0.463402</td><td>0.764952</td></tr> <tr><th>3</th><td>0.806543</td><td>0.300902</td></tr> </tbody> </table>
Autrement dit, en utilisant les méthodes de la fonction show définies pour le type de données correspondant (troisième argument) et le format de sortie correspondant, il est possible d'assurer la formation d'un fichier dans n'importe quel format de données souhaité.
La situation avec les images est plus compliquée. Si nous devons créer un seul fichier html, l'image doit être intégrée dans le code de la page.
Prenons l'exemple dans lequel cela est mis en œuvre. La sortie dans le fichier sera effectuée par la fonction Base.write , pour laquelle nous définissons les méthodes appropriées. Donc le code:
#!/usr/bin/env julia using Plots using Base64 using DataFrames # p = plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) # , , @show typeof(p) # => typeof(p) = Plots.Plot{Plots.GRBackend} # , 3 # abstract type Png end abstract type Svg end abstract type Svg2 end # Base.write # # — , # Base64-. # HTML img src="data:image/png;base64,..." function Base.write(file::IO, ::Type{Png}, p::Plots.Plot) local io = IOBuffer() local iob64_encode = Base64EncodePipe(io); show(iob64_encode, MIME"image/png"(), p) close(iob64_encode); write(file, string("<img src=\"data:image/png;base64, ", String(take!(io)), "\" alt=\"fig.png\"/>\n")) end # Svg function Base.write(file::IO, ::Type{Svg}, p::Plots.Plot) local io = IOBuffer() show(io, MIME"image/svg+xml"(), p) write(file, replace(String(take!(io)), r"<\?xml.*\?>" => "" )) end # XML- , SVG Base.write(file::IO, ::Type{Svg2}, p::Plots.Plot) = show(file, MIME"image/svg+xml"(), p) # DataFrame Base.write(file::IO, df::DataFrame) = show(file, MIME"text/html"(), df) # out.html HTML open("out.html", "w") do file write(file, """ <!DOCTYPE html> <html> <head><title>Test report</title></head> <body> <h1>Test html</h1> """) write(file, Png, p) write(file, "<br/>") write(file, Svg, p) write(file, "<br/>") write(file, Svg2, p) write(file, DataFrame(rand(2, 3))) write(file, """ </body> </html> """) end
Pour créer des images, le moteur Plots.GRBackend est utilisé par défaut, qui peut effectuer une sortie d'image raster ou vectorielle. Selon le type spécifié dans l'argument mime de la fonction show , le résultat correspondant est généré. MIME"image/png"() forme une image au format png . MIME"image/svg+xml"() génère une image svg. Cependant, dans le deuxième cas, vous devez faire attention au fait qu'un document xml complètement indépendant est formé, qui peut être écrit dans un fichier séparé. Dans le même temps, notre objectif est d'incorporer une image dans une page HTML, ce qui en HTML5 peut être fait en insérant simplement le balisage SVG. C'est pourquoi la méthode Base.write(file::IO, ::Type{Svg}, p::Plots.Plot) supprime l'en-tête xml, qui, sinon, violera la structure du document HTML. Bien que la plupart des navigateurs soient capables d'afficher correctement l'image même dans ce cas.
Concernant la méthode pour les Base.write(file::IO, ::Type{Png}, p::Plots.Plot) , la fonctionnalité d'implémentation ici est que nous ne pouvons insérer que des données binaires en HTML au format Base64. Pour ce faire, nous utilisons la construction <img src="data:image/png;base64,"/> . Et pour le transcodage, nous utilisons Base64EncodePipe .
La méthode Base.write(file::IO, df::DataFrame) fournit une sortie au format de table html de l'objet DataFrame .
