
J'entre dans l'équipe Tarantool Core et participe au développement d'un moteur de base de données, aux communications internes des composants serveur et à la réplication. Et aujourd'hui, je vais vous expliquer le fonctionnement de la réplication.
À propos de la réplication
La réplication est le processus de copie de données d'un magasin à un autre. Chaque copie est appelée réplique. La réplication peut être utilisée si vous devez obtenir une sauvegarde, implémenter une redondance d'UC ou redimensionner le système horizontalement. Et pour cela il faut pouvoir utiliser les mêmes données sur différents nœuds du réseau informatique du cluster.
Nous classons la réplication de deux manières principales:
- Direction: maître-maître ou maître-esclave . La réplication maître-esclave est l'option la plus simple. Vous avez un nœud sur lequel vous modifiez des données. Vous traduisez ces modifications vers les autres nœuds où elles sont appliquées. Avec la réplication maître-maître, des modifications sont apportées à plusieurs nœuds à la fois. Dans ce cas, chaque nœud modifie lui-même ses données et applique à lui-même les modifications apportées aux autres nœuds.
- Mode de fonctionnement: asynchrone ou synchrone . La réplication synchrone implique que les données ne seront pas validées et la réplication ne sera pas confirmée à l'utilisateur jusqu'à ce que les modifications soient propagées à travers au moins le nombre minimum de nœuds de cluster. Dans la réplication asynchrone, la validation d'une transaction (la validation) et l'interaction avec un utilisateur sont deux processus indépendants. Pour valider les données, il est seulement nécessaire qu'elles tombent dans le journal local, et alors seulement ces modifications sont transmises d'une manière ou d'une autre aux autres nœuds. De toute évidence, la réplication asynchrone a un certain nombre d'effets secondaires à cause de cela.
Comment fonctionne la réplication dans Tarantool?
La réplication dans Tarantool a plusieurs fonctionnalités:
- Il est construit à partir de briques de base, avec lesquelles vous pouvez créer un cluster de n'importe quelle topologie. Chacun de ces éléments de configuration de base est unidirectionnel, c'est-à-dire que vous avez toujours maître et esclave. Master effectue certaines actions et génère un journal des opérations, qui est utilisé sur la réplique.
- La réplication de Tarantool est asynchrone. Autrement dit, le système vous confirme la validation, quel que soit le nombre de répliques que cette transaction a vues, combien elle a été appliquée à elle-même et si elle s'est avérée être effectuée du tout.
- Une autre propriété de réplication dans Tarantool est qu'il est basé sur des lignes. Tarantool tient un journal des opérations (WAL). L'opération y arrive ligne par ligne, c'est-à-dire que lorsqu'un certain tapla de l'espace change, cette opération est écrite dans le journal comme une ligne. Après cela, le processus d'arrière-plan lit cette ligne dans le journal et l'envoie à la réplique. Combien de répliques le maître possède, autant de processus d'arrière-plan. En d'autres termes, chaque processus de réplication vers différents nœuds du cluster est exécuté de manière asynchrone par rapport aux autres.
- Chaque nœud de cluster a son propre identifiant unique, qui est généré lors de la création du nœud. De plus, le nœud possède également un identifiant dans le cluster (numéro de membre). Il s'agit d'une constante numérique affectée à une réplique lorsqu'elle est connectée à un cluster, et elle reste avec la réplique tout au long de sa vie dans le cluster.
En raison de l'asynchronie, les données sont livrées à des répliques retardées. Autrement dit, vous avez apporté des modifications, le système a confirmé la validation, l'opération a déjà été appliquée sur le maître, mais sur les répliques, elle sera appliquée avec un certain retard, qui est déterminé par la vitesse à laquelle le processus de réplication en arrière-plan lit l'opération, l'envoie à la réplique et celle-ci s'applique .
