
Des documents scandaleux, importants et simplement très cool ne sont pas publiés dans les médias tous les jours, et aucun éditeur ne s'engage à prédire le succès d'un article avec une précision de 100%. Le maximum que l'équipe a est au niveau instinctif pour dire du matériel «fort» ou «ordinaire». C’est tout. Commence alors la magie imprévisible des médias, grâce à laquelle l'article peut atteindre le sommet des résultats de recherche avec des dizaines de liens provenant d'autres publications ou le matériel sombrera dans l'oubli. Et juste dans le cas de la publication d'articles sympas, les sites médiatiques tombent périodiquement sous un afflux monstrueux d'utilisateurs, que nous appelons modestement «l'habraeffet».
Cet été, le site Internet de la
République a été victime du professionnalisme de ses propres auteurs: des articles sur le thème de la réforme des retraites, de l'éducation scolaire et d'une bonne nutrition ont réuni au total plusieurs millions de lecteurs. La publication de chacun des documents mentionnés a conduit à des charges si élevées que jusqu'à la chute du site Internet de la République, il restait absolument «un peu d'espace». L'administration s'est rendu compte qu'il fallait changer quelque chose: il fallait changer la structure du projet de telle sorte qu'il puisse réagir vigoureusement aux changements des conditions de travail (principalement la charge externe), tout en restant pleinement fonctionnel et accessible aux lecteurs même en cas de sauts très brusques de fréquentation. Et un grand bonus serait l'intervention manuelle minimale de l'équipe technique de la République à ces moments.
Sur la base des résultats d'une discussion conjointe avec des experts de la République sur les différentes options de mise en œuvre de la liste de souhaits exprimée, nous avons décidé de transférer le site Web de la publication à Kubernetes *. À propos de ce que tout cela nous a coûté à tous, et ce sera l'histoire d'aujourd'hui.
* Pendant le déménagement, pas un seul spécialiste technique républicain n'a été blesséÀ quoi il ressemblait en termes généraux
Tout a commencé, bien sûr, par des négociations sur la manière dont tout se passera «maintenant» et «plus tard». Malheureusement, le paradigme moderne du marché informatique implique que dès qu'une entreprise se retire pour une sorte de solution d'infrastructure, elle la transforme en liste de prix de service clé en main. Il semblerait que le travail soit «clé en main» - quoi de plus agréable et de plus agréable qu'un directeur conditionnel ou un propriétaire d'entreprise? J'ai payé et ma tête ne me fait pas de mal: planification, développement, assistance - tout est là, du côté de l'entrepreneur, l'entreprise ne peut que gagner de l'argent pour payer un service aussi agréable.
Cependant, le transfert complet de l'infrastructure informatique n'est pas toujours approprié pour le client à long terme. Il est plus correct à tous points de vue de travailler en une seule grande équipe, de sorte qu'après la fin du projet, le client comprenne comment vivre avec la nouvelle infrastructure et que les collègues de l'atelier ne se posent pas la question "oh, qu'est-ce que c'était jusqu'ici?" après signature du certificat d'achèvement et démonstration des résultats. Les gars de la République étaient du même avis. En conséquence, pendant deux mois, nous avons atterri un atterrissage de quatre personnes au client, qui a non seulement réalisé notre idée, mais aussi des spécialistes techniquement formés du côté de la République pour poursuivre le travail et l'existence dans les réalités de Kubernetes.
Et toutes les parties en ont profité: nous avons rapidement terminé le travail, gardé nos spécialistes prêts pour de nouvelles réalisations et obtenu que Republic en tant que client bénéficie d'un soutien consultatif avec nos propres ingénieurs. La publication, en revanche, a reçu une nouvelle infrastructure adaptée aux «habraeffects», son propre personnel de spécialistes techniques retenu et la possibilité de demander de l'aide si nécessaire.