La page résultante est la suivante:
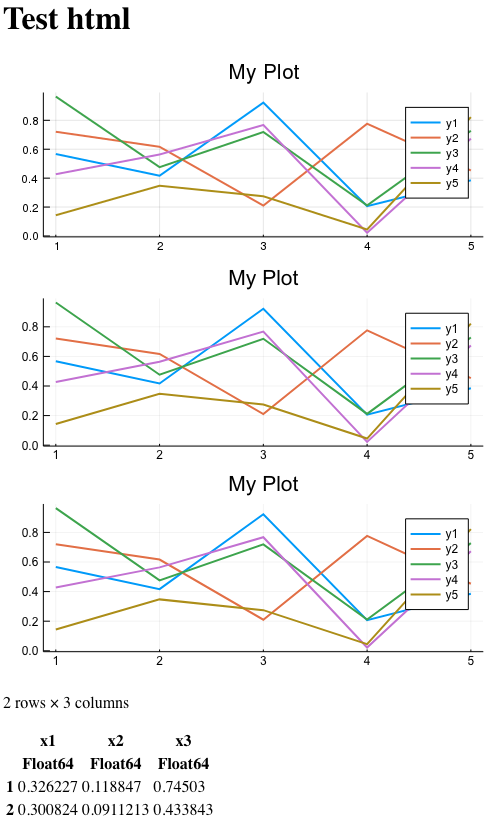
Dans l'image, les trois images se ressemblent à peu près, cependant, rappelez-vous que l'une d'entre elles n'est pas insérée correctement du point de vue du HTML (en-tête xml supplémentaire). L'un est raster, ce qui signifie qu'il ne peut pas être augmenté sans perte de détails. Et un seul d'entre eux est inséré en tant que fragment svg correct dans le balisage HTML. Et il peut être facilement mis à l'échelle sans perte de détails.
Naturellement, la page s'est avérée très simple. Mais toutes les améliorations visuelles sont possibles avec CSS.
Cette méthode de génération de rapports est utile, par exemple, lorsque le nombre de tableaux affichés est déterminé par des données réelles et non par un modèle. Par exemple, vous devez regrouper les données par un champ. Et pour chaque groupe de former des blocs séparés. Étant donné que lors de la formation d'une page, le résultat est déterminé par le nombre d'appels à Base.write , il est évident qu'il n'y a aucun problème à Base.write le bloc souhaité dans une boucle, ce qui rend la sortie dépendante des données, etc.
Exemple de code:
using DataFrames # ptable = DataFrame( Symbol = ["H", "He", "C", "O", "Fe" ], Room = [:Gas, :Gas, :Solid, :Gas, :Solid] ) res = groupby(ptable, [:Room]) # open("out2.html", "w") do f for df in (groupby(ptable, [:Room])) write(f, "<h2>$(df[1, :Room])</h2>\n") show(f, MIME"text/html"(), DataFrame(df)) write(f, "\n") end end
Le résultat de ce script est un fragment de la page HTML.

Veuillez noter que tout ce qui ne nécessite pas de conversion de décoration / format est affiché directement via la fonction Base.write . Dans le même temps, tout ce qui nécessite une conversion est Base.show via Base.show .
Weave.jl
Weave est un générateur de rapports scientifiques implémenté par Julia. Utilise les idées des générateurs Pweave, Knitr, rmarkdown, Sweave. Sa tâche principale est d'exporter le balisage source dans l'une des langues proposées (Noweb, Markdown, format de script) aux formats LaTex, Pandoc, Github markdown, MultiMarkdown, Asciidoc, reStructuredText. Et, même dans les ordinateurs portables IJulia et vice versa. Dans la dernière partie, il est similaire à Jupytext.
Autrement dit, Weave est un outil qui vous permet d'écrire des modèles contenant du code Julia dans différents langages de balisage et, à la sortie, d'avoir du balisage dans un autre langage (mais avec les résultats de l'exécution du code Julia). Et c'est un outil très utile spécifiquement pour les chercheurs. Par exemple, vous pouvez préparer un article sur Latex, qui comportera des encarts sur Julia avec calcul automatique du résultat et de sa substitution. Weave générera un fichier pour l'article final.
Il existe un support pour l'éditeur Atom utilisant le plugin correspondant https://atom.io/packages/language-weave . Cela vous permet de développer et de déboguer des scripts Julia incorporés dans le balisage, puis de générer le fichier cible.
Le principe de base de Weave, comme déjà mentionné, est d'analyser un modèle contenant du balisage avec du texte (formules, etc.) et de coller le code sur Julia. Le résultat de l'exécution du code peut être affiché dans le rapport final. La sortie du texte, du code, la sortie des résultats, la sortie des graphiques - tout cela peut être configuré individuellement.
Pour traiter les modèles, vous devez exécuter un script externe qui collectera tout en un seul document et le convertira au format de sortie souhaité. Autrement dit, les modèles séparément, les gestionnaires séparément.
