Sans électricité, il n'y aura pas de services Internet très chargés que nous aimons tant. Curieusement, les systèmes de contrôle pour la production d'électricité, tels que les centrales nucléaires, sont également distribués, également soumis à des charges élevées, et nécessitent également de nombreuses technologies. De plus, la part de l'énergie nucléaire dans le monde va augmenter, la gestion de ces installations et leur sûreté est un sujet très important.
Par conséquent, comprenons ce qui s'y trouve, comment il est organisé, où sont les principales difficultés architecturales et où, dans la centrale nucléaire, vous pouvez appliquer les technologies ML et VR à la mode.
 Une centrale nucléaire, c'est:
Une centrale nucléaire, c'est:- Une moyenne de 3-4 unités de puissance avec une capacité moyenne de 1000 MW par centrale nucléaire, car les systèmes physiques doivent être sauvegardés, ainsi que les services sur Internet.
- Environ 150 sous-systèmes spéciaux qui assurent le fonctionnement de cette installation. Par exemple, il s'agit d'un système de contrôle interne du réacteur, d'un système de contrôle de turbine, d'un système de contrôle de traitement chimique de l'eau, etc. Chacun de ces sous-systèmes est intégré dans un énorme système du niveau de bloc supérieur (SVBU) d'un système de contrôle de processus automatisé (ACS TP).
- 200-300 milliers d'étiquettes, c'est-à-dire des sources de signaux qui changent en temps réel. Vous devez comprendre ce qui est un changement, ce qui ne l’est pas, si nous n’avons rien manqué et si nous l’avons manqué, alors que faire pour y remédier. Ces paramètres sont surveillés par deux opérateurs, un ingénieur de contrôle de réacteurs (VIUR) et un ingénieur de contrôle de turbines (VIUT).
- Deux bâtiments dans lesquels la plupart des sous-systèmes sont concentrés: un réacteur et un compartiment de turbine. Deux personnes doivent prendre une décision en temps réel en cas d'événements non standard ou standard. Une telle responsabilité n'est imposée qu'à deux personnes, car s'il y en a plus, elles devront s'entendre entre elles.
À propos de l'orateur: Vadim Podolny (
électrovénique ) représente l'usine de Moscou Fizpribor. Ce n'est pas seulement une usine - c'est principalement un bureau d'ingénierie dans lequel le matériel et les logiciels sont développés. Le nom est un hommage à l'histoire de l'entreprise, qui existe depuis 1942. Ce n'est pas très à la mode, mais très fiable - c'est ce qu'ils voulaient leur dire.
IIoT dans les centrales nucléaires
Fizpribor enterprise produit l'intégralité du complexe d'équipements nécessaires pour interfacer le grand nombre de sous-systèmes - ce sont des capteurs, des contrôleurs d'automatisation en aval, des plates-formes pour la construction de contrôleurs d'automatisation en aval, etc.
Dans sa conception moderne, le contrôleur n'est qu'un serveur industriel avec un nombre étendu de ports d'entrée / sortie pour interfacer l'équipement avec des sous-systèmes spéciaux. Ce sont d'énormes armoires - les mêmes que les armoires de serveur, seulement elles ont des contrôleurs spéciaux qui assurent l'informatique, la collecte, le traitement, la gestion.
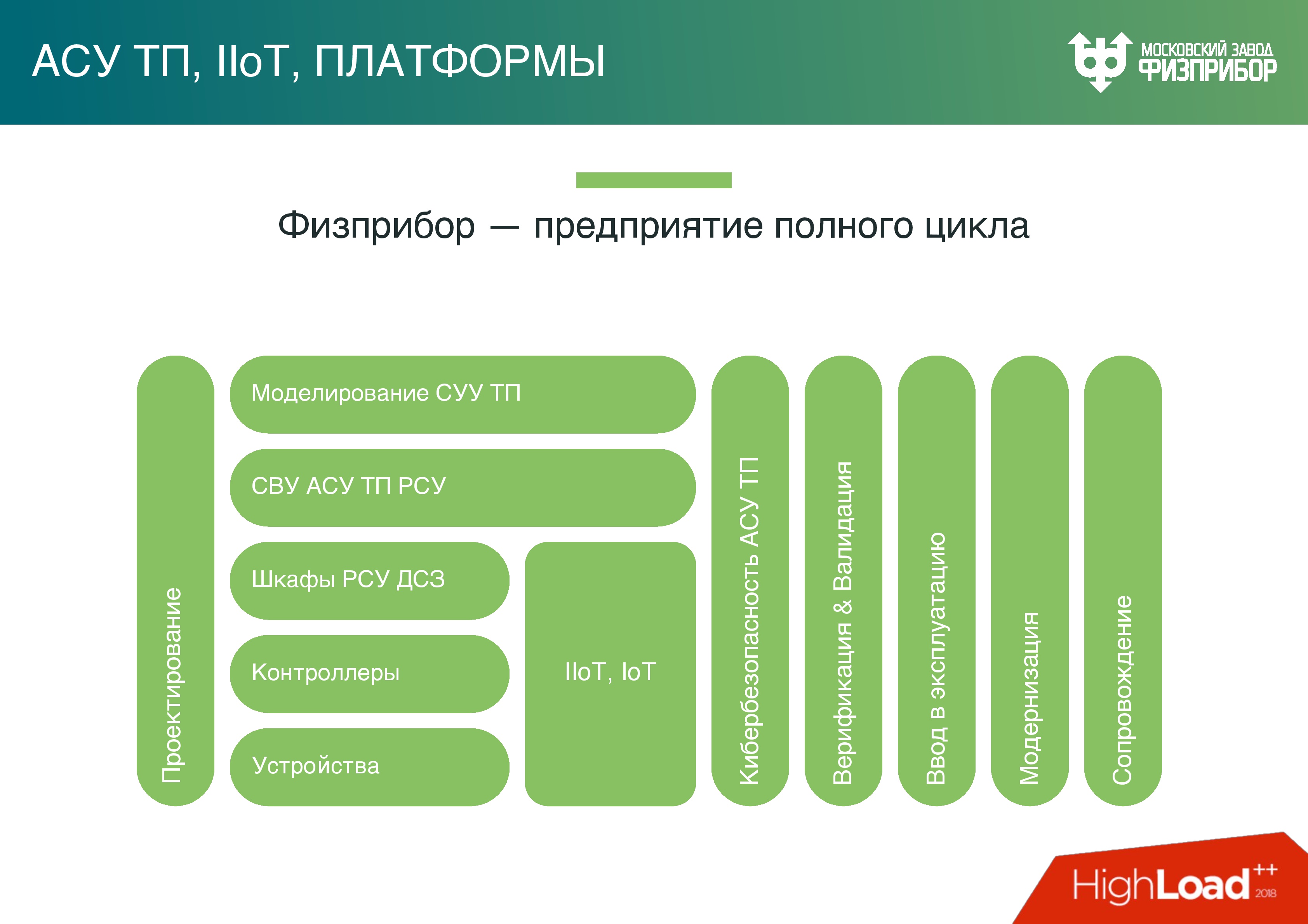
Nous développons des logiciels installés sur ces contrôleurs, sur des équipements passerelles. De plus, comme ailleurs, nous avons des centres de données, un cloud local dans lequel se déroulent le calcul, le traitement, la prise de décision, les prévisions et tout ce qui est nécessaire pour que l'objet de contrôle fonctionne.
Il convient de noter que dans notre siècle, l'équipement diminue, devenant plus intelligent. De nombreux équipements ont déjà des microprocesseurs - de petits ordinateurs qui assurent le prétraitement, comme il est désormais à la mode de l'appeler - des calculs de limites qui sont effectués afin de ne pas surcharger le système global. Par conséquent, nous pouvons dire que le système moderne de contrôle automatisé des processus des centrales nucléaires est déjà quelque chose comme un Internet industriel des objets.
La plate-forme qui contrôle cela est la plate-forme IoT dont beaucoup ont entendu parler. Il y en a maintenant un nombre considérable, le nôtre est très étroitement lié au temps réel.
De plus, des mécanismes de
vérification et de validation de bout en bout sont conçus pour fournir des vérifications de compatibilité et de fiabilité. Il comprend également des tests de résistance, des tests de régression, des tests unitaires - tout ce que vous savez. Seulement cela se fait avec le matériel que nous avons conçu et développé, et le logiciel qui fonctionne avec ce matériel. Les problèmes de cybersécurité (sécurisés par conception, etc.) sont en cours de résolution.

