Lorsque nous avons choisi un outil pour traiter les mégadonnées, nous avons envisagé différentes options - à la fois propriétaires et open source. Nous avons évalué les possibilités d'adaptation rapide, d'accessibilité et de flexibilité des technologies. Y compris la migration entre les versions. En conséquence, nous avons choisi la solution open source Greenplum, qui répondait le mieux à nos exigences, mais nécessitait la solution d'un problème important.

Le fait est que les versions 4 et 5 des fichiers de base de données Greenplum ne sont pas compatibles entre elles, et qu'une simple mise à niveau d'une version à l'autre est donc impossible. La migration des données ne peut se faire que par téléchargement et téléchargement de données. Dans cet article, je parlerai des options possibles pour cette migration.
Évaluation des options de migration
pg_dump & psql (ou pg_restore)
C'est trop lent quand il s'agit de dizaines de téraoctets, car toutes les données sont téléchargées et téléchargées via les nœuds maîtres. Mais assez rapide pour migrer DDL et de petites tables. Vous pouvez télécharger les deux dans un fichier et exécuter pg_dump et psql en même temps via un canal sur un cluster source et un cluster de destination. pg_dump télécharge simplement vers un fichier unique contenant à la fois les commandes DDL et les commandes de données COPY. Les données obtenues peuvent être traitées de manière pratique, comme indiqué ci-dessous.
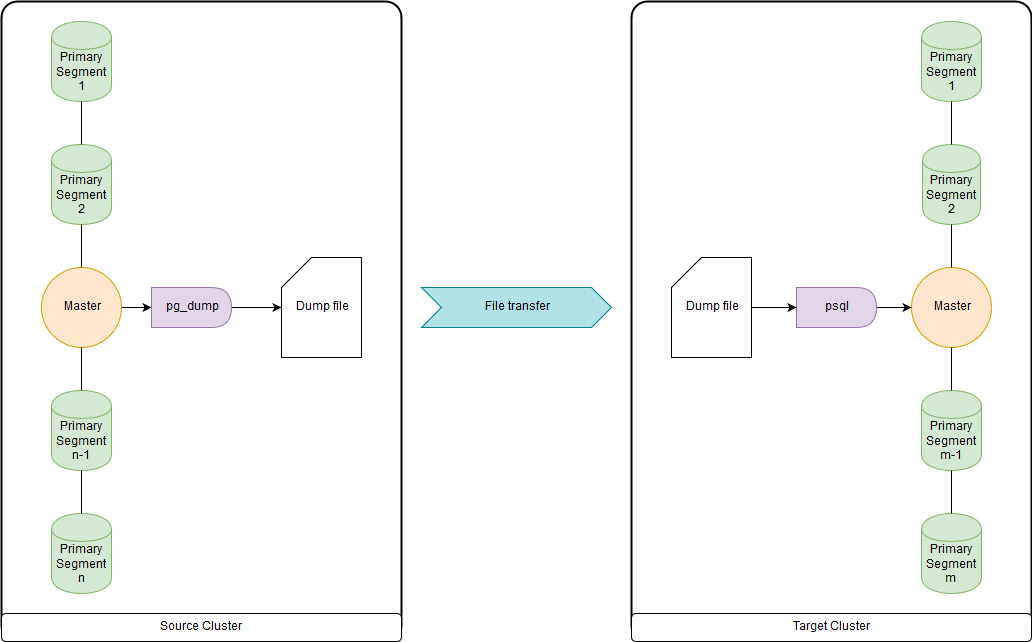
gptransfer
Nécessite la version Greenplum 4.2 ou ultérieure. Il est nécessaire que le cluster source et le cluster de destination fonctionnent simultanément. Le moyen le plus rapide de migrer de grandes tables de données pour la version open source. Mais cette méthode est très lente pour transférer des tables vides et petites en raison de la surcharge élevée.
gptransfer utilise pg_dump pour transférer DDL et gpfdist pour transférer des données. Le nombre de segments principaux sur le cluster de destination ne doit pas être inférieur au segment hôte sur le cluster source. Il est important de prendre en compte lors de la création de clusters «sandbox», si les données des clusters principaux leur seront transférées et que l'utilisation de l'utilitaire gptransfer est prévue. Même si les hôtes de segment sont peu nombreux, vous pouvez déployer le nombre requis de segments sur chacun d'eux. Le nombre de segments sur le cluster de destination peut être inférieur à celui sur le cluster source, mais cela
affectera négativement la vitesse de transfert des données. Entre les clusters, l'authentification ssh sur les certificats doit être configurée.