Un exemple d'un tel script de traitement:
# : # Markdown weave("w_example.jmd", doctype="pandoc" out_path=:pwd) # HTML weave("w_example.jmd", out_path=:pwd, doctype = "md2html") # pdf weave("w_example.jmd", out_path=:pwd, doctype = "md2pdf")
jmd dans les noms de fichiers est Julia Markdown.
Prenons le même exemple que nous avons utilisé dans les outils précédents. Cependant, nous insérerons un en-tête contenant des informations sur l'auteur que Weave comprend.
--- title : Intro to Weave.jl with Plots author : Anonymous date : 06th Feb 2019 --- # Intro ## Plot ` ``{julia;} using Plots, DataFrames plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) ` `` ## Some computational results ` ``julia rand(2, 3) ` `` ` ``julia DataFrame(rand(2, 3)) ` ``
Ce fragment, converti en pdf, ressemble à ceci:

Les polices et la mise en page sont bien reconnues par les utilisateurs de Latex.
Pour chaque morceau de code incorporé, vous pouvez déterminer comment ce code sera traité et ce qui sera affiché à la fin.
Par exemple:
- echo = true - le code sera affiché
- eval = true - le résultat de l'exécution du code sera affiché
- étiquette - ajoutez une étiquette. Si le latex est utilisé, il sera utilisé comme fig: label
- fig_width, fig_height - tailles d'image
- et ainsi de suite
Pour les formats noweb et script, ainsi que pour en savoir plus sur cet outil, voir http://weavejl.mpastell.com/stable/
Literate.jl
Lorsqu'on leur demande pourquoi Literate, les auteurs de ce paquet se réfèrent au paradigme de programmation littéraire de Donald Knutt. La tâche de cet outil est de générer des documents basés sur du code Julia contenant des commentaires au format markdown. Contrairement à l'outil Weave précédent examiné, il ne peut pas créer de documents avec les résultats de l'exécution. Cependant, l'outil est léger et principalement axé sur la documentation du code. Par exemple, aidez à écrire de beaux exemples qui peuvent être placés sur n'importe quelle plateforme de démarque. Souvent utilisé dans une chaîne d'autres outils de documentation, par exemple, avec Documenter.jl .
Il existe trois options possibles pour le format de sortie - démarque, bloc-notes et script (code Julia pur). Aucun d'eux n'exécutera le code implémenté.
Exemple de fichier source avec des commentaires Markdown (après le premier caractère #):
#!/usr/bin/env julia using Literate Literate.markdown(@__FILE__, pwd()) # documenter=true # # Intro # ## Plot using Plots, DataFrames plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) # ## Some computational results rand(2, 3) DataFrame(rand(2, 3))
Le résultat de son travail sera un document Markdown et des directives pour Documenter , si leur génération n'a pas été explicitement désactivée.
` ``@meta EditURL = "https://github.com/TRAVIS_REPO_SLUG/blob/master/" ` `` ` ``@example literate_example #!/usr/bin/env julia using Literate Literate.markdown(@__FILE__, pwd(), documenter=true) ` `` # Intro ## Plot ` ``@example literate_example using Plots, DataFrames plot(rand(5,5), linewidth=2, title="My Plot", size = (500, 200)) ` `` ## Some computational results ` ``@example literate_example rand(2, 3) DataFrame(rand(2, 3)) ` `` *This page was generated using [Literate.jl](https://github.com/fredrikekre/Literate.jl).*
Les insertions de code à l'intérieur du marquage sont délibérément placées avec un espace entre la première et les apostrophes suivantes, afin de ne pas se gâcher lorsque l'article est publié.
Voir plus de détails https://fredrikekre.imtqy.com/Literate.jl/stable/
Documenter.jl
Générateur de documentation. Son objectif principal est de former une documentation lisible pour les packages écrits en Julia. Documenter convertit les exemples html ou pdf avec le balisage Markdown et le code Julia intégré, ainsi que les fichiers source du module, extrayant Julia-docstrings (les propres commentaires de Julia).
Un exemple de documentation typique:

Dans cet article, nous ne nous attarderons pas sur les principes de la documentation, car, dans le bon sens, cela devrait être fait dans le cadre d'un article séparé sur le développement des modules. Cependant, nous examinerons ici certains aspects de Documenter.
Tout d'abord, il convient de prêter attention au fait que l'écran est divisé en deux parties - le côté gauche contient une table des matières interactive. Le côté droit est, en fait, le texte de la documentation.
