Bonjour à tous! Je vous présente une traduction d'un article d' Analytics Vidhya avec un aperçu des événements AI / ML dans les tendances 2018 et 2019. Le matériau est assez grand, il est donc divisé en 2 parties. J'espère que l'article intéressera non seulement les spécialistes spécialisés, mais aussi ceux qui s'intéressent au sujet de l'IA. Bonne lecture!
Navigation dans l'article
Présentation
Les dernières années pour les passionnés de l'IA et les professionnels du machine learning se sont écoulées dans la poursuite d'un rêve. Ces technologies ont cessé d'être des créneaux, sont devenues courantes et affectent déjà la vie de millions de personnes en ce moment. Des ministères de l'IA ont été créés dans différents pays [
plus de détails ici - env. par.] et les budgets sont alloués pour suivre cette course.
Il en va de même pour les professionnels de la science des données. Il y a quelques années, vous pouviez vous sentir à l'aise avec quelques outils et astuces, mais ce temps est révolu. Le nombre d'événements récents en science des données et la quantité de connaissances nécessaires pour suivre le rythme dans ce domaine sont incroyables.
J'ai décidé de prendre du recul et de regarder les développements dans certains domaines clés dans le domaine de l'intelligence artificielle du point de vue des experts en science des données. Quelles évasions se sont produites? Que s'est-il passé en 2018 et à quoi s'attendre en 2019? Lisez cet article pour des réponses!
PS Comme dans toute prévision, voici mes conclusions personnelles basées sur les tentatives de combiner des fragments individuels dans l'image entière. Si votre point de vue est différent du mien, je serai heureux de connaître votre opinion sur ce qui pourrait changer dans la science des données en 2019.
Les domaines que nous aborderons dans cet article sont:
- Processus de langage naturel (PNL)
- Vision par ordinateur
- Outils et bibliothèques
- Apprentissage par renforcement
- Problèmes éthiques en IA
Traitement du langage naturel (PNL)
Forcer les machines à analyser des mots et des phrases a toujours semblé être un rêve chimérique. Il y a beaucoup de nuances et de fonctionnalités dans les langues qui sont parfois difficiles à comprendre même pour les gens, mais 2018 a été un véritable tournant pour la PNL.
Nous avons observé une formidable percée après l'autre: ULMFiT, ELMO, OpenAl Transformer, Google BERT, et ce n'est pas une liste complète. L'application réussie de l'apprentissage par transfert (l'art d'appliquer des modèles pré-formés aux données) a ouvert la porte à la PNL dans une variété de tâches.
Transfert d'apprentissage - vous permet d'adapter un modèle / système pré-formé à votre tâche spécifique en utilisant une quantité relativement faible de données.
Examinons plus en détail certains de ces développements clés.
ULMFiT
Développé par Sebastian Ruder et Jeremy Howard (fast.ai), ULMFiT a été le premier framework à recevoir un apprentissage par transfert cette année. Pour les non-initiés, l'acronyme ULMFiT signifie «Universal Language Model Fine-Tuning». Jeremy et Sebastian ont ajouté à juste titre le mot «universel» à ULMFiT - ce cadre peut être appliqué à presque toutes les tâches de PNL!
La meilleure chose à propos d'ULMFiT est que vous n'avez pas besoin de former des modèles à partir de zéro! Les chercheurs ont déjà fait le plus difficile pour vous - prenez et postulez dans vos projets. ULMFiT a surpassé les autres méthodes dans six tâches de classification de texte.
Vous pouvez
lire le tutoriel de Pratek Joshi [Pateek Joshi - env. trans.] sur la façon de commencer à utiliser ULMFiT pour toute tâche de classification de texte.
ELMo
Devinez ce que l'abréviation ELMo signifie? Acronyme de Embeddings from Language Models [pièces jointes des modèles linguistiques - env. trans.]. Et ELMo a attiré l'attention de la communauté ML juste après la sortie.
