Partie 2/3 ici
Partie 3/3 ici
Bonjour à tous! Dans cet article, je souhaite rationaliser les informations et partager l'expérience de la création et de l'utilisation du cluster interne Kubernetes.
Au cours des dernières années, cette technologie d'orchestration de conteneurs a fait un grand pas en avant et est devenue une sorte de norme d'entreprise pour des milliers d'entreprises. Certains l'utilisent en production, d'autres le testent simplement sur des projets, mais les passions autour, peu importe comment vous le dites, brillent de sérieux. Si vous ne l'avez jamais utilisé auparavant, il est temps de commencer à sortir ensemble.
0. Introduction
Kubernetes est une technologie d'orchestration évolutive qui peut commencer par l'installation sur un seul nœud et atteindre la taille d'énormes clusters HA basés sur plusieurs centaines de nœuds à l'intérieur. Les fournisseurs de cloud les plus populaires proposent différents types d'implémentations Kubernetes - à prendre et à utiliser. Mais les situations sont différentes et il y a des entreprises qui n'utilisent pas les nuages et qui veulent profiter de tous les avantages des technologies d'orchestration modernes. Et voici l'installation de Kubernetes sur du métal nu.

1. Introduction
Dans cet exemple, nous allons créer un cluster Kubernetes HA avec la topologie pour plusieurs maîtres, avec un cluster externe etcd comme couche de base et un équilibreur de charge MetalLB à l'intérieur. Sur tous les nœuds de travail, nous déploierons GlusterFS comme un simple stockage de cluster distribué interne. Nous essaierons également d'y déployer plusieurs projets de test à l'aide de notre registre Docker personnel.
En général, il existe plusieurs façons de créer un cluster Kubernetes HA: le chemin difficile et détaillé décrit dans le document populaire kubernetes-the-hard-way , ou la manière plus simple à l'aide de l'utilitaire kubeadm .
Kubeadm est un outil créé par la communauté Kubernetes spécifiquement pour simplifier l'installation de Kubernetes et faciliter le processus. Auparavant, Kubeadm était recommandé uniquement pour créer de petits clusters de test avec un nœud maître, pour commencer. Mais au cours de la dernière année, beaucoup de choses ont été améliorées, et maintenant nous pouvons l'utiliser pour créer des clusters HA avec plusieurs nœuds maîtres. Selon les nouvelles de la communauté Kubernetes, à l'avenir, Kubeadm sera recommandé comme outil pour installer Kubernetes.
La documentation de Kubeadm propose deux méthodes de base pour implémenter un cluster, avec une pile et des topologies etcd externes. Je choisirai le deuxième chemin avec les nœuds etcd externes en raison de la tolérance aux pannes du cluster HA.
Voici un diagramme de la documentation Kubeadm décrivant ce chemin:
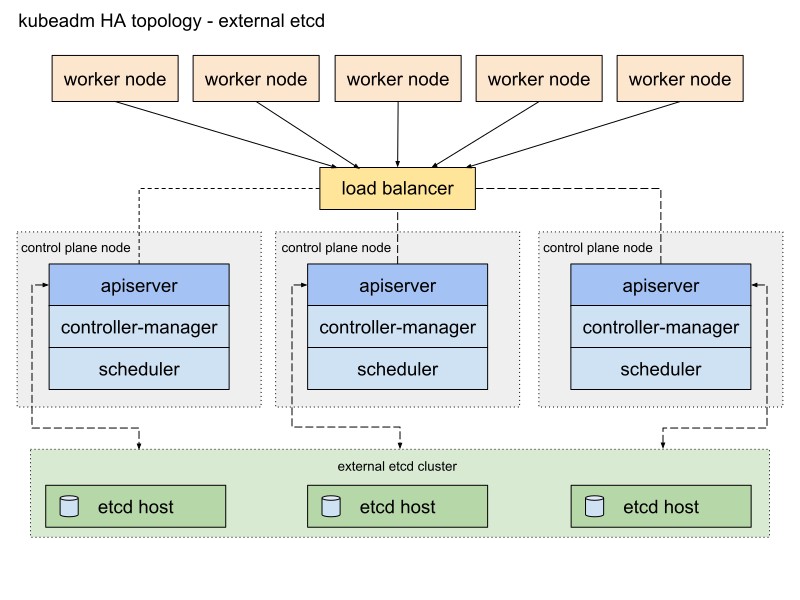
Je vais le changer un peu. Tout d'abord, j'utiliserai une paire de serveurs HAProxy comme équilibreurs de charge avec le package Heartbeat, qui partagera l'adresse IP virtuelle. Heartbeat et HAProxy utilisent une petite quantité de ressources système, je vais donc les placer sur une paire de nœuds etcd pour réduire légèrement le nombre de serveurs pour notre cluster.
