Nous sommes Big Data chez MTS et c'est notre premier article. Aujourd'hui, nous allons parler des technologies qui nous permettent de stocker et de traiter les mégadonnées afin qu'il y ait toujours suffisamment de ressources pour l'analyse, et que le coût d'achat du fer n'atteigne pas des distances très élevées.
Ils ont pensé à créer le centre Big Data chez MTS en 2014: il était nécessaire de faire évoluer le stockage analytique classique et le reporting BI. À cette époque, le moteur de traitement des données et de BI était SAS - cela s'est produit historiquement. Et bien que les besoins de stockage de l'entreprise aient été fermés, au fil du temps, les fonctionnalités de BI et d'analytique ad hoc au-dessus du stockage analytique ont tellement augmenté qu'il était nécessaire de résoudre le problème de l'augmentation de la productivité, étant donné qu'au fil des ans, le nombre d'utilisateurs a décuplé et a continué de croître.
À la suite du concours, le système Teradata MPP est apparu dans MTS, couvrant les besoins des télécommunications à l'époque. Ce fut l'impulsion pour essayer quelque chose de plus populaire et open source.
 Sur la photo - l'équipe Big Data MTS dans le nouveau bureau Descartes à Moscou
Sur la photo - l'équipe Big Data MTS dans le nouveau bureau Descartes à Moscou Le premier cluster était de 7 nœuds. Cela a suffi pour tester plusieurs hypothèses commerciales et bourrer les premières bosses. Les efforts n'ont pas été vains: le Big Data existe dans MTS depuis trois ans et maintenant l'analyse des données est impliquée dans presque tous les domaines fonctionnels. L'équipe est passée de trois à deux cents.
Nous voulions avoir des processus de développement simples, tester rapidement des hypothèses. Pour ce faire, vous avez besoin de trois choses: une équipe avec une pensée de démarrage, des processus de développement légers et une infrastructure développée. Il y a beaucoup d'endroits où vous pouvez lire et écouter le premier et le deuxième, mais cela vaut la peine de parler de l'infrastructure développée séparément, car les sources héritées et de données qui se trouvent dans les télécommunications sont importantes ici. Une infrastructure de données développée ne construit pas seulement un lac de données, une couche de données détaillées et une couche vitrine. Il comprend également des outils et des interfaces d'accès aux données, l'isolement des ressources informatiques pour les produits et les commandes, des mécanismes pour fournir des données aux consommateurs - en temps réel et en mode batch. Et bien plus encore.
Tous ces travaux se sont démarqués dans un domaine distinct, engagé dans le développement d'utilitaires et d'outils de données. Ce domaine est appelé la plate-forme informatique Big Data.
D'où vient le Big Data dans MTS
MTS possède de nombreuses sources de données. L'une des principales est les stations de base; nous desservons la base d'abonnés de plus de 78 millions d'abonnés en Russie. Nous avons également de nombreux services qui ne sont pas liés aux télécommunications et vous permettent de recevoir des données plus polyvalentes (commerce électronique, intégration de systèmes, Internet des objets, services cloud, etc. - l'ensemble des «non-télécommunications» rapporte déjà environ 20% de tous les revenus).