Pour cette raison, il y a une chance que les données ne soient pas synchronisées. Supposons que nous ayons plusieurs maîtres qui modifient les données interconnectées. Il peut s'avérer que les opérations que vous utilisez ne sont pas commutatives et se réfèrent aux mêmes données, alors deux membres de cluster différents auront des versions différentes des données.
Si la réplication dans Tarantool est maître-esclave unidirectionnel, alors comment faire maître-maître? Très simple: créez un autre canal de réplication mais dans l'autre sens. Vous devez comprendre que dans Tarantool, la réplication maître-maître n'est qu'une combinaison de deux flux de données indépendants l'un de l'autre.
En utilisant le même principe, nous pouvons connecter le troisième maître et ainsi créer un réseau maillé complet dans lequel chaque réplique est maître et esclave pour toutes les autres répliques.
Veuillez noter que non seulement les opérations lancées localement sur ce maître sont répliquées, mais également celles qu'il a reçues en externe via des protocoles de réplication. Dans ce cas, les modifications créées sur la réplique n ° 1 viendront à la réplique n ° 3 deux fois: directement et via la réplique n ° 2. Cette propriété nous permet de créer des topologies plus complexes sans utiliser un maillage complet. Disons celui-ci.
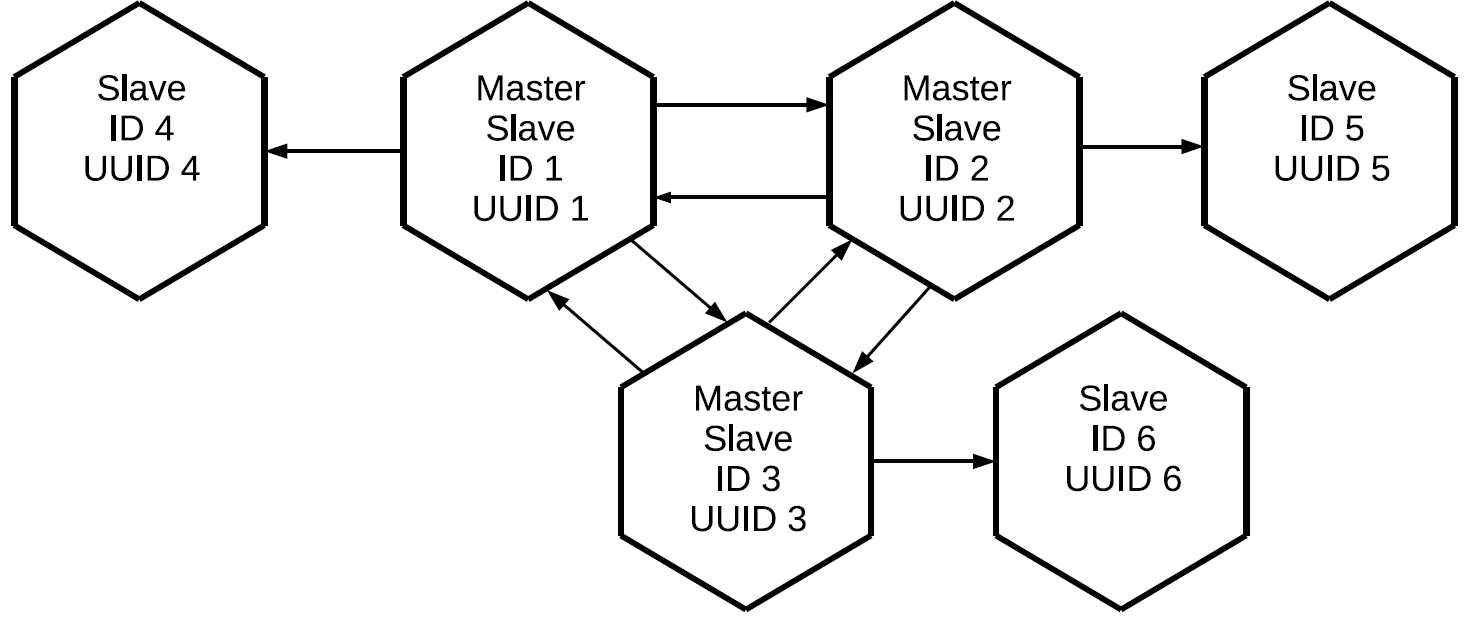
Les trois maîtres, qui constituent ensemble le noyau maillé complet du cluster, ont une réplique individuelle attachée. Étant donné que le proxy de journaux est effectué sur chacun des maîtres, les trois esclaves «propres» contiendront toutes les opérations qui ont été effectuées sur l'un des nœuds du cluster.