Pour ce schéma de cluster Kubernetes, huit nœuds sont requis. Trois serveurs pour un cluster externe, etc. (les services LB en utiliseront également quelques-uns), deux pour les nœuds du plan de contrôle (nœuds maîtres) et trois pour les nœuds de travail. Il peut s'agir d'un serveur nu ou d'un serveur VM. Dans ce cas, cela n'a pas d'importance. Vous pouvez facilement modifier le schéma en ajoutant plus de nœuds maîtres et en plaçant HAProxy avec Heartbeat sur des nœuds séparés, s'il existe de nombreux serveurs gratuits. Bien que mon option pour la première implémentation du cluster HA soit suffisante pour les yeux.
Si vous le souhaitez, ajoutez un petit serveur avec l'utilitaire kubectl installé pour gérer ce cluster ou utilisez votre propre bureau Linux pour cela.
Le diagramme de cet exemple ressemblera à ceci:
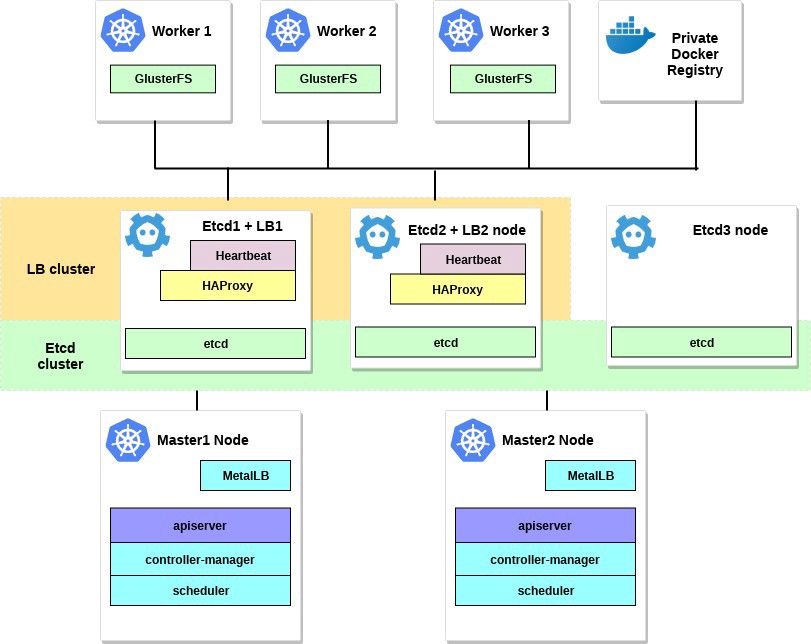
2. Exigences
Vous aurez besoin de deux nœuds maîtres Kubernetes avec la configuration système minimale recommandée: 2 CPU et 2 Go de RAM conformément à la documentation de kubeadm . Pour les nœuds de travail, je recommande d'utiliser des serveurs plus puissants, car nous exécuterons tous nos services d'application sur eux. Et pour Etcd + LB, nous pouvons également prendre des serveurs avec deux processeurs et au moins 2 Go de RAM.
Sélectionnez un réseau public ou privé pour ce cluster; Les adresses IP n'ont pas d'importance; Il est important que tous les serveurs soient accessibles les uns pour les autres et, bien sûr, pour vous. Plus tard, à l'intérieur du cluster Kubernetes, nous mettrons en place un réseau de superposition.