En bref, notre architecture peut être représentée comme un graphique:
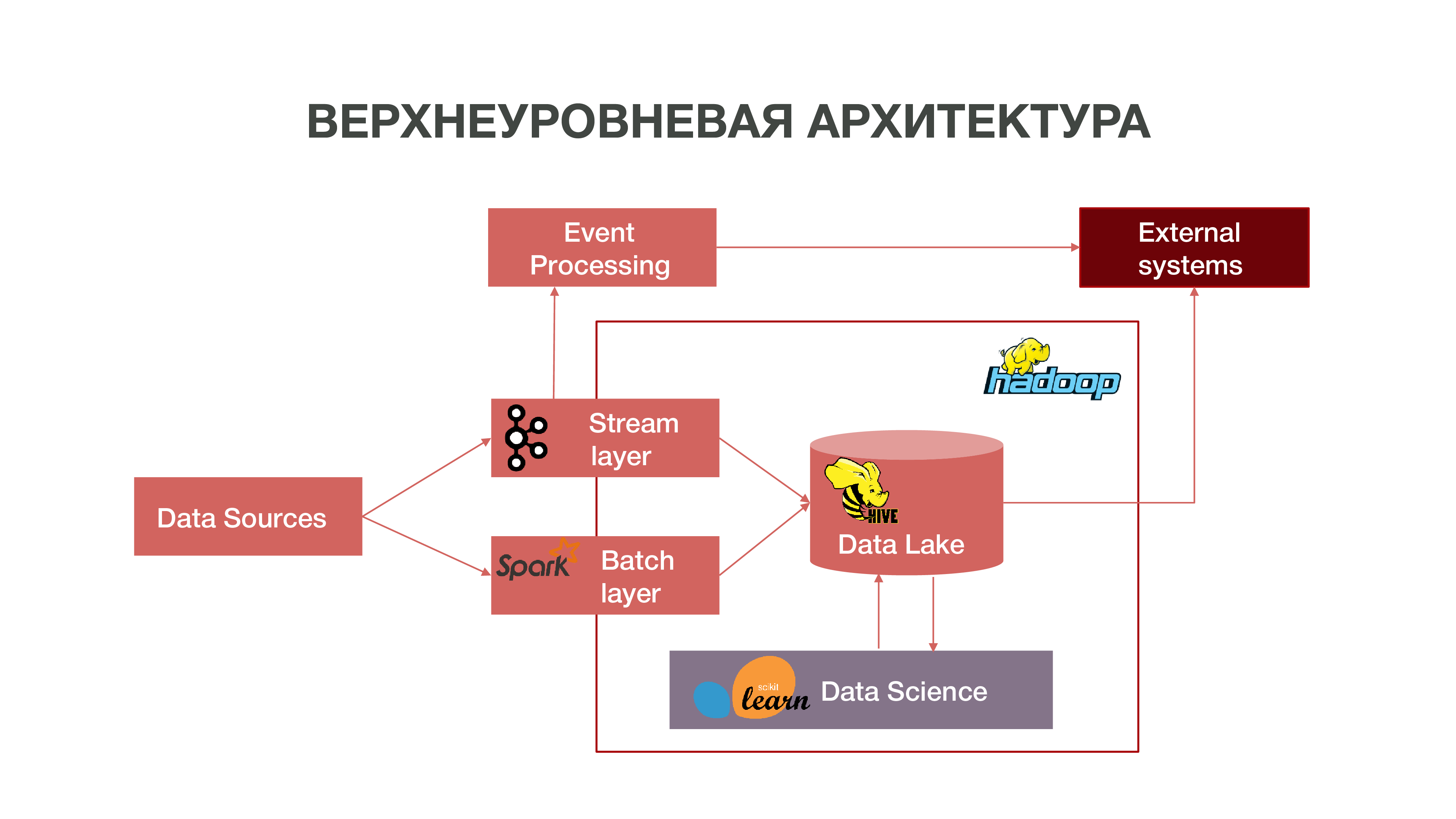
Comme vous pouvez le voir sur le graphique, les sources de données peuvent fournir des informations en temps réel. Nous utilisons la couche de flux - nous pouvons traiter des informations en temps réel, en extraire certains événements qui nous intéressent et construire des analyses à ce sujet. Afin de fournir un tel traitement d'événements, nous avons développé une implémentation assez standard (du point de vue de l'architecture) utilisant Apache Kafka, Apache Spark et du code en langage Scala. Les informations obtenues à la suite d'une telle analyse peuvent être consommées aussi bien à l'intérieur de MTS qu'à l'avenir: les entreprises sont souvent intéressées par le fait même de certaines actions des abonnés.
Il existe également un mode de chargement des données par lots - couche batch. Habituellement, le téléchargement a lieu une fois par heure selon un calendrier, nous utilisons Apache Airflow comme planificateur et les processus de téléchargement par lots eux-mêmes sont implémentés en python. Dans ce cas, une quantité beaucoup plus importante de données est chargée dans Data Lake, ce qui est nécessaire pour remplir les Big Data avec des données historiques, sur lesquelles nos modèles Data Science doivent être formés. En conséquence, un profil d'abonné est formé dans le contexte historique sur la base de données sur son activité réseau. Cela nous permet d'obtenir des statistiques prédictives et de construire des modèles de comportement humain, voire de créer un portrait psychologique de lui - nous avons un produit distinct. Ces informations sont très utiles, par exemple, pour les sociétés de marketing.