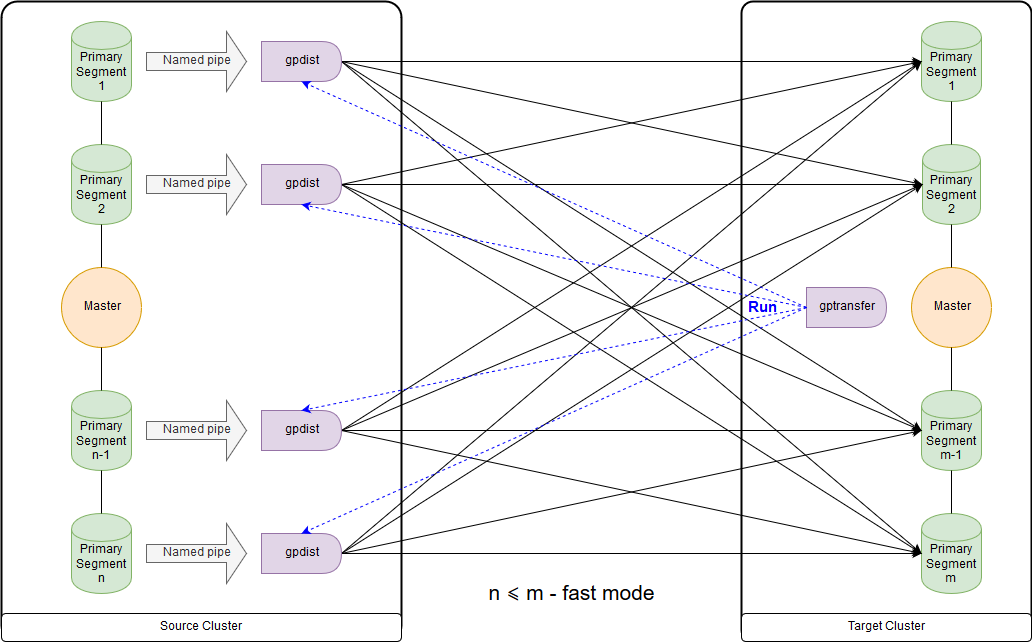
Il s'agit du schéma du mode rapide lorsque le nombre de segments sur le cluster de destination est supérieur ou égal au nombre sur le cluster source. Le lancement de l'utilitaire lui-même est illustré dans le diagramme sur le nœud maître du cluster récepteur. Dans ce mode, une table d'écriture externe est créée sur le cluster source, qui écrit des données sur chaque segment dans le canal nommé. La commande INSERT INTO writable_external_table SELECT * FROM source_table est exécutée. Les données du canal nommé sont lues par gpfdist. Une table externe est également créée sur le cluster de destination, uniquement pour la lecture. Le tableau indique les données fournies par gpfdist via
le protocole du même nom . La commande INSERT INTO target_table SELECT * FROM external_gpfdist_table est exécutée. Les données sont automatiquement redistribuées entre les segments du cluster de destination.