Les exigences minimales pour cet exemple sont:
- 2 serveurs avec 2 processeurs et 2 Go de RAM pour le nœud maître
- 3 serveurs avec 4 processeurs et 4 à 8 Go de RAM pour les nœuds de travail
- 3 serveurs avec 2 processeurs et 2 Go de RAM pour Etcd et HAProxy
- 192.168.0.0/24 - le sous-réseau.
192.168.0.1 - l'adresse IP virtuelle de HAProxy, 192.168.0.2 - 4 adresses IP principales des nœuds Etcd et HAProxy, 192.168.0.5 - 6 adresses IP principales du nœud maître Kubernetes, 192.168.0.7 - 9 adresses IP principales des nœuds de travail Kubernetes .
La base de données Debian 9 est installée sur tous les serveurs.
N'oubliez pas non plus que la configuration requise dépend de la taille et de la puissance du cluster. Pour plus d'informations, consultez la documentation de Kubernetes.
3. Configurez HAProxy et Heartbeat.
Nous avons plus d'un nœud maître Kubernetes, et vous devez donc configurer un équilibreur de charge HAProxy en face d'eux - pour répartir le trafic. Ce sera une paire de serveurs HAProxy avec une adresse IP virtuelle partagée. La tolérance aux pannes est fournie avec le package Heartbeat. Pour le déploiement, nous utiliserons les deux premiers serveurs etcd.
Installez et configurez HAProxy avec Heartbeat sur les premier et deuxième serveurs etcd (192.168.0.2–3 dans cet exemple):
etcd1# apt-get update && apt-get upgrade && apt-get install -y haproxy etcd2# apt-get update && apt-get upgrade && apt-get install -y haproxy
Enregistrez la configuration d'origine et créez-en une nouvelle:
etcd1# mv /etc/haproxy/haproxy.cfg{,.back} etcd1# vi /etc/haproxy/haproxy.cfg etcd2# mv /etc/haproxy/haproxy.cfg{,.back} etcd2# vi /etc/haproxy/haproxy.cfg
Ajoutez ces options de configuration pour les deux HAProxy:
global user haproxy group haproxy defaults mode http log global retries 2 timeout connect 3000ms timeout server 5000ms timeout client 5000ms frontend kubernetes bind 192.168.0.1:6443 option tcplog mode tcp default_backend kubernetes-master-nodes backend kubernetes-master-nodes mode tcp balance roundrobin option tcp-check server k8s-master-0 192.168.0.5:6443 check fall 3 rise 2 server k8s-master-1 192.168.0.6:6443 check fall 3 rise 2
Comme vous pouvez le voir, les deux services HAProxy partagent l'adresse IP - 192.168.0.1. Cette adresse IP virtuelle se déplacera entre les serveurs, nous allons donc être un peu rusés et activer le paramètre net.ipv4.ip_nonlocal_bind pour permettre la liaison des services système à une adresse IP non locale.
Ajoutez cette fonctionnalité au fichier /etc/sysctl.conf :
etcd1# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1 etcd2# vi /etc/sysctl.conf net.ipv4.ip_nonlocal_bind=1
Exécutez sur les deux serveurs:
sysctl -p
Exécutez également HAProxy sur les deux serveurs:
etcd1# systemctl start haproxy etcd2# systemctl start haproxy
Assurez-vous que HAProxy est en cours d'exécution et écoute sur l'adresse IP virtuelle sur les deux serveurs:
etcd1# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy etcd2# netstat -ntlp tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy
Hood! Installez maintenant Heartbeat et configurez cette IP virtuelle.
etcd1# apt-get -y install heartbeat && systemctl enable heartbeat etcd2# apt-get -y install heartbeat && systemctl enable heartbeat
Il est temps de créer plusieurs fichiers de configuration pour cela: pour les premier et deuxième serveurs, ils seront fondamentalement les mêmes.