Cette configuration peut être utilisée pour une variété de tâches. Vous ne pouvez pas créer de liens redondants entre tous les nœuds du cluster, et si des répliques sont placées à proximité, elles auront une copie exacte du maître avec un délai minimal. Et tout cela se fait à l'aide de l'élément de réplication maître-esclave de base.
Étiquetage des opérations de cluster
La question se pose:
si les opérations sont mandatées entre tous les membres du cluster et arrivent à chaque réplique plusieurs fois, comment pouvons-nous comprendre quelle opération doit être effectuée et laquelle ne doit pas l'être? Cela nécessite un mécanisme de filtrage. Chaque opération lue dans le journal se voit attribuer deux attributs:
- L'identifiant du serveur sur lequel cette opération a été lancée.
- Numéro de séquence de l'opération sur le serveur, lsn, qui est son initiateur. Chaque serveur, lors d'une opération, attribue un nombre croissant à chaque ligne de journal reçue: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ... Ainsi, si nous savons que pour un serveur avec un certain identifiant, nous avons appliqué l'opération avec lsn 10, puis les opérations avec lsn 9, 8, 7, 10 qui sont passées par d'autres canaux de réplication ne sont pas nécessaires. Au lieu de cela, nous appliquons les éléments suivants: 11, 12, etc.
Statut de la réplique
Et comment Tarantool stocke-t-il les informations sur les opérations qu'il a déjà appliquées? Pour ce faire, il existe une horloge Vclock - c'est le vecteur du dernier lsn appliqué à chaque nœud du cluster.
[lsn 1 , lsn 2 , lsn n ]où
lsn i est le numéro de la dernière opération connue du serveur avec l'identifiant i.
Vclock peut également être appelé un certain instantané de l'ensemble de l'état du cluster connu de cette réplique. Connaissant l'ID serveur de l'opération arrivée, nous isolons le composant de la Vclock locale dont nous avons besoin, comparons le lsn reçu avec l'opération lsn et décidons s'il faut utiliser cette opération. Par conséquent, les opérations lancées par un maître spécifique seront envoyées et appliquées séquentiellement. Dans le même temps, les workflows créés sur différents maîtres peuvent être mélangés les uns aux autres en raison de la réplication asynchrone.
Création de cluster
Supposons que nous ayons un cluster composé de deux éléments maître et esclave, et que nous voulons y connecter une troisième instance. Il a un UUID unique, mais il n'y a pas encore d'identifiant de cluster. Si Tarantool n'a pas encore été initialisé, veut rejoindre le cluster, il doit envoyer une opération JOIN à l'un des maîtres qui peut l'exécuter, c'est-à-dire qu'il est en mode lecture-écriture. En réponse à JOIN, le maître envoie son instantané local à la réplique de connexion. La réplique le roule à la maison, alors qu'il n'a toujours pas d'identifiant. Maintenant, la réplique avec un léger décalage est synchronisée avec le cluster. Après cela, le maître sur lequel le JOIN a été exécuté attribue un identifiant à cette réplique, qui est enregistré et envoyé à la réplique. Lorsqu'un identifiant est attribué à une réplique, il devient un nœud à part entière et peut ensuite lancer la réplication des journaux de son côté.