ELMo utilise des modèles de langage pour recevoir des pièces jointes pour chaque mot, et prend également en compte le contexte dans lequel le mot s'inscrit dans une phrase ou un paragraphe. Le contexte est un aspect critique de la PNL, dans lequel la plupart des développeurs ont précédemment échoué. ELMo utilise des LSTM bidirectionnels pour créer des pièces jointes.
La mémoire à court terme à long terme (LSTM) est un type d'architecture de réseaux de neurones récurrents proposé en 1997 par Sepp Hochreiter et Jürgen Schmidhuber. Comme la plupart des réseaux de neurones récurrents, un réseau LSTM est universel dans le sens où, avec un nombre suffisant d'éléments de réseau, il peut effectuer tout calcul dont un ordinateur ordinaire est capable, ce qui nécessite une matrice de poids appropriée qui peut être considérée comme un programme. Contrairement aux réseaux de neurones récurrents traditionnels, le réseau LSTM est bien adapté à la formation sur les problèmes de classification, de traitement et de prévision des séries chronologiques dans les cas où des événements importants sont séparés par des décalages temporels à durée et limites indéfinies.
- source. Wikipédia
Comme ULMFiT, ELMo améliore considérablement la productivité dans la résolution d'un grand nombre de tâches PNL, telles que l'analyse de l'humeur du texte ou la réponse aux questions.
BERT de Google
Beaucoup d'experts notent que la sortie de BERT a marqué le début d'une nouvelle ère en PNL. Après ULMFiT et ELMo, BERT a pris les devants, démontrant des performances élevées. Comme l'indique l'annonce originale: «L'ORET est conceptuellement simple et empiriquement puissant.»
Le BERT a montré des résultats exceptionnels dans 11 tâches PNL! Voir les résultats dans les tests SQuAD:
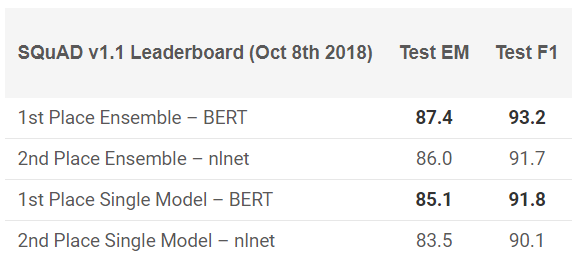
Vous voulez l'essayer? Vous pouvez utiliser la réimplémentation sur PyTorch ou le code TensorFlow de Google et essayer de répéter le résultat sur votre machine.
Facebook PyText
Comment Facebook pourrait-il rester à l'écart de cette course? La société propose son propre framework NLP open source appelé PyText. Selon une étude publiée par Facebook, PyText a augmenté la précision des modèles conversationnels de 10% et réduit le temps de formation.
PyText est en fait derrière plusieurs des propres produits de Facebook, tels que Messenger. Travailler avec lui ajoutera donc un bon point à votre portefeuille et des connaissances inestimables que vous gagnerez sans aucun doute.
Vous pouvez l'essayer vous-même,
téléchargez le code depuis GitHub .
Google duplex
Il est difficile de croire que vous n'avez pas entendu parler de Google Duplex. Voici une démo qui a longtemps fait la une des journaux:
Comme il s'agit d'un produit Google, il y a peu de chances que tôt ou tard le code soit publié pour tout le monde. Bien sûr, cette démonstration soulève de nombreuses questions: de l'éthique aux problèmes de confidentialité, mais nous en parlerons plus tard. Pour l'instant, profitez simplement du chemin parcouru avec ML ces dernières années.
Tendances PNL 2019
Qui mieux que Sebastian Ruder lui-même peut donner une idée de la direction que prendra la PNL en 2019? Voici ses conclusions:
- L'utilisation de modèles d'investissement linguistique pré-formés se généralisera; les modèles avancés sans support seront très rares.
- Des vues pré-formées apparaîtront qui peuvent coder des informations spécialisées qui complètent les pièces jointes du modèle de langage. Nous pourrons regrouper différents types de présentations pré-formées en fonction des exigences de la tâche.
- D'autres travaux apparaîtront dans le domaine des applications multilingues et des modèles multilingues. En particulier, en s'appuyant sur l'intégration des mots dans les langues, nous verrons l'émergence de représentations interlangues pré-entraînées profondes.