Créez d'abord le fichier /etc/ha.d/authkeys , dans ce fichier Heartbeat stocke les données pour l'authentification mutuelle. Le fichier doit être le même sur les deux serveurs:
# echo -n securepass | md5sum bb77d0d3b3f239fa5db73bdf27b8d29a etcd1# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a etcd2# vi /etc/ha.d/authkeys auth 1 1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a
Ce fichier ne doit être accessible qu'à root:
etcd1# chmod 600 /etc/ha.d/authkeys etcd2# chmod 600 /etc/ha.d/authkeys
Créez maintenant le fichier de configuration principal de Heartbeat sur les deux serveurs: pour chaque serveur, il sera légèrement différent.
Créez /etc/ha.d/ha.cf :
etcd1
etcd1# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.3 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to log/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
etcd2
etcd2# vi /etc/ha.d/ha.cf # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # # What UDP port to use for udp or ppp-udp communication? # udpport 694 bcast ens18 mcast ens18 225.0.0.1 694 1 0 ucast ens18 192.168.0.2 # What interfaces to heartbeat over? udp ens18 # # Facility to use for syslog()/logger (alternative to vlog/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node etcd1_hostname node etcd2_hostname
Obtenez les paramètres «nœud» pour cette configuration en exécutant uname -n sur les deux serveurs Etcd. Utilisez également le nom de votre carte réseau au lieu de ens18.
Enfin, vous devez créer le fichier /etc/ha.d/haresources sur ces serveurs. Pour les deux serveurs, le fichier doit être le même. Dans ce fichier, nous définissons notre adresse IP commune et déterminons quel nœud est le maître par défaut:
etcd1# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1 etcd2# vi /etc/ha.d/haresources etcd1_hostname 192.168.0.1
Lorsque tout est prêt, démarrez les services Heartbeat sur les deux serveurs et vérifiez que nous avons reçu cette IP virtuelle déclarée sur le nœud etcd1:
etcd1# systemctl restart heartbeat etcd2# systemctl restart heartbeat etcd1# ip a ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff inet 192.168.0.2/24 brd 192.168.0.255 scope global ens18 valid_lft forever preferred_lft forever inet 192.168.0.1/24 brd 192.168.0.255 scope global secondary
Vous pouvez vérifier que HAProxy fonctionne correctement en exécutant nc à 192.168.0.1 6443. Vous devez avoir expiré car l'API Kubernetes n'écoute pas encore côté serveur. Mais cela signifie que HAProxy et Heartbeat sont correctement configurés.
# nc -v 192.168.0.1 6443 Connection to 93.158.95.90 6443 port [tcp/*] succeeded!
4. Préparation des nœuds pour Kubernetes
L'étape suivante consiste à préparer tous les nœuds Kubernetes. Vous devez installer Docker avec des packages supplémentaires, ajouter le référentiel Kubernetes et installer les packages kubelet , kubeadm , kubectl à partir de celui-ci. Ce paramètre est le même pour tous les nœuds Kubernetes (maître, travailleurs, etc.)
Le principal avantage de Kubeadm est qu'il n'y a pas vraiment besoin de logiciels supplémentaires. Installez kubeadm sur tous les hôtes - et utilisez-le; générer au moins des certificats CA.
Installez Docker sur tous les nœuds:
Update the apt package index # apt-get update Install packages to allow apt to use a repository over HTTPS # apt-get -y install \ apt-transport-https \ ca-certificates \ curl \ gnupg2 \ software-properties-common Add Docker's official GPG key # curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - Add docker apt repository # apt-add-repository \ "deb [arch=amd64] https://download.docker.com/linux/debian \ $(lsb_release -cs) \ stable" Install docker-ce. # apt-get update && apt-get -y install docker-ce Check docker version # docker -v Docker version 18.09.0, build 4d60db4
Après cela, installez les packages Kubernetes sur tous les nœuds:
kubeadm : commande pour charger le cluster.kubelet : un composant qui s'exécute sur tous les ordinateurs du cluster et effectue des actions telles que le lancement de foyers et de conteneurs.kubectl : kubectl ligne de commande pour communiquer avec le cluster.- kubectl - à volonté; Je l'installe souvent sur tous les nœuds pour exécuter certaines commandes Kubernetes pour le débogage.