Une structure de répertoire typique avec des exemples et de la documentation est la suivante:
docs/ src/ make.jl src/ Example.jl ...
Le répertoire docs/src est la documentation de démarquage. Et des exemples se trouvent quelque part dans le répertoire source partagé src .
Le fichier clé pour Docuementer est docs/make.jl Le contenu de ce fichier pour le Documenter lui-même:
using Documenter, DocumenterTools makedocs( modules = [Documenter, DocumenterTools], format = Documenter.HTML( # Use clean URLs, unless built as a "local" build prettyurls = !("local" in ARGS), canonical = "https://juliadocs.imtqy.com/Documenter.jl/stable/", ), clean = false, assets = ["assets/favicon.ico"], sitename = "Documenter.jl", authors = "Michael Hatherly, Morten Piibeleht, and contributors.", analytics = "UA-89508993-1", linkcheck = !("skiplinks" in ARGS), pages = [ "Home" => "index.md", "Manual" => Any[ "Guide" => "man/guide.md", "man/examples.md", "man/syntax.md", "man/doctests.md", "man/latex.md", hide("man/hosting.md", [ "man/hosting/walkthrough.md" ]), "man/other-formats.md", ], "Library" => Any[ "Public" => "lib/public.md", hide("Internals" => "lib/internals.md", Any[ "lib/internals/anchors.md", "lib/internals/builder.md", "lib/internals/cross-references.md", "lib/internals/docchecks.md", "lib/internals/docsystem.md", "lib/internals/doctests.md", "lib/internals/documenter.md", "lib/internals/documentertools.md", "lib/internals/documents.md", "lib/internals/dom.md", "lib/internals/expanders.md", "lib/internals/mdflatten.md", "lib/internals/selectors.md", "lib/internals/textdiff.md", "lib/internals/utilities.md", "lib/internals/writers.md", ]) ], "contributing.md", ], ) deploydocs( repo = "github.com/JuliaDocs/Documenter.jl.git", target = "build", )
Comme vous pouvez le voir, les principales méthodes ici sont makedocs et deploydocs , qui déterminent la structure de la future documentation et le lieu de son placement. makedocs fournit la formation d'un balisage de démarque à partir de tous les fichiers spécifiés, ce qui inclut à la fois l'exécution de code intégré et l'extraction de commentaires docstrings.
Documenter prend en charge un certain nombre de directives pour l'insertion de code. Leur format est `` @something
@docs , @autodocs - liens vers la documentation docstrings extraite des fichiers Julia.@ref , @meta , @index , @contents - liens, indications de pages d'index, etc.@example , @repl , @eval - modes d'exécution du code Julia intégré.- ...
La présence des directives @example, @repl, @eval , en fait, a déterminé s'il fallait ou non inclure Documenter dans cette vue d'ensemble. De plus, le Literate.jl mentionné précédemment peut générer automatiquement un tel balisage, comme cela a été démontré précédemment. Autrement dit, il n'y a aucune restriction fondamentale à l'utilisation du générateur de documentation comme générateur de rapport.
Pour plus d'informations sur Documenter.jl, voir https://juliadocs.imtqy.com/Documenter.jl/stable/
Conclusion
Malgré la jeunesse de la langue Julia, les packages et les outils déjà développés pour celle-ci nous permettent de parler de la pleine utilisation dans des services très chargés, et pas seulement de la mise en œuvre de projets d'essai. Comme vous pouvez le voir, la possibilité de générer divers documents et rapports, y compris les résultats de l'exécution de code à la fois sous forme de texte et de graphique, est déjà fournie. De plus, selon la complexité du rapport, nous pouvons choisir entre la facilité de création d'un modèle et la flexibilité de génération de rapports.
L'article ne considère pas le générateur Flax du package Genie.jl. Genie.jl est une tentative d'implémentation de Julia on Rails, et Flax est une sorte d'analogue d'eRubis avec des insertions de code pour Julia. Cependant, Flax n'est pas fourni en tant que package séparé, et Genie n'est pas inclus dans le référentiel de packages principal, il n'a donc pas été inclus dans cette revue.
Séparément, je voudrais mentionner les packages Makie.jl et Luxor.jl , qui fournissent la formation de visualisations vectorielles complexes. Le résultat de leur travail peut également être utilisé dans le cadre de rapports, mais un article séparé devrait également être écrit à ce sujet.
Les références