
Parmi la date des scientifiques, il existe de nombreux holivars, et l'un d'eux concerne l'apprentissage automatique compétitif. Le succès de Kaggle montre-t-il vraiment la capacité d'un spécialiste à résoudre des tâches de travail typiques? Arseny
arseny_info (R&D Team Lead @
WANNABY ,
Kaggle Master , plus tard dans
A. ) et Arthur
n01z3 (Head of Computer Vision @
X5 Retail Group ,
Kaggle Grandmaster , plus tard dans
N. ) ont fait évoluer l'holivar à un nouveau niveau: au lieu d'une autre discussion dans ils ont pris des microphones dans le salon de discussion et ont tenu une
discussion publique lors de la réunion , sur la base de laquelle cet article est né.
Métriques, noyaux, classement
Un:Je voudrais commencer par l'argument attendu que Kaggle n'enseigne pas la chose la plus importante dans le travail d'une date scientifique typique - l'énoncé du problème. Une tâche correctement définie contient déjà la moitié de la solution, et souvent cette moitié est la plus difficile, et coder un modèle et la former est beaucoup plus facile. Kaggle propose une tâche dans un monde idéal - les données sont prêtes, la métrique est prête, prend et s'entraîne.
Étonnamment, même avec cela, des problèmes surviennent. Il n'est pas difficile de trouver de nombreux exemples lorsque les «kagglers» sont confus lorsqu'ils voient une métrique inconnue / incompréhensible.
N:Oui, c'est l'essence même de la kaggle. Les organisateurs ont réfléchi, officialisé la tâche, collecté l'ensemble de données et déterminé la métrique. Mais si une personne a les débuts de la pensée critique, la première chose à laquelle il réfléchira est la raison pour laquelle elle a décidé que la métrique choisie ou la cible proposée était optimale.
Les participants forts redéfinissent souvent la tâche eux-mêmes et trouvent une meilleure cible.
Et quand ils ont compris la métrique, déterminé la cible et collecté les données, l'optimisation de la métrique est ce que les kagglers font le mieux. Après chaque compétition, le client peut avec une grande confiance croire que les participants ont montré le «plafond» pour l'algorithme idéal avec une vitesse de pointe. Et pour y parvenir, les kagglers essaient de nombreuses approches et idées différentes, en les validant avec des itérations rapides.
Cette approche est directement convertie en un travail réussi sur des tâches réelles. De plus, les kugglers expérimentés peuvent immédiatement immédiatement intuitivement ou à partir d'une expérience passée sélectionner une liste d'idées qui valent la peine d'être essayées en premier lieu pour obtenir un profit maximum. Et ici, tout l'arsenal de la communauté kaggle vient à la rescousse: articles, relâche, forum, noyaux.
 Un:
Un:Vous avez parlé de «noyaux» et j'ai une plainte distincte à leur adresser. De nombreuses compétitions se sont transformées en développement axé sur le noyau. Je ne me concentrerai pas sur les cas dégénérés où une médaille d'or pourrait être obtenue en raison du lancement réussi d'un script public. Néanmoins, même dans les compétitions d'apprentissage en profondeur, vous pouvez maintenant obtenir une sorte de médaille, presque sans écrire de code. Vous pouvez prendre plusieurs décisions publiques, notamment ne pas comprendre la torsion de certains paramètres, vous tester sur le classement, faire la moyenne des résultats et obtenir une bonne métrique.
Auparavant, même des succès modérés dans les compétitions «photo» (par exemple, une médaille de bronze, c'est-à-dire entrer dans le top 10% de la note finale) montraient qu'une personne était capable de quelque chose - il fallait au moins écrire un pipeline normal du tout début à la fin , évitez les bogues critiques. Maintenant, ces succès ont dévalué: Kaggle va de l'avant avec sa plate-forme de base, qui abaisse le seuil d'entrée et vous permet en quelque sorte d'expérimenter sans savoir quoi.
 N:
N:La médaille de bronze n'a jamais été citée. C'est le niveau de "J'ai lancé quelque chose là-bas, et il a appris." Et ce n'est pas si mal.