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository # cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install packages # apt-get update && apt-get install -y kubelet kubeadm kubectl Hold back packages # apt-mark hold kubelet kubeadm kubectl Check kubeadm version # kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.1", GitCommit:"eec55b9dsfdfgdfgfgdfgdfgdf365bdd920", GitTreeState:"clean", BuildDate:"2018-12-13T10:36:44Z", GoVersion:"go1.11.2", Compiler:"gc", Platform:"linux/amd64"}
Après avoir installé kubeadm et d'autres packages, n'oubliez pas de désactiver le swap.
# swapoff -a # sed -i '/ swap / s/^/#/' /etc/fstab
Répétez l'installation sur les nœuds restants. Les packages logiciels sont les mêmes pour tous les nœuds du cluster, et seule la configuration suivante déterminera les rôles qu'ils recevront ultérieurement.
5. Configurer le cluster HA Etcd
Ainsi, après avoir terminé les préparatifs, nous allons configurer le cluster Kubernetes. La première brique sera le cluster HA Etcd, qui est également configuré à l'aide de l'outil kubeadm.
Avant de commencer, assurez-vous que tous les nœuds etcd communiquent via les ports 2379 et 2380. De plus, vous devez configurer l'accès ssh entre eux pour utiliser scp .
Commençons par le premier nœud etcd, puis copions simplement tous les certificats et fichiers de configuration nécessaires sur les autres serveurs.
Sur tous les nœuds etcd , vous devez ajouter un nouveau fichier de configuration systemd pour l'unité kubelet avec une priorité plus élevée:
etcd-nodes# cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf [Service] ExecStart= ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true Restart=always EOF etcd-nodes# systemctl daemon-reload etcd-nodes# systemctl restart kubelet
Ensuite, nous passerons par ssh au premier nœud etcd - nous l'utiliserons pour générer toutes les configurations kubeadm nécessaires pour chaque nœud etcd , puis les copier.
# Export all our etcd nodes IP's as variables etcd1# export HOST0=192.168.0.2 etcd1# export HOST1=192.168.0.3 etcd1# export HOST2=192.168.0.4 # Create temp directories to store files for all nodes etcd1# mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/ etcd1# ETCDHOSTS=(${HOST0} ${HOST1} ${HOST2}) etcd1# NAMES=("infra0" "infra1" "infra2") etcd1# for i in "${!ETCDHOSTS[@]}"; do HOST=${ETCDHOSTS[$i]} NAME=${NAMES[$i]} cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml apiVersion: "kubeadm.k8s.io/v1beta1" kind: ClusterConfiguration etcd: local: serverCertSANs: - "${HOST}" peerCertSANs: - "${HOST}" extraArgs: initial-cluster: ${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380 initial-cluster-state: new name: ${NAME} listen-peer-urls: https://${HOST}:2380 listen-client-urls: https://${HOST}:2379 advertise-client-urls: https://${HOST}:2379 initial-advertise-peer-urls: https://${HOST}:2380 EOF done
Créez maintenant l'autorité de certification principale à l'aide de kubeadm
etcd1# kubeadm init phase certs etcd-ca
Cette commande créera deux fichiers ca.crt & ca.key dans le répertoire / etc / kubernetes / pki / etcd / .
etcd1# ls /etc/kubernetes/pki/etcd/ ca.crt ca.key
Nous allons maintenant générer des certificats pour tous les nœuds etcd :
### Create certificates for the etcd3 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST2}/ ### cleanup non-reusable certificates etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the etcd2 node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST1}/ ### cleanup non-reusable certificates again etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete ### Create certificates for the this local node etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1 #kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml # No need to move the certs because they are for this node # clean up certs that should not be copied off this host etcd1# find /tmp/${HOST2} -name ca.key -type f -delete etcd1# find /tmp/${HOST1} -name ca.key -type f -delete
Copiez ensuite les certificats et les configurations de kubeadm sur les nœuds etcd2 et etcd3 .