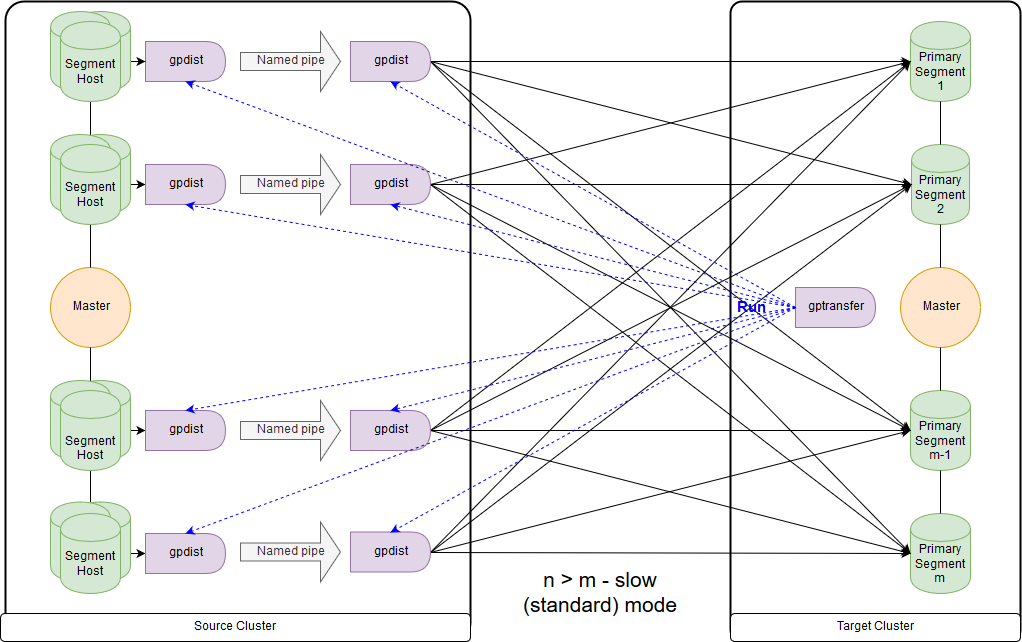
Et c'est le schéma du mode lent, ou, comme le dit gptransfer lui-même, le mode standard. La principale différence est que sur chaque segment-hôte du cluster source, une paire gpfdist est lancée pour tous les segments de ce segment-hôte. Une table d'enregistrement externe fait référence à gpfdist agissant comme un récepteur de données. De plus, si plusieurs valeurs sont indiquées pour l'écriture dans le paramètre LOCATION de la table externe, alors les segments sont distribués uniformément par gpfdist lors de l'écriture des données. Les données entre gpfdist sur le segment hôte sont transmises via le canal nommé. Pour cette raison, la vitesse de transfert de données est inférieure, mais elle s'avère toujours plus rapide que lors du transfert de données uniquement via le nœud maître.
Lors de la migration des données de Greenplum 4 vers Greenplum 5, gptransfer doit être exécuté sur le nœud maître du cluster de destination. Si nous exécutons gptransfer sur le cluster source, nous obtenons l'erreur de l'absence du champ
san_mounts dans la table
pg_catalog.gp_segment_configuration :
gptransfer -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Validating options... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190109:12:46:14:010893 gptransfer:gpdb-source-master.local:gpadmin-[CRITICAL]:-gptransfer failed. (Reason='error 'ERROR: column "san_mounts" does not exist LINE 2: ... SELECT dbid, content, status, unnest(san_mounts... ^ ' in ' SELECT dbid, content, status, unnest(san_mounts) FROM pg_catalog.gp_segment_configuration WHERE content >= 0 ORDER BY content, dbid '') exiting...
Vous devez également vérifier les variables GPHOME afin qu'elles correspondent entre le cluster source et le cluster de destination. Sinon, nous obtenons une
erreur assez étrange (l'utilitaire gptransfer échoue lorsque la source et la cible ont un chemin GPHOME différent).
gptransfer -t big_db.public.test_table --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --source-host=gpdb-spurce-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[ERROR]:-gptransfer: error: GPHOME directory does not exist on gpdb-source-master.local
Vous pouvez simplement créer le lien symbolique correspondant et remplacer la variable GPHOME dans la session dans laquelle gptransfer est démarré.
Lorsque gptransfer est démarré sur le cluster de destination, l'option «--source-map-file» doit pointer vers un fichier contenant une liste d'hôtes et leurs adresses IP avec les segments principaux du cluster source. Par exemple:
sdw1,192.0.2.1 sdw2,192.0.2.2 sdw3,192.0.2.3 sdw4,192.0.2.4
Avec l'option «--full», il est possible de transférer non seulement des tables, mais la base de données entière, cependant, les bases de données utilisateur ne doivent pas être créées sur le cluster de destination. Vous devez également vous rappeler qu'il y a des problèmes dus aux changements de syntaxe lors du déplacement de tables externes.