Les lignes du journal sont envoyées à partir de l'état de cette réplique au moment de la demande du journal de réplication au maître, c'est-à-dire à partir de la vclock qu'il a reçue pendant le processus JOIN ou de l'endroit où la réplique s'est arrêtée plus tôt. Si le réplica est tombé pour une raison quelconque, la prochaine fois qu'il se connecte au cluster, il n'effectue plus JOIN, car il possède déjà un instantané local. Elle demande juste toutes les opérations qui ont eu lieu pendant son absence dans le cluster.
Enregistrer une réplique dans un cluster
Pour stocker l'état de la structure du cluster, un espace spécial est utilisé - cluster. Il contient les identifiants de serveur du cluster, leurs numéros de série et identifiants uniques.
[1, 'c35b285c-c5b1-4bbe-83b1-b825eb594aa4']
[2, '37b12cb7-d324-4d75-b428-cde92c18e708']
[3, 'b72b1aa6-42a0-4d73-a611-900e44cdd465']Il n'est pas nécessaire que les identifiants fonctionnent dans l'ordre, car les nœuds peuvent être supprimés et ajoutés.
Voici le premier écueil. En règle générale, les clusters ne sont pas collectés par un nœud: vous exécutez une certaine application et elle déploie l'ensemble du cluster à la fois. Mais la réplication dans Tarantool est asynchrone. Que se passe-t-il si deux maîtres connectent simultanément de nouveaux nœuds et leur attribuent des identifiants identiques? Il y aura un conflit.
Voici un exemple de jointure incorrecte et correcte:

Nous avons deux maîtres et deux répliques qui souhaitent se connecter. Ils font des JOIN sur différents maîtres. Supposons que les répliques obtiennent les mêmes identifiants. Ensuite, la réplication entre les maîtres et ceux qui parviennent à répliquer leurs journaux s'effondrera, le cluster s'effondrera.
Pour éviter que cela ne se produise, vous devez à tout moment lancer des répliques strictement sur un seul maître. À cette fin, Tarantool a introduit un tel concept en tant que leader d'initialisation et a implémenté un algorithme pour choisir ce leader. Une réplique qui souhaite se connecter au cluster établit d'abord une connexion avec tous les maîtres connus de la configuration transférée. Ensuite, la réplique sélectionne ceux qui ont déjà été lancés (lors du déploiement du cluster, tous les nœuds ne parviennent pas à gagner de l'argent). Et parmi eux, les masters disponibles pour l'enregistrement sont sélectionnés. Dans Tarantool, il y a lecture-écriture et lecture seule, nous ne pouvons pas nous inscrire sur le nœud en lecture seule. Après cela, dans la liste des nœuds filtrés, nous sélectionnons celui qui a l'UUID le plus bas.
Si nous utilisons la même configuration et la même liste de serveurs sur des instances non initialisées se connectant au cluster, ils sélectionneront le même maître, ce qui signifie que JOIN réussira très probablement.
De là, nous dérivons une règle: lors de la connexion de répliques à un cluster en parallèle, toutes ces répliques doivent avoir la même configuration de réplication. Si nous omettons quelque chose quelque part, il est possible que des instances avec une configuration différente soient lancées sur différents maîtres et que le cluster ne puisse pas se réunir.
Supposons que nous nous soyons trompés, ou que l'administrateur ait oublié de réparer la configuration, ou Ansible s'est cassé, et le cluster s'est encore effondré. Que peut en témoigner? Tout d'abord, les réplicas enfichables ne pourront pas créer leurs instantanés locaux: les réplicas ne démarrent pas et ne signalent pas d'erreurs. Deuxièmement, sur les maîtres dans les journaux, nous verrons des erreurs liées aux conflits dans le cluster spatial.
Comment résoudre cette situation? C'est simple:
- Tout d'abord, nous devons valider la configuration que nous avons définie pour les réplicas de connexion, car si nous ne la réparons pas, tout le reste sera inutile.
- Après cela, nous éliminons les conflits dans le cluster et prenons une photo.
Vous pouvez maintenant essayer à nouveau d'initialiser les répliques.