Nous préparons une tête de pont
"Détruire - pas construire." Ce dicton s'applique à tout. Bien sûr, la solution la plus simple semble être la prise en otage de l'infrastructure du client mentionnée précédemment et l'enchaînement, le client à lui-même, ou l'overclocking du personnel existant et la nécessité d'engager un gourou des nouvelles technologies. Nous sommes allés le troisième, pas le moyen le plus populaire aujourd'hui, et avons commencé par la formation des ingénieurs de la République.
Vers le début, nous avons vu une telle solution pour assurer le fonctionnement du site:
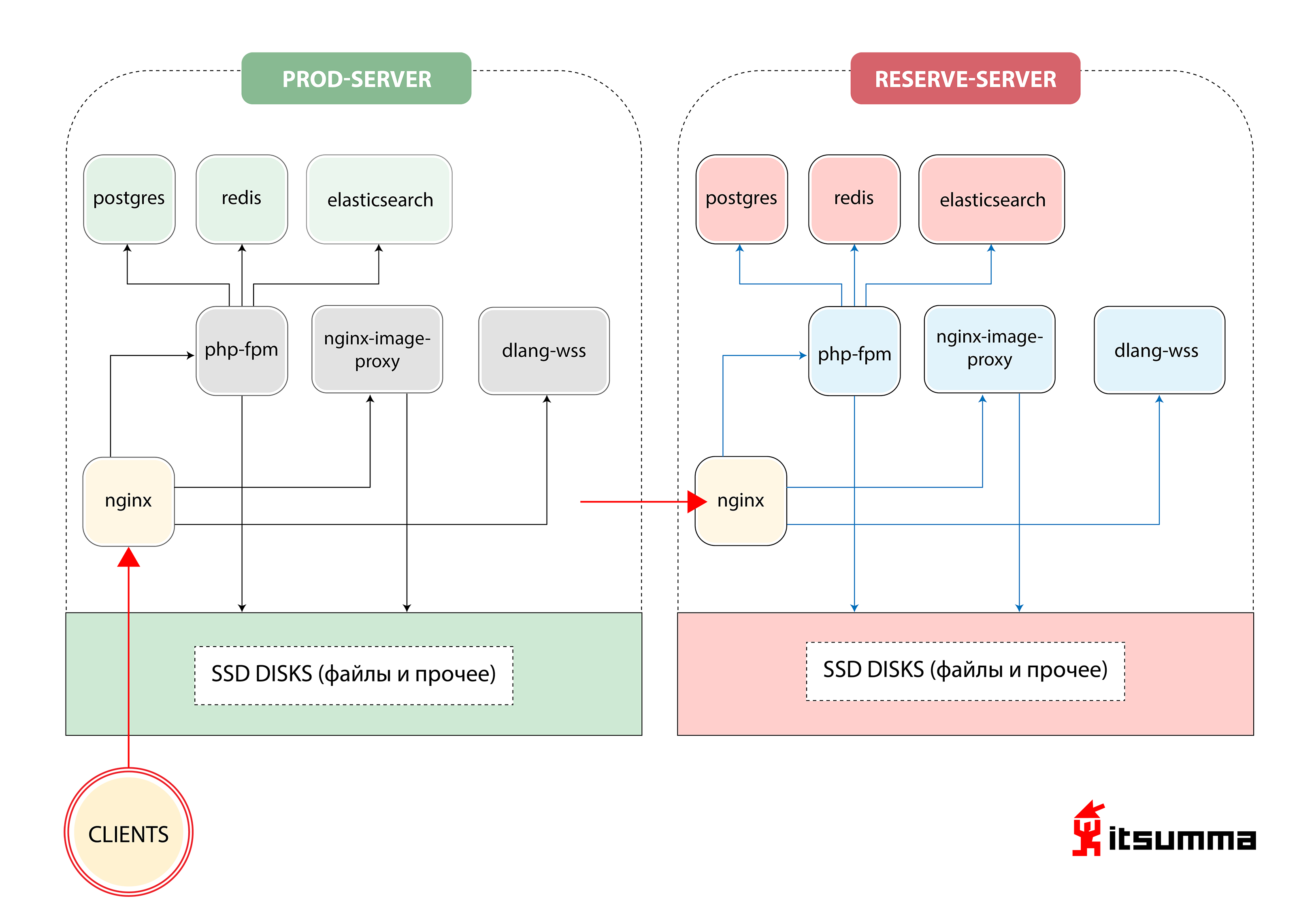
Autrement dit, Republic n'avait que deux serveurs de fer - le principal et la sauvegarde, la sauvegarde. La chose la plus importante pour nous a été de réaliser un changement de paradigme dans la pensée des spécialistes techniques du client, car auparavant, ils traitaient d'un groupe très simple de NGINX, PHP-fpm et PostgreSQL. Ils étaient désormais confrontés à l'architecture de conteneur évolutive de Kubernetes. Donc, tout d'abord, nous avons basculé le développement de Republic local vers l'environnement docker-compose. Et ce n'était que la première étape.