La figure montre les modules de processeur qui contrôlent les contrôleurs. Il s'agit d'une plate-forme de 6 unités avec un châssis pour placer des cartes mères, sur laquelle nous montons en surface l'équipement dont nous avons besoin, y compris les processeurs. Maintenant, nous avons une vague de substitution des importations, nous
essayons de soutenir les transformateurs nationaux . Quelqu'un dit qu'en conséquence, la sécurité des systèmes industriels augmentera. C'est vrai, un peu plus tard j'expliquerai pourquoi.
Système de sécurité
Tout système de contrôle de processus dans une centrale nucléaire est réservé comme système de sécurité. La centrale nucléaire est conçue pour que l'avion y tombe. Le système de sûreté devrait assurer un refroidissement d'urgence du réacteur afin que, en raison de la chaleur résiduelle générée par la désintégration bêta, il ne fond pas, comme cela s'est produit à la centrale nucléaire de Fukushima. Il n'y avait pas de système de sécurité, les générateurs diesel de secours ont été emportés par les vagues et ce qui s'est passé s'est produit. Ce n'est pas possible dans nos centrales nucléaires, car nos systèmes de sûreté y sont situés.
La base des systèmes de sécurité est la logique dure.
En fait, nous déboguons un ou plusieurs algorithmes de contrôle qui peuvent être combinés en un algorithme de groupe fonctionnel, et nous dessoudons toute cette histoire directement sur la carte sans microprocesseur, c'est-à-dire que nous obtenons une logique difficile. Si un équipement doit parfois être remplacé, ses réglages ou paramètres changeront, et il sera nécessaire de modifier son algorithme de fonctionnement - oui, vous devrez retirer la carte sur laquelle l'algorithme est soudé et en mettre un nouveau. Mais c'est sûr -
cher, mais sûr .

Ci-dessous est un exemple d'un triple système de
protection contre le sabotage , sur lequel un algorithme pour résoudre un problème du système de sécurité dans le mode de réalisation est deux sur trois. Il y en a trois sur quatre - c'est comme le RAID.

Diversité technologique
Tout d'abord, il est important d'utiliser différents processeurs. Si nous créons un système multiplateforme et sélectionnons un système commun à partir de modules fonctionnant sur différents processeurs, alors si des logiciels malveillants pénètrent dans le système à un certain stade du cycle de vie (conception, développement, maintenance préventive), alors il ne sera pas frappé immédiatement toute la variété de sabotage de la technologie.

Il existe également une
variété quantitative . La vue des champs depuis le satellite reflète bien le modèle, lorsque nous cultivons une variété de cultures autant que possible en termes de budget, d'espace, de compréhension et de fonctionnement, c'est-à-dire que nous réalisons une redondance, en copiant les systèmes autant que possible.
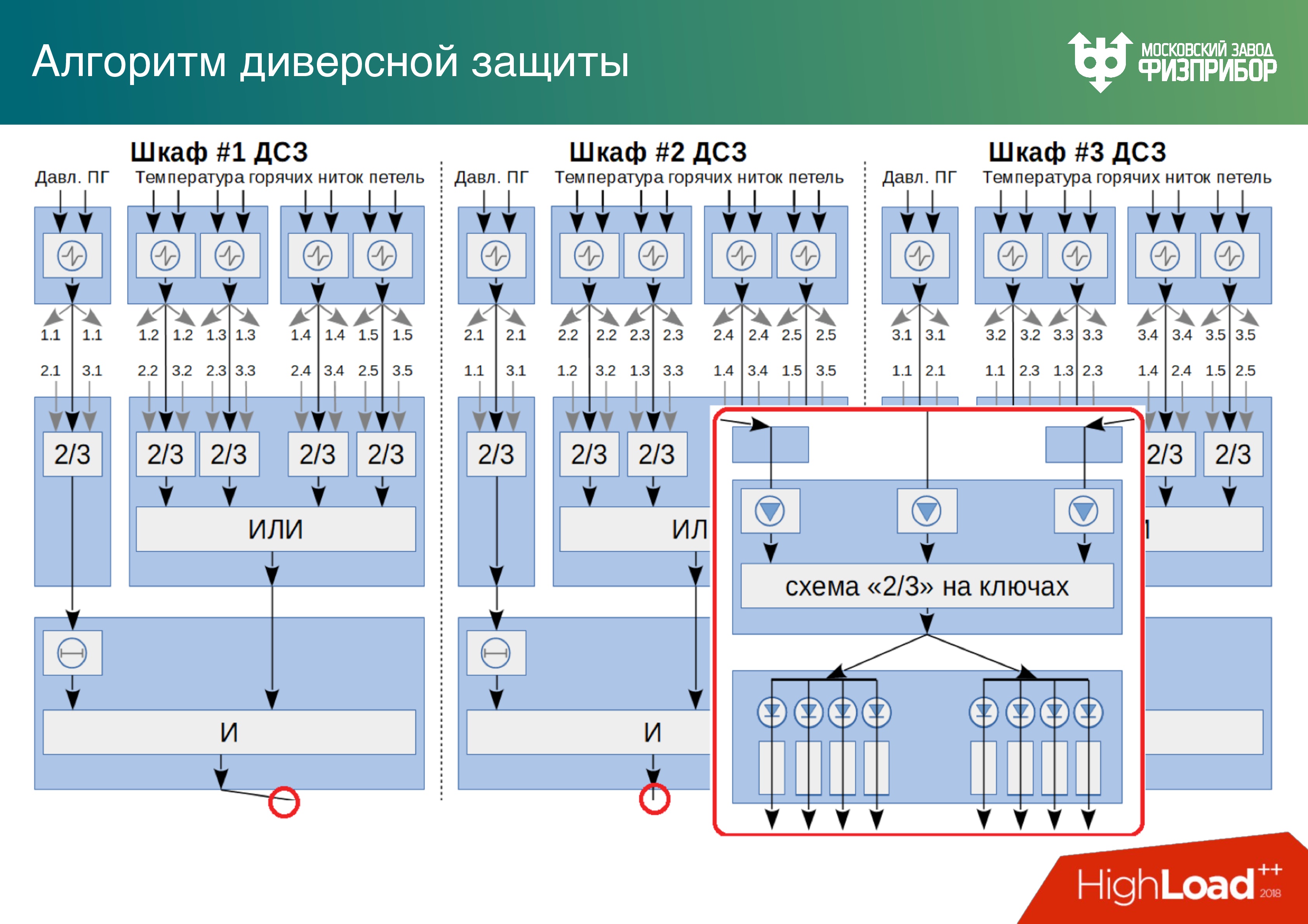
Voici un exemple d'algorithme pour choisir une solution basée sur un système de protection à triple sabotage. L'algorithme est considéré comme correct sur la base de deux des trois réponses. Nous pensons que si l'une des armoires tombe en panne, nous en sommes d'abord informés et, deuxièmement, les deux autres fonctionnent correctement. Il existe des domaines entiers de ces armoires dans les centrales nucléaires.