Nous avons également une grande quantité de données qui composent le référentiel classique. Autrement dit, nous regroupons les informations sur divers événements - à la fois utilisateur et réseau. Toutes ces données anonymisées aident également à prédire avec plus de précision les intérêts et les événements des utilisateurs qui sont importants pour l'entreprise - par exemple, pour prédire les pannes d'équipement possibles et dépanner à temps.
Hadoop
Si vous regardez le passé et vous rappelez comment les mégadonnées sont apparues en général, il convient de noter que, fondamentalement, l'accumulation de données a été effectuée à des fins de marketing. Il n'y a pas de définition aussi claire de ce qu'est le big data - ce sont des gigaoctets, des téraoctets, des pétaoctets. Impossible de tracer une ligne. Pour certains, les mégadonnées représentent des dizaines de gigaoctets, pour d'autres, des pétaoctets.
Il se trouve qu'au fil du temps, beaucoup de données se sont accumulées dans le monde. Et pour mener une sorte d'analyse plus ou moins significative de ces données, les référentiels habituels qui se développent depuis les années 70 du siècle dernier ne suffisent plus. Lorsque le puits d'information a commencé dans les années 2000, 10 et lorsqu'il y avait beaucoup d'appareils qui avaient accès à Internet, lorsque l'Internet des objets est apparu, ces référentiels ne pouvaient tout simplement pas faire face conceptuellement. La base de ces référentiels était la théorie relationnelle. Autrement dit, il y avait des relations de formes différentes qui interagissaient les unes avec les autres. Il y avait un système pour décrire comment construire et concevoir des référentiels.
Lorsque les anciennes technologies échouent, de nouvelles apparaissent. Dans le monde moderne, le problème de l'analyse des mégadonnées est résolu de deux manières:
Créer votre propre framework qui vous permet de traiter de grandes quantités d'informations. Il s'agit généralement d'une application distribuée de plusieurs centaines de milliers de serveurs - comme Google, Yandex, qui ont créé leurs propres bases de données distribuées qui vous permettent de travailler avec un tel volume d'informations.
Le développement de la technologie Hadoop est un cadre informatique distribué, un système de fichiers distribué qui peut stocker et traiter une très grande quantité d'informations. Les outils de Data Science sont principalement compatibles avec Hadoop et cette compatibilité ouvre de nombreuses possibilités pour une analyse avancée des données. De nombreuses entreprises, dont nous, évoluent vers l'écosystème open source Hadoop.
Le cluster central Hadoop est situé à Nizhny Novgorod. Il accumule des informations de presque toutes les régions du pays. En termes de volume, environ 8,5 pétaoctets de données peuvent désormais y être téléchargés. Toujours à Moscou, nous avons des grappes RND distinctes où nous menons des expériences.
Étant donné que nous avons environ un millier de serveurs dans différentes régions, où nous effectuons des analyses, ainsi qu'une expansion est prévue, la question se pose du bon choix d'équipement pour les systèmes analytiques distribués. Vous pouvez acheter un équipement suffisant pour le stockage de données, mais qui s'avère inapproprié pour l'analyse - tout simplement parce qu'il n'y aura pas suffisamment de ressources, le nombre de cœurs de processeur et de RAM libre sur les nœuds. Il est important de trouver un équilibre afin d'obtenir de bonnes opportunités d'analyse et des coûts d'équipement peu élevés.
Intel nous a proposé différentes options sur la façon d'optimiser le travail avec un système distribué afin que l'analyse de notre volume de données puisse être obtenue pour un prix raisonnable. Intel fait progresser la technologie des disques SSD NAND SSD Il est des centaines de fois plus rapide qu'un disque dur ordinaire. C'est bon pour nous: le SSD, en particulier avec l'interface NVMe, fournit un accès assez rapide aux données.
De plus, Intel a publié des SSD pour serveurs Intel Optane SSD basés sur le nouveau type de mémoire non volatile Intel 3D XPoint. Ils supportent des charges mixtes intensives sur le système de stockage et ont une ressource plus longue que les SSD NAND ordinaires. Pourquoi est-ce bon pour nous: le SSD Intel Optane vous permet de travailler de manière stable sous de lourdes charges avec une faible latence. Nous avons initialement considéré le SSD NAND comme un remplacement pour les disques durs traditionnels, car nous avons une très grande quantité de données se déplaçant entre le disque dur et la RAM - et nous devions optimiser ces processus.