Vision par ordinateur

Aujourd'hui, la vision par ordinateur est le domaine le plus populaire dans le domaine de l'apprentissage en profondeur. Il semble que les premiers fruits de la technologie aient déjà été obtenus et nous sommes au stade de développement actif. Qu'il s'agisse de cette image ou de cette vidéo, nous voyons l'émergence de nombreux frameworks et bibliothèques qui résolvent facilement les problèmes de vision par ordinateur.
Voici ma liste des meilleures solutions qui pourraient être vues cette année.
BigGANs Out
Ian Goodfellow a conçu les GAN en 2014, et le concept a engendré une grande variété d'applications. Année après année, nous avons observé comment le concept original a été finalisé pour une utilisation sur des cas réels. Mais une chose est restée inchangée jusqu'à cette année - les images générées par ordinateur étaient trop faciles à distinguer. Une certaine incohérence est toujours apparue dans le cadre, ce qui a rendu la différence très évidente.
Au cours des derniers mois, des changements sont apparus dans cette direction et, avec la
création de BigGAN , de tels problèmes peuvent être résolus une fois pour toutes. Regardez les images générées par cette méthode:

Sans microscope, il est difficile de dire ce qui ne va pas avec ces images. Bien sûr, chacun décidera pour lui-même, mais il ne fait aucun doute que le GAN change la façon dont nous percevons les images numériques (et la vidéo).
Pour référence: ces modèles ont d'abord été formés sur l'ensemble de données ImageNet, puis sur le JFT-300M pour démontrer que ces modèles sont bien transférés d'un ensemble de données à un autre. Voici un
lien vers une page de la liste de diffusion GAN expliquant comment visualiser et comprendre le GAN.
Model Fast.ai formé sur ImageNet en 18 minutes
C'est une implémentation vraiment cool. Il est largement admis que, pour effectuer des tâches d'apprentissage en profondeur, vous aurez besoin de téraoctets de données et de grandes ressources informatiques. Il en va de même pour l'entraînement du modèle à partir de zéro sur les données ImageNet. La plupart d'entre nous pensaient la même chose avant que quelques personnes sur fast.ai ne soient pas en mesure de prouver le contraire à tout le monde.
Leur modèle a donné une précision de 93% avec un impressionnant 18 minutes. Le matériel qu'ils ont utilisé,
décrit en détail
sur leur blog , se composait de 16 instances cloud AWS publiques, chacune avec 8 GPU NVIDIA V100. Ils ont construit un algorithme utilisant les bibliothèques fast.ai et PyTorch.
Le coût total de montage n'était que de 40 $! Jeremy a décrit leurs
approches et méthodes plus en détail
ici . C'est une victoire commune!
vid2vid de NVIDIA
Au cours des 5 dernières années, le traitement d'image a fait de grands progrès, mais qu'en est-il de la vidéo? Les méthodes de conversion d'une trame statique en une trame dynamique se sont avérées un peu plus compliquées que prévu. Pouvez-vous prendre une séquence d'images d'une vidéo et prédire ce qui se passera dans l'image suivante? De telles études ont été faites auparavant, mais les publications étaient au mieux vagues.

NVIDIA a décidé de rendre sa décision accessible au public plus tôt cette année [2018 - env. per.], qui a été évalué positivement par la société. Le but de vid2vid est de dériver une fonction d'affichage d'une vidéo d'entrée donnée afin de créer une vidéo de sortie qui transmet le contenu de la vidéo d'entrée avec une précision incroyable.
Vous pouvez essayer leur implémentation sur PyTorch, apportez-la
à GitHub ici .
Tendances de vision industrielle pour 2019
Comme je l'ai mentionné plus tôt, en 2019, nous sommes plus susceptibles de voir le développement des tendances de 2018, plutôt que de nouvelles percées: voitures autonomes, algorithmes de reconnaissance faciale, réalité virtuelle et plus encore. Pouvez-vous être en désaccord avec moi si vous avez un point de vue différent ou des ajouts, partagez-le avec nous, à quoi pouvons-nous nous attendre en 2019?