L'abaissement du niveau d'entrée dû aux noyaux et à la présence de GPU crée une concurrence et élève le niveau général de connaissances. S'il y a un an, il était possible d'obtenir de l'or en utilisant vanilla Unet, vous ne pouvez plus vous passer de 5+ modifications et astuces. Et ces astuces fonctionnent non seulement sur Kaggle, mais aussi au-delà. Par exemple, chez Aerial
-Inria, nos mecs de ods.ai se sont levés et ont montré l'état de l'art simplement avec leurs puissants pipelines de segmentation développés par Kaggle. Cela montre l'applicabilité de telles approches dans le travail réel.
 Un:
Un:Le problème est que
dans les tâches réelles, il n'y a pas de classement . Habituellement, il n'y a pas de numéro unique qui montre que tout s'est mal passé ou, inversement, tout va bien. Souvent, il existe plusieurs chiffres, ils se contredisent, les relier dans un système est un autre défi.
N:Mais les mesures sont en quelque sorte importantes. Ils montrent une performance objective de l'algorithme. Sans algorithmes avec des mesures supérieures à un certain seuil utilisable, il est impossible de créer des services basés sur ML.
Un:Mais seulement s'ils reflètent honnêtement l'état du produit, ce qui n'est pas toujours le cas. Il arrive que vous ayez à faire glisser la métrique vers un minimum hygiénique, et que d'
autres améliorations de la métrique "technique" ne correspondent pas à des améliorations du produit (l'utilisateur ne les remarque pas +0.01 IoU), la corrélation entre la métrique et les sensations de l'utilisateur est perdue.
De plus, les méthodes classiques de kaggle pour augmenter la métrique ne sont pas applicables dans le travail normal. Pas besoin de rechercher des «visages», pas besoin de reproduire le balisage et de trouver les bonnes réponses par hachage de fichiers.

Validation fiable et ensembles de modèles audacieux
N:Kaggle vous apprend à valider correctement, notamment en raison de la présence de visages. Vous devez être très clair sur la façon dont la vitesse sur le classement s'est améliorée. Il est également
nécessaire de construire une validation locale représentative qui reflète la partie privée du classement ou la distribution des données en production, si nous parlons de travail réel.
Une autre chose dont on blâme souvent les Kagglers, ce sont les ensembles. Une solution Kaggle se compose généralement d'un tas de modèles, et il est impossible de faire glisser la prod. Cependant, ils oublient qu'il est impossible de faire une solution solide sans modèles uniques solides. Et pour gagner, vous avez besoin non seulement d'un ensemble, mais d'un ensemble de modèles uniques diversifiés et solides.
L'approche «mélanger tout de suite» ne donne jamais un résultat décent. Un:
Un:Le concept de «modèle unique simple» dans le cadre de la réunion Kaggle et pour l'environnement de production peut être très différent. Dans le cadre du concours, ce sera une architecture formée à 5/10 fois, avec un encodeur étalé, dans le temps que vous pouvez vous attendre à une augmentation du temps de test. Selon les normes de la concurrence, c'est une solution vraiment simple.
Mais la production a souvent
besoin de solutions de quelques ordres de grandeur plus facilement , en particulier en ce qui concerne les applications mobiles ou l'IoT. Par exemple, dans mon cas, les modèles Kaggle occupent généralement plus de 100 mégaoctets, et dans le travail du modèle, plus de quelques mégaoctets ne sont souvent même pas pris en compte; Il existe un écart similaire dans les exigences relatives au taux d'inférence.
N:Cependant, si la date à laquelle le scientifique sait comment entraîner une grille lourde, toutes les mêmes techniques conviennent également à la formation de modèles légers. En première approximation, vous pouvez prendre un maillage similaire plus simple ou une version mobile de la même architecture. Quantification des échelles et élagage au-delà de la compétence des Kagglers - sans aucun doute ici. Mais ce sont déjà des compétences très spécifiques, qui sont loin d'être toujours urgentes en prod.
Mais une situation beaucoup plus fréquente dans les problèmes réels est qu'il existe un petit ensemble de données étiqueté
(comme votre pantalon) et soit la plupart des données non allouées, soit un flux continu de nouvelles données. Et ici, la possibilité de souder un ensemble large et précis est parfaitement adaptée. Avec lui, vous pouvez faire de la pseudo-gradation ou de la distillation pour entraîner un modèle léger. L'augmentation de l'ensemble de données de cette manière est garantie pour améliorer les performances de n'importe quel modèle.