Nous avons parlé de matériel, passons à ce qui est plus intéressant pour tout le monde - au logiciel.
Logiciel. Haut et colonne vertébrale
Voilà à quoi ressemble le système de surveillance de ces armoires.

Le système de niveau supérieur (après une automatisation de bas niveau) assure une collecte, un traitement et une livraison fiables des informations à l'opérateur et aux autres services d'intérêt. Tout d'abord, il devrait résoudre la tâche principale -
pour pouvoir tout résoudre
au moment des charges de pointe , par conséquent, en fonctionnement normal, le système peut être chargé de 5 à 10%. Les capacités restantes fonctionnent réellement au ralenti et sont conçues pour qu'en cas d'urgence, nous puissions équilibrer, distribuer, traiter toutes les surcharges.
L'exemple le plus typique est une turbine. Il donne le plus d'informations et s'il commence à fonctionner de manière instable, le DDoS se produit réellement, car tout le système d'information est obstrué par les informations de diagnostic de cette turbine. Si la
QoS ne fonctionne pas bien, de graves problèmes peuvent survenir: l'opérateur ne verra tout simplement pas certaines des informations importantes.
En fait, tout n'est pas si effrayant. Un opérateur peut travailler sur un réactimètre physique pendant 2 heures, mais perdre du matériel. Afin d'éviter que cela ne se produise, nous développons notre nouvelle plate-forme logicielle. La version précédente dessert désormais 15 unités de puissance, qui sont construites en Russie et à l'étranger.
 Une plate-forme logicielle est une architecture de microservices multiplateforme
Une plate-forme logicielle est une architecture de microservices multiplateforme composée de plusieurs couches:
- Une couche de données est une base de données en temps réel. C'est très simple - quelque chose comme valeur-clé, mais la valeur ne peut être que double. Plus aucun objet n'y est stocké pour supprimer complètement la possibilité de débordement de tampon, de pile ou autre.
- Une base de données distincte pour stocker les métadonnées. Nous utilisons PostgreSQL et d'autres technologies, en principe, toute technologie est configurée, car il n'y a pas de temps réel difficile.
- Couche d'archives. Il s'agit d'une archive en ligne (environ une journée) pour le traitement des informations actuelles et, par exemple, des rapports.
- Archives à long terme.
- Archive d'urgence - une boîte noire qui sera utilisée en cas d'accident et si l'archive à long terme est endommagée. Des indicateurs clés, des alarmes, le fait d'acquitter des alarmes y sont enregistrés (l' acquittement signifie que l'opérateur a vu l'alarme et commence à faire quelque chose ).
- Couche logique dans laquelle se trouve le langage de script. Le noyau informatique est basé sur lui, et après le noyau informatique, tout comme un module, il y a un générateur de rapports. Rien d'inhabituel: vous pouvez imprimer un graphique, faire une demande, voir comment les paramètres ont changé.
- Couche client - un nœud qui vous permet de développer des services client basés sur du code, contient une API.
Il existe plusieurs options pour les nœuds clients:
- Optimisé pour l'enregistrement . Il développe des pilotes de périphérique, mais ce n'est pas un pilote classique. Il s'agit d'un programme qui collecte des informations auprès des contrôleurs d'automatisation en aval, effectue le prétraitement, analyse toutes les informations et tous les protocoles utilisés par l'équipement d'automatisation en aval - OPC, HART, UART, Profibus.
- Optimisé pour la lecture - pour créer des interfaces utilisateur, des gestionnaires et tout ce qui va plus loin.
Sur la base de ces nœuds, nous construisons un
cloud . Il se compose de serveurs fiables classiques qui sont gérés à l'aide de systèmes d'exploitation courants. Nous utilisons principalement Linux, parfois QNX.
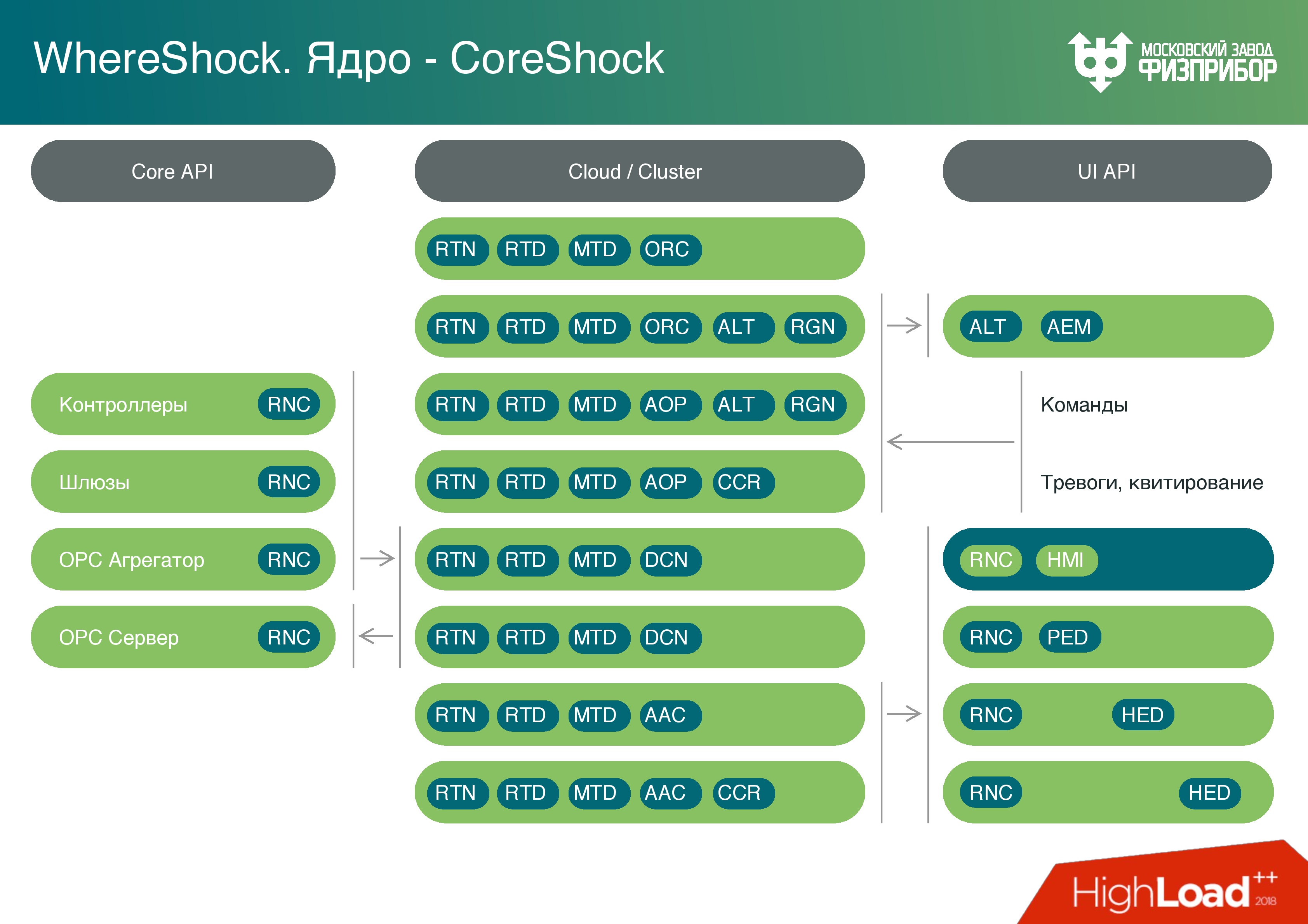
Le cloud est découpé en machines virtuelles, les conteneurs sont lancés quelque part. Dans le cadre de la virtualisation de conteneurs, différents types de nœuds sont lancés, qui, si nécessaire, effectuent différentes tâches. Par exemple, vous pouvez exécuter le générateur de rapports une fois par jour, lorsque tous les documents de rapport nécessaires pour la journée sont prêts, les machines virtuelles sont déchargées et le système est prêt pour d'autres tâches.
Nous avons appelé notre système
Vershok , et le cœur du système
Spine - il est clair pourquoi.