La question des drones, en attendant l'approbation des politiciens et du gouvernement, pourrait enfin obtenir le feu vert aux États-Unis (l'Inde est loin derrière dans ce dossier). Personnellement, j'aimerais que davantage de recherches soient effectuées dans des scénarios réels. Des conférences telles que
CVPR et
ICML donnent une bonne couverture des dernières réalisations dans ce domaine, mais la proximité des projets avec la réalité n'est pas très claire.
La «réponse visuelle aux questions» et les «systèmes de dialogue visuel» pourraient enfin débuter avec un début tant attendu. Ces systèmes n'ont pas la capacité de généraliser, mais il est prévu que nous verrons bientôt une approche multimodale intégrée.
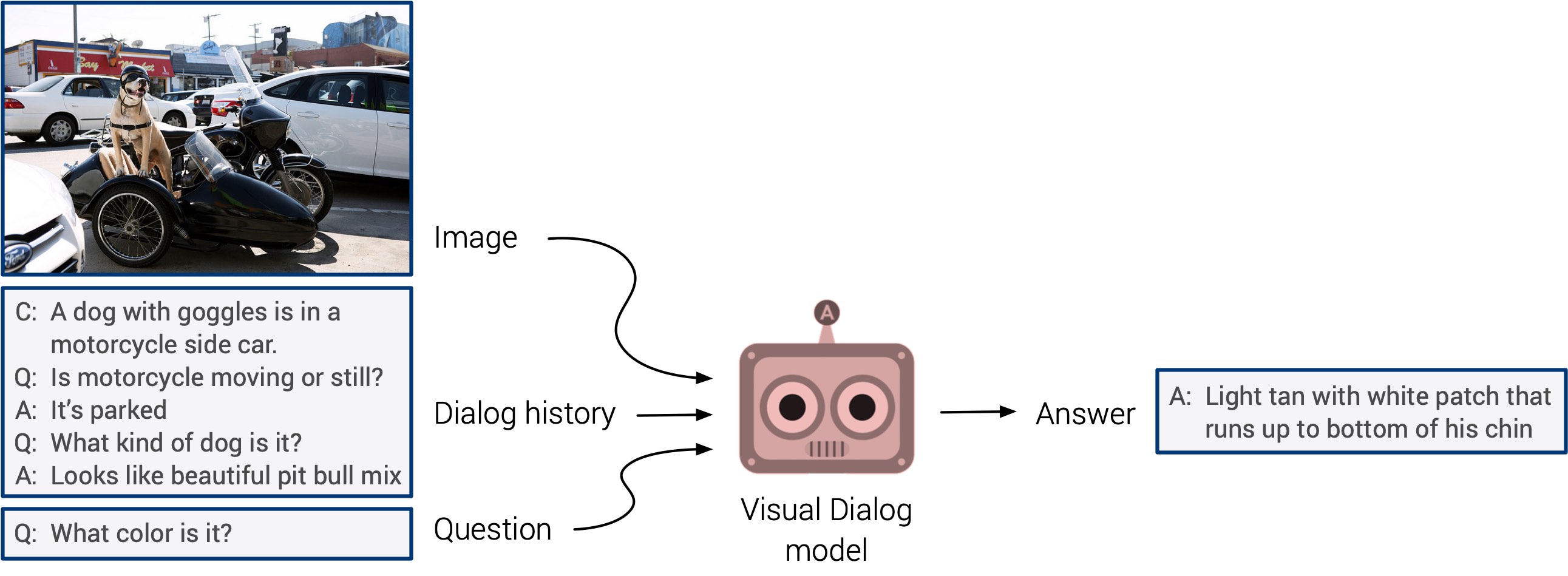
L'autoformation est apparue cette année. Je parie que l'année prochaine, il trouvera une application dans un plus grand nombre d'études. C'est une direction vraiment cool: les signes sont déterminés directement à partir des données d'entrée, au lieu de perdre du temps à marquer manuellement les images. Croisons les doigts!