Avant notre arrivée, les développeurs de Republic ont conservé leur environnement de travail local dans des machines virtuelles configurées via Vagrant, ou ont travaillé directement avec le serveur de développement via sftp. Sur la base de l'image de base générale d'une machine virtuelle, chaque développeur a «préconfiguré» sa machine «pour lui-même», ce qui a donné lieu à un ensemble de configurations différentes. À la suite de cette approche, l'inclusion de nouvelles personnes dans l'équipe a augmenté de façon exponentielle le temps d'entrée dans le projet.
Dans les nouvelles réalités, nous avons offert à l'équipe une structure plus transparente de l'environnement de travail. Il a décrit de manière déclarative quels logiciels et quelles versions sont nécessaires pour le projet, l'ordre des connexions et les interactions entre les services (applications). Cette description a été téléchargée dans un référentiel git séparé afin qu'elle puisse être gérée de manière pratique et centralisée.
Toutes les applications nécessaires ont commencé à s'exécuter dans des conteneurs Docker séparés - et c'est un site php régulier avec nginx, beaucoup de statiques, des services pour travailler avec des images (redimensionnement, optimisation, etc.), et ... un service séparé pour les sockets web écrit en D Tous les fichiers de configuration (nginx-conf, php-conf ...) font également partie de la base de code du projet.
En conséquence, l'environnement local a été complètement "recréé", complètement identique à l'infrastructure actuelle du serveur. Ainsi, le temps nécessaire pour maintenir le même environnement à la fois sur les machines locales des développeurs et sur le prod a été réduit. Ce qui, à son tour, a grandement contribué à éviter des problèmes complètement inutiles causés par les configurations locales auto-écrites de chaque développeur.
En conséquence, les services suivants ont été générés dans l'environnement docker-compose:
- Web pour l'application php-fpm;
- nginx;
- impproxy et cairosvg (services pour travailler avec des images);
- postgres
- redis;
- recherche élastique;
- trompette (le même service pour les sockets web sur D).
Du point de vue des développeurs, le travail avec la base de code est resté inchangé - il a été monté dans les services nécessaires à partir d'un répertoire séparé (le référentiel de base avec le code du site) dans les services nécessaires: le répertoire public dans le service nginx, tout le code d'application php dans le service php-fpm. À partir du répertoire séparé (qui contient toutes les configurations d'environnement de composition), les fichiers de configuration correspondants sont montés dans les services nginx et php-fpm. Les répertoires avec postgres de données, elasticsearch et redis sont également montés sur la machine locale du développeur, de sorte que si tous les conteneurs doivent être reconstruits / supprimés, les données de ces services ne seront pas perdues.
Pour travailler avec les journaux d'application - également dans l'environnement Docker-compose - les services de la pile ELK ont été augmentés. Auparavant, une partie des journaux des applications était écrite dans le fichier standard / var / log / ..., les journaux des applications php et les exécutions étaient écrits dans Sentry, et cette option de stockage de journaux "décentralisé" était extrêmement difficile à utiliser. Désormais, les applications et les services ont été configurés et affinés pour interagir avec la pile ELK. L'utilisation des journaux est devenue beaucoup plus facile; les développeurs disposent désormais d'une interface pratique pour rechercher et filtrer les journaux. À l'avenir (déjà dans le cube) - vous pouvez regarder les journaux d'une version spécifique de l'application (par exemple, un kronzhoba lancé avant-hier).