Premier test
Le premier test que nous avons effectué en 2016. Nous avons juste pris et essayé de remplacer le disque dur par un SSD NAND rapide. Pour ce faire, nous avons commandé des échantillons du nouveau disque Intel - à l'époque c'était le DC P3700. Et ils ont exécuté le test standard de Hadoop - un écosystème qui vous permet d'évaluer l'évolution des performances dans différentes conditions. Ce sont des tests standardisés TeraGen, TeraSort, TeraValidate.

TeraGen vous permet de "générer" des données artificielles d'un certain volume. Par exemple, nous avons pris 1 Go et 1 To. Avec TeraSort, nous avons trié cette quantité de données dans Hadoop. Il s'agit d'une opération assez gourmande en ressources. Et le dernier test - TeraValidate - vous permet de vous assurer que les données sont triées dans le bon ordre. Autrement dit, nous les parcourons une deuxième fois.

À titre expérimental, nous avons pris des voitures uniquement avec des SSD - c'est-à-dire que Hadoop n'était installé que sur des SSD sans utiliser de disques durs. Dans la deuxième version, nous avons utilisé SSD pour stocker des fichiers temporaires, HDD - pour stocker des données de base. Et dans la troisième version, des disques durs étaient utilisés pour les deux.
Les résultats de ces expériences ne nous ont pas beaucoup plu, car la différence dans les indicateurs de performance n'a pas dépassé 10-20%. Autrement dit, nous avons réalisé que Hadoop n'est pas très convivial avec les SSD en termes de stockage, car au départ, le système a été créé pour stocker de grandes données sur le disque dur, et personne ne l'a optimisé en particulier pour les SSD rapides et coûteux. Et comme le coût du SSD à cette époque était assez élevé, nous avons décidé jusqu'à présent de ne pas entrer dans cette histoire et de nous en sortir avec les disques durs.
Deuxième test
Ensuite, Intel a introduit de nouveaux SSD Intel Optane côté serveur basés sur la mémoire 3D XPoint. Ils ont été publiés fin 2017, mais les échantillons étaient disponibles plus tôt. Les fonctionnalités de la mémoire 3D XPoint permettent d'utiliser le SSD Intel Optane comme une extension de RAM dans les serveurs. Comme nous avons déjà réalisé qu'il ne serait pas facile de résoudre le problème de performances IO Hadoop au niveau des périphériques de stockage en bloc, nous avons décidé d'essayer une nouvelle option - étendre la RAM en utilisant la technologie Intel Memory Drive Technology (IMDT). Et au début de cette année, nous avons été parmi les premiers au monde à le tester.
C'est bon pour nous: c'est moins cher que la RAM, ce qui vous permet de collecter des serveurs qui ont des téraoctets de RAM. Et comme la RAM est assez rapide, vous pouvez y charger de grands ensembles de données et les analyser. Permettez-moi de vous rappeler que la particularité de notre processus analytique est que nous accédons aux données plusieurs fois. Afin de faire une sorte d'analyse, nous devons charger autant de données en mémoire que possible et «faire défiler» une sorte d'analyse de ces données plusieurs fois.
Le laboratoire anglais d'Intel à Swindon nous a attribué un cluster de trois serveurs, qui lors des tests nous avons comparé avec notre cluster de test situé à MTS.

Comme le montre le graphique, selon les résultats des tests, nous avons obtenu de très bons résultats.