Disposant de ressources informatiques suffisamment puissantes sur les contrôleurs de passerelle, nous avons pensé - pourquoi ne pas utiliser leur puissance non seulement pour le prétraitement? Nous pouvons transformer ce nuage et tous les nœuds frontaliers en brouillard, et charger ces capacités de tâches, telles que, par exemple, identifier les erreurs.

Il arrive parfois que les capteurs doivent être calibrés. Au fil du temps, les lectures flottent, nous savons selon quel calendrier ils changeront leurs lectures, et au lieu de changer ces capteurs, nous mettons à jour les données et apportons des corrections - c'est ce qu'on appelle l'étalonnage du capteur.
Nous avons une plate-forme Fog complète. Oui, il effectue un nombre limité de tâches dans le brouillard, mais nous augmenterons progressivement leur nombre et déchargerons le cloud total.
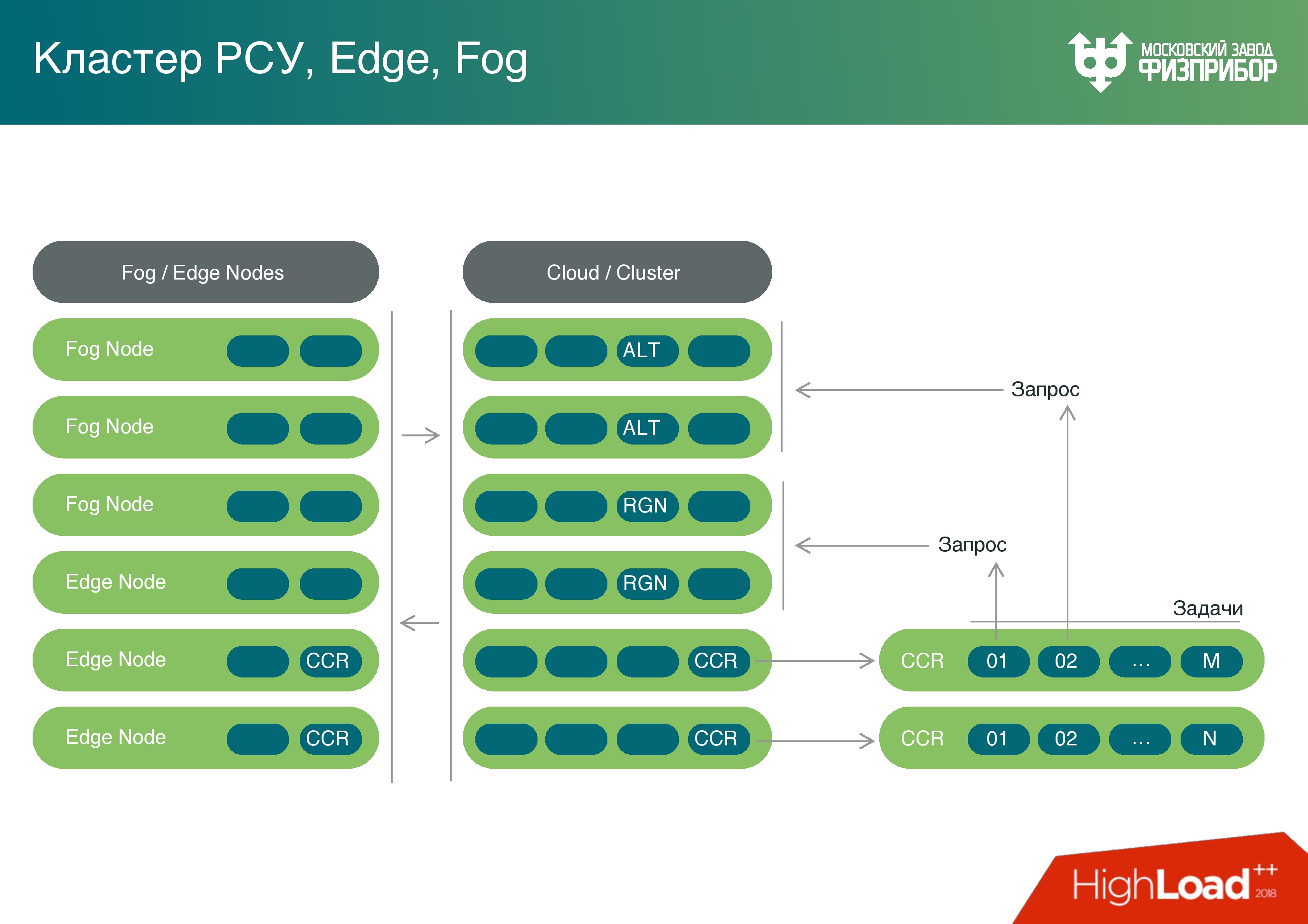
De plus, nous avons un noyau informatique. Nous incluons un langage de script, nous pouvons travailler avec Lua, avec Python (par exemple, la bibliothèque PyPy), avec JavaScript et TypeScript pour résoudre les problèmes avec les interfaces utilisateur. Nous pouvons effectuer ces tâches aussi bien à l'intérieur du cloud qu'aux nœuds limites. Chaque microservice peut être lancé sur le processeur de n'importe quelle quantité de mémoire et de puissance. Il traitera simplement la quantité d'informations possible aux capacités actuelles. Mais le système fonctionne de la même manière sur n'importe quel nœud. Il convient également pour le placement sur des appareils IoT simples.
Désormais, les informations de plusieurs sous-systèmes parviennent à cette plate-forme: niveau de protection physique, systèmes de contrôle d'accès, informations provenant des caméras, données de sécurité incendie, systèmes de contrôle des processus, infrastructure informatique, événements de sécurité des informations.
Sur la base de ces données, Behavior Analytics est une analyse comportementale intégrée. Par exemple, un opérateur ne peut pas être connecté si la caméra n'a pas enregistré qu'il est allé à la salle d'opération. Ou un autre cas: nous voyons que certains canaux de communication ne fonctionnent pas, alors que nous corrigeons qu'à ce moment la température du rack a changé, la porte a été ouverte. Quelqu'un est entré, a ouvert la porte, s'est retiré ou a touché le câble. Bien sûr, cela ne devrait pas être le cas, mais une surveillance est toujours nécessaire. Il est nécessaire de décrire le plus grand nombre de cas possible afin que, lorsque quelque chose se produit soudainement, nous le sachions avec certitude.