Générez d' abord une paire de clés ssh sur etcd1 et ajoutez la partie publique aux nœuds etcd2 et 3 . Dans cet exemple, toutes les commandes sont exécutées au nom d'un utilisateur qui possède tous les droits sur le système.
etcd1# scp -r /tmp/${HOST1}/* ${HOST1}: etcd1# scp -r /tmp/${HOST2}/* ${HOST2}: ### login to the etcd2 or run this command remotely by ssh etcd2# cd /root etcd2# mv pki /etc/kubernetes/ ### login to the etcd3 or run this command remotely by ssh etcd3# cd /root etcd3# mv pki /etc/kubernetes/
Avant de démarrer le cluster etcd, assurez-vous que les fichiers existent sur tous les nœuds:
Liste des fichiers requis sur etcd1 :
/tmp/192.168.0.2 └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── ca.key ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Pour le nœud etcd2, c'est:
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Et le dernier nœud est etcd3 :
/root └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key
Lorsque tous les certificats et configurations sont en place, nous créons des manifestes. Sur chaque nœud, exécutez la commande kubeadm - pour générer un manifeste statique pour le cluster etcd :
etcd1# kubeadm init phase etcd local --config=/tmp/192.168.0.2/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml
Maintenant, le cluster etcd - en théorie - est configuré et sain. Vérifiez en exécutant la commande suivante sur le nœud etcd1:
etcd1# docker run --rm -it \ --net host \ -v /etc/kubernetes:/etc/kubernetes quay.io/coreos/etcd:v3.2.24 etcdctl \ --cert-file /etc/kubernetes/pki/etcd/peer.crt \ --key-file /etc/kubernetes/pki/etcd/peer.key \ --ca-file /etc/kubernetes/pki/etcd/ca.crt \ --endpoints https://192.168.0.2:2379 cluster-health ### status output member 37245675bd09ddf3 is healthy: got healthy result from https://192.168.0.3:2379 member 532d748291f0be51 is healthy: got healthy result from https://192.168.0.4:2379 member 59c53f494c20e8eb is healthy: got healthy result from https://192.168.0.2:2379 cluster is healthy
Le cluster etcd a augmenté, alors continuez.
6. Configuration des nœuds maître et de travail
Configurez les nœuds maîtres de notre cluster - copiez ces fichiers du premier nœud etcd vers le premier nœud maître:
etcd1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt 192.168.0.5: etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.key 192.168.0.5:
Ensuite, allez ssh sur le nœud maître master1 et créez le fichier kubeadm-config.yaml avec le contenu suivant:
master1# cd /root && vi kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: stable apiServer: certSANs: - "192.168.0.1" controlPlaneEndpoint: "192.168.0.1:6443" etcd: external: endpoints: - https://192.168.0.2:2379 - https://192.168.0.3:2379 - https://192.168.0.4:2379 caFile: /etc/kubernetes/pki/etcd/ca.crt certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
Déplacez les certificats et la clé copiés précédemment vers le répertoire approprié sur le nœud master1, comme dans la description du paramètre.
master1# mkdir -p /etc/kubernetes/pki/etcd/ master1# cp /root/ca.crt /etc/kubernetes/pki/etcd/ master1# cp /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ master1# cp /root/apiserver-etcd-client.key /etc/kubernetes/pki/
Pour créer le premier nœud maître, procédez comme suit:
master1# kubeadm init --config kubeadm-config.yaml
Si toutes les étapes précédentes sont terminées correctement, vous verrez ce qui suit:
You can now join any number of machines by running the following on each node as root: kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
Copiez cette sortie d' initialisation kubeadm dans n'importe quel fichier texte, nous utiliserons ce jeton à l'avenir lorsque nous attacherons le deuxième maître et les nœuds de travail à notre cluster.
J'ai déjà dit que le cluster Kubernetes utilisera une sorte de réseau de superposition pour les foyers et autres services, donc à ce stade, vous devez installer une sorte de plugin CNI. Je recommande le plugin Weave CNI . L'expérience a montré qu'il est plus utile et moins problématique, mais vous pouvez en choisir un autre, par exemple Calico.