Résolution des conflits
Nous avons donc créé un cluster et connecté. Tous les nœuds fonctionnent en mode abonnement, c'est-à-dire qu'ils reçoivent les modifications générées par différents maîtres. La réplication étant asynchrone, des conflits sont possibles. Lorsque vous modifiez simultanément des données sur différents maîtres, différentes répliques obtiennent différentes copies des données, car les opérations peuvent être appliquées dans un ordre différent.
Voici un exemple de cluster après avoir exécuté JOIN:
Nous avons trois maîtres-esclaves, des journaux sont transmis entre eux, qui sont mandatés dans différentes directions et appliqués aux esclaves. Les données désynchronisées signifient que chaque réplique aura son propre historique de changement de vclock, car les flux de différents maîtres peuvent être mélangés ensemble. Mais alors l'ordre des opérations sur les instances peut varier. Si nos opérations ne sont pas commutatives, comme l'opération REMPLACER, les données que nous recevons sur ces répliques seront différentes.
Un petit exemple. Supposons que nous ayons deux maîtres avec vclock = {0,0}. Et les deux effectueront deux opérations, appelées op1,1, op1,2, op2,1, op2,2. Il s'agit de la deuxième tranche de temps lorsque chacun des maîtres a effectué une opération locale:

Le vert indique une modification du composant vclock correspondant. Tout d'abord, les deux maîtres modifient leur vclock, puis le second maître effectue une autre opération locale et augmente à nouveau la vclock. Le premier maître reçoit l'opération de réplication du second maître, ceci est indiqué par le numéro rouge 1 en vclock du premier nœud de cluster.

Ensuite, le deuxième maître reçoit l'opération du premier, et le premier - la deuxième opération du second. Et à la fin, le premier maître effectue sa dernière opération, et le second maître la reçoit.

Vclock dans le quantum de temps zéro, nous avons le même - {0,0}. Sur le dernier quantum de temps, nous avons aussi le même vclock {2,2}, il semblerait que les données devraient être les mêmes. Mais l'ordre des opérations effectuées sur chaque maître est différent. Et s'il s'agit d'une opération REMPLACER avec des valeurs différentes pour les mêmes clés? Ensuite, malgré la même vclock à la fin, nous obtiendrons différentes versions des données sur les deux répliques.
Nous sommes également en mesure de résoudre cette situation.
- Dossiers de partage . Tout d'abord, nous pouvons effectuer des opérations d'écriture non pas sur des répliques sélectionnées au hasard, mais en quelque sorte les scinder. Ils ont juste interrompu les opérations d'écriture sur différents maîtres et ont finalement obtenu un système de cohérence. Par exemple, les clés sont passées de 1 à 10 sur un maître et de 11 à 20 sur un autre - les nœuds échangeront leurs journaux et obtiendront exactement les mêmes données.
Le partage implique que nous avons un certain routeur. Il ne doit pas du tout être une entité distincte, le routeur peut faire partie de l'application. Il peut s'agir d'un fragment qui applique des opérations d'écriture à lui-même ou les transfère à un autre maître d'une manière ou d'une autre. Mais cela passe de telle manière que les changements dans les valeurs associées vont à un maître particulier: un bloc de valeur est allé à un maître, un autre bloc à un autre maître. Dans ce cas, les opérations de lecture peuvent être envoyées à n'importe quel nœud du cluster. Et n'oubliez pas la réplication asynchrone: si vous avez enregistré sur le même master, vous devrez peut-être également en lire.
- Ordre logique des opérations . Supposons que, selon les conditions du problème, vous pouvez en quelque sorte déterminer la priorité de l'opération. Dites, mettez un horodatage, une version ou une autre étiquette qui nous permettra de comprendre quelle opération s'est physiquement produite plus tôt. Autrement dit, nous parlons d'une source externe de commande.