De plus, l'équipe de la République a commencé une courte période d'adaptation. L'équipe devait comprendre et apprendre à travailler dans le nouveau paradigme de développement, dans lequel les éléments suivants devraient être pris en compte:
- Les applications deviennent sans état, et elles peuvent perdre des données à tout moment, donc travailler avec des bases de données, des sessions, des fichiers statiques doit être construit différemment. Les sessions PHP doivent être stockées de manière centralisée et partagées entre toutes les instances d'application. Il peut s'agir de fichiers, mais le plus souvent, redis est utilisé à ces fins en raison de sa plus grande facilité de gestion. Les conteneurs pour les bases de données doivent «monter» un datadir ou la base de données doit être exécutée en dehors de l'infrastructure de conteneur.
- Un stockage de fichiers d'environ 50 à 60 Go d'images ne doit pas se trouver «dans l'application Web». À ces fins, il est nécessaire d'utiliser du stockage externe, des systèmes cdn, etc.
- Toutes les applications (bases de données, serveurs d'applications ...) sont désormais des «services» distincts, et l'interaction entre elles doit être configurée par rapport au nouvel espace de noms.
Une fois que l'équipe de développement de Republic s'est habituée aux innovations, nous avons commencé à transférer l'infrastructure de vente de la publication à Kubernetes.
Et voici Kubernetes
Sur la base de l'environnement conçu pour le développement local de docker-compose, nous avons commencé à traduire le projet en un "cube". Tous les services sur lesquels le projet est construit localement, nous avons "emballé dans des conteneurs": nous avons organisé une procédure linéaire et compréhensible pour la construction d'applications, le stockage de configurations, la compilation de statiques. Du point de vue du développement, ils ont supprimé les paramètres de configuration dont nous avions besoin dans les variables d'environnement, ont commencé à stocker les sessions non pas dans des fichiers, mais dans des radis. Nous avons augmenté l'environnement de test, où nous avons déployé une version fonctionnelle du site.
Comme il s'agit d'un ancien projet monolithique, il est évident qu'il y avait une relation difficile entre les versions frontend et backend, respectivement, et ces deux composants ont été déployés en même temps. Par conséquent, nous avons décidé de construire les pods de l'application Web de manière à ce que deux conteneurs tournent dans un pod: php-fpm et nginx.
Nous avons également construit une mise à l'échelle automatique afin que les applications Web soient mises à l'échelle jusqu'à un maximum de 12 au pic de trafic, définissez certains tests de vivacité / de préparation, car l'application nécessite au moins 2 minutes pour s'exécuter (car vous devez réchauffer le cache, générer des configurations ...)
Immédiatement, bien sûr, il y avait toutes sortes de bancs et de nuances. Par exemple: la statique compilée était nécessaire à la fois pour le serveur Web qui la distribuait et pour le serveur d'applications sur fpm, qui quelque part à la volée générait une sorte d'images, quelque part svg donnait directement au code. Nous avons réalisé que pour ne pas se lever deux fois, nous devons créer un conteneur de construction intermédiaire et conteneuriser l'assemblage final en plusieurs étapes. Pour ce faire, nous avons créé plusieurs conteneurs intermédiaires, dans chacun desquels les dépendances sont extraites séparément, puis les statiques (css et js) sont collectées séparément, puis dans deux conteneurs - en nginx et en fpm - elles sont copiées à partir du conteneur de build intermédiaire.
Nous commençons
Pour travailler avec des fichiers lors de la première itération, nous avons créé un répertoire commun synchronisé avec toutes les machines en fonctionnement. Par le mot «synchronisé», je veux dire ici exactement ce que vous pouvez penser avec horreur en premier lieu - rsync dans un cercle. De toute évidence, une mauvaise décision. En conséquence, nous avons obtenu tout l'espace disque sur GlusterFS, configuré le travail avec les images afin qu'elles soient toujours accessibles à partir de n'importe quelle machine et que rien ne ralentisse. Pour l'interaction de nos applications avec les systèmes de stockage (postgres, elasticsearch, redis), les services externalName ont été créés dans k8s, de sorte que, par exemple, en cas de passage urgent à la base de données de sauvegarde, mettez à jour les paramètres de connexion en un seul endroit.