Installation du plugin réseau Weave sur le premier nœud maître:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" The connection to the server localhost:8080 was refused - did you specify the right host or port? serviceaccount/weave-net created clusterrole.rbac.authorization.k8s.io/weave-net created clusterrolebinding.rbac.authorization.k8s.io/weave-net created role.rbac.authorization.k8s.io/weave-net created rolebinding.rbac.authorization.k8s.io/weave-net created daemonset.extensions/weave-net created
Attendez un moment, puis entrez la commande suivante pour vérifier que les foyers de composants démarrent:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 6m25s coredns-86c58d9df4-xj98p 1/1 Running 0 6m25s kube-apiserver-master1 1/1 Running 0 5m22s kube-controller-manager-master1 1/1 Running 0 5m41s kube-proxy-8ncqw 1/1 Running 0 6m25s kube-scheduler-master1 1/1 Running 0 5m25s weave-net-lvwrp 2/2 Running 0 78s
- Il est recommandé d'attacher de nouveaux nœuds du plan de contrôle uniquement après l'initialisation du premier nœud.
Pour vérifier l'état du cluster, procédez comme suit:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 11m v1.13.1
Super! Le premier nœud maître s'est levé. Maintenant, il est prêt et nous terminerons la création du cluster Kubernetes - nous ajouterons un deuxième nœud maître et des nœuds de travail.
Pour ajouter un deuxième nœud maître, créez une clé ssh sur master1 et ajoutez la partie publique à master2 . Effectuez une connexion de test, puis copiez certains fichiers du premier nœud maître vers le second:
master1# scp /etc/kubernetes/pki/ca.crt 192.168.0.6: master1# scp /etc/kubernetes/pki/ca.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.key 192.168.0.6: master1# scp /etc/kubernetes/pki/sa.pub 192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/front-proxy-ca.key @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt @192.168.0.6: master1# scp /etc/kubernetes/pki/apiserver-etcd-client.key @192.168.0.6: master1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.6:etcd-ca.crt master1# scp /etc/kubernetes/admin.conf 192.168.0.6: ### Check that files was copied well master2# ls /root admin.conf ca.crt ca.key etcd-ca.crt front-proxy-ca.crt front-proxy-ca.key sa.key sa.pub
Sur le deuxième nœud maître, déplacez les certificats et clés précédemment copiés vers les répertoires appropriés:
master2# mkdir -p /etc/kubernetes/pki/etcd mv /root/ca.crt /etc/kubernetes/pki/ mv /root/ca.key /etc/kubernetes/pki/ mv /root/sa.pub /etc/kubernetes/pki/ mv /root/sa.key /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.crt /etc/kubernetes/pki/ mv /root/apiserver-etcd-client.key /etc/kubernetes/pki/ mv /root/front-proxy-ca.crt /etc/kubernetes/pki/ mv /root/front-proxy-ca.key /etc/kubernetes/pki/ mv /root/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt mv /root/admin.conf /etc/kubernetes/admin.conf
Connectez le deuxième nœud maître au cluster. Pour ce faire, vous avez besoin de la sortie de la commande de connexion, qui nous a été précédemment transmise par kubeadm init sur le premier nœud.
Exécutez le nœud maître master2 :
master2# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6 --experimental-control-plane
- Vous devez ajouter le
--experimental-control-plane . Il automatise la connexion des données de base à un cluster. Sans cet indicateur, le nœud de travail habituel sera simplement ajouté.