Tarantool a un déclencheur before_replace qui peut être exécuté pendant la réplication. Dans ce cas, nous ne sommes pas limités par la nécessité d'acheminer les demandes, nous pouvons les envoyer où nous voulons. Mais lors de la réplication à l'entrée du flux de données, nous avons un déclencheur. Il lit la ligne envoyée, la compare à la ligne qui est déjà stockée et décide laquelle des lignes a une priorité plus élevée. En d'autres termes, le déclencheur ignore la demande de réplication ou l'applique, éventuellement avec les modifications requises. Nous appliquons déjà cette approche, mais elle a aussi ses inconvénients. Tout d'abord, vous avez besoin d'une source d'horloge externe. Supposons qu'un opérateur dans un salon de téléphonie mobile apporte des modifications à un abonné. Pour de telles opérations, vous pouvez utiliser l'heure sur l'ordinateur de l'opérateur, car il est peu probable que plusieurs opérateurs apportent des modifications à un même abonné en même temps. Les opérations peuvent venir de différentes manières, mais si chacune d'elles peut être affectée à une certaine version, alors lors du passage par des déclencheurs, seuls ceux qui sont pertinents resteront.
Deuxième inconvénient de la méthode: puisque le déclencheur est appliqué à chaque delta issu de la réplication pour chaque requête, cela crée une charge de calcul supplémentaire. Mais nous aurons alors une copie cohérente des données à l'échelle du cluster.
Sync
Notre réplication est asynchrone, c'est-à-dire qu'en exécutant la validation, vous ne savez pas si ces données se trouvent déjà sur un autre nœud de cluster. Si vous avez effectué un commit sur master, cela vous a été confirmé et que master pour une raison quelconque a immédiatement cessé de fonctionner, vous ne pouvez pas être sûr que les données ont été enregistrées ailleurs. Pour résoudre ce problème, le protocole de réplication Tarantool a un ACK. Chaque maître a connaissance du dernier ACK provenant de chaque esclave.
Qu'est-ce qu'un ACK? Lorsque l'esclave reçoit le delta, qui est marqué avec le maître lsn et son identifiant, puis en réponse, il envoie un paquet ACK spécial, dans lequel il emballe sa vclock locale après avoir appliqué cette opération. Voyons comment cela peut fonctionner.
Nous avons un maître qui a effectué 4 opérations en lui-même. Supposons qu'à un moment donné, l'esclave esclave reçoive les trois premières lignes et sa vclock augmente à {3.0}.
ACK n'est pas encore arrivé. Après avoir reçu ces trois lignes, l'esclave envoie le paquet ACK auquel il a cousu sa vclock au moment où le paquet a été envoyé. Laissez le maître esclave envoyer une autre ligne dans le même intervalle de temps, c'est-à-dire que la vitesse d'horloge de l'esclave a augmenté. Sur cette base, le maître n ° 1 sait avec certitude que les trois premières opérations qu'il a effectuées ont déjà été appliquées à cet esclave. Ces états sont stockés pour tous les esclaves avec lesquels le maître travaille; ils sont complètement indépendants.
Et à la fin, l'esclave répond avec un quatrième paquet ACK. Après cela, le maître sait que l'esclave est synchronisé avec lui.
Ce mécanisme peut être utilisé dans le code d'application. Lorsque vous validez une opération, vous ne reconnaissez pas immédiatement l'utilisateur, mais appelez d'abord une fonction spéciale. Il attend que l'esclave lsn connu du maître soit égal au lsn de votre maître à la fin de la validation. Vous n'avez donc pas besoin d'attendre la synchronisation complète, attendez simplement le moment mentionné.
Supposons que notre premier appel ait changé trois lignes et que le deuxième appel en ait changé une. Après le premier appel, vous voulez vous assurer que les données sont synchronisées. L'état indiqué ci-dessus signifie déjà que le premier appel a été synchronisé sur au moins un esclave.
Où chercher exactement des informations à ce sujet, nous considérerons dans la section suivante.