Tout le travail avec les crones a été transféré aux nouvelles entités k8s - cronjob, qui peuvent fonctionner selon un calendrier spécifique.
En conséquence, nous avons obtenu cette architecture:
 Cliquable
CliquableOh difficile
Ce fut le lancement de la première version, car parallèlement à la restructuration complète de l'infrastructure, le site était toujours en cours de refonte. Une partie du site a été construite avec certains paramètres - pour la statique et tout le reste, et une partie - avec d'autres. Là, il fallait ... pour le moins ... pervertir avec tous ces conteneurs à plusieurs étages, copier les données d'eux dans un ordre différent, etc.
Nous avons également dû danser avec des tambourins autour du système CI \ CD afin d'enseigner tout cela à déployer et à contrôler à partir de différents référentiels et d'environnements différents. Après tout, un contrôle constant des versions des applications est nécessaire afin que vous puissiez comprendre quand un service ou un autre service a été déployé et avec quelle version de l'application une ou une autre erreur a commencé. Pour ce faire, nous avons mis en place le système de journalisation correct (ainsi que la culture de journalisation elle-même) et implémenté ELK. Les collègues ont appris à définir certains sélecteurs, à voir quel cron génère quelles erreurs, comment il est généralement exécuté, car dans le «cube» après l'exécution du conteneur de cron, vous n'y entrerez plus.
Mais la chose la plus difficile pour nous a été de retravailler et de réviser l'intégralité de la base de code.
Je vous rappelle que Republic est un projet qui a maintenant 10 ans. Cela a commencé avec une équipe, une autre se développe maintenant, et il est vraiment difficile de pelleter tous les codes source pour d'éventuels bugs et erreurs. Bien sûr, en ce moment, notre groupe d'atterrissage de quatre personnes a connecté les ressources du reste de l'équipe: nous avons cliqué et testé l'ensemble du site avec des tests, même dans les sections que les gens vivants n'avaient pas visités depuis 2016.
Aucun échec partout
Lundi, tôt le matin, lorsque les gens sont allés au mailing de masse avec un résumé, nous avons tous eu un pieu. Le coupable a été trouvé assez rapidement: cronjob a commencé et a commencé frénétiquement à envoyer des lettres à tous ceux qui voulaient obtenir une sélection de nouvelles au cours de la semaine dernière, dévorant les ressources de l'ensemble du cluster en cours de route. Nous ne pouvions pas accepter un tel comportement, nous avons donc rapidement mis des limites strictes sur toutes les ressources: la quantité de processeur et de mémoire qu'un conteneur peut consommer, etc.
Comment l'équipe de développeurs de la République a-t-elle fait face
Nos activités ont apporté beaucoup de changements et nous l'avons compris. En fait, nous avons non seulement redessiné l'infrastructure de la publication, au lieu du bundle habituel «serveur de sauvegarde principal», implémenté une solution de conteneur, qui, si nécessaire, connectait des ressources supplémentaires, mais a également complètement changé l'approche de développement.
Après un certain temps, les gars ont commencé à comprendre que cela ne fonctionnait pas directement avec du code, mais avec une application abstraite. Compte tenu des processus CI \ CD (construits sur Jenkins), ils ont commencé à écrire des tests, ils ont obtenu des environnements de développement de stade à part entière où ils peuvent tester de nouvelles versions de leur application en temps réel, voir où tout tombe et apprendre à vivre nouveau monde idéal.
Qu'a obtenu le client
Tout d'abord, Republic a enfin obtenu un processus de déploiement contrôlé! Auparavant, dans la République, il y avait un responsable qui est allé sur le serveur, a tout démarré manuellement, puis collecté des statistiques, vérifié avec ses mains que rien n'était tombé ... Maintenant, le processus de déploiement est construit de sorte que les développeurs soient engagés dans le développement et ne perdent pas de temps sur autre chose . Et la personne responsable a maintenant une tâche - surveiller comment la libération s'est déroulée en général.