Ci-dessus sont des exemples de l'équipement sur lequel tout cela fonctionne, et ses paramètres:
- À gauche, un serveur Supermicro standard. Le choix s'est porté sur Supermicro, car avec lui toutes les possibilités de fer sont immédiatement disponibles, il est possible d'utiliser des équipements domestiques.
- Sur la droite se trouve le contrôleur, qui est produit dans notre usine. Nous lui faisons entièrement confiance et comprenons ce qui se passe là-bas. Sur la diapositive, il est entièrement chargé de modules informatiques.
Notre
contrôleur fonctionne avec un refroidissement passif , et de notre point de vue, il est beaucoup plus fiable, nous essayons donc de transférer le nombre maximal de tâches vers des systèmes avec un refroidissement passif. Tout ventilateur tombera en panne à un moment donné, et la durée de vie de la centrale nucléaire est de 60 ans, avec une possibilité d'extension à 80. Il est clair que pendant ce temps des réparations préventives programmées seront effectuées, l'équipement sera remplacé. Mais si vous prenez maintenant un objet qui a commencé dans les années 90 ou 80, il est même impossible de trouver un ordinateur pour exécuter le logiciel qui y fonctionne. Par conséquent, tout doit être réécrit et modifié, y compris l'algorithmique.
Nos services fonctionnent en mode Multi-Master, il n'y a pas de point de défaillance unique, tout cela est multi-plateforme. Les nœuds sont autodéterminés, vous pouvez effectuer un échange à chaud, grâce auquel vous pouvez ajouter et modifier des équipements, et il n'y a aucune dépendance à la défaillance d'un ou plusieurs éléments.

La
dégradation du système existe. Dans une certaine mesure, l'opérateur ne doit pas remarquer que quelque chose ne va pas avec le système: le module processeur a grillé, ou l'alimentation du serveur a disparu et il s'est éteint; Le canal de communication a été surchargé car le système ne fait pas face. Ces problèmes et d'autres similaires peuvent être résolus en sauvegardant tous les composants et le réseau. Nous avons maintenant une topologie à double étoile et maillage. Si un nœud tombe en panne, la topologie du système vous permet de continuer à fonctionner normalement.