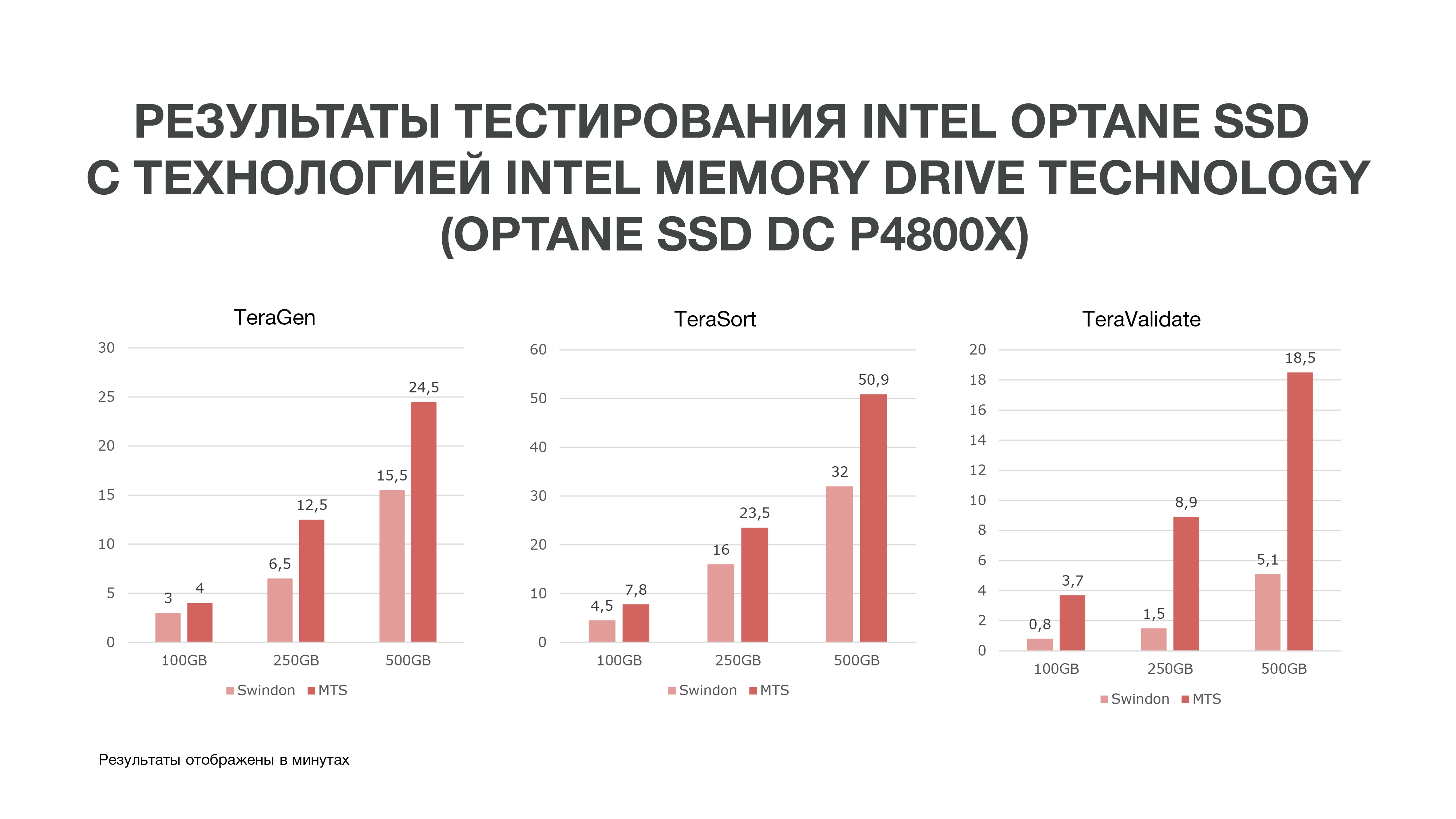
Le même TeraGen a montré une augmentation de productivité presque double, TeraValidate - de 75%. C'est très bien pour nous, car, comme je l'ai dit, nous accédons plusieurs fois aux données que nous avons en mémoire. Par conséquent, si nous obtenons un tel gain de performances, cela nous aidera particulièrement dans l'analyse des données, en particulier en temps réel.
Nous avons effectué trois tests dans différentes conditions. 100 Go, 250 Go et 500 Go. Et plus nous utilisions de mémoire, plus le SSD Intel Optane avec la technologie Intel Memory Drive était performant. Autrement dit, plus nous analysons de données, plus nous obtenons d'efficacité. Les analyses qui ont eu lieu sur plus de nœuds peuvent avoir lieu sur moins d'entre eux. Et nous obtenons également une assez grande quantité de mémoire sur nos machines, ce qui est très bon pour les tâches de Data Science. Sur la base des résultats des tests, nous avons décidé d'acheter ces disques pour travailler chez MTS.
Si vous deviez également choisir et tester du matériel pour stocker et traiter une grande quantité de données, nous serons intéressés de lire quelles difficultés vous avez rencontrées et quels résultats vous avez obtenus: écrivez dans les commentaires.
Auteurs:
Grigory Koval, chef du centre de compétences en architecture appliquée du département Big Data de MTS, grigory_koval
Chef de la tribu de gestion des données du département Big Data MTS Dmitry Shostko zloi_diman