Attendez un peu que le nœud rejoigne le cluster et vérifiez le nouvel état du cluster:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 32m v1.13.1 master2 Ready master 46s v1.13.1
Assurez-vous également que tous les pods de tous les nœuds maîtres sont démarrés normalement:
master1# kubectl — kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-86c58d9df4-d7qfw 1/1 Running 0 46m coredns-86c58d9df4-xj98p 1/1 Running 0 46m kube-apiserver-master1 1/1 Running 0 45m kube-apiserver-master2 1/1 Running 0 15m kube-controller-manager-master1 1/1 Running 0 45m kube-controller-manager-master2 1/1 Running 0 15m kube-proxy-8ncqw 1/1 Running 0 46m kube-proxy-px5dt 1/1 Running 0 15m kube-scheduler-master1 1/1 Running 0 45m kube-scheduler-master2 1/1 Running 0 15m weave-net-ksvxz 2/2 Running 1 15m weave-net-lvwrp 2/2 Running 0 41m
Super! Nous avons presque terminé avec la configuration du cluster Kubernetes. Et la dernière chose à faire est d'ajouter les trois nœuds de travail que nous avons préparés plus tôt.
Entrez les nœuds de travail et exécutez la commande kubeadm join sans l' --experimental-control-plane .
worker1-3# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6
Vérifiez à nouveau l'état du cluster:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 1h30m v1.13.1 master2 Ready master 1h59m v1.13.1 worker1 Ready <none> 1h8m v1.13.1 worker2 Ready <none> 1h8m v1.13.1 worker3 Ready <none> 1h7m v1.13.1
Comme vous pouvez le voir, nous avons un cluster Kubernetes HA entièrement configuré avec deux nœuds maître et trois nœuds de travail. Il est construit sur la base du cluster HA etcd avec un équilibreur de charge à sécurité intégrée devant les nœuds maîtres. Cela me semble assez bon.
7. Configuration de la gestion de cluster à distance
Une autre action qui reste à considérer dans cette première partie de l'article est la configuration de l'utilitaire kubectl distant pour la gestion du cluster. Auparavant, nous exécutions toutes les commandes du nœud maître master1 , mais cela ne convient que pour la première fois - lors de la configuration du cluster. Ce serait bien de configurer un nœud de contrôle externe. Vous pouvez utiliser un ordinateur portable ou un autre serveur pour cela.
Connectez-vous à ce serveur et exécutez:
Add the Google repository key control# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - Add the Google repository control# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF Update and install kubectl control# apt-get update && apt-get install -y kubectl In your user home dir create control# mkdir ~/.kube Take the Kubernetes admin.conf from the master1 node control# scp 192.168.0.5:/etc/kubernetes/admin.conf ~/.kube/config Check that we can send commands to our cluster control# kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready master 6h58m v1.13.1 master2 Ready master 6h27m v1.13.1 worker1 Ready <none> 5h36m v1.13.1 worker2 Ready <none> 5h36m v1.13.1 worker3 Ready <none> 5h36m v1.13.1
Ok, exécutons maintenant un test sous dans notre cluster et vérifions comment cela fonctionne.
control# kubectl create deployment nginx --image=nginx deployment.apps/nginx created control# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-5c7588df-6pvgr 1/1 Running 0 52s
Félicitations! Vous venez de déployer Kubernetes. Et cela signifie que votre nouveau cluster HA est prêt. En fait, le processus de configuration d'un cluster Kubernetes à l' aide de kubeadm est assez simple et rapide.
Dans la partie suivante de l'article, nous ajouterons du stockage interne en configurant GlusterFS sur tous les nœuds de travail, en configurant un équilibreur de charge interne pour notre cluster Kubernetes, et en exécutant également certains tests de stress, en déconnectant certains nœuds et en vérifiant la stabilité du cluster.
Postface
Oui, en travaillant sur cet exemple, vous rencontrerez un certain nombre de problèmes. Ne vous inquiétez pas: pour annuler les modifications et ramener les nœuds à leur état d'origine, exécutez simplement kubeadm reset - les modifications que kubeadm a apportées précédemment seront réinitialisées et vous pourrez configurer à nouveau. N'oubliez pas non plus de vérifier l'état des conteneurs Docker sur les nœuds du cluster - assurez-vous qu'ils démarrent et fonctionnent tous sans erreur. Pour plus d'informations sur les conteneurs endommagés, utilisez la commande docker logs containerid .
C'est tout pour aujourd'hui. Bonne chance