Suivi
Lorsque la réplication est synchrone, la surveillance est très simple: si elle s'effondre, des erreurs sont émises pour vos opérations. Et si la réplication est asynchrone, la situation devient confuse. Le Maître vous répond que tout va bien, cela fonctionne, accepté, écrit. Mais en même temps, toutes les répliques sont mortes, les données n'ont pas de redondance et si vous perdez le maître, vous perdrez les données. Par conséquent, je veux vraiment surveiller le cluster, comprendre ce qui se passe avec la réplication asynchrone, où se trouvent les répliques, dans quel état elles se trouvent.
Pour la surveillance de base, Tarantool possède une entité box.info. Cela vaut la peine de l'appeler dans la console, car vous verrez des données intéressantes.
id: 1 uuid: c35b285c-c5b1-4bbe-83b1-b825eb594aa4 lsn : 5 vclock : {2: 1, 1: 5} replication : 1: id: 1 uuid : c35b285c -c5b1 -4 bbe -83b1 - b825eb594aa4 lsn : 5 2: id: 2 uuid : 37 b12cb7 -d324 -4 d75 -b428 - cde92c18e708 lsn : 1 upstream : status : follow idle : 0.30358312401222 peer : lag: 3.6001205444336 e -05 downstream : vclock : {2: 1, 1: 5}
La métrique la plus importante est l'id
id . Dans ce cas, 1 signifie que le LSN de ce maître sera stocké dans la première position de tous les vclock. Une chose très utile. Si vous avez un conflit avec JOIN, vous ne pouvez distinguer un maître d'un autre que par des identifiants uniques. En outre, les quantités locales incluent des quantités telles que lsn. Il s'agit du numéro de la dernière ligne que ce maître a exécutée et écrite dans son journal. Dans notre exemple, le premier maître a effectué cinq opérations. Vclock est l'état des opérations qu'il sait qu'il s'est appliqué à lui-même. Et enfin, pour le maître numéro 2, il a effectué l'une de ses opérations de réplication.
Après les indicateurs de l'état local, vous pouvez voir ce que cette instance sait de l'état de la réplication de cluster; pour cela, il y a une section de
replication . Il répertorie tous les nœuds de cluster connus de l'instance, y compris lui-même. Le premier nœud a l'identifiant 1, id correspond à l'instance actuelle. Le deuxième nœud a l'identifiant 2, son lsn 1 correspond au lsn qui est écrit dans vclock. Dans ce cas, nous considérons la réplication maître-maître, lorsque le maître n ° 1 est à la fois le maître du deuxième nœud du cluster et son esclave, c'est-à-dire qu'il le suit.
- L'essence de l'
upstream . L'attribut status follow signifie que le maître 1 suit le maître 2. Inactif est le temps qui s'est écoulé localement depuis la dernière interaction avec ce maître. Nous n'envoyons pas de flux en continu, le maître n'envoie un delta que lorsque des changements s'y produisent. Lorsque nous envoyons une sorte d'ACK, nous communiquons également. De toute évidence, si le ralenti devient important (secondes, minutes, heures), alors quelque chose ne va pas. - Attribut de
lag . Nous avons parlé de décalage. En plus de lsn et de server id chaque opération dans le journal est également marquée d'un horodatage - heure locale pendant laquelle cette opération a été enregistrée en vclock sur le maître qui l'a effectuée. Dans le même temps, Slave compare son horodatage local avec l'horodatage du delta qu'il a reçu. Le dernier horodatage actuel reçu pour la dernière ligne, l'esclave s'affiche en surveillance. - Attribut en
downstream . Il montre ce que le maître sait de son esclave particulier. C'est l'ACK que l'esclave lui envoie. L' downstream présenté ci-dessus signifie que la dernière fois que son esclave, alias maître au numéro 2, lui a envoyé sa vclock, qui était de 5,1. Ce maître sait que ses cinq lignes, qu'il a terminées chez lui, sont parties pour un autre nœud.