Évaluons la surcharge supplémentaire, par exemple, en copiant 10 tables vides (tables de big_db.public.test_table_2 à big_db.public.test_table_11) à l'aide de gptarnsfer:
gptransfer -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-ba tch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-batch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190118:06:14:09:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving source tables... 20190118:06:14:12:031521 gptransfer:mdw:gpadmin-[INFO]:-Checking for gptransfer schemas... 20190118:06:14:22:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving list of destination tables... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Reading source host map file... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Building list of source tables to transfer... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Number of tables to transfer: 10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-gptransfer will use "standard" mode for transfer. 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating source host map... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating transfer table set... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-The following tables on the destination system will be truncated: 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_2 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_3 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_4 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_5 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_6 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_7 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_8 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_9 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_11 … 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using batch size of 10 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using sub-batch size of 16 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating work directory '/home/gpadmin/gptransfer_31521' 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating schema public in database edw_prod... 20190118:06:14:40:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting transfer of big_db.public.test_table_5 to big_db.public.test_table_5... … 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Validation of big_db.public.test_table_4 successful 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Removing work directories... 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Finished.
En conséquence, le transfert de 10 tables vides a pris environ 16 secondes (14: 40-15: 02), c'est-à-dire une table - 1,6 secondes. Pendant ce temps, dans notre cas, environ 100 Mo de données peuvent être téléchargées à l'aide de pg_dump & psql.
gp_dump & gp_restore
En option: utilisez des modules complémentaires sur eux, gpcrondump & gpdbrestore, car gp_dump & gp_restore sont déclarés obsolètes. Bien que gpcrondump & gpdbrestore utilisent eux-mêmes gp_dump & gp_restore dans le processus. C'est le moyen le plus universel, mais pas le plus rapide. Les fichiers de sauvegarde créés avec gp_dump représentent un ensemble de commandes DDL sur le nœud maître et sur les segments principaux, principalement des ensembles de commandes et de données COPY. Convient aux cas où il n'est pas possible de fournir un fonctionnement simultané du cluster de destination et du cluster source. Il existe à la fois dans les anciennes versions de Greenplum et dans les nouvelles:
gp_dump ,
gp_restore .
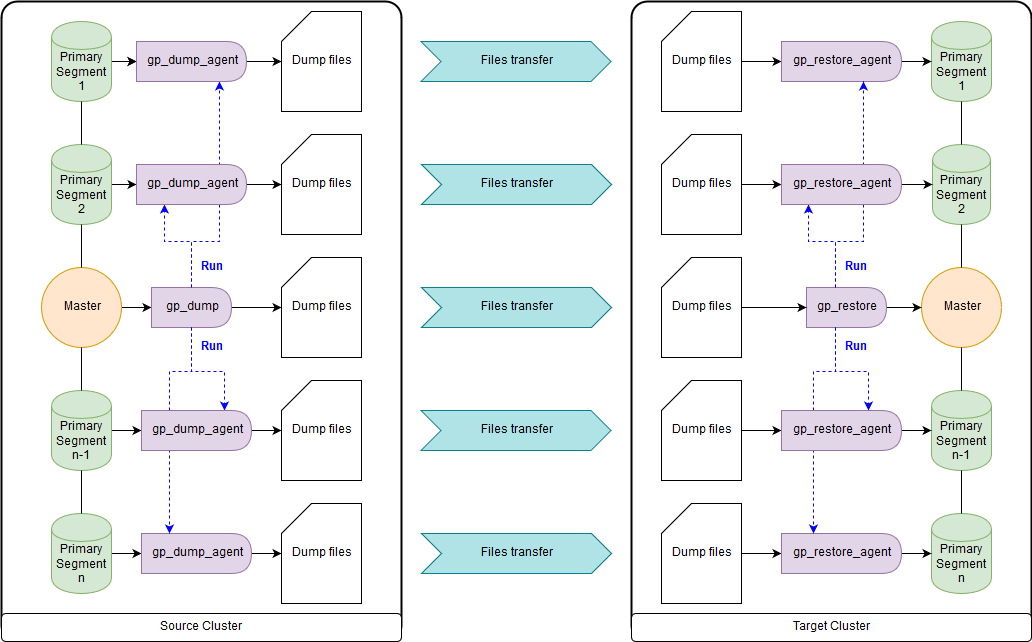
Utilitaires gpbackup et gprestore
Créé en remplacement de gp_dump & gp_restore. Pour leur travail, la version minimale 4.3.17 de Greenplum est requise (
const MINIMUM_GPDB4_VERSION = "4.3.17" ). Le schéma de travail est similaire à gpbackup & gprestore, tandis que la vitesse de travail est beaucoup plus rapide. Le moyen le plus rapide d'obtenir des commandes DDL pour de grandes bases de données. Par défaut, il transfère les objets globaux, pour la récupération, vous devez spécifier "gprestore --with-globals". Le paramètre facultatif «--jobs» peut définir le nombre de travaux (et de sessions dans la base de données) lors de la création d'une sauvegarde. Étant donné que plusieurs sessions sont créées, il est important de garantir la cohérence des données jusqu'à ce que tous les verrous soient reçus. Il existe également une option utile «--with-stats», qui vous permet de transférer des statistiques sur les objets utilisés pour construire des plans d'exécution. Plus d'informations
ici .
Utilitaire Gpcopy
Pour copier des bases de données, il existe un utilitaire gpcopy - un remplacement de gptansfer. Mais il n'est inclus que dans la version propriétaire de Greenplum de Pivotal, à partir de 4.3.26 - dans la version open source,
cet utilitaire ne le fait pas . Lorsque vous travaillez sur le cluster source, la commande COPIER source_table POUR PROGRAMMER 'gpcopy_helper ...' SUR SEGMENT CSV IGNORE EXTERNAL PARTITIONS est exécutée. Du côté du cluster récepteur, une table externe temporaire CREATE EXTERNAL WEB TEMP TABLE external_temp_table (LIKE target_table) EXECUTE '... gpcopy_helper –listen ...' est créée et la commande INSERT INTO target_table SELECT * FROM external_temp_table est exécutée. Par conséquent, gpcopy_helper avec le paramètre –listen est lancé sur chaque segment du cluster de destination, qui reçoit les données de gpcopy_helper des segments du cluster source. En raison d'un tel schéma de transmission de données, ainsi que de la compression, la vitesse de transmission est beaucoup plus élevée. Entre les clusters, l'authentification ssh sur les certificats doit également être configurée. Je veux également noter que gpcopy a une option pratique «--truncate-source-after» (et «--validate») pour les cas où les clusters source et de destination sont situés sur les mêmes serveurs.
Stratégie de transfert de données
Pour déterminer la stratégie de transfert, nous devons déterminer ce qui est le plus important pour nous: transférer des données rapidement, mais avec plus de travail et peut-être moins de manière fiable (gpbackup, gptransfer ou une combinaison de ceux-ci) ou avec moins de travail, mais plus lentement (gpbackup ou gptransfer sans combinaison).
Le moyen le plus rapide de transférer des données - lorsqu'il existe un cluster source et un cluster de destination - est le suivant:
- Obtenez DDL en utilisant gpbackup --metadata-only, convertissez et chargez à travers le pipeline en utilisant psql
- Supprimer les index
- Transférer des tables d'une taille de 100 Mo ou plus à l'aide de gptransfer
- Transférer des tables d'une taille inférieure à 100 Mo à l'aide de pg_dump | psql comme dans le premier paragraphe
- Créer des index supprimés
Cette méthode s'est avérée être dans nos mesures au moins 2 fois plus rapide que gp_dump & gp_restore. Méthodes alternatives: transfert de toutes les bases de données à l'aide de gptransfer –full, gpbackup & gprestore ou gp_dump & gp_restore.