Après un push vers la branche maître, soit automatiquement, soit par un déploiement par «bouton-poussoir» (périodiquement, en raison de certaines exigences métier, le déploiement automatique est désactivé), Jenkins entre dans la mêlée: l'assemblage du projet commence. Tout d'abord, tous les conteneurs docker sont assemblés: des dépendances (compositeur, fil, npm) sont installées dans les conteneurs préparatoires, ce qui vous permet d'accélérer le processus de construction si la liste des bibliothèques requises n'a pas changé pendant le déploiement; puis des conteneurs pour php-fpm, nginx, d'autres services sont collectés, dans lesquels, par analogie avec l'environnement docker-compose, seules les parties nécessaires de la base de code sont copiées. Après cela, les tests sont lancés et, en cas de réussite des tests, il y a une poussée d'images vers le magasin privé et, en fait, le déploiement des déploiements dans le cuber.
Grâce au transfert de Republic vers k8s, nous avons obtenu une architecture utilisant un cluster de trois machines réelles sur lesquelles jusqu'à douze copies de l'application web peuvent «tourner» en même temps. Dans le même temps, le système lui-même, en fonction des charges actuelles, décide du nombre de copies dont il a besoin actuellement. Nous avons pris Republic de la loterie «fonctionne - ne fonctionne pas» avec des serveurs statiques primaires et de secours et avons construit un système flexible pour eux, prêt pour une augmentation semblable à une avalanche de la charge sur le site.
À ce moment, la question peut se poser "les gars, vous avez changé deux morceaux de fer pour les mêmes morceaux de fer, mais avec la virtualisation, quel est le gain, êtes-vous bien là?" Et, bien sûr, ce sera logique. Mais seulement en partie. En conséquence, nous n'avons pas obtenu uniquement des pièces de matériel avec virtualisation. Nous avons eu un environnement de travail stable, le même dans la nourriture et la vierge. Un environnement géré de manière centralisée pour tous les participants au projet. Nous avons obtenu un mécanisme pour assembler l'ensemble du projet et déployer les versions, encore une fois, le même pour tout le monde. Nous avons obtenu un système d'orchestration de projet pratique. Dès que l'équipe de la République constate qu'ils cessent généralement d'avoir suffisamment de ressources actuelles et les risques de charges ultra-élevées (ou quand c'est déjà arrivé et que tout est réglé), ils prennent juste un autre serveur, en 10 minutes déploient le rôle d'un nœud de cluster dessus, et op-op tout est beau et bon à nouveau. La structure précédente du projet ne suggérait pas du tout une telle approche; il n'y avait ni solution lente ni rapide à de tels problèmes.
Deuxièmement, un déploiement transparent est apparu: le visiteur pourra soit accéder à l'ancienne version de l'application, soit à une nouvelle. Et pas comme avant, quand le contenu pourrait être nouveau, mais les styles sont anciens.
En conséquence, l'entreprise est satisfaite: toutes sortes de nouvelles choses peuvent désormais être réalisées plus rapidement et plus souvent.
Au total, de «mais essayons» à «terminé», le travail sur le projet a duré 2 mois. L'équipe de notre part est un atterrissage héroïque de quatre personnes + soutien à la "base" lors de la vérification du code et des tests.
Ce que les utilisateurs ont
Et les visiteurs, en principe, n'ont pas vu les changements. Le processus de déploiement de la stratégie de RollingUpdate est construit «de manière transparente». Le déploiement d'une nouvelle version du site ne nuit en rien aux utilisateurs, la nouvelle version du site, jusqu'à ce que les tests réussissent et les tests de vivacité / préparation, ne sera pas disponible. Ils voient simplement que le site fonctionne et qu'il ne tombera pas après avoir publié des articles sympas. C'est en général ce dont tout projet a besoin.