Ce sont des comparaisons des paramètres Supermicro (ci-dessus) et de notre contrôleur (ci-dessous), que nous obtenons à partir de mises à jour basées sur une base de données en temps réel. Les figures 4 et 8 sont le nombre de répliques, c'est-à-dire que la base de données maintient l'état actuel de tous les nœuds en temps réel - ce sont la multidiffusion et en temps réel. Dans la configuration de test, il y a environ 10 millions d'étiquettes, c'est-à-dire des sources de changements de signal.
Supermicro affiche une moyenne de 7 M / s ou 5 M / s, avec une augmentation du nombre de répliques. Nous nous battons pour ne pas perdre la puissance du système, avec une augmentation du nombre de nœuds. Malheureusement, lorsqu'il devient nécessaire de traiter les réglages et autres paramètres, nous perdons de la vitesse avec une augmentation du nombre de nœuds, mais plus il y a de nœuds, moins il y a de pertes.
Sur
notre contrôleur (sur Atom) les paramètres sont d'un ordre de grandeur plus petits.
Pour créer une tendance, l'utilisateur voit un ensemble de balises. Ci-dessous se trouve une interface tactile pour l'opérateur, dans laquelle il peut sélectionner des options. Chaque nœud client possède une copie de la base de données. Le développeur de l'application client travaille avec la mémoire locale et ne pense pas à synchroniser les données sur le réseau, il ne fait que Get, Set via l'API.
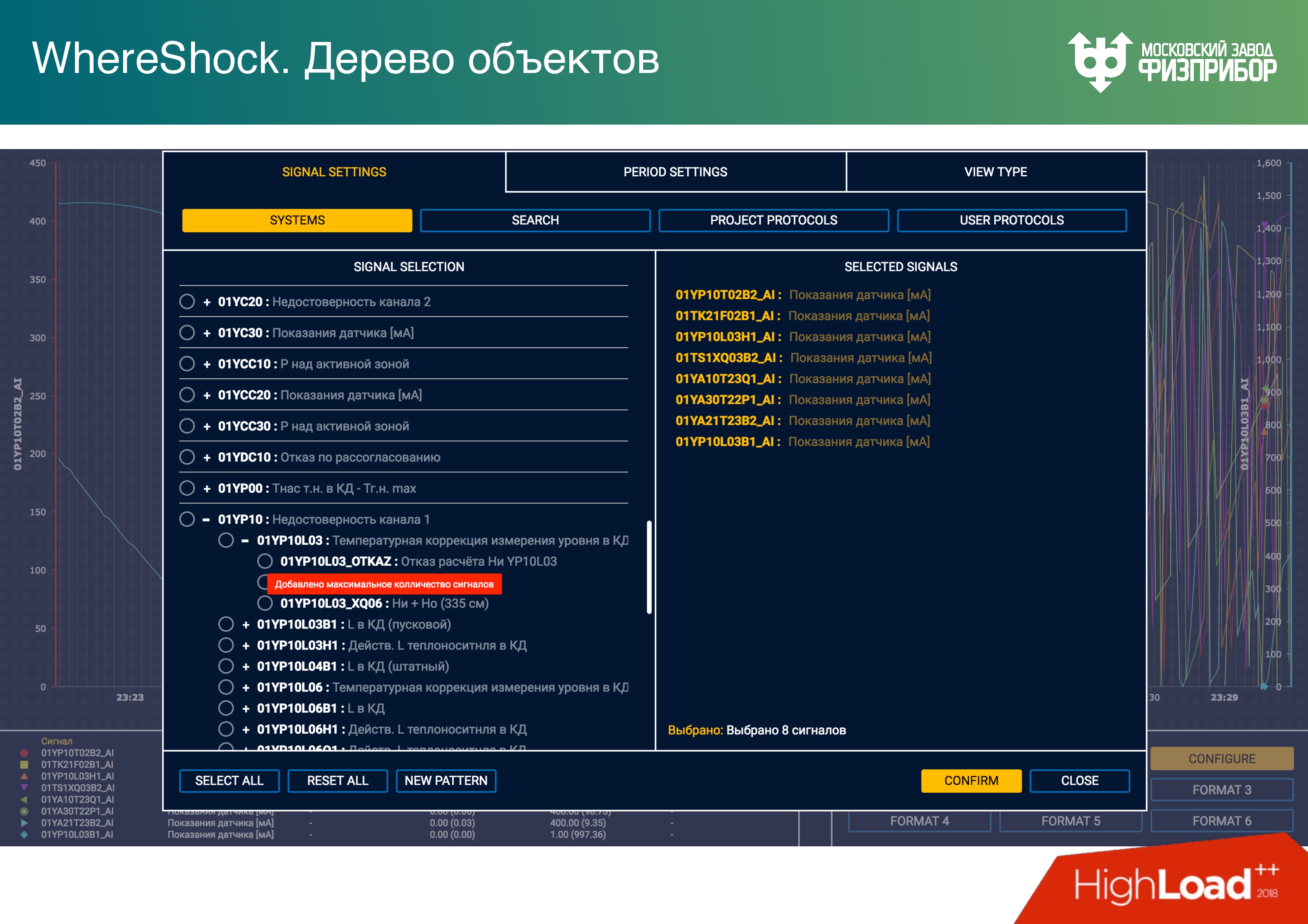
Le développement d'une interface client pour les systèmes de contrôle de processus n'est pas plus compliqué que le développement d'un site. Auparavant, nous nous battions pour le temps réel sur le client, utilisions C ++, Qt. Maintenant, nous l'avons refusé et avons tout fait sur Angular. Les processeurs modernes vous permettent de maintenir la fiabilité de telles applications. Le Web est déjà suffisamment fiable, bien que la mémoire, bien sûr, flotte.
La tâche d'assurer le fonctionnement de l'application pendant un an sans redémarrage n'est plus d'actualité. Tout cela est emballé dans
Electron et donne en fait l'indépendance de la plate-forme, c'est-à-dire la possibilité d'exécuter l'interface sur des tablettes et des panneaux.
L'anxiété
Une alarme est le seul objet dynamique qui apparaît dans le système. Après le démarrage du système, l'arborescence entière des objets est corrigée; rien ne peut en être supprimé. Autrement dit, le modèle CRUD ne fonctionne pas, vous pouvez uniquement marquer «marquer comme supprimé». Si vous devez supprimer une balise, elle est simplement marquée et cachée à tout le monde, mais elle n'est pas supprimée, car l'opération de suppression est complexe et peut endommager l'état du système, son intégrité.
Une alarme est un objet qui apparaît lorsqu'un paramètre de signal d'un équipement particulier dépasse les paramètres. Les paramètres sont les limites d'avertissement inférieures et supérieures des valeurs: urgence, critique, supercritique, etc. Lorsqu'un paramètre tombe dans une valeur d'échelle particulière, une alarme correspondante apparaît.
La première question qui se pose lorsqu'une alarme se produit est de savoir à qui afficher un message à ce sujet. Afficher l'alarme à deux opérateurs? Mais notre système est universel, il peut y avoir plus d'opérateurs. Dans une centrale nucléaire, les bases de données du turbiniste et du spécialiste des réacteurs diffèrent «un peu», car l'équipement est différent. Il est clair, bien sûr, si le niveau du signal a dépassé les limites dans le compartiment du réacteur, alors cela sera vu par le principal ingénieur de contrôle du réacteur, dans la turbine - par la turbine.
Mais supposons qu'il existe de nombreux opérateurs. . - , . real-time , , . . , “” .
, . - “” – . , , , , “” . , . : , . , .
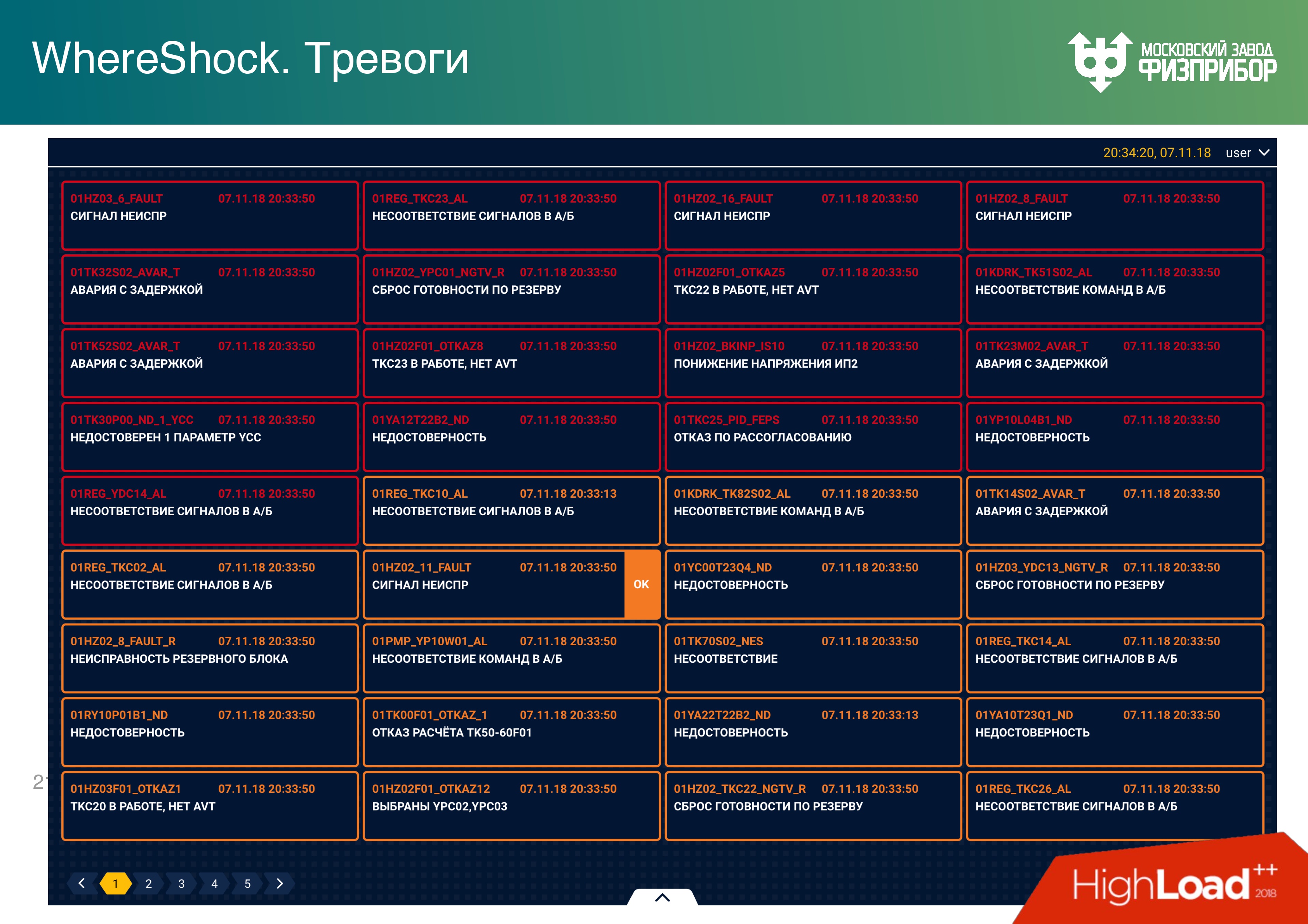
, , .