Les tailles de table peuvent être obtenues par la requête suivante:
SELECT nspname AS "schema", coalesce(tablename, relname) AS "name", SUM(pg_total_relation_size(class.oid)) AS "size" FROM pg_class class JOIN pg_namespace namespace ON namespace.oid = class.relnamespace LEFT JOIN pg_partitions parts ON class.relname = parts.partitiontablename AND namespace.nspname = parts.schemaname WHERE nspname NOT IN ('pg_catalog', 'information_schema', 'pg_toast', 'pg_bitmapindex', 'pg_aoseg', 'gp_toolkit') GROUP BY nspname, relkind, coalesce(tablename, relname), pg_get_userbyid(class.relowner) ORDER BY 1,2;
Conversions nécessaires
Les fichiers de sauvegarde dans les versions 4 et 5 de Greenplum ne sont pas non plus entièrement compatibles. Ainsi, dans Greenplum 5, en raison d'un changement de syntaxe, les commandes CREATE EXTERNAL TABLE et COPY n'ont pas le paramètre INTO ERROR TABLE, et vous devez définir le paramètre SET gp_ignore_error_table sur true afin que la restauration de la sauvegarde n'échoue pas par erreur. Avec le paramètre défini, nous obtenons simplement un avertissement.
De plus, la cinquième version a introduit un protocole différent pour interagir avec les tables pxf externes et pour l'utiliser, vous devez modifier le paramètre LOCATION et configurer le service pxf.
Il convient également de noter que dans les fichiers de sauvegarde gp_dump et gp_restore à la fois sur le nœud maître et sur chaque segment principal, le paramètre SET gp_strict_xml_parse est défini sur false. Il n'y a pas un tel paramètre dans Greenplum 5, et par conséquent, nous obtenons un message d'erreur.
Si le protocole gphdfs a été utilisé pour les tables externes, vous devez archiver dans les fichiers de sauvegarde la liste des sources dans le paramètre LOCATION pour les tables externes sur la ligne 'gphdfs: //'. Par exemple, il ne devrait y avoir que 'gphdfs: //hadoop.local: 8020'. S'il existe d'autres lignes, elles doivent être ajoutées au script de remplacement sur le nœud maître par analogie.
grep -o gphdfs\:\/\/.*\/ /data1/master/gpseg-1/db_dumps/20181206/gp_dump_-1_1_20181206122002.gz | cut -d/ -f1-3 | sort | uniq gphdfs://hadoop.local:8020
Nous remplaçons le nœud maître (en utilisant le fichier de données gp_dump comme exemple):
mv /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz gunzip -c /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz | sed "s#'gphdfs://hadoop.local:8020#'pxf:/#g" | sed "s/\(^.*pxf\:\/\/.*'\)/\1\\&\&\?PROFILE=HdfsTextSimple'/" |sed "s#'&#g" | sed 's/SET gp_strict_xml_parse = false;/SET gp_ignore_error_table = true;/g' | gzip -1 > /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz nets
Dans les versions récentes, le nom du profil HdfsTextSimple est
déclaré obsolète , le nouveau nom est hdfs: text.
Résumé
Implicit Text Casting , le nouveau mécanisme de gestion des ressources du cluster des
groupes de ressources, remplaçant les files d'attente de ressources, l'optimiseur
GPORCA , qui est inclus par défaut dans Greenplum 5, les problèmes mineurs avec les clients restaient en dehors du champ d'application de l'article.
J'attends avec impatience la sortie de la sixième version de Greenplum, prévue pour le printemps 2019: niveau de compatibilité avec PostgreSQL 9.4, recherche en texte intégral, prise en charge de l'index GIN, types de plage, JSONB, compression zStd. De plus, les plans préliminaires de Greenplum 7 sont devenus connus: niveau de compatibilité avec PostgreSQL 9.6 minimum, Row Level Security, Automated Master Failover. Les développeurs promettent également la disponibilité d'utilitaires de mise à niveau de la base de données pour la mise à jour entre les versions principales, ce qui facilitera la vie.
Cet article a été préparé par l'équipe de gestion des données de Rostelecom