Un:Le pseudo-tamponnage est utile, mais dans les compétitions, il n'est pas utilisé pour une bonne vie - uniquement parce qu'il est impossible de redimensionner les données. Les données obtenues à l'aide de la pseudo-gradation, bien qu'améliorant la métrique, ne sont pas aussi utiles que le re-marquage manuel des données manquantes.
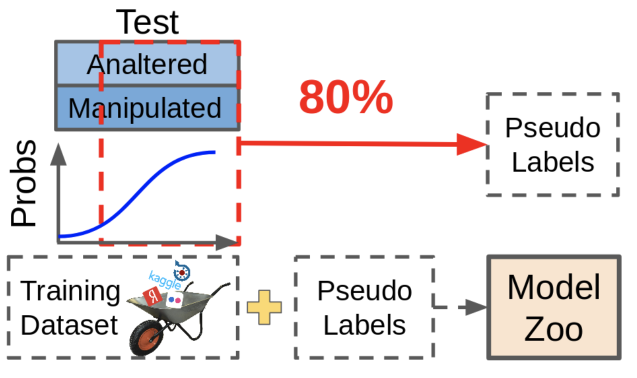
Qu'est-ce que le pseudo-tamponnage? Nous prenons des modèles existants, regardons où ils donnent des prédictions fiables, nous jetons ces échantillons avec des prédictions dans notre ensemble de données. Dans ce cas, les échantillons difficiles pour le modèle restent non étiquetés, car ces prévisions ne sont pas assez bonnes maintenant. Cercle vicieux!
En pratique, il est beaucoup plus utile de trouver les échantillons qui font que le réseau produit des prédictions incertaines et de les redimensionner. Cela nécessite beaucoup de travail manuel, mais l'effet en vaut la peine.
À propos de la beauté du code et du travail d'équipe
Un:Un autre problème est la qualité du code et la culture de développement. Kaggle ne vous apprend pas seulement à écrire du code, mais il fournit également de nombreux mauvais exemples. La plupart des noyaux sont du code mal structuré, illisible et inefficace qui est copié sans réfléchir. Certaines personnalités Kaggle populaires s'entraînent même à télécharger leur code sur Google Drive au lieu du référentiel.

Les gens sont bons dans l'apprentissage non supervisé. Si vous regardez beaucoup le mauvais code, vous pouvez vous habituer à l'idée qu'il devrait en être ainsi. C'est particulièrement dangereux pour les débutants, qui sont beaucoup sur Kaggle.
N:La qualité du code est un point discutable sur le cuggle, je suis d'accord. Cependant, j'ai également rencontré des gens qui ont écrit des pipelines très dignes qui pourraient être réutilisés pour d'autres tâches. Mais c'est plutôt l'exception: dans le feu de l'action, la qualité du code est sacrifiée au profit d'une vérification rapide des nouvelles idées, surtout vers la fin de la compétition.
Mais Kaggle enseigne le travail d'équipe. Et rien n'unit les gens comme une cause commune, un objectif compréhensible commun. Vous pouvez essayer de rivaliser avec un tas de personnes différentes, vous impliquer et développer des compétences générales.
 Un:
Un:Les équipes de style Kaggle sont également très différentes. C'est bien s'il y a vraiment une sorte de séparation des tâches par les rôles, une interaction constructive et que tout le monde y contribue. Néanmoins, les équipes dans lesquelles chacun fait sa propre grosse boule de boue, et dans les derniers jours de la compétition, tout cela est frénétiquement mélangé, suffisent également, et cela n'enseigne rien de bon - le développement de logiciels réels (y compris la science des données) pas fait depuis très longtemps.
Résumé
Résumons.
Sans aucun doute, la participation à des concours donne ses bonus utiles dans le travail quotidien: tout d'abord, c'est la capacité d'itérer rapidement, de tout extraire des données dans le cadre de la métrique et n'hésite pas à utiliser des approches de pointe.
D'un autre côté, l'abus des approches Kaggle conduit souvent à un code illisible sous-optimal, à des priorités de travail douteuses et à un peu de bling.
Cependant, à toute date, le scientifique sait que pour créer avec succès un ensemble, vous devez combiner une variété de modèles. Donc, dans une équipe,
cela vaut la peine de combiner des personnes avec des compétences différentes , et un ou deux Kagglers expérimentés seront utiles à presque toutes les équipes.