Perte XLOG
Considérez la situation avec la chute du maître.
lsn : 0 id: 3 replication : 1: <...> upstream : status: disconnected peer : lag: 3.9100646972656 e -05 idle: 1602.836148153 message: connect, called on fd 13, aka [::1]:37960 2: <...> upstream : status : follow idle : 0.65611373598222 peer : lag: 1.9550323486328 e -05 3: <...> vclock : {2: 2, 1: 5}
Tout d'abord, le statut va changer.
Lag ne change pas car la ligne que nous avons appliquée reste la même, nous n'en avons pas obtenu de nouvelles. Dans le même temps, le
idle augmente, dans ce cas, il est déjà égal à 1602 secondes, tant de temps maître était mort. Et nous voyons un message d'erreur: il n'y a pas de connexion réseau.
Que faire dans une situation similaire? Nous découvrons ce qui s'est passé avec notre maître, attirons l'administrateur, redémarrez le serveur, élevons le nœud. Une réplication répétée est effectuée, et lorsque le maître pénètre dans le système, nous nous connectons à celui-ci, nous nous abonnons à son XLOG, les obtenons pour nous-mêmes et le cluster se stabilise.
Mais il y a un petit problème. Imaginez que nous avions un esclave qui, pour une raison quelconque, s'est éteint et a été absent pendant longtemps. Pendant ce temps, le maître qui l'a servi a supprimé le XLOG. Par exemple, le disque est plein, le garbage collector a collecté les journaux. Comment un esclave de retour peut-il continuer? Pas question. Parce que les journaux qu'il doit appliquer pour se synchroniser avec le cluster ont disparu et qu'il n'y a nulle part où les prendre. Dans ce cas, nous verrons une erreur intéressante: l'état n'est plus
disconnected , mais
stopped . Et un message spécifique: il n'y a pas de fichier journal correspondant à un tel lsn.
id: 3 replication : 1: <...> upstream : peer : status: stopped lag : 0.0001683235168457 idle : 9.4331328970147 message: 'Missing .xlog file between LSN 7 1: 5, 2: 2 and 8 1: 6, 2: 2' 2: <...> 3: <...> vclock : {2: 2, 1: 5}
En fait, la situation n'est pas toujours fatale. Supposons que nous ayons plus de deux maîtres, et sur certains d'entre eux, ces journaux sont toujours conservés. Nous les versons à tous les maîtres à la fois et ne les stockons pas sur un seul. Ensuite, il s'avère que cette réplique, se connectant à tous les maîtres qu'elle connaît, trouvera sur certains d'entre eux les journaux dont elle a besoin. Elle effectuera toutes ces opérations à la maison, sa vitesse d'horloge augmentera et elle atteindra l'état actuel du cluster. Après cela, vous pouvez essayer de vous reconnecter.
S'il n'y a aucun journal, nous ne pouvons pas continuer la réplique. Il ne reste plus qu'à le réinitialiser. N'oubliez pas son identifiant unique, vous pouvez l'écrire sur une feuille de papier ou dans un fichier. Ensuite, nous nettoyons la réplique localement: supprimez ses images, ses journaux, etc. Après cela, reconnectez la réplique avec le même UUID que celui qu'elle avait.
Supprimez le cluster ou réutilisez l'UUID pour la nouvelle réplique:
box.cfg{instance_uuid = uuid} .
, . UUID space cluster, . , . UUID, master, JOIN, , UUID, , .
, UUID , space cluster , . . , , .
, - . , . , , .
Tarantool .
replication_connect_quorum: 2
replication_connect_timeout: 30
replication_sync_lag: 0.1, , , , , , master' 0,1 . 30 . , . 0,1 . , .
Keep alive
, ip tables drop. , - 30 30 , , . , keep alive-.
keep alive- :
box.cfg.replication_timeout .
master' , keep alive-, , . 4 master slave keep alive- , . master'.
, . 6 , 5 . 10 , 9 . .
, , . , master', . - . .
6 , 3. , . , 5 , 3 .
, :
, Telegram-, . , GitHub, .