– .
. , .

.

, , , , .
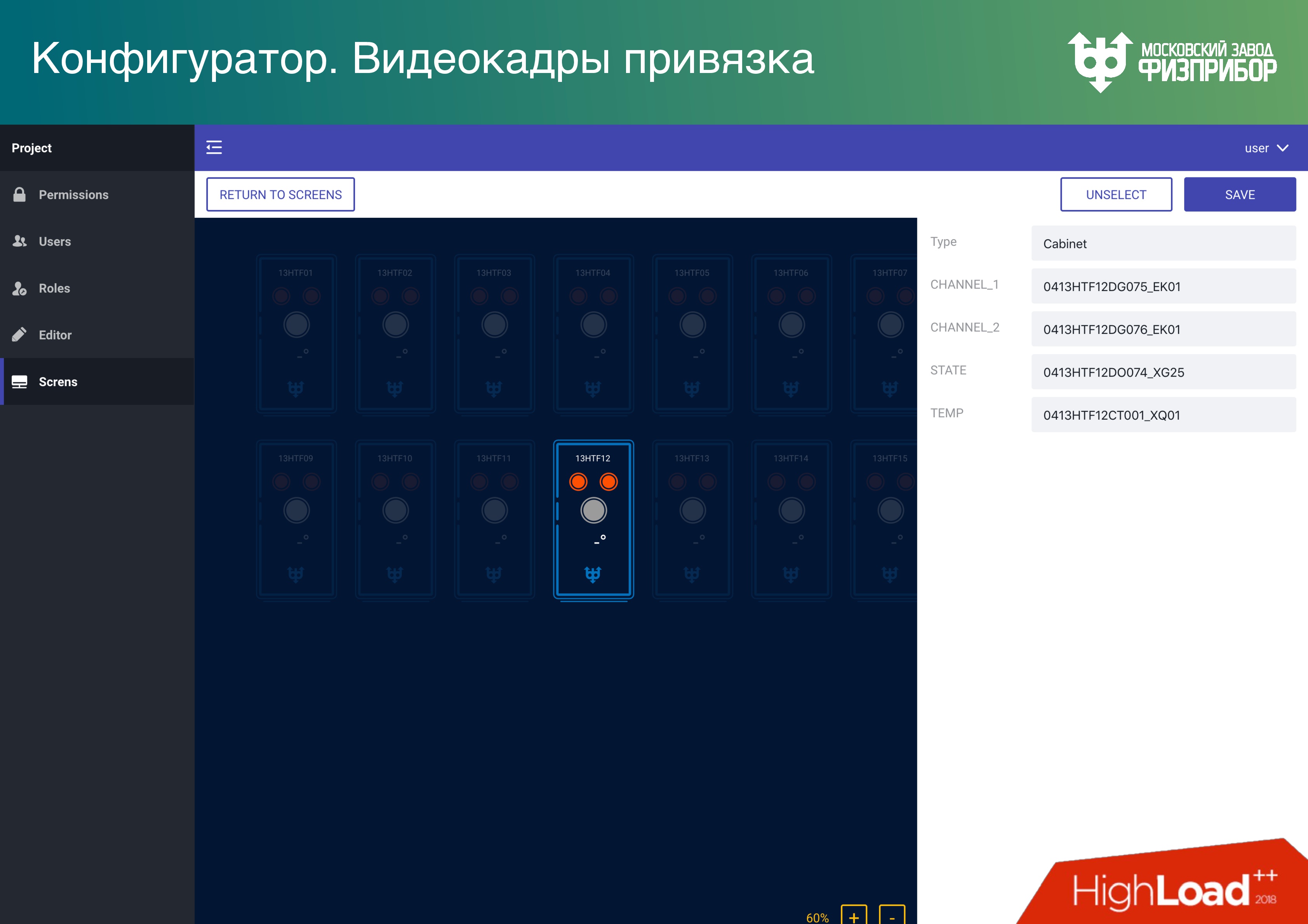
– , . SCADA/HMI , , , – , , . , : «, ! Illustrator, Sketch – , SVG». SVG . , .
, . API, . , , , . , , . , , , , – . , , , , .
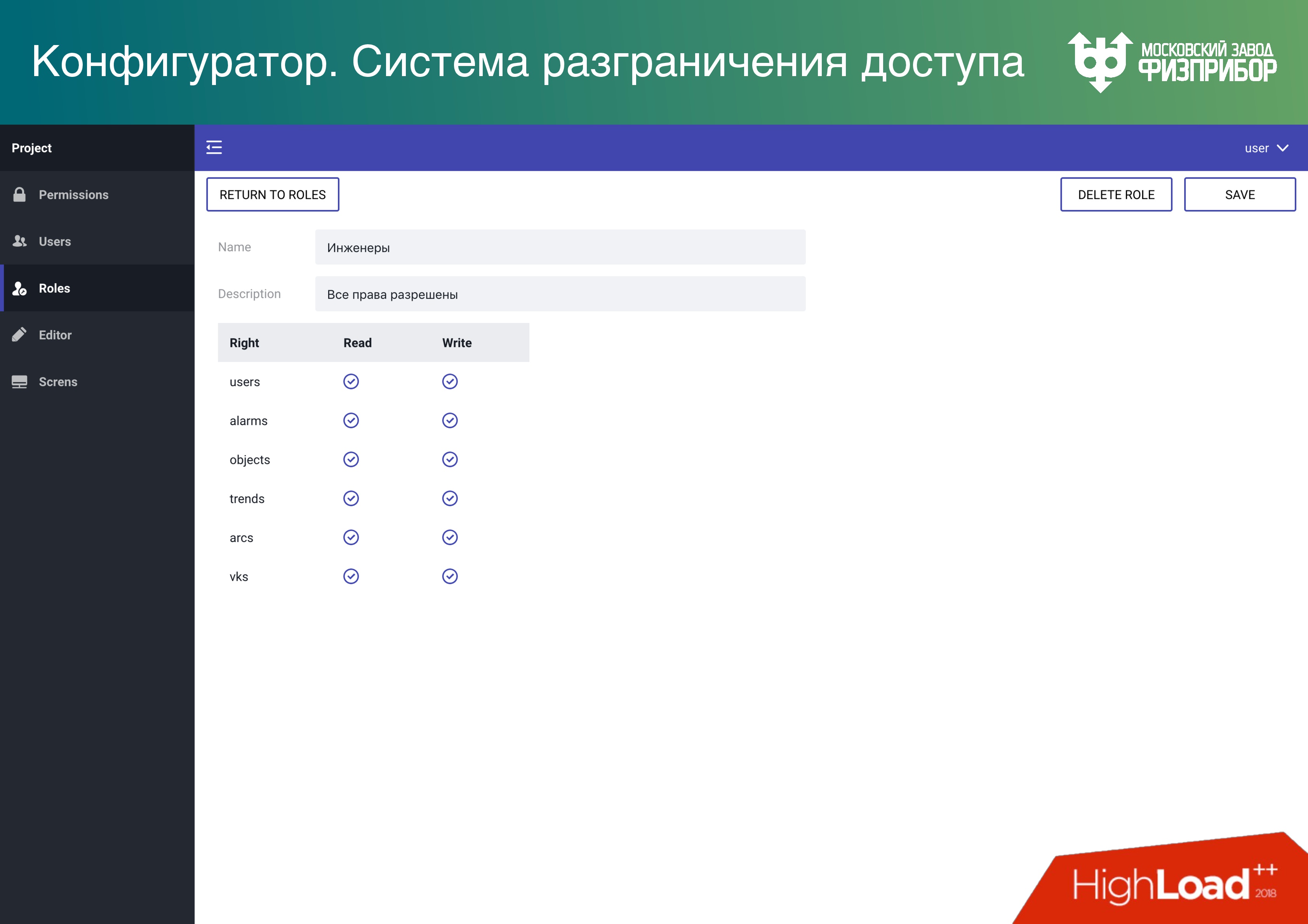
,
. , . Data Lake. ,
multitenancy (, ). .
, . , , ,
.
, : . , 10 100 , – .
, . , .
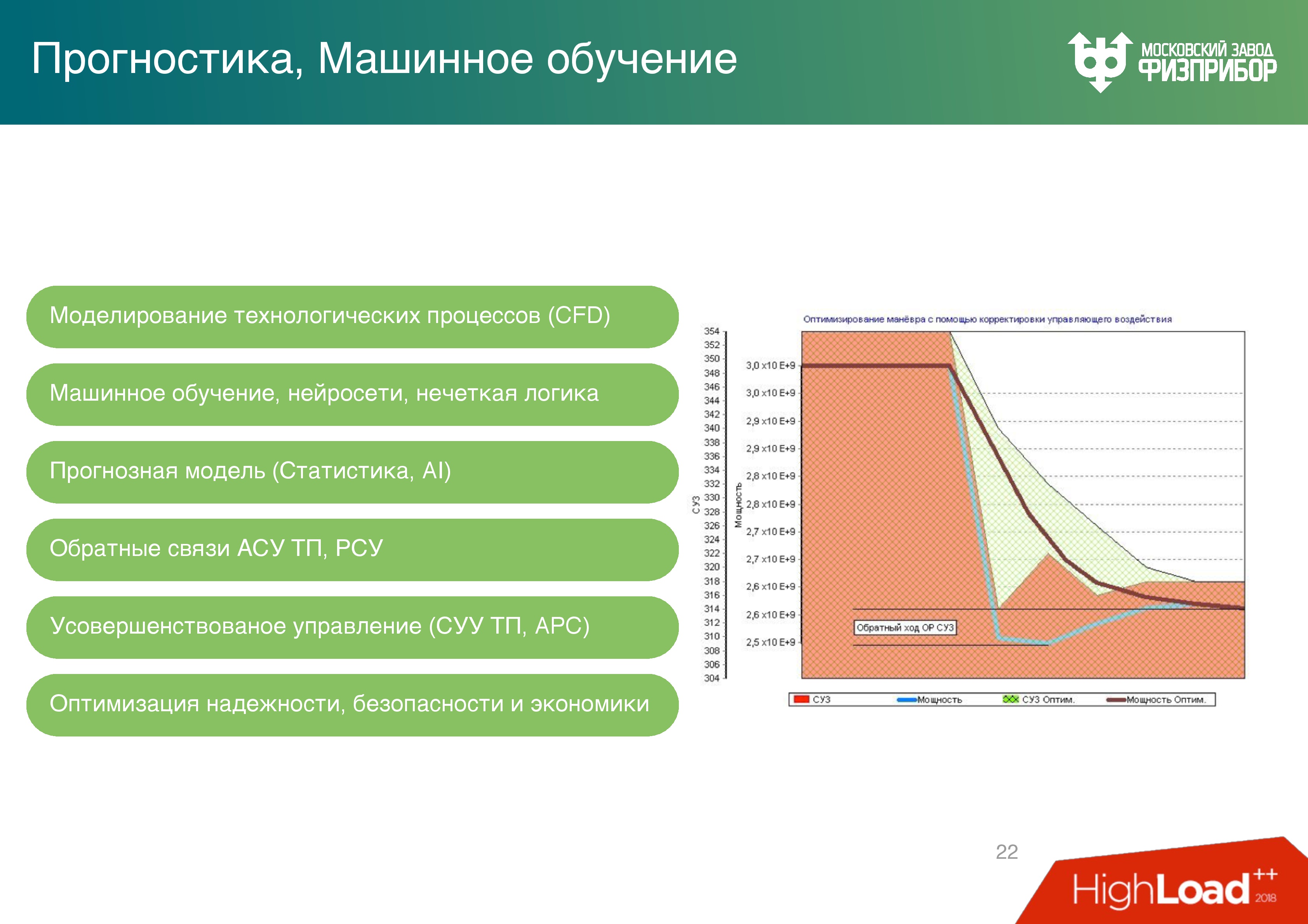
— . , , . – , : -1200 10 .
, , , , , - , , .… .
. . 5 : , , , . .
:
- - ( CPU);
- Computational Fluid Dynamics (CFD) ( GPU).
, . - , , ( ). .
60 , ( , ). KPI , .
.
 – , – .
– , – .. – . , , , – .
VR- , .

, , , . ( ) — , - . , , . — ( ), – ( ), .
, , — . . . .
ITER . , – . , , . , !
Nous allons faire un plus grand biais dans le développement de logiciels et de matériel pour l'Internet des objets à InoThings Conf le 4 avril. L'année dernière, des rapports ont été publiés sur l'IIoT et l' électricité . Cette année, nous prévoyons de rendre le programme encore plus mouvementé. Écrivez des candidatures si vous êtes prêt à nous aider.